溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Hadoop HDFS怎么安裝使用”,在日常操作中,相信很多人在Hadoop HDFS怎么安裝使用問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Hadoop HDFS怎么安裝使用”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
一、HDFS基本原理
HDFS(Hadoop Distribute File System)是一個分布式文件系統,是Hadoop的重要成員。
1、文件系統的問題
文件系統是操作系統提供的磁盤空間管理服務,只需要我們制定把文件放到哪兒,從哪個路徑讀取文件就可以了,不用關心文件在磁盤上是如何存放的。
當文件所需空間大于本機磁盤空間時,如何處理呢?
一是加磁盤,但是加到一定程度就有限制了;二是加機器,用遠程共享目錄的方式提供網絡化的存儲,這種方式可以理解為分布式文件系統的雛形,可以把不同文件放入不同的機器中,空間不足了可繼續加機器,突破了存儲空間的限制。但這個方式有多個問題:
單機負載可能極高例如某個文件是熱門,很多用戶經常讀取這個文件,就使得次文件所在機器的訪問壓力極高。
數據不安全如果某個文件所在的機器出現故障,這個文件就不能訪問了,可靠性很差。
文件整理困難例如想把一些文件的存儲位置進行調整,就需要看目標機器的空間是否夠用,并且需要自己維護文件位置,如果機器非常多,操作就極為復雜。
2、HDFS的解決思路
HDFS是個抽象層,底層依賴很多獨立的服務器,對外提供統一的文件管理功能,對于用戶來講,感覺就像在操作一臺機器,感受不到HDFS下面的多臺服務器。
例如用戶訪問HDFS中的/a/b/c.mpg這個文件,HDFS負責從底層相應服務器中讀取,然后返回給用戶,這樣用戶只需和HDFS打交道,不關心這個文件是怎么存儲的。
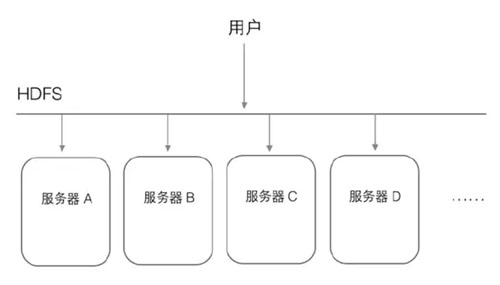
例如用戶需要保存一個文件/a/b/xxx.avi。
HDFS首先會把這個文件進行分割,例如分為4塊,然后分別放到不同服務器上。
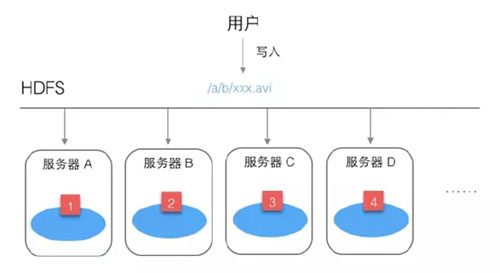
這樣做有個好處,不怕文件太大,并且讀文件的壓力不會全部集中在一臺服務器上。但如果某臺服務器壞了,文件就讀不全了。
HDFS為保證文件可靠性,會把每個文件塊進行多個備份:
塊1:A B C
塊2:A B D
塊3:B C D
塊4:A C D
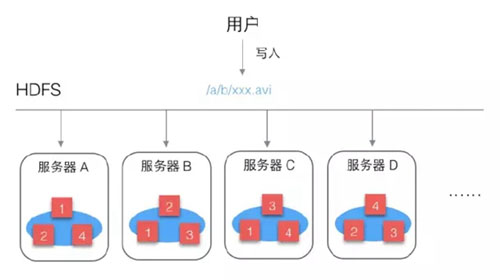
這樣文件的可靠性就大大增強了,即使某個服務器壞了,也可以完整讀取文件。
同時還帶來一個很大的好處,就是增加了文件的并發訪問能力,比如多個用戶讀取這個文件時,都要讀塊1,HDFS可以根據服務器的繁忙程度,選擇從那臺服務器讀塊1。
3、元數據的管理
HDFS中存了哪些文件?
文件被分成了哪些塊?
每個塊被放在哪臺服務器上?
