溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Graphlab怎么實現分析圖的存儲,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
前一段時間參與了一個迭代計算平臺的開發,對于內存計算和圖計算產生了比較濃厚的興趣,這期間也閱讀了spark和pregel的相關論文,了解一下BSP模型,但總覺得看論文太抽象了,于是選擇閱讀graphlab源碼,作為深入了解圖計算的一個契機。接下去如果有時間的話,會詳細記錄下我對graphlab的一些膚淺的理解。
在graphlab中,采用鄰接矩陣來表示頂點之間的相鄰關系,給定一個圖G(V, E),使用一個一維數組存儲V的頂點信息,使用一個稀疏矩陣來存儲E的邊信息。
在graphlab中,圖是分布在多個機器之上,每個機器中存儲著圖的一部分,在這里我們討論graphlab中,每個節點是如何實現圖的本地存儲。
在graphlab的圖相關接口中有兩個接口,分別是獲取頂點的in edges和out edges。那么在graphlab中需要考慮如何有效地存儲一個圖的邊集合,并可以快速地對頂點的in edges和out edges進行快速索引,并盡可能地減少空間開銷。
Graphlab中采用的思路是同時采用稀疏矩陣的csr(compressed sparse row)和csc(compressed sparse column)存儲格式來存儲圖的邊集合,并高效地實現獲取頂點的in edges和out edges的接口。
Graphlab分別實現了圖的靜態存儲和動態存儲,靜態存儲是指一旦完成對圖的頂點和邊的存儲之后,不會添加新的頂點和邊。而動態存儲,可以動態地往圖中新增頂點和邊,這兩者都沒有刪除頂點和邊的操作。靜態存儲和動態存儲的思路都是同時采用稀疏矩陣的csr和csc格式來存儲邊集合,不過csr和csr采用的數據結構不一樣,靜態存儲采用數組實現,動態存儲采用鏈表實現。在本篇博客中,只對靜態存儲進行介紹,動態存儲會在下一篇博客中進行介紹。
首先會介紹一下稀疏矩陣的csr和csc格式以及計數排序,然后會舉一個實際的例子來分析graphlab圖的靜態存儲,介紹一下graphlab實現圖靜態存儲的相關類。
1 稀疏矩陣csr和csc格式和計數排序簡介
1.1 csr和csc格式介紹
csr是使用三個數組來表示一個稀疏矩陣,稀疏矩陣用A表示,三個數組分別是values、rowptrs和columns;values中按行順序存儲著A中的非零單元的值。Columns中存儲著values數組中的單元的列索引,values(k) = A(i, j),則columns[k] = j。Rowptrs中存儲著行在values中的起始地址,如果values(k) = A(i, j),則rowptrs(i) <= k <rowptrs(i + 1),行i中的非零單元的數目為rowptrs(i + 1) - rowptrs(i)。
比如稀疏矩陣A = 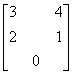
假設下標都從0開始,那么行是{0,1,2},列也是{0,1,2};稀疏矩陣A的csr格式就可以用如下三個數組表示:

csc格式類似于,只不過是把行換成了列,csc可以用values,columnptrs和rows表示矩陣A。values中按列順序存儲著A中的非零值;rows中存儲著values數組中單元的行索引,values(k) = A(i, j),則rows(k) = i;columnptrs中存儲著列在values中的起始地址,values(k) = A(i,j),則columns(j) <= k < columns(j + 1),j列的非零單元數目為columns(j + 1) - columns(j)。

