溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關MapReduce+HDFS海量數據去重的策略有哪些,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
隨著存儲數據信息量的飛速增長,越來越多的人開始關注存儲數據的縮減方法。數據壓縮、單實例存儲和重復數據刪除等都是經常使用的存儲數據縮減技術。
重復數據刪除往往是指消除冗余子文件。不同于壓縮,重復數據刪除對于數據本身并沒有改變,只是消除了相同的數據占用的存儲容量。重復數據刪除在減少存儲、降低網絡帶寬方面有著顯著的優勢,并對擴展性有所幫助。
舉個簡單的例子:在專門為電信運營商定制的呼叫詳單去重應用程序中,我們就可以看到刪除重復數據的影子。同樣的,對于包含相同數據包的通信網絡,我們可以使用這種技術來進行優化。
在存儲架構中,刪除重復數據的一些常用的方法包括:哈希、二進制比較和增量差分。在HadoopSphere這篇文章中,將專注于如何利用MapReduce和HDFS來消除重復的數據。(下面列出的方法中包括一些學者的實驗方法,因此把術語定義為策略比較合適)。
策略1:只使用HDFS和MapReduce
Owen O’Malley在一個論壇的帖子中建議使用以下方法:
讓你的歷史數據按照MD5值進行排序。 運行一個MapReduce的作業,將你的新數據按照MD5進行排序。需要注意的是:你要做所有數據的整體排序,但因為MD5是在整個密鑰空間中是均勻分布的,排序就變得很容易。
基本上,你挑選一個reduce作業的數量(如256),然后取MD5值的前N位數據來進行你的reduce作業。由于這項作業只處理你的新數據,這是非常快的。 接下來你需要進行一個map-side join,每一個合并的輸入分塊都包含一個MD5值的范圍。RecordReader讀取歷史的和新的數據集,并將它們按照一定方式合并。(你可以使用map-side join庫)。你的map將新數據和舊數據合并。這里僅僅是一個map作業,所以這也非常快。
當然,如果新的數據足夠小,你可以在每一個map作業中將其讀入,并且保持新記錄(在RAM中做了排序)在合適的數量范圍內,這樣就可以在RAM中執行合并。這可以讓你避免為新數據進行排序的步驟。類似于這種合并的優化,正是Pig和Hive中對開發人員隱藏的大量細節部分。
策略2:使用HDFS和Hbase
在一篇名為“工程云系統中一種新穎的刪除重復數據技術”的論文中,Zhe Sun, Jun Shen, Jianming Young共同提出了一種使用HDFS和Hbase的方法,內容如下:
使用MD5和SHA-1哈希函數計算文件的哈希值,然后將值傳遞給Hbase
將新的哈希值與現有的值域比較,如果新值已經存在于Hbase去重復表中,HDFS會檢查鏈接的數量,如果數量不為零時,哈希值對應的計數器將增加1。如果數量是零或哈希值在之前的去重復表中不存在,HDFS會要求客戶端上傳文件并更新文件的邏輯路徑。
HDFS將存儲由用戶上傳的源文件,以及相應的鏈接文件,這些鏈接文件是自動生成的。鏈接文件中記錄了源文件的哈希值和源文件的邏輯路徑。
要注意使用這種方法中的一些關鍵點:
文件級的重復數據刪除需要保持索引數量盡可能小,這樣可以有高效的查找效率。
MD5和SHA-1需要結合使用從而避免偶發性的碰撞。
