溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了MySQL備份失敗的問題分析和處理是怎樣的,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
今天和同事一起處理了一個奇怪的MySQL空間異常問題,從這個問題的處理中可以找到一些問題處理的方式。
問題的背景是有一個實例的備份總是失敗,在排查了多次之后,在保證Slave可用的情況先擱置了,剛好借著這幾天的時間做了下收尾和梳理。
備份失敗的報錯提示信息是:
innobackupex: Error writing file '/tmp/xbtempevLQbf' (Errcode: 28 - No space left on device) xtrabackup: Error: write to logfile failed xtrabackup: Error: xtrabackup_copy_logfile() failed.
看起來多直白的問題,空間不足嘛,是不是空間配置的問題。
但是在本地進行模擬測試的時候,使用了如下的腳本開啟本機測試。
/usr/local/mysql_tools/percona-xtrabackup-2.4.8-Linux-x86_64/bin/innobackupex --defaults-file=/data/mysql_4308/my.cnf --user=xxxx --password=xxxx --socket=/data/mysql_4308/tmp/mysql.sock --stream=tar /data/xxxx/mysql/xxxx_4308/2020-02-11 > /data/xxxx/mysql/xxxx_4308/2020-02-11.tar.gz
發現所在的/tmp目錄卻沒有空間異常的情況,而相反是根目錄的空間使用出現了異常,這是測試中截取到的一個空間異常的截圖。
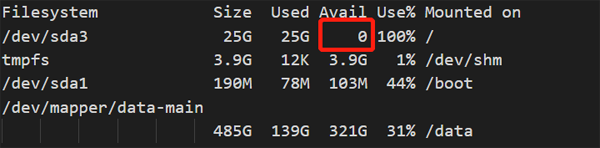
而在拋出異常之后,備份失敗,空間使用率馬上恢復。
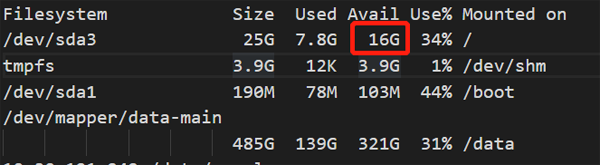
綜合目前得到的信息,我的直觀感覺是問題貌似和/tmp沒有太直接的聯系,那一定是在根目錄的使用過程中的其他目錄產生了異常。
于是我開始了第二次測試,這一次我著重關注根目錄的整體使用,看看到底是哪個目錄的使用異常了,但是尷尬的是,盡管做了腳本的快速采集,竟然沒有發現在我們常見的目錄下有空間異常。
332K ./home 411M ./lib 26M ./lib64 16K ./lost+found 4.0K ./media 4.0K ./misc 4.0K ./mnt 0 ./net 184M ./opt du: cannot access `./proc/40102/task/40102/fd/4': No such file or directory du: cannot access `./proc/40102/task/40102/fdinfo/4': No such file or directory du: cannot access `./proc/40102/fd/4': No such file or directory du: cannot access `./proc/40102/fdinfo/4': No such file or directory 0 ./proc 2.3G ./root 56K ./tmp 。。。
所以從目前的情況來看,應該是/proc相關的目錄下的空間異常了。
事情到了這個時候,似乎可用的方式已經不多了。
我排查了腳本,排查了參數文件,整體來看沒有和其他環境相比明顯的問題,但是有一個細節引起了我的注意,那就是使用top的時候,看到這個實例的內存使用了6G(服務器內存是8G),但是buffer pool的配置才是3G左右,這是一個從庫環境,也沒有應用連接,所以也不大可能存在太多的連接資源消耗,所以綜合來看,應該是和服務器的內存異常有關。
這個時候嘗試了在線resize,發現已經沒有收縮的空間了。因為是從庫服務,于是我開始重啟從庫的服務。
但是意外的是重啟數據庫的時候卡住了,大概過了有2分鐘,只是看到一些輸出的小數點,大概輸出了兩行,還是沒有反應,查看后臺日志沒有任何輸出,于是我開始嘗試plan B,準備Kill 進程重啟服務。
這一次kill操作生效了,過一會服務啟動起來了。但是報出了從庫復制異常。
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.' 。。。 Master_Server_Id: 190 Master_UUID: 570dcd0e-f6d0-11e8-adc3-005056b7e95f 。。。 Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: 200211 14:20:57 Retrieved_Gtid_Set: 570dcd0e-f6d0-11e8-adc3-005056b7e95f:821211986-2157277214 Executed_Gtid_Set: 570dcd0e-f6d0-11e8-adc3-005056b7e95f:1-820070317:821211986-2157277214
這個錯誤的信息是比較明顯了,是主庫的binlog被purge掉了,導致在從庫去復制應用的時候失敗了。
為什么會有這么奇怪的一個問題呢,因為主庫的binlog默認還是保留了一些天數,不至于把1個小時前的binlog刪除。
關于GTID的一些變量值如下:
Retrieved_Gtid_Set: 570dcd0e-f6d0-11e8-adc3-005056b7e95f:821211986-2157277214
Executed_Gtid_Set: 570dcd0e-f6d0-11e8-adc3-005056b7e95f:1-820070317:821211986-2157277214
gtid_purged : 570dcd0e-f6d0-11e8-adc3-005056b7e95f:1-820070317:821211986-2131381624
Master端的GTID_Purged為:
gtid_purged :570dcd0e-f6d0-11e8-adc3-005056b7e95f:1-2089314252
綜合這些信息來看,Slave端的GTID和主庫沒有完整的銜接起來,也就意味著在之前對這個Slave做過一些操作,導致GTID在Master和Slave端產生了一些偏差。
而這個遺漏的變更部分570dcd0e-f6d0-11e8-adc3-005056b7e95f:821211986保守來估計也是1個月以前了,binlog是肯定沒有保留的。
我們在此先暫時修復這個復制問題。
停止Slave沒想到又出問題了,一個看似簡單的stop Slave操作竟然持續了1分多鐘。
>>stop slave;
Query OK, 0 rows affected (1 min 1.99 sec)
嘗試減小Buffer pool配置,重啟,stop slave,這個操作依然很慢,所以可以在這個方向上排除延遲的問題和Buffer Pool關系不大,而相對和GTID的關系更大一些。
Slave端修復步驟如下:
reset master; stop slave; reset slave all; SET @@GLOBAL.GTID_PURGED='570dcd0e-f6d0-11e8-adc3-005056b7e95f:1-2157277214'; CHANGE MASTER TO MASTER_USER='dba_repl', MASTER_PASSWORD='xxxx' , MASTER_HOST='xxxxx',MASTER_PORT=4308,MASTER_AUTO_POSITION = 1;
其中GTID_PURGED的配置是關鍵。
修復后,Slave端的延遲問題就解決了,而再次嘗試重新備份,在根目錄竟然沒有了空間消耗。
這個過程中主要是要快速解決問題,有些步驟的日志抓取的不夠豐富和細致,從問題的分析來說,還是缺少了一些更有說服力的東西,對于問題的原因,本質上還是不合理的問題(比如bug或者配置異常等)導致了不合理的現象。
在這一塊還是可以借鑒的是分析的整體思路,而不是這個問題本身。
上述內容就是MySQL備份失敗的問題分析和處理是怎樣的,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





