溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Redis中哈希分布不均勻如何解決,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
Redis 是一個鍵值對數據庫,其鍵是通過哈希進行存儲的。整個 Redis 可以認為是一個外層哈希,之所以稱為外層哈希,是因為 Redis 內部也提供了一種哈希類型,這個可以稱之為內部哈希。當我們采用哈希對象進行數據存儲時,對整個 Redis 而言,就經過了兩層哈希存儲。
哈希對象本身也是一個 key-value 存儲結構,底層的存儲結構也可以分為兩種:ziplist(壓縮列表) 和 hashtable(哈希表)。這兩種存儲結構也是通過編碼來進行區分:
| 編碼屬性 | 描述 | object encoding命令返回值 |
|---|---|---|
| OBJ_ENCODING_ZIPLIST | 使用壓縮列表實現哈希對象 | ziplist |
| OBJ_ENCODING_HT | 使用字典實現哈希對象 | hashtable |
Redis 中的 key-value 是通過 dictEntry 對象進行包裝的,而哈希表就是將 dictEntry 對象又進行了再一次的包裝得到的,這就是哈希表對象 dictht:
typedef struct dictht { dictEntry **table;//哈希表數組 unsigned long size;//哈希表大小 unsigned long sizemask;//掩碼大小,用于計算索引值,總是等于size-1 unsigned long used;//哈希表中的已有節點數 } dictht;注意:上面結構定義中的 table 是一個數組,其每個元素都是一個 dictEntry 對象。
字典,又稱為符號表(symbol table),關聯數組(associative array)或者映射(map),字典的內部嵌套了哈希表 dictht 對象,下面就是一個字典 ht 的定義:
typedef struct dict { dictType *type;//字典類型的一些特定函數 void *privdata;//私有數據,type中的特定函數可能需要用到 dictht ht[2];//哈希表(注意這里有2個哈希表) long rehashidx; //rehash索引,不在rehash時,值為-1 unsigned long iterators; //正在使用的迭代器數量 } dict;其中 dictType 內部定義了一些常用函數,其數據結構定義如下:
typedef struct dictType { uint64_t (*hashFunction)(const void *key);//計算哈希值函數 void *(*keyDup)(void *privdata, const void *key);//復制鍵函數 void *(*valDup)(void *privdata, const void *obj);//復制值函數 int (*keyCompare)(void *privdata, const void *key1, const void *key2);//對比鍵函數 void (*keyDestructor)(void *privdata, void *key);//銷毀鍵函數 void (*valDestructor)(void *privdata, void *obj);//銷毀值函數 } dictType;當我們創建一個哈希對象時,可以得到如下簡圖(部分屬性被省略):
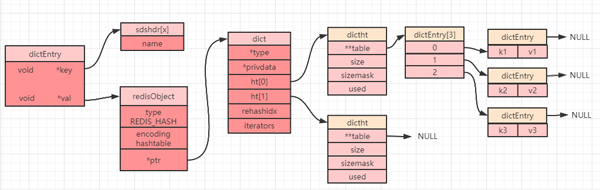
dict 中定義了一個數組 ht[2],ht[2] 中定義了兩個哈希表:ht[0] 和 ht[1]。而 Redis 在默認情況下只會使用 ht[0],并不會使用 ht[1],也不會為 ht[1] 初始化分配空間。
當設置一個哈希對象時,具體會落到哈希數組(上圖中的 dictEntry[3])中的哪個下標,是通過計算哈希值來確定的。如果發生哈希碰撞(計算得到的哈希值一致),那么同一個下標就會有多個 dictEntry,從而形成一個鏈表(上圖中最右邊指向 NULL 的位置),不過需要注意的是最后插入元素的總是落在鏈表的最前面(即發生哈希沖突時,總是將節點往鏈表的頭部放)。
當讀取數據的時候遇到一個節點有多個元素,就需要遍歷鏈表,故鏈表越長,性能越差。為了保證哈希表的性能,需要在滿足以下兩個條件中的一個時,對哈希表進行 rehash(重新散列)操作:
負載因子大于等于 1 且 dict_can_resize 為 1 時。
負載因子大于等于安全閾值(dict_force_resize_ratio=5)時。
PS:負載因子 = 哈希表已使用節點數 / 哈希表大小(即:h[0].used/h[0].size)。
擴展哈希和收縮哈希都是通過執行 rehash 來完成,這其中就涉及到了空間的分配和釋放,主要經過以下五步:
1. 為字典 dict 的 ht[1] 哈希表分配空間,其大小取決于當前哈希表已保存節點數(即:ht[0].used):
