溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“分庫分表的分布式主鍵ID生成方法有哪些”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“分庫分表的分布式主鍵ID生成方法有哪些”吧!
引入任何一種技術都是存在風險的,分庫分表當然也不例外,除非庫、表數據量持續增加,大到一定程度,以至于現有高可用架構已無法支撐,否則不建議大家做分庫分表,因為做了數據分片后,你會發現自己踏上了一段踩坑之路,而分布式主鍵 ID 就是遇到的第一個坑。
不同數據節點間生成全局唯一主鍵是個棘手的問題,一張邏輯表 t_order 拆分成多個真實表 t_order_n,然后被分散到不同分片庫 db_0、db_1... ,各真實表的自增鍵由于無法互相感知從而會產生重復主鍵,此時數據庫本身的自增主鍵,就無法滿足分庫分表對主鍵全局唯一的要求。
db_0-- |-- t_order_0 |-- t_order_1 |-- t_order_2 db_1-- |-- t_order_0 |-- t_order_1 |-- t_order_2
盡管我們可以通過嚴格約束,各個分片表自增主鍵的 初始值 和 步長 的方式來解決 ID 重復的問題,但這樣會讓運維成本陡增,而且可擴展性極差,一旦要擴容分片表數量,原表數據變動比較大,所以這種方式不太可取。
步長 step = 分表張數 db_0-- |-- t_order_0 ID: 0、6、12、18... |-- t_order_1 ID: 1、7、13、19... |-- t_order_2 ID: 2、8、14、20... db_1-- |-- t_order_0 ID: 3、9、15、21... |-- t_order_1 ID: 4、10、16、22... |-- t_order_2 ID: 5、11、17、23...
目前已經有了許多第三放解決方案可以完美解決這個問題,比如基于 UUID、SNOWFLAKE算法 、segment號段,使用特定算法生成不重復鍵,或者直接引用主鍵生成服務,像美團(Leaf)和 滴滴(TinyId)等。
而sharding-jdbc 內置了兩種分布式主鍵生成方案,UUID、SNOWFLAKE,不僅如此它還抽離出分布式主鍵生成器的接口,以便于開發者實現自定義的主鍵生成器,后續我們會在自定義的生成器中接入 滴滴(TinyId)的主鍵生成服務。
前邊介紹過在 sharding-jdbc 中要想為某個字段自動生成主鍵 ID,只需要在 application.properties 文件中做如下配置:
# 主鍵字段 spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id # 主鍵ID 生成方案 spring.shardingsphere.sharding.tables.t_order.key-generator.type=UUID # 工作機器 id spring.shardingsphere.sharding.tables.t_order.key-generator.props.worker.id=123
key-generator.column 表示主鍵字段,key-generator.type 為主鍵 ID 生成方案(內置或自定義的),key-generator.props.worker.id 為機器ID,在主鍵生成方案設為 SNOWFLAKE 時機器ID 會參與位運算。
在使用 sharding-jdbc 分布式主鍵時需要注意兩點:
一旦 insert 插入操作的實體對象中主鍵字段已經賦值,那么即使配置了主鍵生成方案也會失效,最后SQL 執行的數據會以賦的值為準。
不要給主鍵字段設置自增屬性,否則主鍵ID 會以默認的 SNOWFLAKE 方式生成。比如:用 mybatis plus 的 @TableId 注解給字段 order_id 設置了自增主鍵,那么此時配置哪種方案,總是按雪花算法生成。
下面我們從源碼上分析下 sharding-jdbc 內置主鍵生成方案 UUID、SNOWFLAKE 是怎么實現的。
UUID
打開 UUID 類型的主鍵生成實現類 UUIDShardingKeyGenerator 的源碼發現,它的生成規則只有 UUID.randomUUID() 這么一行代碼,額~ 心中默默來了一句臥槽。
UUID 雖然可以做到全局唯一性,但還是不推薦使用它作為主鍵,因為我們的實際業務中不管是 user_id 還是 order_id 主鍵多為整型,而 UUID 生成的是個 32 位的字符串。
它的存儲以及查詢對 MySQL 的性能消耗較大,而且 MySQL 官方也明確建議,主鍵要盡量越短越好,作為數據庫主鍵 UUID 的無序性還會導致數據位置頻繁變動,嚴重影響性能。