……
這些都叫做元數據,這些元數據被抽象為一個目錄樹,記錄了這些復雜的對應關系。這些元數據由一個單獨的模塊進行管理,這個模塊叫做NameNode。存放文件塊的真實服務器叫做DataNode,所以用戶訪問HDFS的過程可以理解為:
用戶-> HDFS -> NameNode -> DataNode
4、HDFS優點
容量可以線性擴展
有副本機制,存儲可靠性高,吞吐量增大
有了NameNode后,用戶訪問文件只需指定HDFS上的路徑
二、HDFS實踐
經過上面介紹,可以對HDFS有個基本的了解,下面開始進行實際操作,在實踐中更好的認識HDFS。
1、安裝實踐環境
您可以選擇自己搭建環境,也可以使用打包好的Hadoop環境(版本2.7.3)
這個Hadoop環境實際上是一個虛機鏡像,所以需要安裝virtualbox虛擬機、vagrant鏡像管理工具,和我的Hadoop鏡像,然后用這個鏡像啟動虛機就可以了,下面是具體操作步驟:
1)安裝virtualbox
下載地址:https://www.virtualbox.org/wiki/Downloads
2)安裝vagrant
因為官網下載較慢,我上傳到了云盤
Windows版
鏈接: https://pan.baidu.com/s/1pKKQGHl
密碼: eykr
Mac版
鏈接: https://pan.baidu.com/s/1slts9yt
密碼: aig4
安裝完成后,在命令行終端下就可以使用vagrant命令。
3)下載Hadoop鏡像
鏈接: https://pan.baidu.com/s/1bpaisnd
密碼: pn6c
4)啟動
加載Hadoop鏡像
vagrant box add {自定義鏡像名稱} {鏡像所在路徑}
例如您想命名為Hadoop,鏡像下載后的路徑為d:\hadoop.box,加載命令就是這樣:
vagrant box add hadoop d:\hadoop.box
創建工作目錄,例如d:\hdfstest。
進入此目錄,初始化
cd d:\hdfstest vagrant init hadoop
啟動虛機
vagrant up
啟動完成后,就可以使用SSH客戶端登錄虛機了
IP 127.0.0.1
端口 2222
用戶名 root
密碼 vagrant
登錄后使用命令ifconfig 查看本虛機的IP(如192.168.31.239),可以使用此IP和端口22登錄了
IP 192.168.31.239
端口 22
用戶名 root
密碼 vagrant
Hadoop服務器環境搭建完成。
2、Shell命令行操作
登錄Hadoop服務器后,先啟動HDFS,執行命令:
start-dfs.sh
查看幫助
hdfs dfs –help
顯示目錄信息
-ls 后面是要查看的目錄路徑
創建目錄
創建目錄/test
hdfs dfs -mkdir /test
一次創建多級目錄/aa/bb
hdfs dfs -mkdir -p /aa/bb
上傳文件
形式
hdfs dfs -put {本地路徑} {hdfs中的路徑}
實例(先創建好一個測試文件mytest.txt,內容隨意,然后上傳到/test)
hadoop fs -put ~/mytest.txt /test
顯示文件內容
hdfs dfs -cat /test/mytest.txt
下載文件
hdfs dfs -get /test/mytest.txt ./mytest2.txt
合并下載
先創建2個測試文件(log.access, log.error),內容隨意,使用-put上傳到/test目錄下
hdfs dfs -put log.* /test
然后把2個log文件合并下載到一個文件中
hdfs dfs -getmerge /test/log.* ./log
查看本地log文件內容,應該包含log.access與log.error兩個文件的內容。
復制
從HDFS的一個路徑拷貝HDFS的另一個路徑
hdfs dfs -cp /test/mytest.txt /aa/mytest.txt.2
驗證
hdfs dfs -ls /aa
移動文件
hdfs dfs -mv /aa/mytest.txt.2 /aa/bb
驗證
hdfs dfs -ls /aa/bb
應列出mytest.txt.2。
刪除
hdfs dfs -rm -r /aa/bb/mytest.txt.2
使用-r參數可以一次刪除多級目錄。
驗證
hdfs dfs -ls /aa/bb
應為空
