溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
爬蟲是python最常見的一類應用,但是如何自己動手來寫一個爬蟲,這可能是很多人關心的問題,這次準備用30分鐘來教會大家如何自己動手編寫一個Scrapy爬蟲的應用
推薦一個不錯的Scrapy視頻教程給大家,可以直接點擊觀看:https://www.bilibili.com/video/av27042686/
首先,我們需要理解爬蟲的原理,只是拿一個庫來用誰都會,但理解它的原理才對大家有好處
通過上圖我們可以對爬蟲的工作原理(不僅限于Scrapy框架)有一個認識:
- 數據源:需要知道從哪里拿到你要的數據,可以是Web,也可以是App或其他應用
- 下載器(Download):需要將數據下載到本機才能進行分析工作,而在下載中我們需要關注幾件事:性能、模擬操作和分布式等
- 分析器(Parser):對已下載的數據進行分析,有很多種,比如HTML、正則、json等,當然,在分析的過程中,也能發現更多的鏈接,從而生成更多采集任務
- 數據存儲(Storage):可以將數據保存在數據或磁盤上,以供后續產品的調取、分析等
既然理解了爬蟲的原理,我們可以更進一步的認識一下Scrapy框架
Scrapy是Python中很成熟、很常用的一個框架,大部分Python爬蟲都是由Scrapy來編寫的,那么,為了理解Scrapy的基本結構,我們先來看一張圖:
其實,這張圖和我們之前說的爬蟲原理是一一對應的,我們來看看:
- 下載器(Downloader):將數據下載回來,以供分析
- 爬蟲(Spider):這個其實是用于分析的(Parser),用于對下載的數據進行分析
- 調度器(Scheduler):負責調度任務
- 數據管道(Pipeline):負責把數據導出給其他程序、文件、數據庫
當然,只是了解上述內容其實意義不大,我們來通過動手做一個例子理解Scrapy
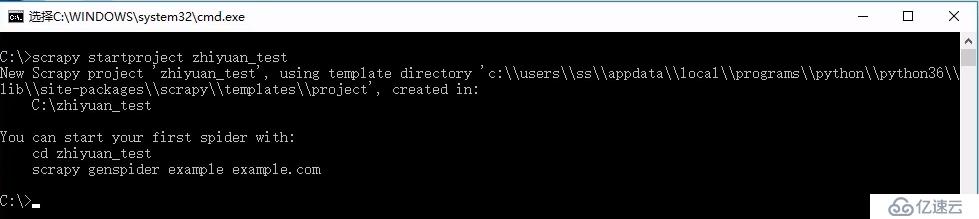