public final class UUIDShardingKeyGenerator implements ShardingKeyGenerator { private Properties properties = new Properties(); public UUIDShardingKeyGenerator() { } public String getType() { return "UUID"; } public synchronized Comparable<?> generateKey() { return UUID.randomUUID().toString().replaceAll("-", ""); } public Properties getProperties() { return this.properties; } public void setProperties(Properties properties) { this.properties = properties; } }SNOWFLAKE
SNOWFLAKE(雪花算法)是默認使用的主鍵生成方案,生成一個 64bit的長整型(Long)數據。
sharding-jdbc 中雪花算法生成的主鍵主要由 4部分組成,1bit符號位、41bit時間戳位、10bit工作進程位以及 12bit 序列號位。

符號位(1bit位)
Java 中 Long 型的最高位是符號位,正數是0,負數是1,一般生成ID都為正數,所以默認為0
時間戳位(41bit)
41位的時間戳可以容納的毫秒數是 2 的 41次冪,而一年的總毫秒數為 1000L * 60 * 60 * 24 * 365,計算使用時間大概是69年,額~,我有生之間算是夠用了。
Math.pow(2, 41) / (365 * 24 * 60 * 60 * 1000L) = = 69年
工作進程位(10bit)
表示一個唯一的工作進程id,默認值為 0,可通過 key-generator.props.worker.id 屬性設置。
spring.shardingsphere.sharding.tables.t_order.key-generator.props.worker.id=0000
序列號位(12bit)
同一毫秒內生成不同的ID。
時鐘回撥
了解了雪花算法的主鍵 ID 組成后不難發現,這是一種嚴重依賴于服務器時間的算法,而依賴服務器時間的就會遇到一個棘手的問題:時鐘回撥。
為什么會出現時鐘回撥呢?
互聯網中有一種網絡時間協議 ntp 全稱 (Network Time Protocol) ,專門用來同步、校準網絡中各個計算機的時間。
這就是為什么,我們的手機現在不用手動校對時間,可每個人的手機時間還都是一樣的。
我們的硬件時鐘可能會因為各種原因變得不準( 快了 或 慢了 ),此時就需要 ntp 服務來做時間校準,做校準的時候就會發生服務器時鐘的 跳躍 或者 回撥 的問題。
雪花算法如何解決時鐘回撥
服務器時鐘回撥會導致產生重復的 ID,SNOWFLAKE 方案中對原有雪花算法做了改進,增加了一個最大容忍的時鐘回撥毫秒數。
如果時鐘回撥的時間超過最大容忍的毫秒數閾值,則程序直接報錯;如果在可容忍的范圍內,默認分布式主鍵生成器,會等待時鐘同步到最后一次主鍵生成的時間后再繼續工作。
最大容忍的時鐘回撥毫秒數,默認值為 0,可通過屬性 max.tolerate.time.difference.milliseconds 設置。
# 最大容忍的時鐘回撥毫秒數 spring.shardingsphere.sharding.tables.t_order.key-generator.max.tolerate.time.difference.milliseconds=5
下面是看下它的源碼實現類 SnowflakeShardingKeyGenerator,核心流程大概如下:
最后一次生成主鍵的時間 lastMilliseconds 與 當前時間currentMilliseconds 做比較,如果 lastMilliseconds > currentMilliseconds則意味著時鐘回調了。
那么接著判斷兩個時間的差值(timeDifferenceMilliseconds)是否在設置的最大容忍時間閾值 max.tolerate.time.difference.milliseconds內,在閾值內則線程休眠差值時間 Thread.sleep(timeDifferenceMilliseconds),否則大于差值直接報異常。
/** * @author xiaofu */ public final class SnowflakeShardingKeyGenerator implements ShardingKeyGenerator{ @Getter @Setter private Properties properties = new Properties(); public String getType() { return "SNOWFLAKE"; } public synchronized Comparable<?