溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹提升Rails CI效率的方法有哪些,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
最近,我們在 Gusto 創下了一個新紀錄:6 分 29 秒。
這是我們為 Gusto 最大的一個應用程序,一個 Rails 單體程序運行測試套件所花費的時間。6 分 29 秒是公司的持續集成(CI)流水線啟用以來的最快紀錄。上一次 CI 套件跑出這樣的成績,公司的規模還很小,而現在我們共有全球數百名工程師在使用這個 Rails 單體應用,為全美 1% 的小型企業提供支持。
對 Gusto 而言,高速 CI 流水線并不只是做做樣子,我們把它視為一種競爭優勢,代碼部署越快,那么客戶的業務開展也會越快。隨著 CI 速度的提升,工程師的生產率也在提高,CI 時間每縮短一分鐘,Gusto 每位工程師每周可增加 2%的拉取請求。
我們的目標很簡單,希望讓測試套件的速度成為一個參數的函數,這個參數就是:我們愿意花多少錢?將基礎架構簡化到這個層面后,就更容易做成本效益分析,例如如果想要將構建速度從 7 分鐘提升到 5 分鐘,那么需要花費 1 美元。
這篇文章介紹了我們是怎樣加快測試套件速度的,其中涉及一個 Rails 單體程序和一個主要用 React 編寫的 JavaScript 單頁應用程序(SPA),這些經驗適用于所有速度較慢的測試套件。
我的同事 Kent 說,構建軟件有 3 個步驟:
讓它跑起來(Make it work)
讓它走上正軌(Make it right)
讓它跑得更快(Make it fast)
“讓它跑起來”指的是做出不會隨便崩潰的軟件。在這一步代碼可能晦澀難懂,但足以為客戶提供價值,并且通過了測試,讓我們能信任它。沒有測試,就很難判斷“它能行嗎?”
“讓它走上正軌”指的是要讓代碼可維護,且易于更改。代碼不僅能在計算機上運行,更要讓人容易理解。新來的工程師可以輕松向代碼添加功能,代碼中的缺陷也應該很容易隔離和糾正。
“讓它跑得更快”指的是要提升軟件性能。為什么它會是最后一步呢?對于像 Gusto 這樣的金融科技公司來說,如果只關注速度卻無視質量,那么我們的客戶和我們自己就離破產不遠了。并非每段代碼都需要優異的性能,如果一段代碼每天可能只執行一次,那么就算它有”高性能”水平,卻難以閱讀和理解,那也是一段失敗的代碼。
我們把這套原則應用在 CI 套件的提速優化過程中。
消除不可靠測試
首先需要做的事情是消除測試套件中的不可靠測試(test flakes)。不可靠測試(flaky test)指的是結果不確定的測試,它有時會通過,有時會失敗。速度飛快但不可靠的測試套件并不能讓你確信代碼可以正常運行,這只是在拋硬幣賭運氣而已。
為了讓一個規模龐大的工程團隊消除不可靠測試,我們采用并執行了以下政策:
在 master 分支上所有失敗的測試都將視為不可靠的。這些測試將標記為已跳過(skipped)。負責不可靠測試的團隊可以在空閑時修復它們并取消跳過標記。
這個做法不僅能讓測試套件一直亮綠燈,同時也讓各個團隊決定何時編寫更多確定性測試。他們可以立刻開始編寫,也可以選擇等到再次處理這個功能時再行動。這種方法減少了一個團隊的不確定測試給其他團隊帶來的損害。
當然,這種方法也存在質疑,“如果我們跳過了一項重要的測試該怎么辦?”是最常見的問題。沒錯,這個問題很重要,但我們需要搞清楚問題的背景。一個測試之所以會被標記為已跳過,是因為它會隨機失敗,首先要考慮的是我們對這個測試和功能到底有多大的信心。很多時候,測試會出現不可靠情況是因為生產環境中的確存在錯誤!
通過這種方式,我們在主分支上的構建綠燈率從約 75%增至 98%!