在正式開始編寫爬蟲之前,我們需要先來創建一個項目
$> scrapy startproject 項目名稱
先來了解一下剛剛創建好的目錄里面都有什么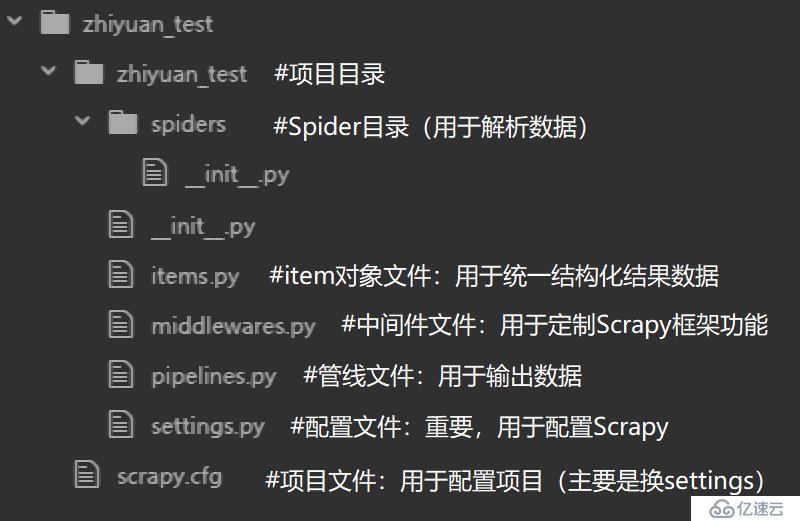
在這里面,其實只有兩個東西是我們目前需要關心的:
本文我們先關心最基本的功能,所以不會過于深入Scrapy的細節,所以只對中間件和items的功能做一簡單敘述,在其他文章中再詳細說明:
本案例中,我們準備抓取一個拍賣手機號的網站:http://www.jihaoba.com/escrow/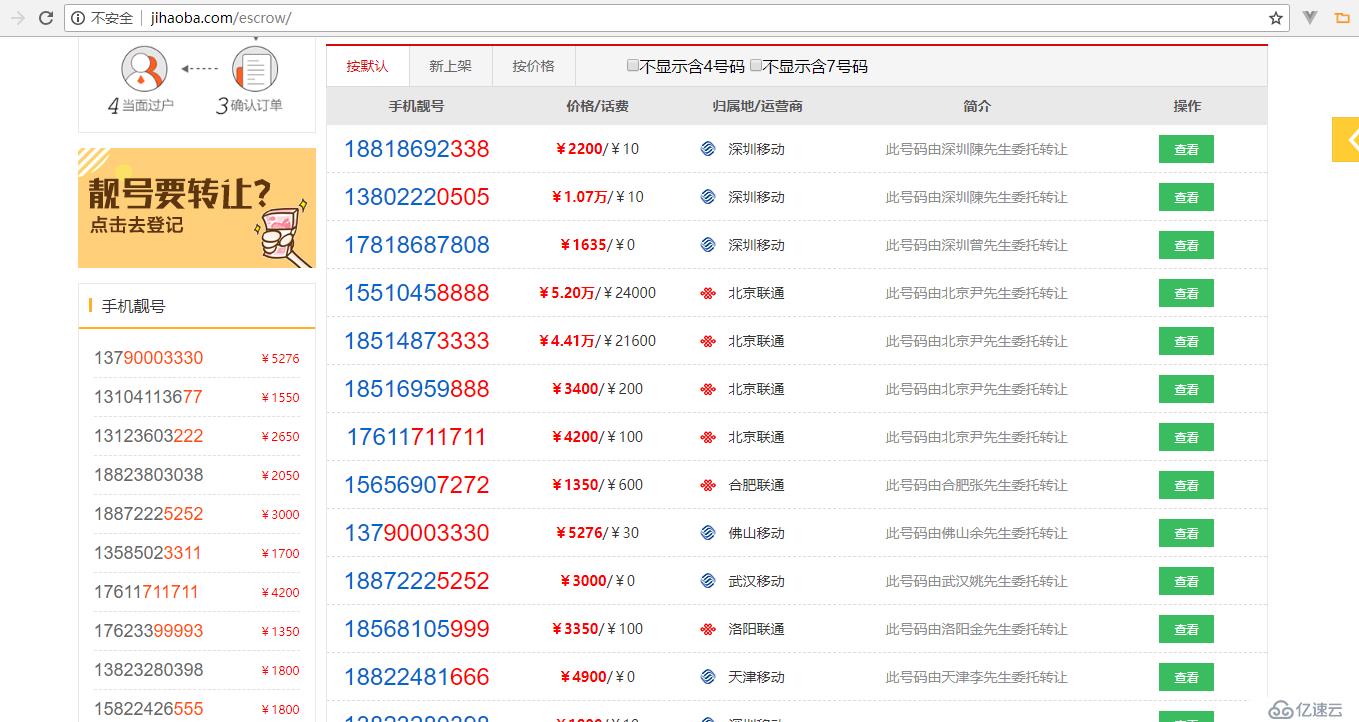
在剛剛創建好的項目中,我們再創建一個文件:phone_spider.py
import scrapy
class PhoneSpider(scrapy.Spider):
name='phone'
start_urls=[
'http://www.jihaoba.com/escrow/'
]
def parse(self, response):
pass在這里我們主要關心幾件事:
盡管現在還沒有實際的工作,但我們可以試著啟動爬蟲的抓取
scrapy crawl phone

我們可以看到爬蟲的抓取能夠正常啟動
我們可以繼續為爬蟲加入實際的功能
import scrapy
class PhoneSpider(scrapy.Spider):
name='phone'
start_urls=[
'http://www.jihaoba.com/escrow/'
]
def parse(self, response):
for ul in response.xpath('//div[@class="numbershow"]/ul'):
phone=ul.xpath('li[contains(@class,"number")]/a/@href').re("\\d{11}")[0]
price=ul.xpath('li[@class="price"]/span/text()').extract_first()[1:]
