溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹如何使用pandas分析大型數據集,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
1. 簡介
pandas雖然是個非常流行的數據分析利器,但很多朋友在使用pandas處理較大規模的數據集的時候經常會反映pandas運算“慢”,且內存開銷“大”。
特別是很多學生黨在使用自己性能一般的筆記本嘗試處理大型數據集時,往往會被捉襟見肘的算力所勸退。但其實只要掌握一定的pandas使用技巧,配置一般的機器也有能力hold住大型數據集的分析。

圖1
本文就將以真實數據集和運存16G的普通筆記本電腦為例,演示如何運用一系列策略實現多快好省地用pandas分析大型數據集。
2. pandas多快好省策略
我們使用到的數據集來自kaggle上的「TalkingData AdTracking Fraud Detection Challenge」競賽( https://www.kaggle.com/c/talkingdata-adtracking-fraud-detection ),使用到其對應的訓練集,這是一個大小有7.01G的csv文件。
下面我們將循序漸進地探索在內存開銷和計算時間成本之間尋求平衡,首先我們不做任何優化,直接使用pandas的read_csv()來讀取train.csv文件:
import pandas as pd raw = pd.read_csv('train.csv') # 查看數據框內存使用情況 raw.memory_usage(deep=True)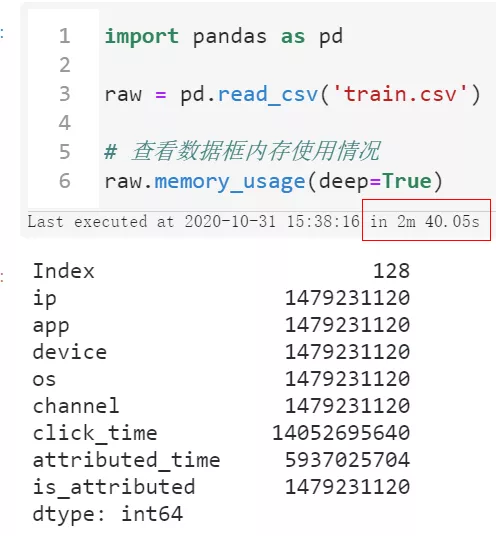
圖2
可以看到首先我們讀入整個數據集所花費的時間達到了將近三分鐘,且整個過程中因為中間各種臨時變量的創建,一度快要撐爆我們16G的運行內存空間。
這樣一來我們后續想要開展進一步的分析可是說是不可能的,因為隨便一個小操作就有可能會因為中間過程大量的臨時變量而撐爆內存,導致死機藍屏,所以我們第一步要做的是降低數據框所占的內存:
(1) 指定數據類型以節省內存
因為pandas默認情況下讀取數據集時各個字段確定數據類型時不會替你優化內存開銷,比如我們下面利用參數nrows先讀入數據集的前1000行試探著看看每個字段都是什么類型:
raw = pd.read_csv('train.csv', nrows=1000) raw.info()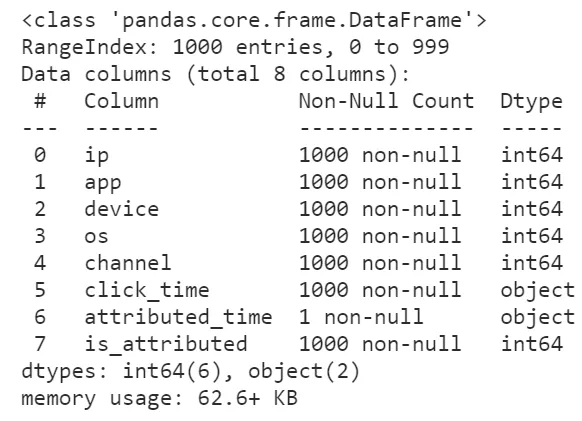
圖3
怪不得我們的數據集讀進來會那么的大,原來所有的整數列都轉換為了int64來存儲,事實上我們原數據集中各個整數字段的取值范圍根本不需要這么高的精度來存儲,因此我們利用dtype參數來降低一些字段的數值精度:
raw = pd.read_csv('train.csv', nrows=1000, dtype={ 'ip': 'int32', 'app': 'int16', 'device': 'int16', 'os': 'int16', 'channel': 'int16', 'is_attributed': 'int8' }) raw.info()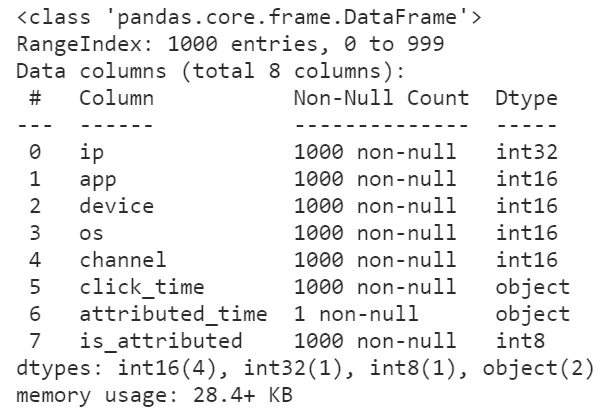
圖4
可以看到,在修改數據精度之后,前1000行數據集的內存大小被壓縮了將近54.6%,這是個很大的進步,按照這個方法我們嘗試著讀入全量數據并查看其info()信息:
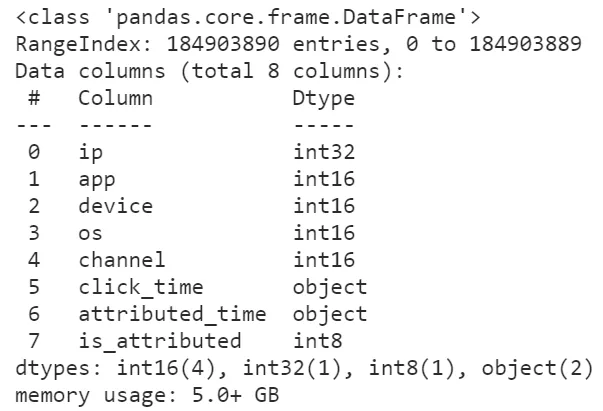
圖5
可以看到隨著我們對數據精度的優化,數據集所占內存有了非常可觀的降低,使得我們開展進一步的數據分析更加順暢,比如分組計數:
( raw # 按照app和os分組計數 .groupby(['app', 'os']) .agg({'ip': 'count'}) )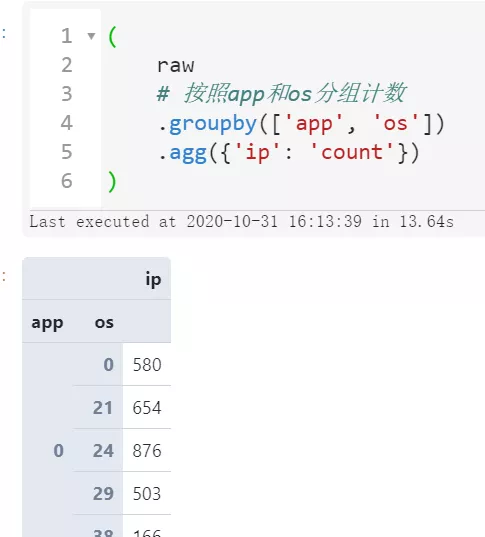
圖6
那如果數據集的數據類型沒辦法優化,那還有什么辦法在不撐爆內存的情況下完成計算分析任務呢?
