溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“如何掌握Table與DataStream之間的互轉”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
一、將kafka作為輸入流
kafka 的連接器 flink-kafka-connector 中,1.10 版本的已經提供了 Table API 的支持。我們可以在 connect方法中直接傳入一個叫做 Kafka 的類,這就是 kafka 連接器的描述器ConnectorDescriptor。
準備數據:
1,語數 2,英物 3,化生 4,文學 5,語理 6,學物
創建kafka主題
./kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --replication-factor 2 --partitions 3 --topic FlinkSqlTest
通過命令行的方式啟動一個生產者
[root@node01 bin]# ./kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic FlinkSqlTest >1,語數 >2,英物 >3,化生 >4,文學 >5,語理\ >6,學物
編寫Flink代碼連接到kafka
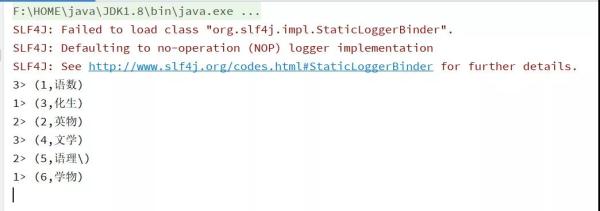
import org.apache.flink.streaming.api.scala._ import org.apache.flink.table.api.DataTypes import org.apache.flink.table.api.scala._ import org.apache.flink.table.descriptors.{Csv, Kafka, Schema} /** * @Package * @author 大數據老哥 * @date 2020/12/17 0:35 * @version V1.0 */ object FlinkSQLSourceKafka { def main(args: Array[String]): Unit = { // 獲取流處理的運行環境 val env = StreamExecutionEnvironment.getExecutionEnvironment // 獲取table的運行環境 val tableEnv = StreamTableEnvironment.create(env) tableEnv.connect( new Kafka() .version("0.11") // 設置kafka的版本 .topic("FlinkSqlTest") // 設置要連接的主題 .property("zookeeper.connect","node01:2181,node02:2181,node03:2181") //設置zookeeper的連接地址跟端口號 .property("bootstrap.servers","node01:9092,node02:9092,node03:9092") //設置kafka的連接地址跟端口號 ).withFormat(new Csv()) // 設置格式 .withSchema(new Schema() // 設置元數據信息 .field("id",DataTypes.STRING()) .field("name",DataTypes.STRING()) ).createTemporaryTable("kafkaInputTable") // 創建臨時表 //定義要查詢的sql語句 val result = tableEnv.sqlQuery("select * from kafkaInputTable ") //打印數據 result.toAppendStream[(String,String)].print() // 開啟執行 env.execute("source kafkaInputTable") } }運行結果圖
當然也可以連接到 ElasticSearch、MySql、HBase、Hive 等外部系統,實現方式基本上是類似的。
二、表的查詢
利用外部系統的連接器 connector,我們可以讀寫數據,并在環境的 Catalog 中注冊表。接下來就可以對表做查詢轉換了。Flink 給我們提供了兩種查詢方式:Table API 和 SQL。
三、Table API 的調用
Table API 是集成在 Scala 和 Java 語言內的查詢 API。與 SQL 不同,Table API 的查詢不會用字符串表示,而是在宿主語言中一步一步調用完成的。 Table API 基于代表一張表的 Table 類,并提供一整套操作處理的方法 API。這些方法會返回一個新的 Table 對象,這個對象就表示對輸入表應用轉換操作的結果。有些關系型轉換操作,可以由多個方法調用組成,構成鏈式調用結構。例如 table.select(…).filter(…) ,其中 select(…) 表示選擇表中指定的字段,filter(…)表示篩選條件。代碼中的實現如下:
val kafkaInputTable = tableEnv.from("kafkaInputTable") kafkaInputTable.select("*") .filter('id !=="1")四、SQL查詢
Flink 的 SQL 集成,基于的是 ApacheCalcite,它實現了 SQL 標準。在 Flink 中,用常規字符串來定義 SQL 查詢語句。SQL 查詢的結果,是一個新的 Table。
代碼實現如下:
val result = tableEnv.sqlQuery("select * from kafkaInputTable ")當然,也可以加上聚合操作,比如我們統計每個用戶的個數
調用 table API