策略3:使用HDFS,MapReduce和存儲控制器
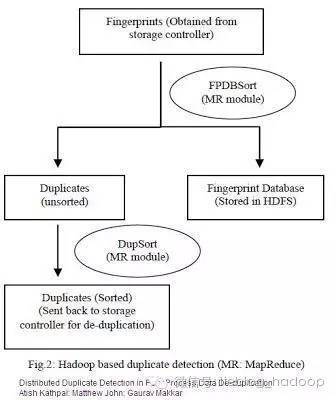
由Netapp的工程師AshishKathpal、GauravMakkar以及Mathew John三人聯合,在一篇名為“在后期處理重復數據刪除的分布式重復檢測方式”的文章中,提出通過使用HadoopMapReduce的重復檢測機制來替代Netapp原有的重復檢測環節,文中提到的基于重復檢測的Hadoop工作流包含如下幾個環節:
將數據指紋(Fingerprint)由存儲控制器遷移到HDFS
生成數據指紋數據庫,并在HDFS上***存儲該數據庫
使用MapReduce從數據指紋記錄集中篩選出重復記錄,并將去重復后的數據指紋表保存回存儲控制器。
數據指紋是指存儲系統中文件塊經過計算后的哈希索引,通常來說數據指紋要比它代表的數據塊體積小的多,這樣就可以減少分布式檢測時網絡中的數據傳輸量。
策略4:使用Streaming,HDFS,MapReduce
對于Hadoop和Streaming的應用集成,基本上包含兩種可能的場景。以IBM Infosphere Streams和BigInsights集成為例,場景應該是:
1. Streams到Hadoop的流程:通過控制流程,將Hadoop MapReduce模塊作為數據流分析的一部分,對于Streams的操作需要對更新的數據進行檢查并去重,并可以驗證MapReduce模型的正確性。
眾所周知,在數據攝入的時候對數據進行去重復是最有效的,因此在Infosphere Streams中對于某個特定時間段或者數量的記錄會進行去重復,或者識別出記錄的增量部分。接著,經過去重的數據將會發送給Hadoop BigInsights用于新模型的建立。

2. Hadoop到Streams的流程:在這種方式中,Hadoop MapReduce用于移除歷史數據中的重復數據,之后MapReduce模型將會更新。MapReduce模型作為Streams中的一部分被集成,針對mid-stream配置一個操作符(operator),從而對傳入的數據進行處理。
策略5:結合塊技術使用MapReduce
在萊比錫大學開發的一個原型工具Dedoop(Deduplication with Hadoop)中,MapReduce應用于大數據中的實體解析處理,到目前為止,這個工具囊括了MapReduce在重復數據刪除技術中最為成熟的應用方式。
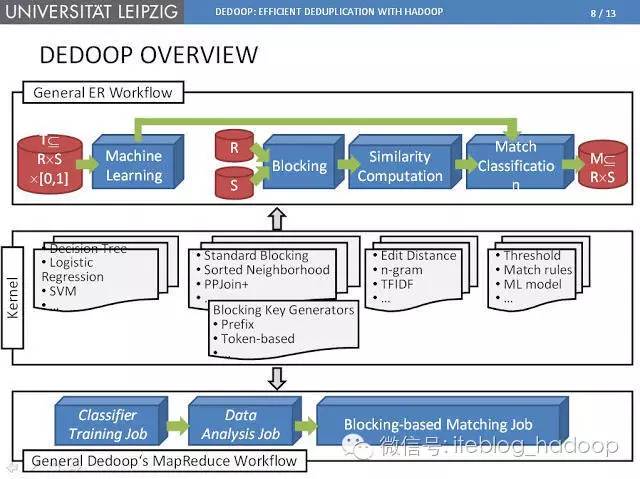
基于實體匹配的分塊是指將輸入數據按照類似的數據進行語義分塊,并且對于相同塊的實體進行限定。
實體解析處理分成兩個MapReduce作業:分析作業主要用于統計記錄出現頻率,匹配作業用于處理負載均衡以及近似度計算。另外,匹配作業采用“貪婪模式”的負載均衡調控,也就是說匹配任務按照任務處理數據大小的降序排列,并做出最小負載的Reduce作業分配。
Dedoop還采用了有效的技術來避免多余的配對比較。它要求MR程序必須明確定義出哪個Reduce任務在處理哪個配對比較,這樣就無需在多個節點上進行相同的配對比較。
關于“MapReduce+HDFS海量數據去重的策略有哪些”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