print(phone, price)
這里我們用了一個非常重要的東西——xpath,xpath是一種用于從XML和HTML中提取數據的查詢語言,在這里不做贅述,想了解更多xpath的內容請點擊https://www.bilibili.com/video/av30320885
再次啟動抓取,我們會看到一些有用的數據產生了
當然,我們現在只是把print出來,這肯定不行,需要把數據保存到文件中,以便后續使用
所以,將print改為yield
import scrapy
class PhoneSpider(scrapy.Spider):
name='phone'
start_urls=[
'http://www.jihaoba.com/escrow/'
]
def parse(self, response):
for ul in response.xpath('//div[@class="numbershow"]/ul'):
phone=ul.xpath('li[contains(@class,"number")]/a/@href').re("\\d{11}")[0]
price=ul.xpath('li[@class="price"]/span/text()').extract_first()[1:]
#print(phone, price)
yield {
"phone": phone,
"price": price
}
再次運行,并且需要修改運行命令,添加輸出選項
scrapy crawl phone
改為
scrapy crawl phone -o data.json
我們可以看到,運行后目錄中會多出一個data.json,打開后就是我們要的結果數據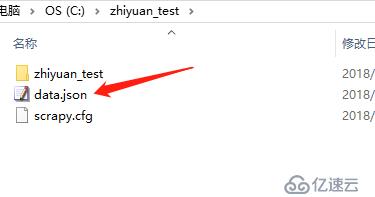
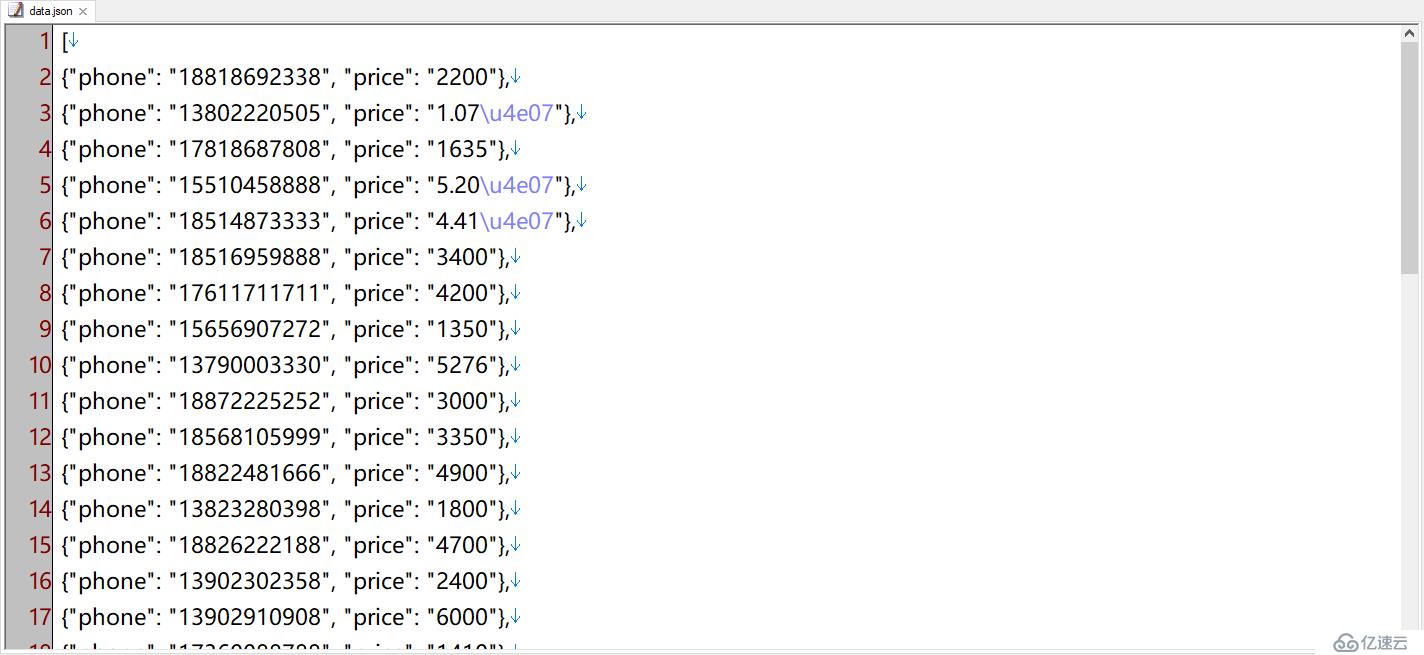