(2) 只讀取需要的列
如果我們的分析過程并不需要用到原數據集中的所有列,那么就沒必要全讀進來,利用usecols參數來指定需要讀入的字段名稱:
raw = pd.read_csv('train.csv', usecols=['ip', 'app', 'os']) raw.info()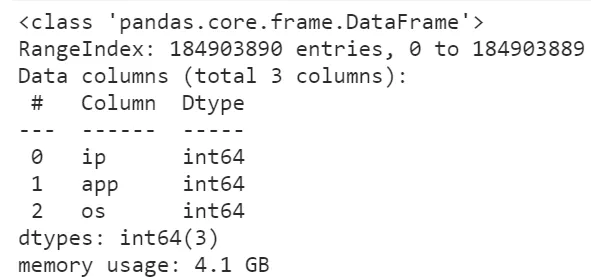
圖7
可以看到,即使我們沒有對數據精度進行優化,讀進來的數據框大小也只有4.1個G,如果配合上數據精度優化效果會更好:
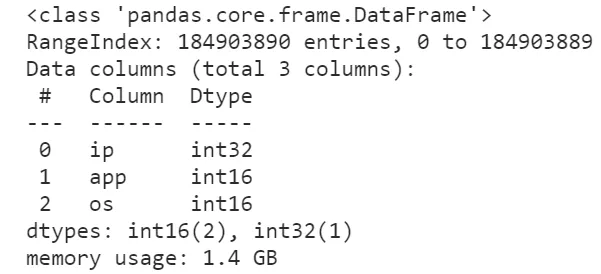
圖8
如果有的情況下我們即使優化了數據精度又篩選了要讀入的列,數據量依然很大的話,我們還可以以分塊讀入的方式來處理數據:
(3) 分塊讀取分析數據
利用chunksize參數,我們可以為指定的數據集創建分塊讀取IO流,每次最多讀取設定的chunksize行數據,這樣我們就可以把針對整個數據集的任務拆分為一個一個小任務最后再匯總結果:
from tqdm.notebook import tqdm # 在降低數據精度及篩選指定列的情況下,以1千萬行為塊大小 raw = pd.read_csv('train.csv', dtype={ 'ip': 'int32', 'app': 'int16', 'os': 'int16' }, usecols=['ip', 'app', 'os'], chunksize=10000000) # 從raw中循環提取每個塊并進行分組聚合,最后再匯總結果 result = \ ( pd .concat([chunk .groupby(['app', 'os'], as_index=False) .agg({'ip': 'count'}) for chunk in tqdm(raw)]) .groupby(['app', 'os']) .agg({'ip': 'sum'}) ) result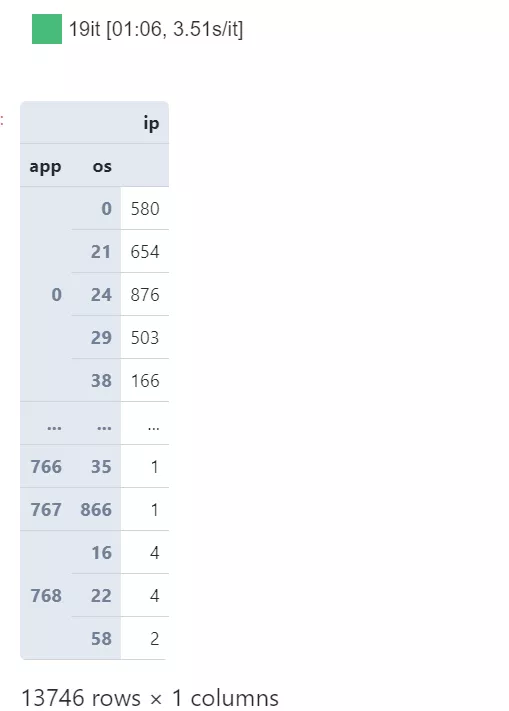
