溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Pandas如何處理大數據,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
大文本數據的讀寫
有時候我們會拿到一些很大的文本文件,完整讀入內存,讀入的過程會很慢,甚至可能無法讀入內存,或者可以讀入內存,但是沒法進行進一步的計算,這個時候如果我們不是要進行很復雜的運算,可以使用read_csv提供的chunksize或者iterator參數,來部分讀入文件,處理完之后再通過to_csv的mode='a',將每部分結果逐步寫入文件。
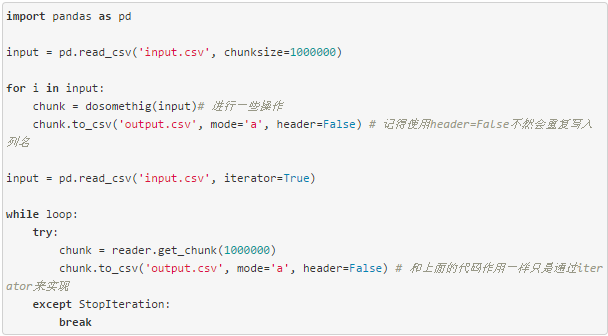
to_csv, to_excel的選擇
在輸出結果時統稱會遇到輸出格式的選擇,平時大家用的最多的.csv, .xls, .xlsx,后兩者一個是excel2003,一個是excel2007,我的經驗是csv>xls>xlsx,大文件輸出csv比輸出excel要快的多,xls只支持60000+條記錄,xlsx雖然支持記錄變多了,但是,如果內容有中文常常會出現詭異的內容丟失。因此,如果數量較小可以選擇xls,而數量較大則建議輸出到csv,xlsx還是有數量限制,而且大數據量的話,會讓你覺得python都死掉了
讀入時處理日期列
我之前都是在數據讀入后通過to_datetime函數再去處理日期列,如果數據量較大這又是一個浪費時間的過程,其實在讀入數據時,可以通過parse_dates參數來直接指定解析為日期的列。它有幾種參數,TRUE的時候會將index解析為日期格式,將列名作為list傳入則將每一個列都解析為日期格式
關于to_datetime函數再多說幾句,我們拿到的時期格式常常出現一些亂七八糟的怪數據,遇到這些數據to_datimetime函數默認會報錯,其實,這些數據是可以忽略的,只需要在函數中將errors參數設置為'ignore'就可以了。
另外,to_datetime就像函數名字顯示的,返回的是一個時間戳,有時我們只需要日期部分,我們可以在日期列上做這個修改,datetime_col = datetime_col.apply(lambda x: x.date()),用map函數也是一樣的datetime_col = datetime_col.map(lambda x: x.date())
把一些數值編碼轉化為文字
前面提到了map方法,我就又想到了一個小技巧,我們拿到的一些數據往往是通過數字編碼的,比如我們有gender這一列,其中0代表男,1代表女。當然我們可以用索引的方式來完成

其實我們有更簡單的方法,對要修改的列傳入一個dict,就會達到同樣的效果。

通過shift函數求用戶的相鄰兩次登錄記錄的時間差
之前有個項目需要計算用戶相鄰兩次登錄記錄的時間差,咋看起來其實這個需求很簡單,但是數據量大起來的話,就不是一個簡單的任務,拆解開來做的話,需要兩個步驟,***步將登錄數據按照用戶分組,再計算每個用戶兩次登錄之間的時間間隔。數據的格式很單純,如下所示

如果數據量不大的,可以先unique uid,再每次計算一個用戶的兩次登錄間隔,類似這樣
這種方法雖然計算邏輯比較清晰易懂,但是缺點也非常明顯,計算量巨大,相當與有多少量記錄就要計算多少次。
那么為什么說pandas的shift函數適合這個計算呢?來看一下shift函數的作用

剛好把值向下錯位了一位,是不是恰好是我們需要的。讓我們用shift函數來改造一下上面的代碼。

上面的代碼就把pandas向量化計算的優勢發揮出來了,規避掉了計算過程中最耗費時間的按uid循環。如果我們的uid都是一個只要排序后用shift(1)就可以取到所有前一次登錄的時間,不過真實的登錄數據中有很多的不用的uid,因此再將uid也shift一下命名為uid0,保留uid和uid0匹配的記錄就可以了。
以上是“Pandas如何處理大數據”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





