溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關如何解析MySQL索引問題,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
0 前言
這篇文章不會講解索引的基礎知識,主要是關于MySQL數據庫的B+樹索引的相關原理,里面的一些知識都參考了MySQL技術內幕這本書,也算對于這些知識的總結。對于B樹和B+樹相關的知識,可以參考我的這篇博客:面試官問你B樹和B+樹,就把這篇文章丟給他
1 索引的管理
索引有很多中類型:普通索引、唯一索引、主鍵索引、組合索引、全文索引,下面我們看看如何創建和刪除下面這些類型的索引。
1.1 索引的創建方式
索引的創建是可以在很多種情況下進行的。
直接創建索引
CREATE [UNIQUE|FULLLTEXT] INDEX index_name ON table_name(column_name(length))
[UNIQUE|FULLLTEXT]:表示可選擇的索引類型,唯一索引還是全文索引,不加話就是普通索引。
table_name:表的名稱,表示為哪個表添加索引。
column_name(length):column_name是表的列名,length表示為這一列的前length行記錄添加索引。
修改表結構的方式添加索引
ALTER TABLE table_name ADD [UNIQUE|FULLLTEXT] INDEX index_name (column(length))
創建表的時候同時創建索引
CREATE TABLE `table` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(255) CHARACTER NOT NULL , PRIMARY KEY (`id`), [UNIQUE|FULLLTEXT] INDEX index_name (title(length)) )
1.2 主鍵索引和組合索引創建的方式
前面講的都是普通索引、唯一索引和全文索引創建的方式,但是,主鍵索引和組合索引創建的方式卻是有點不一樣的,所以單獨拿出來講一下。
組合索引創建方式
創建表的時候同時創建索引
CREATE TABLE `table` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(255) CHARACTER NOT NULL , PRIMARY KEY (`id`), INDEX index_name(id,title) )
修改表結構的方式添加索引
ALTER TABLE table_name ADD INDEX name_city_age (name,city,age);
主鍵索引創建方式
主鍵索引是一種特殊的唯一索引,一個表只能有一個主鍵,不允許有空值。一般是在建表的時候同時創建主鍵索引。
CREATE TABLE `table` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(255) CHARACTER NOT NULL , PRIMARY KEY (`id`) )
1.3 刪除索引
刪除索引可利用ALTER TABLE或DROP INDEX語句來刪除索引。類似于CREATE INDEX語句,DROP INDEX可以在ALTER TABLE內部作為一條語句處理,語法如下。
(1)DROP INDEX index_name ON talbe_name
(2)ALTER TABLE table_name DROP INDEX index_name
(3)ALTER TABLE table_name DROP PRIMARY KEY
第3條語句只在刪除PRIMARY KEY索引時使用,因為一個表只可能有一個PRIMARY KEY索引,因此不需要指定索引名。
1.4 索引實例
上面講了一下基本的知識,接下來,還是通過一個具體的例子來體會一下。
step1:創建表
create table table_index( id int(11) not null auto_increment, title char(255) not null, primary key(id) );
step2:添加索引
首先,我們使用直接添加索引的方式添加一個普通索引。
CREATE INDEX idx_a ON table_index(title);
接著,我們用修改表結構的時候添加索引。
ALTER TABLE table_index ADD UNIQUE INDEX idx_b (title(100));
最后,我們再添加一個組合索引。
ALTER TABLE table_index ADD INDEX idx_id_title (id,title);
這樣,我們就把前面索引的方式都用上一遍了,我相信你也熟悉這些操作了。
step3:使用SHOW INDEX命令查看索引信息
如果想要查看表中的索引信息,可以使用命令SHOW INDEX,下面的例子,我們查看表table_index的索引信息。
SHOW INDEX FROM table_index\G;
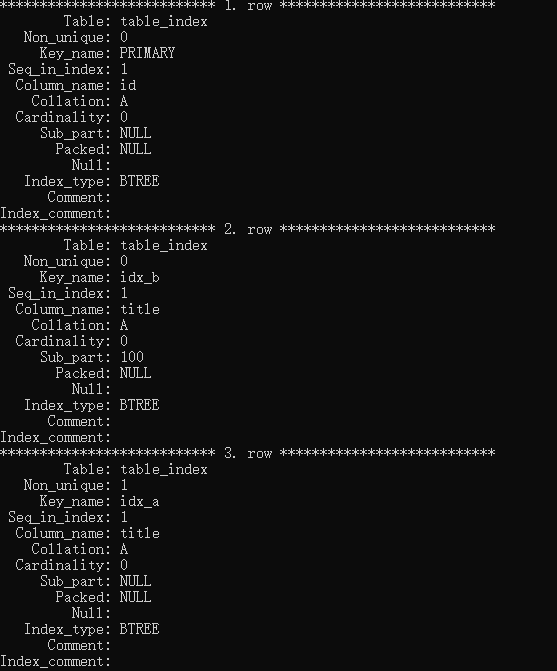
得到上面的信息,上面的信息什么意思呢?我們逐一介紹!
