溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“SQL需要執行的樹搜索操作有幾次”,在日常操作中,相信很多人在SQL需要執行的樹搜索操作有幾次問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”SQL需要執行的樹搜索操作有幾次”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
一、面試官考點之索引是什么?

索引是一種能提高數據庫查詢效率的數據結構。它可以比作一本字典的目錄,可以幫你快速找到對應的記錄。
索引一般存儲在磁盤的文件中,它是占用物理空間的。
正所謂水能載舟,也能覆舟。適當的索引能提高查詢效率,過多的索引會影響數據庫表的插入和更新功能。
二、索引有哪些類型類型
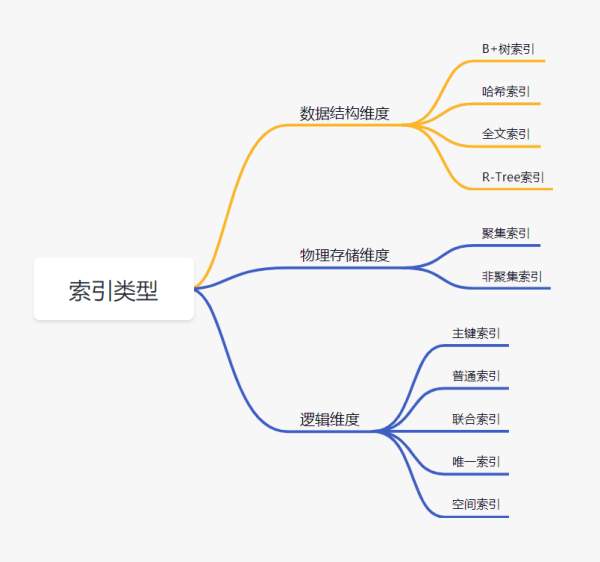
數據結構維度
B+樹索引:所有數據存儲在葉子節點,復雜度為O(logn),適合范圍查詢。
哈希索引: 適合等值查詢,檢索效率高,一次到位。
全文索引:MyISAM和InnoDB中都支持使用全文索引,一般在文本類型char,text,varchar類型上創建。
R-Tree索引: 用來對GIS數據類型創建SPATIAL索引
物理存儲維度
聚集索引:聚集索引就是以主鍵創建的索引,在葉子節點存儲的是表中的數據。
非聚集索引:非聚集索引就是以非主鍵創建的索引,在葉子節點存儲的是主鍵和索引列。
邏輯維度
主鍵索引:一種特殊的唯一索引,不允許有空值。
普通索引:MySQL中基本索引類型,允許空值和重復值。
聯合索引:多個字段創建的索引,使用時遵循最左前綴原則。
唯一索引:索引列中的值必須是唯一的,但是允許為空值。
空間索引:MySQL5.7之后支持空間索引,在空間索引這方面遵循OpenGIS幾何數據模型規則。
三、面試官考點之為什么選擇B+樹作為索引結構
可以從這幾個維度去看這個問題,查詢是否夠快,效率是否穩定,存儲數據多少,以及查找磁盤次數等等。為什么不是哈希結構?為什么不是二叉樹,為什么不是平衡二叉樹,為什么不是B樹,而偏偏是B+樹呢?
我們寫業務SQL查詢時,大多數情況下,都是范圍查詢的,如下SQL
select * from employee where age between 18 and 28;
為什么不使用哈希結構?
我們知道哈希結構,類似k-v結構,也就是,key和value是一對一關系。它用于「等值查詢」還可以,但是范圍查詢它是無能為力的哦。
為什么不使用二叉樹呢?
