溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
提高Apache Spark工作性能的技巧有哪些,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
使您的Apache Spark應用程序運行速度更快,而對代碼的更改最少!
介紹
在開發Spark應用程序時,最耗時的部分之一是優化。 在此博客文章中,我將提供一些性能提示,以及(至少對我而言)啟動時可能會使用的未知配置參數。
因此,我將介紹以下主題:
多個小文件作為源
隨機分區參數
強制廣播Join
分區vs合并vs隨機分區參數設置
我們可以改善什么?
1. 使用多個小文件?
OpenCostInBytes(來自文檔)—可以同時掃描打開文件的估計成本(以字節數衡量)。 將多個文件放入分區時使用。 最好高估一下,然后,具有較小文件的分區將比具有較大文件的分區(首先安排)更快。 默認值為4MB。
spark.conf.set("spark.files.openCostInBytes", SOME_COST_IN_BYTES)
我對包含12,000個文件的1GB文件夾,包含800個文件的7.8GB文件夾和包含1.6k個文件的18GB文件夾進行了測試。 我的目的是弄清楚輸入文件是否較小,最好使用低于默認值的文件。
因此,當測試1GB和7.8GB文件夾時-肯定是較低的值,但是測試大約11MB的文件時,較大的參數值會更好。
使用接近您的小文件大小的openCostInBytes大小。 這樣會更有效率!
2. 隨機分區
開始使用Spark時,我莫名其妙地想到了在創建Spark會話時設置的配置是不可變的。 天哪,我怎么錯。
因此,通常,在進行聚集或聯接時,spark分區在spark中是一個靜態數字(默認為200)。 根據您的數據大小,這會導致兩個問題:
數據集很小-200太多,數據分散且效率不高
數據集巨大-200太少了。 數據被浪費了,我們沒有充分利用我們想要的所有資源。
因此,在遇到此類問題時遇到了一些麻煩,我在Google上花費了很多時間,發現了這個美麗的東西
spark.conf.set("spark.sql.shuffle.partitions", X)可以在運行時中途隨時隨地更改此整潔的配置,它會影響設置后觸發的步驟。 您也可以在創建Spark會話時使用這個壞男孩。 在對聯接或聚合進行數據混排時,將使用此分區數量。 還獲得數據幀分區計數:
df.rdd.getNumPartitions()
您可以估計最合適的混搭分區數,以進行進一步的聯接和聚合。
也就是說,您有一個巨大的數據框,并且想要保留一些信息。 這樣就得到了大數據幀的分區數。 將shuffle分區參數設置為此值。 這樣一來,加入后就不會成為默認值200! 更多并行性-我們來了!
3. 廣播Join
非常簡單的情況:我們有一個龐大的表,其中包含所有用戶,而我們的表中包含內部用戶,質量檢查人員和其他不應包含在內的用戶。 目標只是離開非內部人員。
讀兩個表
Huge_table 左防聯接小表
它看起來像是一個簡單且性能明智的好解決方案。 如果您的小型表小于10MB,則您的小型數據集將在沒有任何提示的情況下進行廣播。 如果在代碼中添加提示,則可能會使它在更大的數據集上運行,但這取決于優化程序的行為。
但是,假設它是100-200MB,并且提示您不要強制廣播它。 因此,如果您確信它不會影響代碼的性能(或引發一些OOM錯誤),則可以使用它并覆蓋默認值:
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", SIZE_OF_SMALLER_DATASET)在這種情況下,它將廣播給所有執行者,并且加入應該工作得更快。
當心OOM錯誤!