| 字段 | 解釋 |
|---|---|
| Table | 索引所在的表 |
| Non_unique | 非唯一索引,如果是0,代表唯一的,也就是說如果該列索引中不包括重復的值則為0 否則為1 |
| Key_name | 索引的名字,如果是主鍵的話 則為PRIMARY |
| Seq_in_index | 索引中該列的位置,從1開始,如果是組合索引 那么按照字段在建立索引時的順序排列 |
| Collation | 列是以什么方式存儲在索引中的。可以是A或者NULL,B+樹索引總是A,排序的, |
| Sub_part | 是否列的部分被索引,如果只是前100行索引,就顯示100,如果是整列,就顯示NULL |
| Packed | 關鍵字是否被壓縮,如果沒有,為NULL |
| Index_type | 索引的類型,對于InnoDB只支持B+樹索引,所以都是顯示BTREE |
step4:刪除索引
直接刪除索引方式
DROP INDEX idx_a ON table_index;
修改表結構時刪除索引
ALTER TABLE table_index DROP INDEX idx_b;
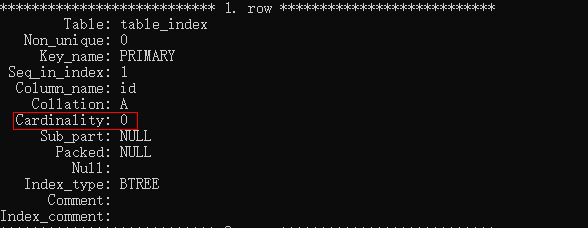
1.5 Cardinality關鍵字解析
在上面介紹了那么多個關鍵字的意思,但是Cardinality這個關鍵字非常的關鍵,優化器會根據這個值來判斷是否使用這個索引。在B+樹索引中,只有高選擇性的字段才是有意義的,高選擇性就是這個字段的取值范圍很廣,比如姓名字段,會有很多的名字,可選擇性就高了。
一般來說,判斷是否需要使用索引,就可以通過Cardinality關鍵字來判斷,如果非常接近1,說明有必要使用,如果非常小,那么就要考慮是否使用索引了。
需要注意的一個問題時,這個關鍵字不是及時更新的,需要更新的話,需要使用ANALYZE TABLE,例如。
analyze table table_index;

因為目前沒有數據,所以,你會發現,這個值一直都是0,沒有變化。
InoDB存儲引擎Cardinality的策略
在InnoDB存儲引擎中,這個關鍵字的更新發生在兩個操作中:insert和update。但是,并不是每次都會更新,這樣會增加負荷,所以,對于這個關鍵字的更新有它的策略:
表中1/16的數據發生變化
InnoDB存儲引擎的計數器stat_modified_conter>2000000000
默認InnoDB存儲引擎會對8個葉子節點進行采樣,采樣過程如下:
B+樹索引中葉子節點數量,記做A
隨機取得B+樹索引中的8個葉子節點。統計每個頁不同的記錄個數,分別為p1-p8
根據采樣信息得到Cardinality的預估值:(p1+p2+p3+...+p8)*A/8
因為隨機采樣,所以,每次的Cardinality值都是不一樣的,只有一種情況會一樣的,就是表中的葉子節點小于或者等于8,這時候,怎么隨機采樣都是這8個,所以也就一樣的。
1.6 Fast Index Creation
在MySQL 5.5之前,對于索引的添加或者刪除,每次都需要創建一張臨時表,然后導入數據到臨時表,接著刪除原表,如果一張大表進行這樣的操作,會非常的耗時,這是一個很大的缺陷。
InnoDB存儲引擎從1.0.x版本開始加入了一種Fast Index Creation(快速索引創建)的索引創建方式。
這種方式的策略為:每次為創建索引的表加上一個S鎖(共享鎖),在創建的時候,不需要重新建表,刪除輔助索引只需要更新內部視圖,并將輔助索引空間標記為可用,所以,這種效率就大大提高了。
1.7 在線數據定義