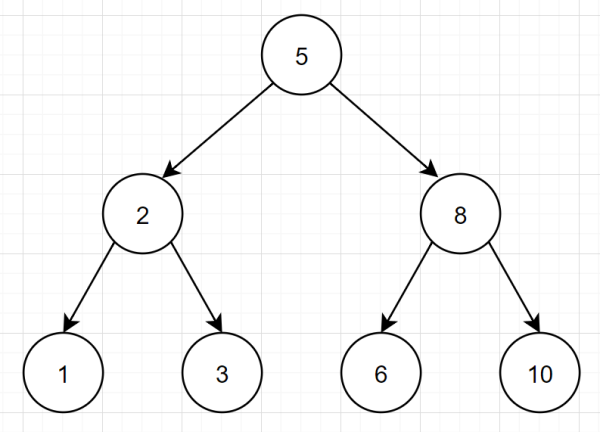
先回憶下二叉樹相關知識啦~ 所謂「二叉樹,特點如下:」
每個結點最多兩個子樹,分別稱為左子樹和右子樹。
左子節點的值小于當前節點的值,當前節點值小于右子節點值
頂端的節點稱為根節點,沒有子節點的節點值稱為葉子節點。
我們腦海中,很容易就浮現出這種二叉樹結構圖:
但是呢,有些特殊二叉樹,它可能這樣的哦:
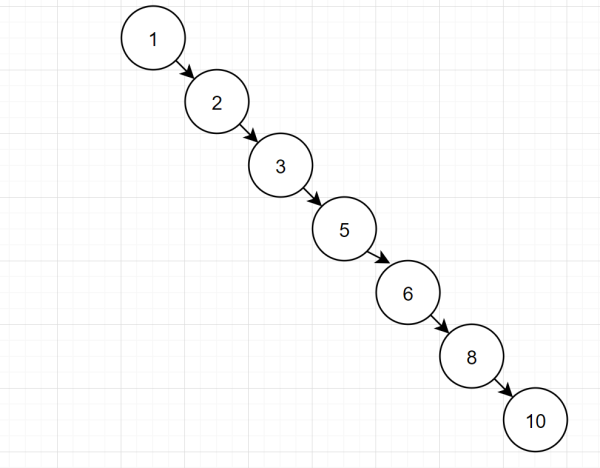
如果二叉樹特殊化為一個鏈表,相當于全表掃描。那么還要索引干嘛呀?因此,一般二叉樹不適合作為索引結構。
為什么不使用平衡二叉樹呢?
平衡二叉樹特點:它也是一顆二叉查找樹,任何節點的兩個子樹高度最大差為1。所以就不會出現特殊化一個鏈表的情況啦。

但是呢:
平衡二叉樹插入或者更新時,需要左旋右旋維持平衡,維護代價大
如果數量多的話,樹的高度會很高。因為數據是存在磁盤的,以它作為索引結構,每次從磁盤讀取一個節點,操作IO的次數就多啦。
為什么不使用B樹呢?
數據量大的話,平衡二叉樹的高度會很高,會增加IO嘛。那為什么不選擇同樣數據量,「高度更矮的B樹」呢?
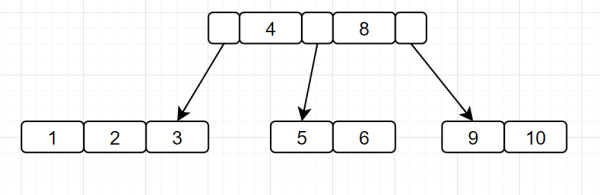
B樹相對于平衡二叉樹,就可以存儲更多的數據,高度更低。但是最后為甚選擇B+樹呢?因為B+樹是B樹的升級版:
B+樹非葉子節點上是不存儲數據的,僅存儲鍵值,而B樹節點中不僅存儲鍵值,也會存儲數據。innodb中頁的默認大小是16KB,如果不存儲數據,那么就會存儲更多的鍵值,相應的樹的階數(節點的子節點樹)就會更大,樹就會更矮更胖,如此一來我們查找數據進行磁盤的IO次數有會再次減少,數據查詢的效率也會更快。
B+樹索引的所有數據均存儲在葉子節點,而且數據是按照順序排列的,鏈表連著的。那么B+樹使得范圍查找,排序查找,分組查找以及去重查找變得異常簡單。
四、面試官考點之一次B+樹索引搜索過程
「面試官:」 假設有以下表結構,并且有這幾條數據
CREATE TABLE `employee` ( `id` int(11) NOT NULL, `name` varchar(255) DEFAULT NULL, `age` int(11) DEFAULT NULL, `date` datetime DEFAULT NULL, `sex` int(1) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_age` (`age`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into employee values(100,'小倫',43,'2021-01-20','0'); insert into employee values(200,'俊杰',48,'2021-01-21','0'); insert into employee values(300,'紫琪',36,'2020-01-21','1'); insert into employee values(400,'立紅',32,'2020-01-21','0'); insert into employee values(500,'易迅',37,'2020-01-21','1'); insert into employee values(600,'小軍',49,'2021-01-21','0'); insert into employee values(700,'小燕',28,'2021-01-21','1');
「面試官:」 如果執行以下的查詢SQL,需要執行幾次的樹搜索操作?可以畫下對應的索引結構圖~
select * from Temployee where age=32;
「解析:」 其實這個,面試官就是考察候選人是否熟悉B+樹索引結構圖。可以像醬紫回答~
先畫出idx_age索引的索引結構圖,大概如下:
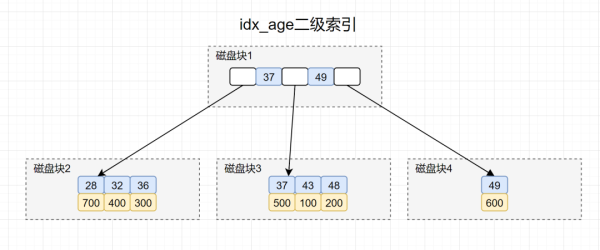
再畫出id主鍵索引,我們先畫出聚族索引結構圖,如下:
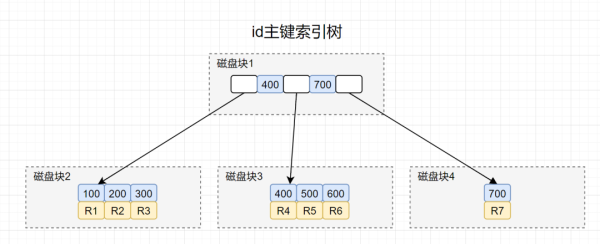
因此,這條 SQL 查詢語句執行大概流程就是醬紫:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
搜索idx_age索引樹,將磁盤塊1加載到內存,由于32<37,搜索左路分支,到磁盤尋址磁盤塊2。
將磁盤塊2加載到內存中,在內存繼續遍歷,找到age=32的記錄,取得id = 400.