4. 分區vs合并vs隨機分區配置設置
如果您使用的是Spark,則可能知道重新分區方法。 對我來說,來自SQL后臺方法合并的方式有不同的含義! 顯然,在分區上進行火花合并時,其行為方式有所不同-它移動并將多個分區組合在一起。 基本上,我們將數據改組和移動減到最少。
如果我們只需要減少分區數,則應該使用合并而不是重新分區,因為這樣可以最大程度地減少數據移動并且不會觸發交換。 如果我們想更均勻地在分區之間劃分數據,請重新分區。
但是,假設我們有一個重復出現的模式,我們執行聯接/轉換并得到200個分區,但是我們不需要200個分區,即100個甚至1個。
讓我們嘗試進行比較。 我們將讀取11MB的文件夾,并像以前一樣進行匯總。
通過將數據幀持久存儲在僅存儲選件磁盤上,我們可以估計數據幀大小。 所以small_df只有10 MB,但是分區數是200。等等? 平均每個分區可提供50KB的數據,這效率不高。 因此,我們將讀取大數據幀,并將聚合后的分區計數設置為1,并強制Spark執行,最后我們將其算作一項操作。
這是我們三種情況的執行計劃:
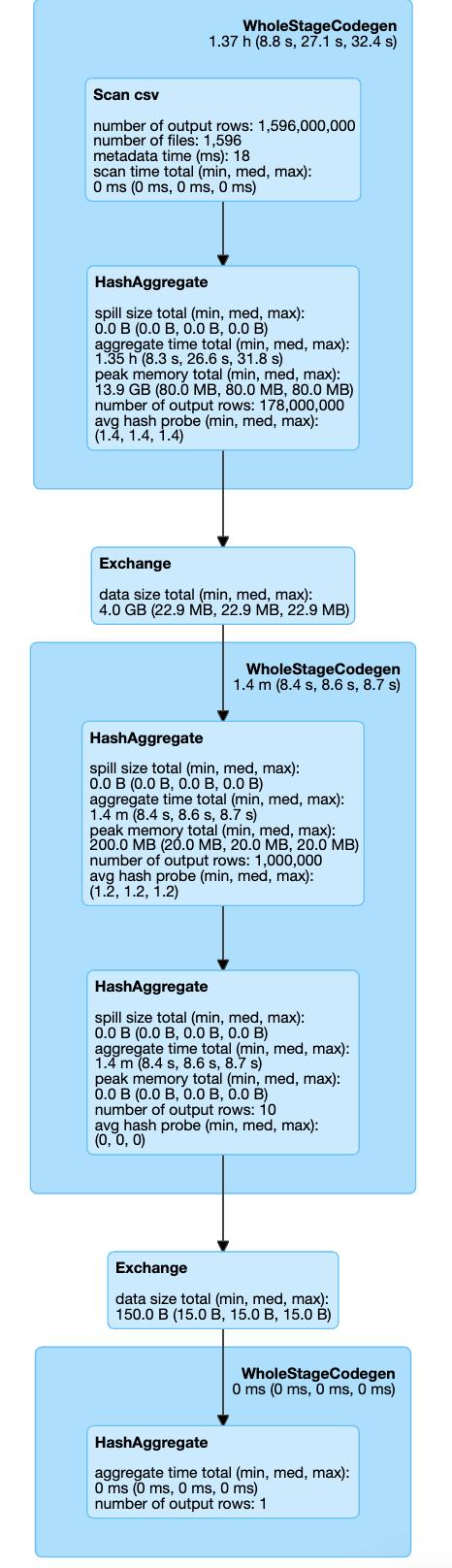
> Setting shuffle partition parameter