MySQL5.6開始支持的在線數據定義操作就是:允許輔助索引創建的同時,還允許其他insert、update、delete這類DM操作,這就極大提高了數據庫的可用性。
所以,我們可以使用新的語法進行創建索引:
ALTER TABLE table_name ADD [UNIQUE|FULLLTEXT] INDEX index_name (column(length)) [ALGORITHM = {DEFAULT|INPLACE|COPY}] [LOCK = {DEFAULT|NONE|SHARED|EXLUSIVE}]ALGORITHM指定創建或者刪除索引的算法
COPY:創建臨時表的方式
INPLACE:不需要創建臨時表
DEFAULT:根據參數old_alter_table參數判斷,如果是OFF,采用INPLACE的方式
LOCK表示對表添加鎖的情況
NONE:不加任何鎖
SHARE:加一個S鎖,并發讀可以進行,寫操作需要等待
EXCLUSIVE:加一個X鎖,讀寫都不能并發進行
DEFAULT:先判斷是否可以使用NONE,如不能,判斷是否可以使用SHARE,如不能,再判斷是否可以使用EXCLUSIVE模式。
2 B+ 樹索引的使用
2.1 聯合索引
聯合索引是指對表上的多個列進行索引,這一部分我們將通過幾個例子來講解聯合索引的相關知識點。
首先,我們先創建一張表以及為這張表創建聯合索引。
create table t_index( a char(2) not null default '', b char(2) not null default '', c char(2) not null default '', d char(2) not null default '' )engine myisam charset utf8;
創建聯合索引
alter table t_index add index abcd(a,b,c,d);
插入幾條測試數據
insert into t_index values('a','b','c','d'), ('a2','b2','c2','d2'), ('a3','b3','c3','d3'), ('a4','b4','c4','d4'), ('a5','b5','c5','d5'), ('a6','b6','c6','d6');到這一步,我們已經基本準備好了需要的數據,我們可以進行更深一步的聯合索引的探討。
我們什么時候需要創建聯合索引呢
索引建立的主要目的就是為了提高查詢的效率,那么聯合索引的目的也是類似的,聯合索引的目的就是為了提高存在多個查詢條件的情況下的效率,就如上面建立的表一樣,有多個字段,當我們需要利用多個字段進行查詢的時候,我們就需要利用到聯合索引了。
什么時候聯合索引才會發揮作用呢
有時候,我們會用聯合索引,但是,我們并不清楚其原理,不知道什么時候聯合索引會起到作用,什么時候又是會失效的?
帶著這個問題,我們了解一下聯合索引的最左匹配原則。
最左匹配原則:這個原則的意思就是創建組合索引,以最左邊的為準,只要查詢條件中帶有最左邊的列,那么查詢就會使用到索引。
下面,我們用幾個例子來看看這個原則。
EXPLAIN SELECT * FROM t_index WHERE a = 'a' \G;
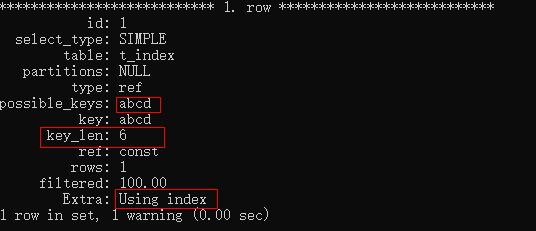
我們看看這條語句的結果,首先,我們看到使用了索引,因為查詢條件中帶有最左邊的列a,那么利用了幾個索引呢?這個我們需要看key_len這個字段,我們知道utf8編碼的一個字符3個字節,而我們使用的數據類型是char(2),占兩個字節,索引就是2*3等于6個字節,所以只有一個索引起到了作用。