注意,這里導出的價格中,有的帶有“\u4e07”,這其實是中文“萬”的unicode碼,并不影響數據使用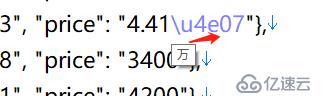
目前只抓取了第一頁的數據,而我們希望能獲取所有的數據,所以需要找到下一頁的地址,并讓爬蟲進入其中繼續抓取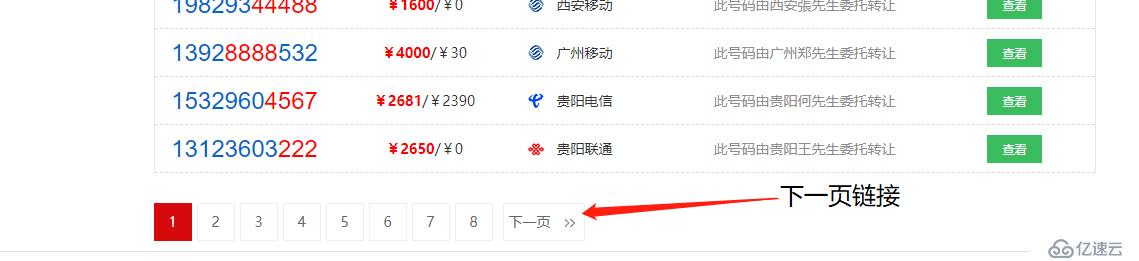
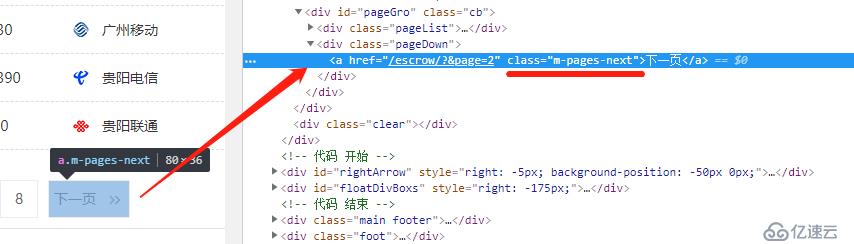
所以,我們需要對代碼進行修改
import scrapy
class PhoneSpider(scrapy.Spider):
name='phone'
start_urls=[
'http://www.jihaoba.com/escrow/'
]
def parse(self, response):
for ul in response.xpath('//div[@class="numbershow"]/ul'):
phone=ul.xpath('li[contains(@class,"number")]/a/@href').re("\\d{11}")[0]
price=ul.xpath('li[@class="price"]/span/text()').extract_first()[1:]
#print(phone, price)
yield {
"phone": phone,
"price": price
}
#繼續抓取下一頁
next="http://www.jihaoba.com"+response.xpath('//a[@class="m-pages-next"]/@href').extract_first()
yield scrapy.Request(next)我們再次啟動爬蟲
scrapy crawl phone -o data.json
這次,我們會得到比之前多的數據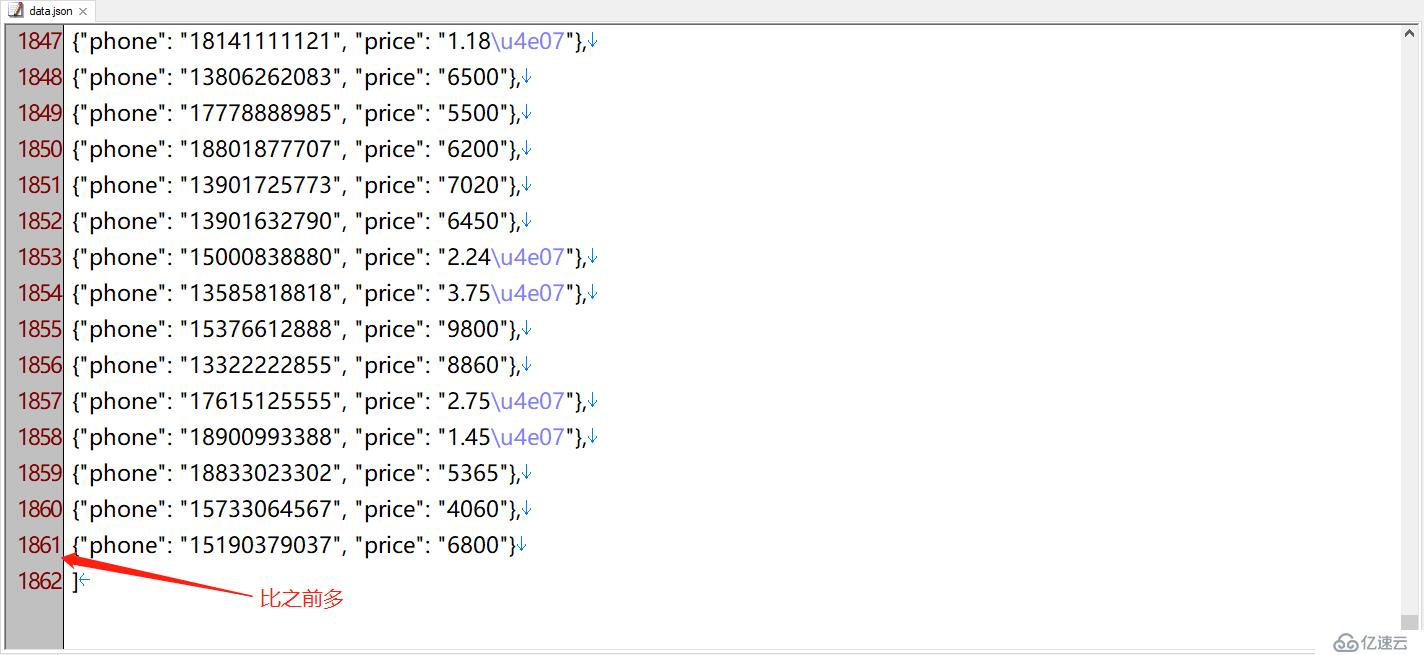
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