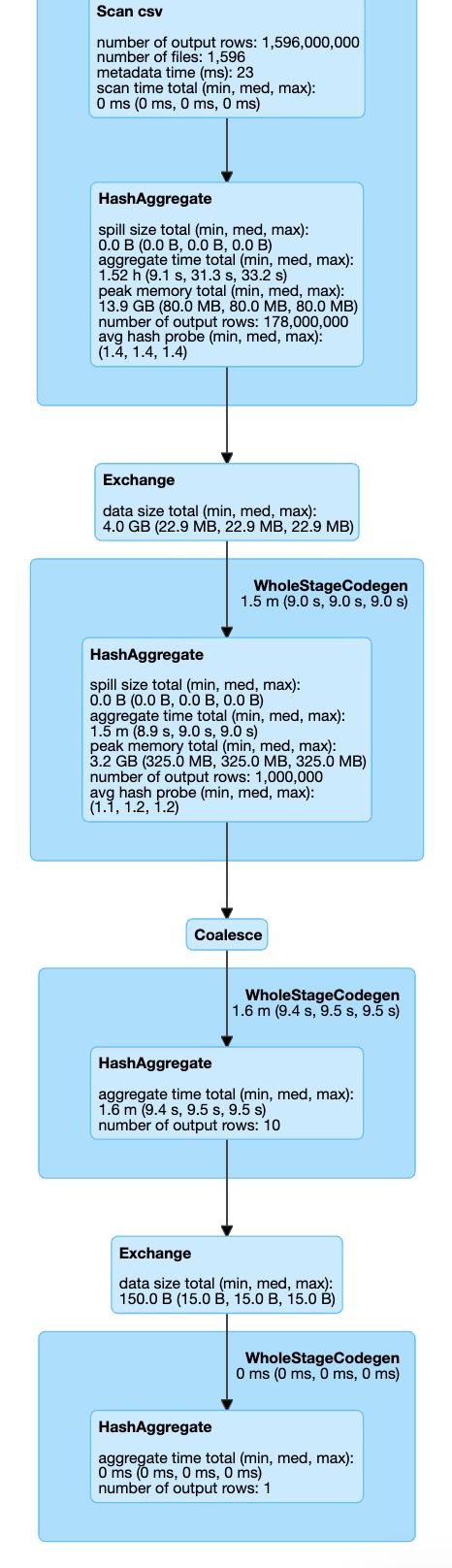
> Coalesce action
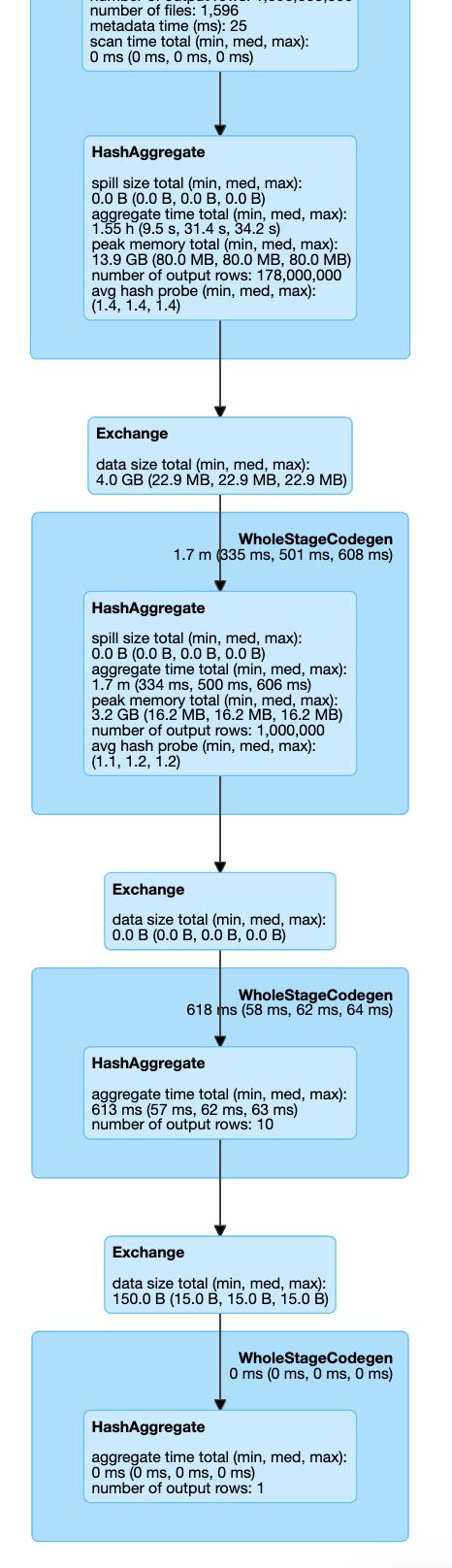
> Repartitioning
因此,在所有可見的設置中,我們不會調用Coalesce / Exchange的其他步驟(重新分區操作)。 因此,我們可以通過跳過它來節省一些執行時間。 如果我們看一下執行時間:Shuffle Partition設置在7.1分鐘,Coalesce 8.1,Repartition 8.3中完成。
這只是一個簡單的示例,它仍然顯示了通過設置一個配置參數可以節省多少時間!
關于如何使您的Apache Spark應用程序更快,更高效地運行,有許多小而簡單的技巧和竅門。 不幸的是,使用Spark時,大多數情況下解決方案都是單獨的。 為了使其正常工作,大多數時候您必須了解Spark內部組件的內幕,并從頭到尾閱讀文檔多次。
我提到了如何更快地讀取多個小文件,如何強制建議廣播連接,選擇何時使用shuffle分區參數,合并和重新分區。
看完上述內容,你們掌握提高Apache Spark工作性能的技巧有哪些的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