EXPLAIN SELECT * FROM t_index WHERE b = 'b2' \G;
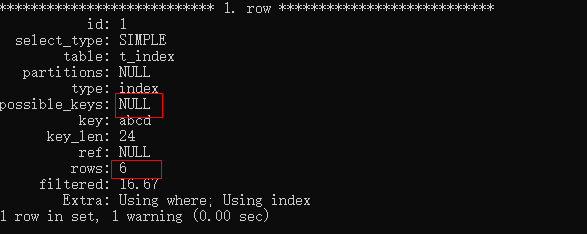
這個語句我們可以看出,這個沒有使用索引,因為possible_keys為空,而且,從查詢的行數rows可以看出為6(我們測試數據總共6條),說明進行了全盤掃描的,說明這種情況是不符合最左匹配原則,所以不會使用索引查詢。
EXPLAIN SELECT * FROM t_index WHERE a = 'a2' AND b = 'b2' ORDER BY d \G;
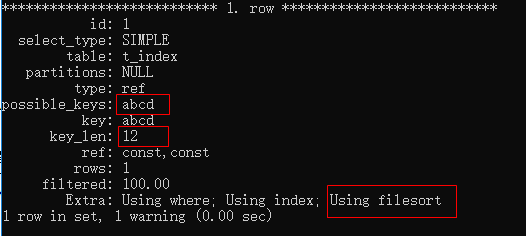
這種情況又有點不一樣了,我們使用了一個排序,可以看出使用了索引,通過key_len為12可以得到使用了2個索引a、b,另外在Extra選項中可以看到使用了Using filesort,也就是文件排序,這里使用文件排序的原因是這樣的:上面的查詢使用了a、b索引,但是當我們用d字段來排序時,(a,d)或者(b,d)這兩個索引是沒有排序的,聯合索引的使用有一個好處,就是索引的下一個字段是會自動排序的,在這里的這種情況來說,c字段就是排序的,但是d是不會,如果我們用c來排序就會得到不一樣的結果。
EXPLAIN SELECT * FROM t_index WHERE a = 'a2' AND b = 'b2' ORDER BY c \G;
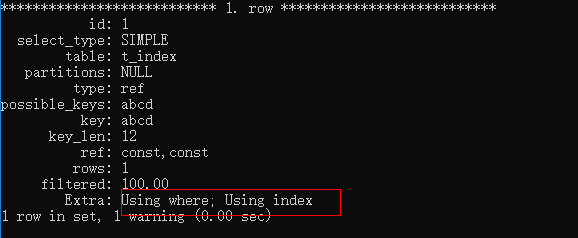
是不是可以看到,當我們用c進行排序的時候,因為使用了a、b索引,所以c就自動排序了,所以也就不用filesort了。
講到這里,我相信通過上面的幾個例子,對于聯合索引的相關知識已經非常的透徹清晰了,最后,我們再來聊幾個常見的問題。
Q1:為什么不對表中的每一個列創建一個索引呢
第一,創建索引和維護索引要耗費時間,這種時間隨著數據量的增加而增加。
第二,索引需要占物理空間,除了數據表占數據空間之外,每一個索引還要占一定的物理空間,如果要建立聚簇索引,那么需要的空間就會更大。
第三,當對表中的數據進行增加、刪除和修改的時候,索引也要動態的維護,這樣就降低了數據的維護速度。
Q2:為什么需要使用聯合索引
減少開銷。建一個聯合索引(col1,col2,col3),實際相當于建了(col1),(col1,col2),(col1,col2,col3)三個索引。每多一個索引,都會增加寫操作的開銷和磁盤空間的開銷。對于大量數據的表,使用聯合索引會大大的減少開銷!
覆蓋索引。對聯合索引(col1,col2,col3),如果有如下的sql: select col1,col2,col3 from test where col1=1 and col2=2。那么MySQL可以直接通過遍歷索引取得數據,而無需回表,這減少了很多的隨機io操作。減少io操作,特別的隨機io其實是dba主要的優化策略。所以,在真正的實際應用中,覆蓋索引是主要的提升性能的優化手段之一。
效率高。索引列越多,通過索引篩選出的數據越少。有1000W條數據的表,有如下sql:select from table where col1=1 and col2=2 and col3=3,假設假設每個條件可以篩選出10%的數據,如果只有單值索引,那么通過該索引能篩選出1000W10%=100w條數據,然后再回表從100w條數據中找到符合col2=2 and col3= 3的數據,然后再排序,再分頁;如果是聯合索引,通過索引篩選出1000w10% 10% *10%=1w,效率提升可想而知!