關于csr的詳細描述見:http://web.eecs.utk.edu/~dongarra/etemplates/node373.html
1.2 計數排序
計數排序的思路如下:假設n個輸入元素中的每一個都是介于0-k的整數,此處k為某個整數。對每一個輸入元素x,統計小于x的數目s,那么可以通過s來確定x在最終輸出數組中的位置。
在graphlab中,計數排序的輸入是一個未經排序的原始數組A;輸出是兩個數組,分別是P和I;P數組長度等于原始數組的長度,是按從小到大對原始數組進行排序后生成的序列數組,P[i]表示排序后的第i個值在原始數組中的下標;I數組表示值為i的整型在排序后的數組中的起始位置,I數組的長度為max{A[i]} + 1(+1的原因是從0開始計數)。
Graphlab中計數排序算法的偽碼:

比如給定一個原始數組A,數組長度為7,數組中存儲著整型值(可能有重復),如下圖所示:
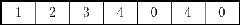
運行結果:
在counting_sort函數中12-13行的循環運行完后,原始數組(A)和統計數組(c)如下所示:

c[i]存儲著在A中,值小于等于i的元素數目。
第15-16的運行步驟如下,總共有:
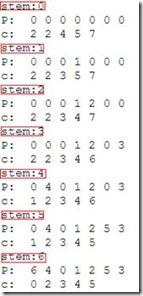
***P數組存儲著排序后的數值在原數組中的下標。c數組中的每個單元c[i]中則存儲著在A數組中,值小于i的元素數目。i在A中的數目等于:c[i + 1] - c[i],i < k或n - c[i] ,i == k;c[i]表示i值在P數組出現的***個值的下標。
最終I數組的結果等于stem 6中的c:

這三個數組之間的關系如下:
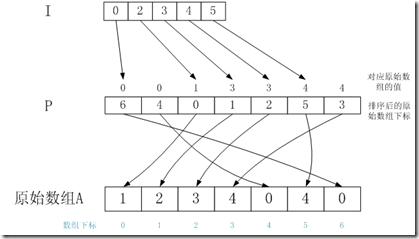
給定一個值2,那么2在A中的數目為:I[3] - I[2] = 1;2在A中的位置為A[P[I[2]] ] = A[1]。
2 使用csr和csc存儲圖
我們可以將邊集合表示為一個鄰接矩陣,使用稀疏矩陣的csr和csc格式來存儲鄰接矩陣。
因為稀疏矩陣的csr存儲格式是對row進行壓縮,可以根據row來快速對稀疏矩陣的某一行進行檢索,所以使用csr來對out_edges進行檢索(邊(v,w)是頂點v的out edges,頂點v對于邊(v,w)相當于行)。同理,稀疏矩陣的csc存儲格式是對column進行壓縮,可以根據column來快速對稀疏矩陣的某一列進行檢索,所以使用csc對in_edges進行檢索。
我們先單獨分別從csr和csc角度考慮邊集合的存儲。然后再分析graphlab是如何同時使用csr和csc巧妙地實現對邊集合進行存儲,并實現對頂點的in edges和out edges快速檢索。
2.1 CSR格式存儲
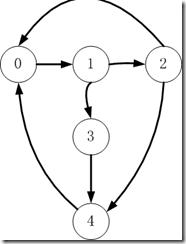
如上圖所示,給定以一個有向圖G(V,E),V為頂點集合,E為邊集合。一條邊包括頂點對(邊從source vertex指向targe vertex)和值,邊集合可以表示成如下的鄰近矩陣,對于邊(v,w),將v作為行,w作為列(source vertex對應行,target vertex對應列)。
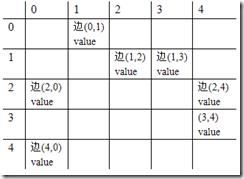
假設E中邊的輸入順序如下所示:
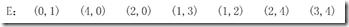
那么我們就可以用如下三個數組來表示輸入的邊集合E:
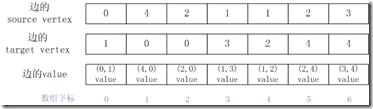
那么如何將輸入的E轉化為按照csr格式存儲的稀疏矩陣呢?
