溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“SQL Server Hadoop怎么實現連接”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Apache Hadoop集群
Hadoop是一個主-從架構,部署在Linux主機的集群中。想要處理海量數據,Hadoop環境中必須包含一下組件:
主節點管理從節點,主要涉及處理、管理和訪問數據文件。當外部應用對Hadoop環境發送作業請求時,主節點還要作為主接入點。
命名節點運行NameNode后臺程序,管理Hadoop分布式文件系統(HDFS)的命名空間并控制數據文件的訪問。該節點支持以下操作,如打開、關閉、重命名以及界定如何映射數據塊。在小型環境中,命名節點可以同主節點部署在同一臺服務器上。
每一個從節點都運行DataNode后臺程序,管理數據文件的存儲并處理文件的讀寫請求。從節點由標準硬件組成,該硬件相對便宜,隨時可用。可以在上千臺計算機上運行并行操作。
下圖給出了Hadoop環境中各個組件的相互關系。注意主節點運行JobTracker程序,每個從節點運行TaskTracker程序。JobTracker用來處理客戶端應用的請求,并將其分配到不同的TaskTracker實例上。當它從JobTracker那里接收到指令之后,TaskTracker將同DataNode程序一同運行分配到的任務,并處理每個操作階段中的數據移動。
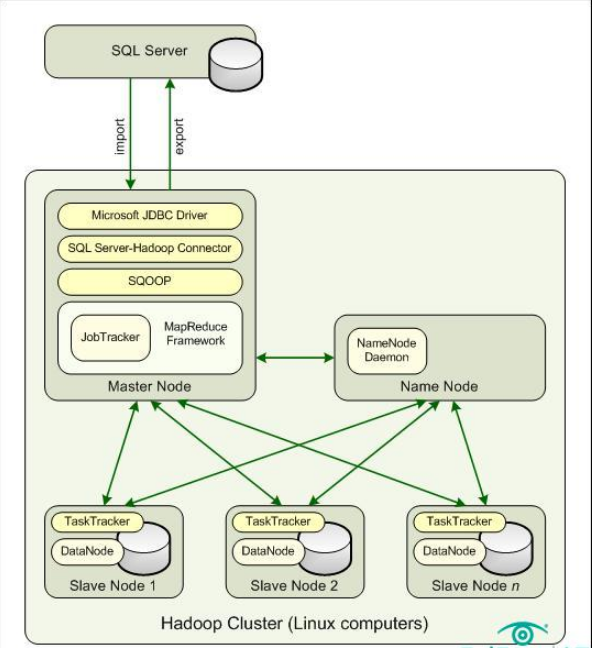
你必須將SQL Server Hadoop連接器部署在Hadoop集群之內
MapReduce框架
再如上圖所示,主節點支持MapReduce框架,這一技術是依賴于Hadoop環境之上的。事實上,你可以把Hadoop想象成一個MapReduce框架,而這個框架中會有JobTracker和TaskTracker來扮演關鍵的角色。
MapReduce將大型的數據集打散成小型的、可管理的數據塊,并分布到上千臺主機當中。它還包含一系列的機制,可以用來運行大量的并行操作,搜索PB級別的數據,管理復雜的客戶端請求并對數據進行深度的分析。此外,MapReduce還提供負載平衡以及容錯功能,保證操作能夠迅速并準確地完成。
MapReduce和HDFS架構是緊密結合在一起的,后者將每個文件存儲為數據塊的序列。數據塊是跨集群復制的,除了***的數據塊,文件中的其他數據塊大小都相同。每一個從節點的DataNode程序會同HDFS一起創建、刪除并復制數據塊。然而,一個HDFS文件只可以被寫一次。
SQL Server Hadoop連接器
用戶需要將SQL Server Hadoop連接器部署到Hadoop集群的主節點上。主節點還需要安裝Sqoop和微軟的Java數據庫連接驅動。Sqoop是一個開源命令行工具,用來從關系型數據庫導入數據,并使用Hadoop MapReduce框架進行數據轉換,然后將數據重新導回數據庫當中。
當SQL Server Hadoop連接器部署完畢之后,你可以使用Sqoop來導入導出SQL Server數據。注意,Sqoop和連接器是在一個Hadoop的集中視圖下進行操作的,這意味著當你使用Sqoop導入數據的時候是從SQL Server數據庫檢索數據并添加到Hadoop環境中,而相反地,導出數據是指從Hadoop中檢索數據并發送到SQL Server數據庫當中。
Sqoop導入導出的數據支持一些存儲類型:
文本文件:基礎的文本文件,用逗號等相隔;
序列文件:二進制文件,包含序列化記錄數據;
Hive表:Hive數據倉庫中的表,這是針對Hadoop構建的一種特殊的數據倉庫架構。
總體來說,SQL Server和Hadoop環境(MapReduce和HDFS)能夠讓用戶處理海量的非結構化數據,并將這部分數據整合到一個結構化的環境中,進行報表制作以及BI分析。
微軟大數據策略才剛剛開始
SQL Server Hadoop連接器在微軟大數據之路上算是邁出了重要的一步。但與此同時,由于Hadoop、Linux和Sqoop都是開源技術,這意味著微軟要對開源世界大規模地敞開胸懷。其實微軟的計劃并不只如此,在今年年底,他們還將推出一個類似于Hadoop的解決方案,并以服務的形式運行在Windows Azure云平臺上。
在明年,微軟還計劃推出針對Windows Server平臺的類似服務。不能否認,SQL Server Hadoop連接器對于微軟來說意義重大,用戶可以在SQL Server環境中處理大數據挑戰,相信在未來他們還會帶給我們更多的驚喜。
“SQL Server Hadoop怎么實現連接”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