覆蓋索引
覆蓋索引是一種從輔助索引中就可以得到查詢的記錄,而不需要查詢聚集索引中的記錄,使用覆蓋索引的一個好處是輔助索引不包含整行記錄的所有信息,所以大小遠小于聚集索引,因此可以大大減少IO操作。覆蓋索引的另外一個好處就是對于統計問題有優化,我們看下面的一個例子。
explain select count(*) from t_index \G;
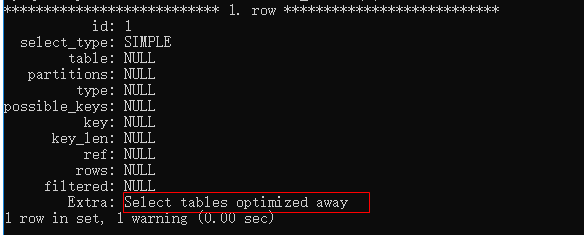
如果是myisam引擎,Extra列會輸出Select tables optimized away語句,myisam引擎已經保存了記錄的總數,直接返回結果,就不需要覆蓋索引優化了。
如果是InnoDB引擎,Extra列會輸出Using index語句,說明InnoDB引擎優化器使用了覆蓋索引操作。
2.2 索引提示
MySQL數據庫支持索引提示功能,索引提示功能就是我們可以顯示的告訴優化器使用哪個索引,一般有下面兩種情況可能使用到索引提示功能(INDEX HINT):
MySQL數據庫的優化器錯誤的選擇了某個索引,導致SQL運行很慢
某SQL語句可以選擇的索引非常的多,這時優化器選擇執行計劃時間的開銷可能會大于SQL語句本身。
這里我們接著上面的例子來講解,首先,我們先為上面的t_index表添加幾個索引;
alter table t_index add index a (a); alter table t_index add index b (b); alter table t_index add index c (c);
接著,我們執行下面的語句;
EXPLAIN SELECT * FROM t_index WHERE a = 'a' AND b = 'b' AND c = 'c' \G;
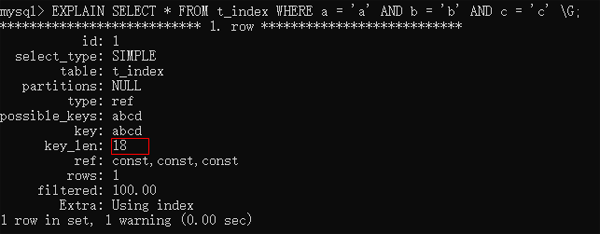
你會發現這條語句就可以使用三個索引,這個時候,我們可以顯示的使用索引提示來使用a這個索引,如下:
EXPLAIN SELECT * FROM t_index USE INDEX(a) WHERE a = 'a' AND b = 'b' AND c = 'c' \G;
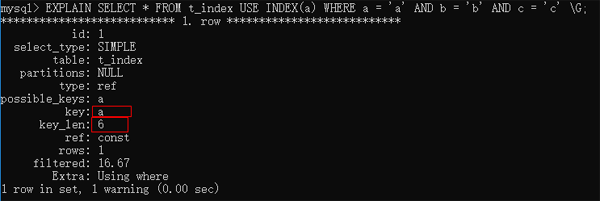
這樣就顯示的使用索引a了,如果這種方式有時候優化器還是沒有選擇你想要的索引,那么,我們可以另外一種方式FORCE INDEX。
EXPLAIN SELECT * FROM t_index FORCE INDEX(a) WHERE a = 'a' AND b = 'b' AND c = 'c' \G;
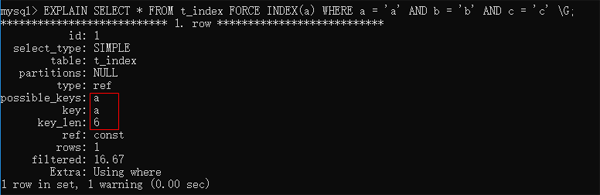
這種方式則一定會選擇你想要的索引。
2.3 索引優化
Multi-Range Read 優化
MySQL5.6開始支持,這種優化的目的是為了減少磁盤的隨機訪問,并且將隨機訪問轉化為較為順序的數據訪問,這種優化適用于range、ref、eq_ref類型的查詢。
Multi-Range Read 優化的好處:
讓數據訪問變得較為順序。
減少緩沖區中頁被替換的次數。
批量處理對鍵值的查詢操作。
我們可以使用參數optimizer_switch中的標記來控制是否開啟Multi-Range Read 優化。下面的方式將設置為總是開啟狀態:
SET @@optimizer_switch='mrr=on,mrr_cost_based=off';
Index Condition Pushdown(ICP) 優化
這種優化方式也是從MySQL5.6開始支持的,不支持這種方式之前,當進行索引查詢時,首先我們先根據索引查找記錄,然后再根據where條件來過濾記錄。然而,當支持ICP優化后,MySQL數據庫會在取出索引的同時,判斷是否可以進行where條件過濾,也就是將where過濾部分放在了存儲引擎層,大大減少了上層SQL對記錄的索取。