1. 將source vertex數組作為輸入數組,使用1.2張中的counting_sort進行排序,輸出的數組為P和I。因為source vertex相當于鄰接矩陣的行,這一步驟等同于將稀疏矩陣的非零單元按照行順序存儲在一個數組中(這里不需要考慮同一行內的各個邊的順序)。那么P是按行的從小到大順序對原始數組進行排序后生成的序列數組;I等于csr中的rowptrs;
2. 使用P對輸入邊集合E的target vertex數組和value數組按照行大小進行重新排序,那么排序后的target vertex數組就是csr中的columns,value數組就是csr的values。這里的排序可以使用不同的方式實現,最簡單的方法就是引入一個臨時數組,按照P數組中的下標對target vertex和value進行排序。
counting_sort具體過程見1.2章(1.2張的例子就是本例),最終E的CSR格式如下圖所示。
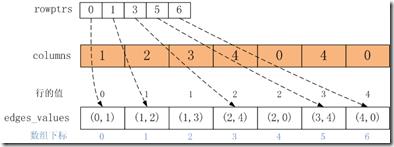
1.edges_values數組:是按行順序進行排序后邊集合的值數組。
2.rowptrs數組:保存行在edges_values中的起始偏移地址, rowptrs[i]是第i行在edges_values中的起始偏移位置;那么第i行的邊數目等于rowptrs[i + 1] –rowptrs[i]或edges_values長度 – rowptrs[i ];rowptrs數組的長度為頂點的***值。
3.columns數組:列索引,columns[i]是edges_values[i]值對應的邊的列的值。如edges_values[2]的列為columns[2],等于3。
那么用csr存儲的邊集合E,給定一個頂點v,可以快速檢索v的所有out edges的值。v的值相當于行,那么v的所有out edges的值可以通過如下的方式獲取:

拿上面的例子,頂點1的out edges的數目為rowptrs[2] – rowptrs[1] = 2,那么可以得到頂點1的兩個out edges在edges_values數組的下標分別為1和2,那么out edges集合為{edges_values[1], edges_values[2]} = {(1,2), (1, 3)}。
2.2 CSC格式存儲
使用csc來存儲邊集合E的邊關系和值,與csr基本相同。首先將target vertex數組作為輸入數組進行counting_sort,得到P和I,I為csc的columnptrs。使用P對E的source vertex數組和value數組進行排序,生成了csc的rows和values。E以csc格式存儲的最終結果如下所示。
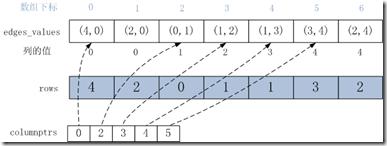
1.edges_values數組:是按列順序進行排序后邊集合的值數組。
2.columnptrs數組:保存列在edges_values中的起始偏移地址,columnptrs[i]是第i列在edges_values中的起始偏移位置;
3.rows數組:列索引,rows[i]是edges_values[i]值對應的邊的列的值。
通過csc獲取一個頂點的in edges類似于在csr中獲取out edges,不在贅述。
2.3 Graphlab圖的靜態存儲
Graphlab對圖的靜態存儲是同時采用了csr和csc格式。在graphlab中,會首先對邊集合按照csr方式進行存儲(通過對source vertex進行counting_sort),然后再建立csc格式,通過shuffle方式,在csc和csr之間進行轉換。把csr和csc整合到一起,同時實現對頂點的out edges和in edges的快速索引。如下圖所示。
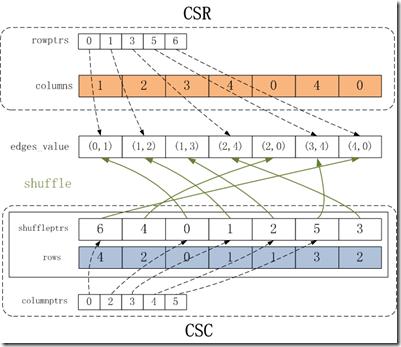
edges_value:同CSR中的rowptrs。
rowptrs:同CSR中的rowptrs。
columns:同CSR中的columns。
shuffleptrs:這個數組用于將按列順序排列的稀疏矩陣轉換為按行順序排列的稀疏矩陣。Shuffleptrs[i]表示按列順序排序的邊集合的第i條邊在edges_value數組中的下標。
rows:同CSC中的rows。
columnptrs:同CSC中的columnptrs。
如上圖所示,在內存中存儲邊集合E,需要維持邊的值數組,csr和csc。CSR有兩個整型數組,rowptrs和columns,分別用來存儲行偏移地址和列索引。CSC有三個整型數組,shuffleptrs、rows和columnptrs,分別存儲著從按列順序排序的稀疏矩陣到按行順序排列的稀疏矩陣轉換的下標,行索引和列偏移地址,shuffleptrs和rows具有相同的下標,可以合并成一個數組。
具體步驟如下:
E的原始輸入由三個相同長度的數組組成,source_arr、target_arr和data_arr,分別存儲著邊的source vertex、target vertex和邊的值。source vertex相當于鄰接矩陣的行,target vertex相當于鄰近矩陣的列。如果要形成最終的結果,需要以下這些步驟,才能形成上圖中的存儲。
1. counter_sort(source_arr, P, rowptrs)
2. sort(P, E)
//使用P按照行順序對E中的三個數組進行排序,P數組是按照行的順序保存著E的下標,
3. columns = target_arr
4. csr = {rowptrs, columns}
5. counter_sourt(target_arr, P, columnptrs)
6. sort(P, source_arr)
//對source_arr按列順序進行排列,***作為行索引
7. rows = source_arr; shuffleptrs = P.