圖9
可以看到,利用分塊讀取處理的策略,從始至終我們都可以保持較低的內存負載壓力,并且一樣完成了所需的分析任務,同樣的思想,如果你覺得上面分塊處理的方式有些費事,那下面我們就來上大招:
(4) 利用dask替代pandas進行數據分析
dask相信很多朋友都有聽說過,它的思想與上述的分塊處理其實很接近,只不過更加簡潔,且對系統資源的調度更加智能,從單機到集群,都可以輕松擴展伸縮。

圖10
推薦使用conda install dask來安裝dask相關組件,安裝完成后,我們僅僅需要需要將import pandas as pd替換為import dask.dataframe as dd,其他的pandas主流API使用方式則完全兼容,幫助我們無縫地轉換代碼:
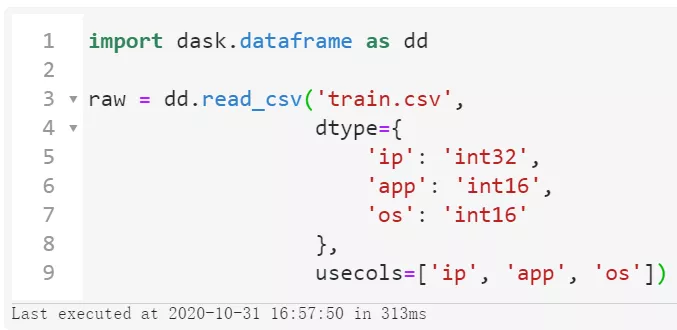
圖11
可以看到整個讀取過程只花費了313毫秒,這當然不是真的讀進了內存,而是dask的延時加載技術,這樣才有能力處理「超過內存范圍的數據集」。
接下來我們只需要像操縱pandas的數據對象一樣正常書寫代碼,最后加上.compute(),dask便會基于前面搭建好的計算圖進行正式的結果運算:
( raw # 按照app和os分組計數 .groupby(['app', 'os']) .agg({'ip': 'count'}) .compute() # 激活計算圖 )并且dask會非常智能地調度系統資源,使得我們可以輕松跑滿所有CPU:
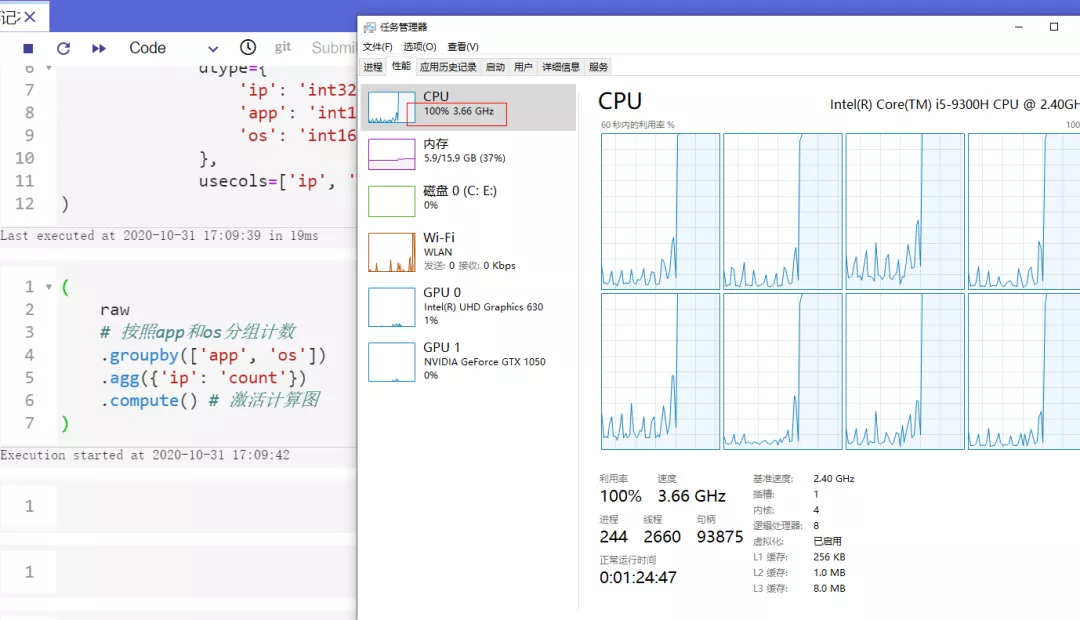
圖12
關于dask的更多知識可以移步官網自行學習( https://docs.dask.org/en/latest/ )。
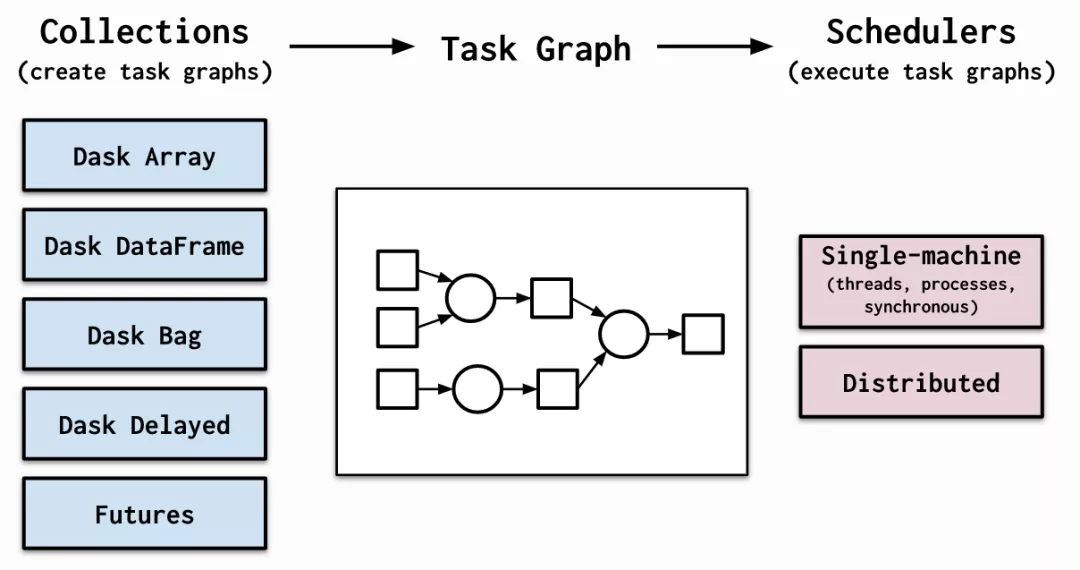
圖13
以上是“如何使用pandas分析大型數據集”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