ICP支持range、ref、eq_ref、ref_or_null類型的查詢,當前支持MyISAM和InnoDB存儲引擎。
我們可以使用下面語句開啟ICP:
set @@optimizer_switch = "index_condition_pushdown=on"
或者關閉:
set @@optimizer_switch = "index_condition_pushdown=off"
當開啟了ICP之后,在執行計劃Extra可以看到Using index condition提示。
3 索引的特點、優點、缺點及適用場景
索引的特點
可以加快數據庫的檢索速度
降低數據庫插入、修改、刪除等維護的速度
只能創建在表上,不能創建在視圖上
既可以直接創建也可以間接創建
索引的優點
創建唯一性索引,保證數據庫表中的每一行數據的唯一性
大大加快數據的檢索速度
加快數據庫表之間的連接,特別是在實現數據的參考完整性方面特別有意義
在使用分組和排序字句進行數據檢索時,同樣可以顯著減少查詢的時間
通過使用索引,可以在查詢中使用優化隱藏器,提高系統性能
索引的缺點
第一,創建索引和維護索引要耗費時間,這種時間隨著數據量的增加而增加。
第二,索引需要占物理空間,除了數據表占數據空間之外,每一個索引還要占一定的物理空間,如果要建立聚簇索引,那么需要的空間就會更大。
第三,當對表中的數據進行增加、刪除和修改的時候,索引也要動態的維護,這樣就降低了數據的維護速度。
索引的適用場景
匹配全值
對索引中所有列都指定具體值,即是對索引中的所有列都有等值匹配的條件。
匹配值的范圍查詢
對索引的值能夠進行范圍查找。
匹配最左前綴
僅僅使用索引中的最左邊列進行查詢,比如在 col1 + col2 + col3 字段上的聯合索引能夠被包含 col1、(col1 + col2)、(col1 + col2 + col3)的等值查詢利用到,可是不能夠被 col2、(col2、col3)的等值查詢利用到。
最左匹配原則可以算是 MySQL 中 B-Tree 索引使用的首要原則。
僅僅對索引進行查詢
當查詢的列都在索引的字段中時,查詢的效率更高,所以應該盡量避免使用 select *,需要哪些字段,就只查哪些字段。
匹配列前綴
僅僅使用索引中的第一列,并且只包含索引第一列的開頭一部分進行查找。
能夠實現索引匹配部分精確而其他部分進行范圍匹配
如果列名是索引,那么使用 column_name is null 就會使用索引,例如下面的就會使用索引:
explain select * from t_index where a is null \G
經常出現在關鍵字order by、group by、distinct后面的字段
在union等集合操作的結果集字段
經常用作表連接的字段
考慮使用索引覆蓋,對數據很少被更新,如果用戶經常值查詢其中你的幾個字段,可以考慮在這幾個字段上建立索引,從而將表的掃描變為索引的掃描
索引失效情況
以%開頭的 like 查詢不能利用 B-Tree 索引,執行計劃中 key 的值為 null 表示沒有使用索引
數據類型出現隱式轉換的時候也不會使用索引,例如,where 'age'+10=30
對索引列進行函數運算,原因同上
正則表達式不會使用索引
字符串和數據比較不會使用索引
復合索引的情況下,假如查詢條件不包含索引列最左邊部分,即不滿足最左原則 leftmost,是不會使用復合索引的
如果 MySQL 估計使用索引比全表掃描更慢,則不使用索引
用 or 分割開的條件,如果 or 前的條件中的列有索引,而后面的列中沒有索引,那么涉及的索引都不會被用到
使用負向查詢(not ,not in, not like ,<> ,!= ,!> ,!< ) 不會使用索引
看完上述內容,你們對如何解析MySQL索引問題有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