8. csc = {columnptrs, rows, shuffleptrs}
Graphlab中的具體類:
在graphlab中,圖的本地靜態存儲是由local_graph來實現,local_graph中保存圖使用了四個數據結構:
std::vector<VertexData> vertices:存儲頂點數據的數組,頂點的ID為0到數組的長度。
std::vector<EdgeData> edges:存儲邊的值的數組,相當于edges_values。
csr_type _csr_storage:表示csr,由csr_storage這個類來實現。
csc_type _csc_storage:表示csc,由csr_storage這個類來實現。
csr_storage中有兩個成員變量,分別是:
std::vector<sizetype> value_ptrs;
std::vector<valuetype> values;
當csr_storage表示csr時,value_ptrs等同于rowptrs,是一個uint64_t數組;values等同于columns,也是一個uint64_t數組。
當csr_storage表示csc時,value_ptrs等同于columnptrs,是一個uint64_t數組;values則被定義成std::vector< std::pair<lvid_type, edge_id_type> >,相當于將rows和shuffleptrs存儲在同一個vector中。
3 存儲結構
Graphlab實現對圖的動態存儲也是基于csr和csc格式,不過在csr和csc的底層數據結構設計上做了一些調整,將數組替換為分塊鏈表。如果實現對圖的動態存儲,那么需要把底層的數據結構從數組換成鏈表,但需要對原先在靜態圖存儲中所用的那套算法做些調整。
動態存儲格式的CSR、CSC和邊的值數數組如下圖所示:
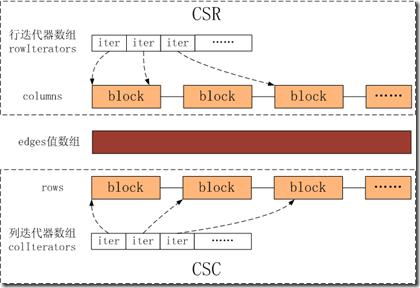
1. Edges是一個數組,數據結構使用vector,只是將批量插入的邊的權值按順序放入到vector中。
2. CSR是由行迭代器數組rowIterators和columns組成。columns是一個分塊鏈表,表示按鄰近矩陣的行(即邊的source vertex)大小排序的列的鏈表,如上圖所示,Block的內容如下,Block是固定長度的pair< uint64_t, uint64_t>數組,多個block組成一個鏈,pair的first是鄰接矩陣的列(即邊的target vertex),second是列所在的邊在edges數組中的位置。CSR的rowIterators是對鏈表的行建立索引,rowIterator[i]指向行i在columns中的起始位置偏移地址。

3. 對于CSC是有列迭代器數組colIterators和rows組成。Rows是一個分塊鏈表,表示按鄰接矩陣的列(即邊的target vertex)大小排序的行的鏈表,如上圖所示,Block的內容如下,Block是固定長度的pair<uint64_t, uint64_t>的數組,多個block組成一個鏈,pair的first是鄰接矩陣的行(即邊的target vertex),second是行所在的邊在edges數組中的位置。colIterators是對鏈表的列建立索引,colIterators[j]指向列j在rows中的起始位置偏移地址。

4 實現步驟
源碼中對csr和csc的構建和動態插入的整體流程:
批量輸入的邊可以用三個數組來表示,source_vertex數組(邊的源頂點),target_vertex數組(邊的目標頂點)和邊的值數組edge_values。