拿到id=400后,回到id主鍵索引樹。
搜索id主鍵索引樹,將磁盤塊1加載內存,在內存遍歷,找到了400,但是B+樹索引非葉子節點是不保存數據的。索引會繼續搜索400的右分支,到磁盤尋址磁盤塊3.
將磁盤塊3加載內存,在內存遍歷,找到id=400的記錄,拿到R4這一行的數據,好的,大功告成。
因此,這個SQL查詢,執行了幾次樹的搜索操作,是不是一步了然了呀。「特別的」,在idx_age二級索引樹找到主鍵id后,回到id主鍵索引搜索的過程,就稱為回表。
什么是回表?拿到主鍵再回到主鍵索引查詢的過程,就叫做「回表」
五、面試官考點之覆蓋索引
「面試官:」 如果不用select *, 而是使用select id,age,以上的題目執行了幾次樹搜索操作呢?
「解析:」 這個問題,主要考察候選人的覆蓋索引知識點。回到idx_age索引樹,你可以發現查詢選項id和age都在葉子節點上了。因此,可以直接提供查詢結果啦,根本就不需要再回表了~
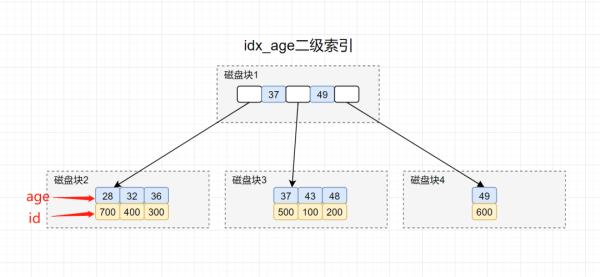
覆蓋索引:在查詢的數據列里面,不需要回表去查,直接從索引列就能取到想要的結果。換句話說,你SQL用到的索引列數據,覆蓋了查詢結果的列,就算上覆蓋索引了。
所以,相對于上個問題,就是省去了回表的樹搜索操作。
六、面試官考點之索引失效
「面試官:」 如果我現在給name字段加上普通索引,然后用個like模糊搜索,那會執行多少次查詢呢?SQL如下:
select * from employee where name like '%杰倫%';
「解析:」 這里考察的知識點就是,like是否會導致不走索引,看先該SQL的explain執行計劃吧。其實like 模糊搜索,會導致不走索引的,如下:
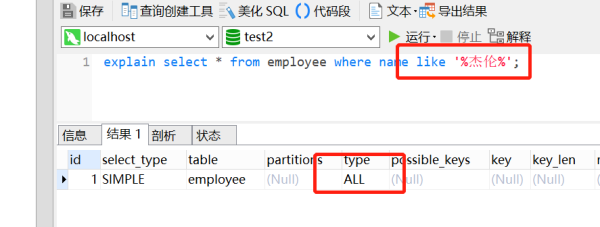
因此,這條SQL最后就全表掃描啦~日常開發中,這幾種騷操作都可能會導致索引失效,如下:
查詢條件包含or,可能導致索引失效
如何字段類型是字符串,where時一定用引號括起來,否則索引失效
like通配符可能導致索引失效。
聯合索引,查詢時的條件列不是聯合索引中的第一個列,索引失效。
在索引列上使用mysql的內置函數,索引失效。
對索引列運算(如,+、-、*、/),索引失效。
索引字段上使用(!= 或者 < >,not in)時,可能會導致索引失效。
索引字段上使用is null, is not null,可能導致索引失效。
左連接查詢或者右連接查詢查詢關聯的字段編碼格式不一樣,可能導致索引失效。
mysql估計使用全表掃描要比使用索引快,則不使用索引。
七、面試官考點聯合索引之最左前綴原則
「面試官:」 如果我現在給name,age字段加上聯合索引索引,以下SQL執行多少次樹搜索呢?先畫下索引樹?