修改文件權限
與Linux文件系統中的用法一樣,修改文件所屬權限
-chgrp -chmod -chown
示例
hdfs dfs -chmod 666 /test/mytest.txt hdfs dfs -chown someuser:somegrp /test/mytest.txt
統計文件系統的可用空間
hdfs dfs -df -h /
統計文件夾的大小
hdfs dfs -du -s -h /test
3、Java API操作
(1)環境配置
因為需要在本機鏈接Hadoop虛機服務器,所以需要配置Hadoop,使其可以被外部訪問。
先登錄Hadoop虛機服務器,然后:
1)查看本機IP
ip address
例如IP為:192.168.31.239
2)修改文件:
vi /usr/local/hadoop-2.7.3/etc/hadoop/core-site.xml fs.defaultFS hdfs://localhost:9000
把其中的localhost:9000修改為本機IP 192.168.31.239:9000
3)重新啟動HDFS
#停止
stop-dfs.sh
#啟動
start-dfs.sh
(2)搭建開發環境
1)新建項目目錄hdfstest
2)在項目目錄下創建pom.xml
內容:

3)創建源碼目錄src/main/java
現在項目目錄結構
├── pom.xml !"" src │ └── main │ └── java
(3)示例代碼
查看文件列表ls
1)新建文件src/main/java/Ls.java
列出/下的文件列表,及遞歸獲取所有文件


2)編譯執行
mvn compile mvn exec:java -Dexec.mainClass="Ls" -Dexec.cleanupDaemonThreads =false
創建目錄mkdir
在HDFS中創建目錄/mkdir/a/b
1)新建文件
src/main/java/Mkdir.java


2)編譯執行
mvn compile mvn exec:java -Dexec.mainClass="Mkdir" -Dexec.cleanupDaemonThre ads=false
3)在服務器中使用HDFS命令驗證
hdfs dfs -ls /mkdir
上傳文件put
在當前項目目錄下新建測試文件,上傳到HDFS中的/mkdir
1)在項目目錄下創建測試文件testfile.txt,內容隨意
2)新建文件src/main/java/Put.java
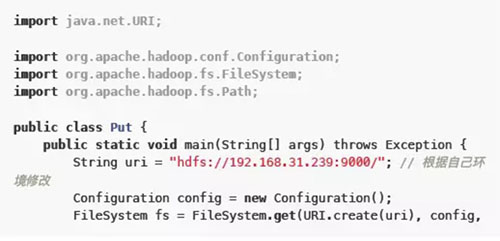
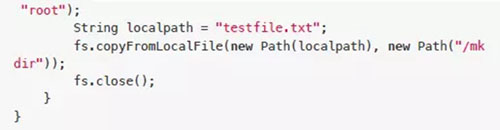
3)編譯執行
mvn compile mvn exec:java -Dexec.mainClass="Put" -Dexec.cleanupDaemonThread s=false
4)在服務器中使用HDFS命令驗證
hdfs dfs -ls /mkdir hdfs dfs -cat /mkdir/testfile.txt
下載文件get
1)新建文件src/main/java/Get.java
把HDFS中/mkdir/test?le.txt下載到當前項目目錄下

2)編譯執行
mvn compile mvn exec:java -Dexec.mainClass="Get" -Dexec.cleanupDaemonThread s=false
3)查看項目目錄下是否存在test?le2.txt及其內容
刪除文件delete
刪除HDFS上之前上傳的/mkdir/test?le.txt
1)新建文件src/main/java/Del.java
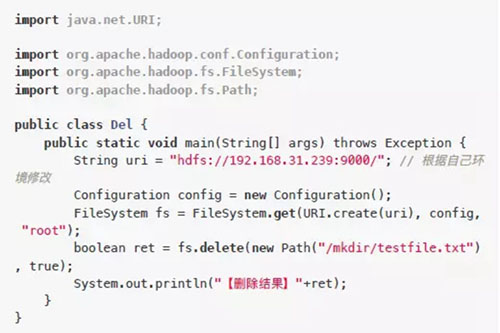
2)編譯執行
mvn compile mvn exec:java -Dexec.mainClass="Del" -Dexec.cleanupDaemonThread s=false
3)在服務器中使用HDFS命令驗證,檢查test?le.txt是否被刪除
hdfs dfs -ls /mkdir
重命名rename
把HDFS中的/mkdir/a重命名為/mkdir/a2
1)新建文件src/main/java/Rename.java
2)編譯執行
mvn compile mvn exec:java -Dexec.mainClass="Rename" -Dexec.cleanupDaemonThr eads=false