val result: Table = tableEnv.from("kafkaInputTable") result.groupBy("user") .select('name,'name.count as 'count)調用SQL
val result = tableEnv.sqlQuery("select name ,count(1) as count from kafkaInputTable group by name ")這里 Table API 里指定的字段,前面加了一個單引號’,這是 Table API 中定義的 Expression類型的寫法,可以很方便地表示一個表中的字段。 字段可以直接全部用雙引號引起來,也可以用半邊單引號+字段名的方式。以后的代碼中,一般都用后一種形式。
五、將DataStream 轉成Table
Flink 允許我們把 Table 和DataStream 做轉換:我們可以基于一個 DataStream,先流式地讀取數據源,然后 map 成樣例類,再把它轉成 Table。Table 的列字段(column fields),就是樣例類里的字段,這樣就不用再麻煩地定義 schema 了。
5.1、代碼實現
代碼中實現非常簡單,直接用 tableEnv.fromDataStream() 就可以了。默認轉換后的 Table schema 和 DataStream 中的字段定義一一對應,也可以單獨指定出來。
這就允許我們更換字段的順序、重命名,或者只選取某些字段出來,相當于做了一次 map 操作(或者 Table API 的 select 操作)。
代碼具體如下:
import org.apache.flink.streaming.api.scala._ import org.apache.flink.table.api.scala._ /** * @Package * @author 大數據老哥 * @date 2020/12/17 21:21 * @version V1.0 */ object FlinkSqlReadFileTable { def main(args: Array[String]): Unit = { // 構建流處理運行環境 val env = StreamExecutionEnvironment.getExecutionEnvironment // 構建table運行環境 val tableEnv = StreamTableEnvironment.create(env) // 使用流處理來讀取數據 val readData = env.readTextFile("./data/word.txt") // 使用flatMap進行切分 val word: DataStream[String] = readData.flatMap(_.split(" ")) // 將word 轉為 table val table = tableEnv.fromDataStream(word) // 計算wordcount val wordCount = table.groupBy("f0").select('f0, 'f0.count as 'count) wordCount.printSchema() //轉換成流處理打印輸出 tableEnv.toRetractStream[(String,Long)](wordCount).print() env.execute("FlinkSqlReadFileTable") } }5.2 數據類型與 Table schema 的對應
DataStream 中的數據類型,與表的 Schema之間的對應關系,是按照樣例類中的字段名來對應的(name-based mapping),所以還可以用 as 做重命名。
另外一種對應方式是,直接按照字段的位置來對應(position-based mapping),對應的過程中,就可以直接指定新的字段名了。
基于名稱的對應:
val userTable = tableEnv.fromDataStream(dataStream,'username as 'name,'id as 'myid)
基于位置的對應:
val userTable = tableEnv.fromDataStream(dataStream, 'name, 'id)
Flink 的 DataStream 和 DataSet API 支持多種類型。組合類型,比如元組(內置 Scala 和 Java 元組)、POJO、Scala case 類和 Flink 的 Row 類型等,允許具有多個字段的嵌套數據結構,這些字段可以在 Table 的表達式中訪問。其他類型,則被視為原子類型。
元組類型和原子類型,一般用位置對應會好一些;如果非要用名稱對應,也是可以的:元組類型,默認的名稱是_1, _2;而原子類型,默認名稱是 f0。
六、創建臨時視圖(Temporary View)
創建臨時視圖的第一種方式,就是直接從 DataStream 轉換而來。同樣,可以直接對應字段轉換;也可以在轉換的時候,指定相應的字段。代碼如下:
tableEnv.createTemporaryView("sensorView", dataStream) tableEnv.createTemporaryView("sensorView", dataStream, 'id, 'temperature,'timestamp as 'ts)另外,當然還可以基于 Table 創建視圖:
tableEnv.createTemporaryView("sensorView", sensorTable)View 和 Table 的 Schema 完全相同。事實上,在 Table API 中,可以認為 View 和 Table是等價的。
“如何掌握Table與DataStream之間的互轉”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