如果是擴展操作則 ht[1] 的大小為 2 的n次方中第一個大于等于ht[0].used * 2屬性的值(比如used=3,此時ht[0].used * 2=6,故2的3次方為8就是第一個大于used * 2的值(2 的 2 次方 < 6 且 2 的 3 次方 > 6))。
如果是收縮操作則 ht[1] 大小為 2 的 n 次方中第一個大于等于 ht[0].used 的值。
2. 將字典中的屬性 rehashix 的值設置為 0,表示正在執行 rehash 操作。
3. 將 ht[0] 中所有的鍵值對依次重新計算哈希值,并放到 ht[1] 數組對應位置,每完成一個鍵值對的 rehash之后 rehashix 的值需要自增 1。
4. 當 ht[0] 中所有的鍵值對都遷移到 ht[1] 之后,釋放 ht[0] ,并將 ht[1] 修改為 ht[0],然后再創建一個新的 ht[1] 數組,為下一次 rehash 做準備。
5. 將字典中的屬性 rehashix 設置為 -1,表示此次 rehash 操作結束,等待下一次 rehash。
Redis 中的這種重新哈希的操作因為不是一次性全部 rehash,而是分多次來慢慢的將 ht[0] 中的鍵值對 rehash 到 ht[1],故而這種操作也稱之為漸進式 rehash。漸進式 rehash 可以避免集中式 rehash 帶來的龐大計算量,是一種分而治之的思想。
在漸進式 rehash 過程中,因為還可能會有新的鍵值對存進來,此時** Redis 的做法是新添加的鍵值對統一放入 ht[1] 中,這樣就確保了 ht[0] 鍵值對的數量只會減少**。
當正在執行 rehash操作時,如果服務器收到來自客戶端的命令請求操作,則會先查詢 ht[0],查找不到結果再到ht[1] 中查詢。
關于 ziplist 的一些特性,之前的文章中有單獨進行過分析,想要詳細了解的,可以點擊這里。但是需要注意的是哈希對象中的 ziplist 和列表對象中 ziplist 的有一點不同就是哈希對象是一個 key-value 形式,所以其 ziplist 中也表現為 key-value,key 和 value 緊挨在一起:
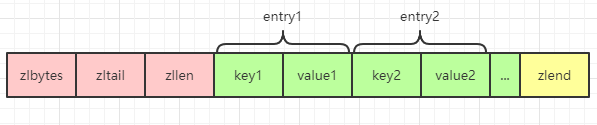
當一個哈希對象可以滿足以下兩個條件中的任意一個,哈希對象會選擇使用 ziplist 編碼來進行存儲:
哈希對象中的所有鍵值對總長度(包括鍵和值)小于等于 64字節(這個閾值可以通過參數 hash-max-ziplist-value 來進行控制)。
哈希對象中的鍵值對數量小于等于 512 個(這個閾值可以通過參數 hash-max-ziplist-entries 來進行控制)。
一旦不滿足這兩個條件中的任意一個,哈希對象就會選擇使用 hashtable 編碼進行存儲。
hset key field value:設置單個 field(哈希對象的 key 值)。
hmset key field1 value1 field2 value2 :設置多個 field(哈希對象的 key 值)。
hsetnx key field value:將哈希表 key 中域 field 的值設置為 value,如果 field 已存在,則不執行任何操作。
hget key field:獲取哈希表 key 中的域 field 對應的 value。
hmget key field1 field2:獲取哈希表 key 中的多個域 field 對應的 value。
hdel key field1 field2:刪除哈希表 key 中的一個或者多個 field。
hlen key:返回哈希表key中域的數量。
hincrby key field increment:為哈希表 key 中的域 field 的值加上增量 increment ,increment 可以為負數,如果 field 不是數字則會報錯。
hincrbyfloat key field increment:為哈希表 key 中的域 field 的值加上增量 increment,increment 可以為負數,如果 field 不是 float 類型則會報錯。
hkeys key:獲取哈希表 key 中的所有域。
hvals key:獲取哈希表中所有域的值。
了解了操作哈希對象的常用命令,我們就可以來驗證下前面提到的哈希對象的類型和編碼了,在測試之前為了防止其他 key 值的干擾,我們先執行 flushall 命令清空 Redis 數據庫。
然后依次執行如下命令:
hset address country china type address object encoding address
得到如下效果:
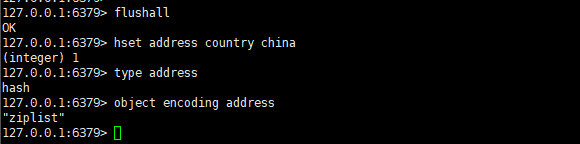
可以看到當我們的哈希對象中只有一個鍵值對的時候,底層編碼是 ziplist。
現在我們將 hash-max-ziplist-entries 參數改成 2,然后重啟 Redis,最后再輸入如下命令進行測試:
hmset key field1 value1 field2 value2 field3 value3 object encoding key
輸出之后得到如下結果:

可以看到,編碼已經變成了 hashtable。
上述內容就是Redis中哈希分布不均勻如何解決,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