3)在服務器中使用HDFS命令驗證
hdfs dfs -ls /mkdir
流方式讀取文件部分內容
上傳一個文本文件,然后使用流方式讀取部分內容保存到當前項目目錄。
1)在服務器中創建一個測試文件test.txt,內容:
123456789abcdefghijklmn
上傳到HDFS
hdfs dfs -put test.txt /
2)在本地項目中新建文件src/main/java/StreamGet.java
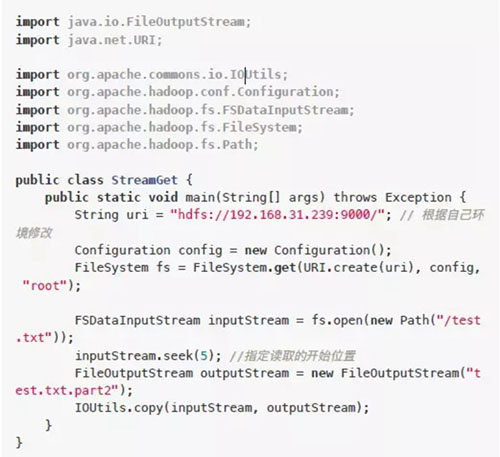
2)編譯執行
mvn compile mvn exec:java -Dexec.mainClass="StreamGet" -Dexec.cleanupDaemon Threads=false
3)執行后查看項目目錄下的test.txt.part2
6789abcdefghijklmn
前面的12345已經被略過
三、深入了解
1、寫入機制
向HDFS中寫入文件時,是按照塊兒為單位的,client會根據配置中設置的塊兒的大小把目標文件切為多塊,例如文件是300M ,配置中塊大小值為128M,那么就分為3塊兒。
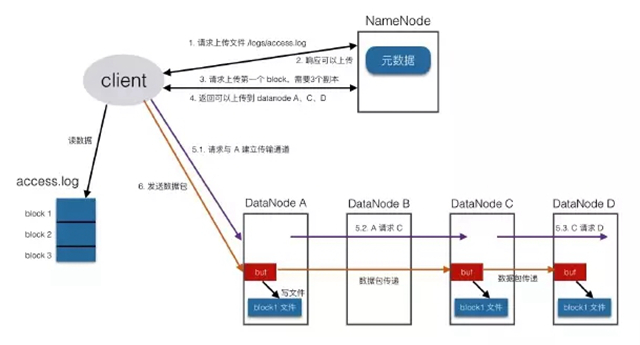
具體寫入流程:
client向namenode發請求,說想要上傳文件
namenode會檢查目標文件是否存在、父目錄是否存在,檢查沒有問題后返回確認信息
client再發請求,問***個block應該傳到哪些datanode上
namenode經過衡量,返回3個可用的datanode(A,B,C)
client與A建立連接,A與B建立連接,B與C建立連接,形成一個pipeline
傳輸管道建立完成后,client開始向A發送數據包,此數據包會經過管道一次傳遞到B和C
當***個block的數據都傳完以后,client再向namenode請求第二個block上傳到哪些datanode,然后建立傳輸管道發送數據
就這樣,直到client把文件全部上傳完成
2、讀取機制
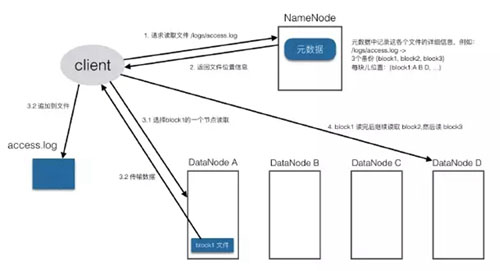
Client把要讀取的文件路徑發給namenode,查詢元數據,找到文件塊所在的datanode服務器
Client直到了文件包含哪幾塊兒、每一塊兒在哪些datanode上,就選擇那些離自己進的datanode(在同一機房,如果有多個離著近的,就隨機選擇),請求簡歷socket流
從datanode獲取數據
Client接收數據包,先本地緩存,然后寫入目標文件
直到文件讀取完成
3、NameNode機制
通過對HDFS讀寫流程的了解,可以發現namenode是一個很重要的部分,它記錄著整個HDFS系統的元數據,這些元數據是需要持久化的,要保存到文件中。
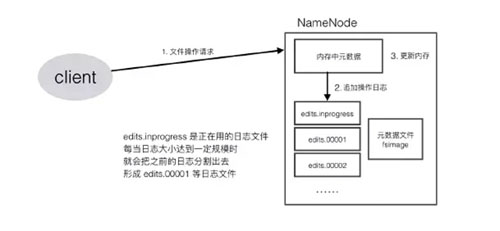
Namenode還要承受巨大的訪問量,client讀寫文件時都需要請求namenode,寫文件時要修改元數據,讀文件時要查詢元數據。
為了提高效率,namenode便將元數據加載到內存中,每次修改時,直接修改內存,而不是直接修改文件,同時會記錄下操作日志,供后期修改文件時使用。
這樣,namenode對數據的管理就涉及到了3種存儲形式:
內存數據
元數據文件
操作日志文件
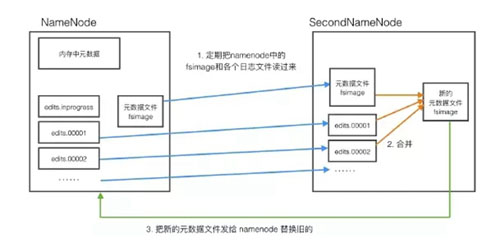
namenode需要定期對元數據文件和日志文件進行整合,以保證文件中數據是新的,但這個過程很消耗性能,namenode需要快速地響應client的大量請求,很難去完成文件整合操作,這時就引入了一個小助手secondnamenode。
secondnamenode會定期從namenode中下載元數據文件和操作日志,進行整合,形成新的數據文件,然后傳回namenode,并替換掉之前的舊文件。
secondnamenode是namenode的好幫手,替namenode完成了這個重體力活兒,并且還可以作為namenode的一個防災備份,當namenode數據丟失時,secondnamenode上有最近一次整理好的數據文件,可以傳給namenode進行加載,這樣可以保證最少的數據丟失。
到此,關于“Hadoop HDFS怎么安裝使用”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