回到默認狀態
隨著時間的流逝,我們逐漸偏離了運行 RSpec 測試的默認路徑。遵守默認值是很難的。下面是 RSpec 測試的一些默認值:
在各個測試用例之間重置狀態。這樣可以確保測試是可重復的、確定性的,并且不會相互依賴。
測試執行是隨機的。這樣可以確保測試之間不存在相互依賴,幫助避免測試污染。
測試文件使用 Rails 自動加載器。這意味著我們僅加載應用程序所需的部分,而不是程序整體,可以幫助避免不完整的測試設置。
重新采用這些默認值的過程并不輕松。確保每個測試用例都重置其狀態(數據庫、Redis 值、緩存等),都會帶來新的不可靠測試。根據其性質,我們可以修復更改或將之前正常的測試標記為不可靠。
我們慢慢重新引入了 RSpec 默認值,這為測試提速奠定了基礎。
引入測試時間上限
我們的測試是不平衡的。有些測試文件只需幾毫秒就能執行完畢,還有些則需要花費數十分鐘時間。耗時幾分鐘的測試是集成測試,涉及我們應用程序中最重要的一些流程。我們希望這些測試的速度能更快,但并不想移除它們。
因為測試套件是分布在多個節點上并行執行的,所以很快就遇到了測試提速的瓶頸。
我們的測試套件速度取決于最慢的測試文件,因此實施了一項新政策:
任何測試文件的執行時間都不能超過 2 分鐘。
這個門檻是憑空拉出來的,但似乎很實用。我們只有 40 多個耗時超過 2 分鐘的文件。
確定界限之后,我們開始處理速度緩慢的測試,試圖讓它們通過新的門檻,之前 40 個文件的時間都降到了閾值以下。之后,每個團隊都有責任確保其測試文件的執行時間不超過 2 分鐘,而執行時間超過 2 分鐘的測試文件會被標記為已跳過。
根據最壞情況來平衡測試
現在我們有了一個可靠的測試套件,只是速度很慢,它可以按任何順序執行測試,但是將測試分配給節點的方法是隨機的。有些節點只需幾秒鐘就完成了,而另一些節點則需要數十分鐘。我們怎樣才能讓它們平衡呢?
我們面臨的最后一個問題是測試平衡。我們在這一步評估了兩種解決方案:
開發一個隊列,以在節點準備就緒后為其輸入測試用例。雖然這種方案原理上沒問題,但 RSpec 需要對框架做大幅更新才能兼容這種方案。此外,它在所有各不相同的并行作業之間引入了共享狀態。
在一次 CI 流程開始時在一個數據庫中記錄測試時間,將測試分為不同的桶,讓所有分組都有相同的長度。
我們采用了記錄與分桶的方法將測試分配到各個節點上,因為它非常適合 knapsack(https://docs.knapsackpro.com/ruby/knapsack)。測試運行期間,這種方法也不會在許多不同的并行作業之間共享狀態。這是很重要的,因為一個共享隊列可能有數百個節點,每個節點每秒為一個構建可以請求數千次工作。
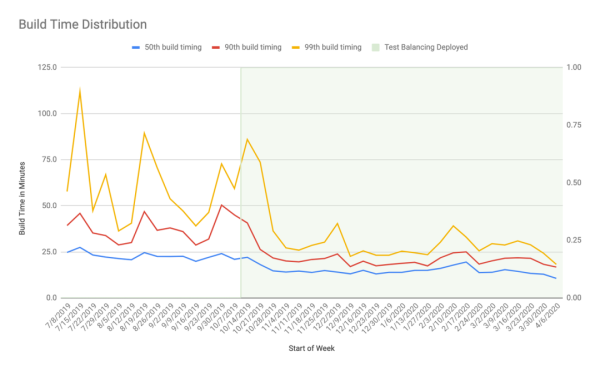
我們建立了一個 MySQL 實例來記錄所有文件的測試時間。在每次 CI 流程開始時,它會根據每個測試文件的第 99 個百分位時間生成一個 knapsack 文件。在每次 CI 流程結束時,它將上傳新的結果。
為什么是第 99 個百分位?由于我們在共享硬件(AWS)上運行 CI,因此無法控制基礎架構,各個測試文件的測試時間會大相徑庭。我們無法將這些波動與使用的 EC2 實例類型,或者其他任何可以衡量的參數關聯起來。
我們沒有進一步完善構建基礎架構,而是讓系統具備了彈性。我們使用第 99 個百分位來組織測試,從而保證了測試的性能表現有一個下限,而不是在獲得較好的平均性能時卻存在明顯偏低的個例。即便底層硬件發生變化或基礎架構層出現故障,CI 管道依舊能保障可預期的性能水平。
這套策略實施之后,我們就有了一個自平衡的系統。測試越多,系統也就越平衡。如果某些測試隨著時間的推移變慢,則測試桶也會隨之調整平衡狀態。
提升并行度
現在到了有意思的地方:讓測試速度真的變快。
這里的主要做法是增加并行度。項目開始以來,我們已經從 40 個并行作業增加到了 130 個。這稍稍增加了成本,但大幅提升了 CI 的運行速度。在 Gusto,我們使用 Buildkite 作為 CI 基礎架構,但這種并行化的理念適用于所有主流 CI 產品。
雖然我們將并行度提高到了 3 倍以上,但 CI 費用卻沒有隨之線性增長。為什么?因為我們更好地利用了已有的 CPU 時間,通過在各個節點之間平衡作業,總 CPU 時間并沒有變化,但是實際運行時間大幅縮短了。
在過去幾個月中,我們在一點點讓 Gusto 主要應用程序的 CI 管道變得更堅實可靠,而且速度更快。
關于提升Rails CI效率的方法有哪些就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