> generateKey() { /** * 當前系統時間毫秒數 */ long currentMilliseconds = timeService.getCurrentMillis(); /** * 判斷是否需要等待容忍時間差,如果需要,則等待時間差過去,然后再獲取當前系統時間 */ if (waitTolerateTimeDifferenceIfNeed(currentMilliseconds)) { currentMilliseconds = timeService.getCurrentMillis(); } /** * 如果最后一次毫秒與 當前系統時間毫秒相同,即還在同一毫秒內 */ if (lastMilliseconds == currentMilliseconds) { /** * &位與運算符:兩個數都轉為二進制,如果相對應位都是1,則結果為1,否則為0 * 當序列為4095時,4095+1后的新序列與掩碼進行位與運算結果是0 * 當序列為其他值時,位與運算結果都不會是0 * 即本毫秒的序列已經用到最大值4096,此時要取下一個毫秒時間值 */ if (0L == (sequence = (sequence + 1) & SEQUENCE_MASK)) { currentMilliseconds = waitUntilNextTime(currentMilliseconds); } } else { /** * 上一毫秒已經過去,把序列值重置為1 */ vibrateSequenceOffset(); sequence = sequenceOffset; } lastMilliseconds = currentMilliseconds; /** * XX......XX XX000000 00000000 00000000 時間差 XX * XXXXXX XXXX0000 00000000 機器ID XX * XXXX XXXXXXXX 序列號 XX * 三部分進行|位或運算:如果相對應位都是0,則結果為0,否則為1 */ return ((currentMilliseconds - EPOCH) << TIMESTAMP_LEFT_SHIFT_BITS) | (getWorkerId() << WORKER_ID_LEFT_SHIFT_BITS) | sequence; } /** * 判斷是否需要等待容忍時間差 */ @SneakyThrows private boolean waitTolerateTimeDifferenceIfNeed(final long currentMilliseconds) { /** * 如果獲取ID時的最后一次時間毫秒數小于等于當前系統時間毫秒數,屬于正常情況,則不需要等待 */ if (lastMilliseconds <= currentMilliseconds) { return false; } /** * ===>時鐘回撥的情況(生成序列的時間大于當前系統的時間),需要等待時間差 */ /** * 獲取ID時的最后一次毫秒數減去當前系統時間毫秒數的時間差 */ long timeDifferenceMilliseconds = lastMilliseconds - currentMilliseconds; /** * 時間差小于最大容忍時間差,即當前還在時鐘回撥的時間差之內 */ Preconditions.checkState(timeDifferenceMilliseconds < getMaxTolerateTimeDifferenceMilliseconds(), "Clock is moving backwards, last time is %d milliseconds, current time is %d milliseconds", lastMilliseconds, currentMilliseconds); /** * 線程休眠時間差 */ Thread.sleep(timeDifferenceMilliseconds); return true; } // 配置的機器ID private long getWorkerId() { long result = Long.valueOf(properties.getProperty("worker.id", String.valueOf(WORKER_ID))); Preconditions.checkArgument(result >= 0L && result < WORKER_ID_MAX_VALUE); return result; } private int getMaxTolerateTimeDifferenceMilliseconds() { return Integer.valueOf(properties.getProperty("max.tolerate.time.difference.milliseconds", String.valueOf(MAX_TOLERATE_TIME_DIFFERENCE_MILLISECONDS))); } private long waitUntilNextTime(final long lastTime) { long result = timeService.getCurrentMillis(); while (result <= lastTime) { result = timeService.getCurrentMillis(); } return result; } }但從 SNOWFLAKE 方案生成的主鍵ID 來看,order_id 它是一個18位的長整型數字,是不是發現它太長了,想要 MySQL 那種從 0 遞增的自增主鍵該怎么實現呢?別急,后邊已經會給出了解決辦法!