select * from employee where name like '小%' order by age desc;
「解析:」 這里考察聯合索引的最左前綴原則以及like是否中索引的知識點。組合索引樹示意圖大概如下:

聯合索引項是先按姓名name從小到大排序,如果名字name相同,則按年齡age從小到大排序。面試官要求查所有名字第一個字是“小”的人,SQL的like '小%'是可以用上idx_name_age聯合索引的。

該查詢會沿著idx_name_age索引樹,找到第一個字是小的索引值,因此依次找到小軍、小倫、小燕、,分別拿到Id=600、100、700,然后回三次表,去找對應的記錄。這里面的最左前綴小,就是字符串索引的最左M個字符。實際上,
這個最左前綴可以是聯合索引的最左N個字段。比如組合索引(a,b,c)可以相當于建了(a),(a,b),(a,b,c)三個索引,大大提高了索引復用能力。
最左前綴也可以是字符串索引的最左M個字符。
八、面試官考點之索引下推
「面試官:」 我們還是居于組合索引 idx_name_age,以下這個SQL執行幾次樹搜索呢?
select * from employee where name like '小%' and age=28 and sex='0';
「解析:」 這里考察索引下推的知識點,如果是「Mysql5.6之前」,在idx_name_age索引樹,找出所有名字第一個字是“小”的人,拿到它們的主鍵id,然后回表找出數據行,再去對比年齡和性別等其他字段。如圖:
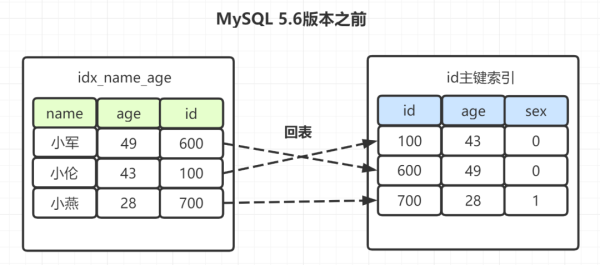
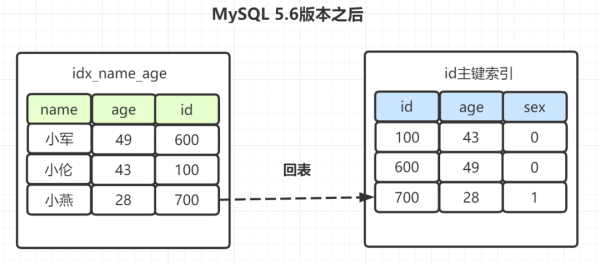
有些朋友可能覺得奇怪,(name,age)不是聯合索引嘛?為什么選出包含“小”字后,不再順便看下年齡age再回表呢,不是更高效嘛?所以呀,MySQL 5.6 就引入了「索引下推優化」,可以在索引遍歷過程中,對索引中包含的字段先做判斷,直接過濾掉不滿足條件的記錄,減少回表次數。
因此,MySQL5.6版本之后,選出包含“小”字后,順表過濾age=28,,所以就只需一次回表。
九、 面試官考點之大表添加索引
「面試官:」 如果一張表數據量級是千萬級別以上的,那么,給這張表添加索引,你需要怎么做呢?
「解析:」 我們需要知道一點,給表添加索引的時候,是會對表加鎖的。如果不謹慎操作,有可能出現生產事故的。可以參考以下方法:
1.先創建一張跟原表A數據結構相同的新表B。
2.在新表B添加需要加上的新索引。
3.把原表A數據導到新表B
4.rename新表B為原表的表名A,原表A換別的表名;
總結與練習
本文主要講解了索引的9大關鍵面試考點,希望對大家有幫助。接下來呢,給大家出一道,有關于我最近業務開發遇到的加索引SQL,看下大家是怎么回答的,有興趣可以聯系我,一起討論哈~題目如下:
select * from A where type ='1' and status ='s' order by create_time desc;
假設type有9種類型,區分度還算可以,status的區分度不高(有3種類型),那么你是如何加索引呢?
是給type加單索引
還是(type,status,create_time)聯合索引
還是(type,create_time)聯合索引呢?
到此,關于“SQL需要執行的樹搜索操作有幾次”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