自定義
sharding-jdbc 利用 SPI 全稱( Service Provider Interface) 機制拓展主鍵生成規則,這是一種服務發現機制,通過掃描項目路徑 META-INF/services 下的文件,并自動加載文件里所定義的類。
實現自定義主鍵生成器其實比較簡單,只有兩步。
第一步,實現 ShardingKeyGenerator 接口,并重寫其內部方法,其中 getType() 方法為自定義的主鍵生產方案類型、generateKey() 方法則是具體生成主鍵的規則。
下面代碼中用 AtomicInteger 來模擬實現一個有序自增的 ID 生成。
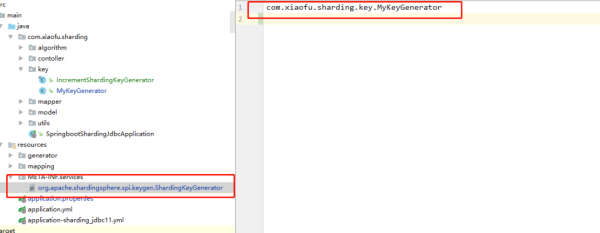
/** * @Author: xiaofu * @Description: 自定義主鍵生成器 */ @Component public class MyShardingKeyGenerator implements ShardingKeyGenerator { private final AtomicInteger count = new AtomicInteger(); /** * 自定義的生成方案類型 */ @Override public String getType() { return "XXX"; } /** * 核心方法-生成主鍵ID */ @Override public Comparable<?> generateKey() { return count.incrementAndGet(); } @Override public Properties getProperties() { return null; } @Override public void setProperties(Properties properties) { } }第二步,由于是利用 SPI 機制實現功能拓展,我們要在 META-INF/services 文件中配置自定義的主鍵生成器類路勁。
com.xiaofu.sharding.key.MyShardingKeyGenerator
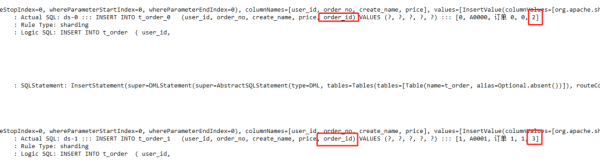
上面這些弄完我們測試一下,配置定義好的主鍵生成類型 XXX,并插入幾條數據看看效果。
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id spring.shardingsphere.sharding.tables.t_order.key-generator.type=XXX
通過控制臺的SQL 解析日志發現,order_id 字段已按照有序自增的方式插入記錄,說明配置的沒問題。
舉一反九
既然可以自定義生成方案,那么實現分布式主鍵的思路就很多了,又想到之前我寫的這篇 《9種 分布式ID生成方案》,發現可以完美兼容,這里挑選其中的 滴滴(Tinyid)來實踐一下,由于它是個單獨的分布式ID生成服務,所以要先搭建環境了。
Tinyid 的服務提供Http 和 Tinyid-client 兩種接入方式,下邊使用 Tinyid-client 方式快速使用,更多的細節到這篇文章里看吧,實在是介紹過太多次了。
Tinyid 服務搭建
先拉源代碼 https://github.com/didi/tinyid.git。
由于是基于號段模式實現的分布式ID,所以依賴于數據庫,要創建相應的表 tiny_id_info 、tiny_id_token 并插入默認數據。
CREATE TABLE `tiny_id_info` ( `id` BIGINT (20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增主鍵', `biz_type` VARCHAR (63) NOT NULL DEFAULT '' COMMENT '業務類型,唯一', `begin_id` BIGINT (20) NOT NULL DEFAULT '0' COMMENT '開始id,僅記錄初始值,無其他含義。初始化時begin_id和max_id應相同', `max_id` BIGINT (20) NOT NULL DEFAULT '0' COMMENT '當前最大id', `step` INT (11) DEFAULT '0' COMMENT '步長', `delta` INT (11) NOT NULL DEFAULT '1' COMMENT '每次id增量', `remainder` INT (11) NOT NULL DEFAULT '0' COMMENT '余數', `create_time` TIMESTAMP NOT NULL DEFAULT '2010-01-01 00:00:00' COMMENT '創建時間', `update_time` TIMESTAMP NOT NULL DEFAULT '2010-01-01 00:00:00' COMMENT '更新時間', `version` BIGINT (20) NOT NULL DEFAULT '0' COMMENT '版本號', PRIMARY KEY (`id`), UNIQUE KEY `uniq_biz_type` (`biz_type`) ) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8 COMMENT 'id信息表'; CREATE TABLE `tiny_id_token` ( `id` INT (11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增id', `token` VARCHAR (255) NOT NULL DEFAULT '' COMMENT 'token', `biz_type` VARCHAR (63) NOT NULL DEFAULT '' COMMENT '此token可訪問的業務類型標識', `remark` VARCHAR (255) NOT NULL DEFAULT '' COMMENT '備注', `create_time` TIMESTAMP NOT NULL DEFAULT '2010-01-01 00:00:00' COMMENT '創建時間', `update_time` TIMESTAMP NOT NULL DEFAULT '2010-01-01 00:00:00' COMMENT '更新時間', PRIMARY KEY (`id`) ) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8 COMMENT 'token信息表'; INSERT INTO `tiny_id_token` (`id`, `token`, `biz_type`, `remark`, `create_time`, `update_time`) VALUES ('1', '0f673adf80504e2eaa552f5d791b644c', 'order', '1', '2017-12-14 16:36:46', '2017-12-14 16:36:48'); INSERT INTO `tiny_id_info` (`id`, `biz_type`, `begin_id`, `max_id`, `step`, `delta`, `remainder`, `create_time`, `update_time`, `version`) VALUES ('1', 'order', '1', '1', '100000', '1', '0', '2018-07-21 23:52:58', '2018-07-22 23:19:27', '1');并在 Tinyid 服務中配置上邊表所在數據源信息
datasource.tinyid.primary.url=jdbc:mysql://47.93.6.e:3306/ds-0?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8 datasource.tinyid.primary.username=root datasource.tinyid.primary.password=root
最后項目 maven install ,右鍵 TinyIdServerApplication 啟動服務, Tinyid 分布式ID生成服務就搭建完畢了。
自定義 Tinyid 主鍵類型
Tinyid 服務搭建完下邊在項目中引入它,新建個 tinyid_client.properties 文件其中添加 tinyid.server 和 tinyid.token 屬性,token 為之前 SQL 預先插入的用戶數據。
# tinyid 分布式ID # 服務地址 tinyid.server=127.0.0.1:9999 # 業務token tinyid.token=0f673adf80504e2eaa552f5d791b644c
代碼中獲取 ID更簡單,只需一行代碼,業務類型 order 是之前 SQ L 預先插入的數據。
Long id = TinyId.nextId("order");我們開始自定義 Tinyid 主鍵生成類型的實現類 TinyIdShardingKeyGenerator 。
/** * @Author: xiaofu * @Description: 自定義主鍵生成器 */ @Component public class TinyIdShardingKeyGenerator implements ShardingKeyGenerator { /** * 自定義的生成方案類型 */ @Override public String getType() { return "tinyid"; } /** * 核心方法-生成主鍵ID */ @Override public Comparable<?> generateKey() { Long id = TinyId.nextId("order"); return id; } @Override public Properties getProperties() { return null; } @Override public void setProperties(Properties properties) { } }并在配置文件中啟用 Tinyid 主鍵生成類型,到此配置完畢,趕緊測試一下。
# 主鍵字段 spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id # 主鍵ID 生成方案 spring.shardingsphere.sharding.tables.t_order.key-generator.type=tinyid
測試 Tinyid 主鍵
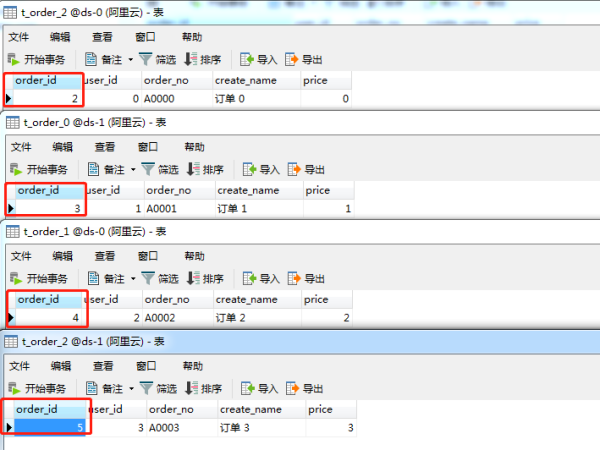
向數據庫插入訂單記錄測試發現,主鍵ID字段 order_id 已經為趨勢遞增的了, Tinyid 服務成功接入,完美!
到此,相信大家對“分庫分表的分布式主鍵ID生成方法有哪些”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