1. 對source_vertex數組進行計數排序,輸出P1和rowptrs,P1是按行從小到大順序對source_vertex進行排序后生成的序列數組;rowptrs[i]指向第i行在P1中的起始偏移地址,P1[rowptrs[i] + k ]表示第i行的第k個元素在edges數組中的位置,其中 0 <= k < (rowptrs[i + 1] - rowptrs[i])。
2. 對target_vertex數組進行計數排序,輸出P2和colptrs,P2是按列從小到大順序對target_vertex進行排序后生成的序列數組;colptrs[j]指向第j列在P2中的起始偏移地址,P2[colptrs[j] + k]表示第j列的第k個元素在edges數組中的位置,其中0 <= k < (colptrs[j + 1] - colptrs[j]);
3. 由于CSR的底層數據結構是分塊鏈表和行迭代器數組指針,所以需要將計數排序后得到的rowptrs、P1和target_vertex轉化為迭代器數組和pair<col,pos>數組。分塊鏈表的block是固定長度的pair<col, pos>數組,所以利用P1和target_vertex來構建pair<col, pos>數組csr_values,第i個輸入的邊在csr_values中的值為{target_vertex[P1[i]], length(edges) + P1[i]}。
3.1 如果圖為空,則用rowptrs和csr_values,來初始化CSR,即將csr_values中的值賦值給CSR的columns,然后將rowptrs的行起始位置轉化為columns中的迭代器,放入到rowIterators中。
3.2 如果圖不為空,則按行向CSR插入數據,一次插入一行,第i行在csr_values中的值是從csr_values[P1[i]]至csr_values[P1[i + 1]]這一段數據。如下圖所示的CSR,rowIterators是一個迭代器的數組,rowIterators[i]存放第i行在columns中的起始位置,rowIterators[i + 1]為第i行的結束位置也是第i + 1行的起始位置;columns是一個分塊鏈表。藍色為第i行的數據,橙色為i+1行的數據。綠色為需要新插入的第i行的數據。
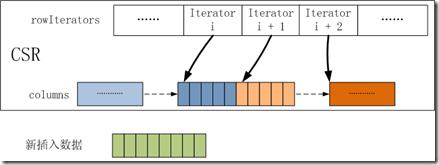
往第i行插入新數據,CSR插入行的步驟如下:
A. 首先會找到rowIterators[i+1]所指向的第i行的結束位置Pos,將此block中位于Pos之后的第i+1行的數據段預先保存起來。
B. 將第i行的新數據拷貝到Pos之后位置上,如果新插入的數據過長,那么會創建一個或多個新的block來容納。
C. 將預先保存的第i+1行的數據重新拷貝到新插入數據之后。
如下圖所示:
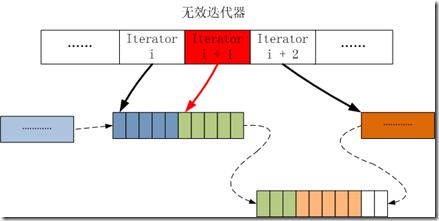
D. 在上述操作完成之后,第i+1行的迭代器指針變為無效,指向的數據位置為第i行新插入的數據,所以要調整第i+1行的迭代器指針。
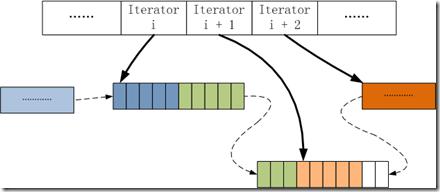
E. ***因為按行將數據插入到CSR中會產生一些空隙,如上圖block中的白色空格,所以會在所有行都插入后,進行repack操作,將空白的內存進行壓縮,變為下圖所示:
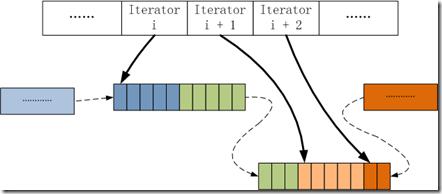
CSC的處理類似于CSR,不在贅述,這種做法的只能支持動態地批量插入,隨機插入的性能開銷太大。
5 Graphlab中相關的類
dynamic_block:圖的動態存儲的底層數據結構采用內存塊的鏈表,可以進行動態的插入。Dynamic_block就是實現這個內存塊的類,dynamic_block組成了一個塊的鏈表。
block_linked_list:分塊鏈表,是使用dynamic_block組成的一個單向鏈表。
dynamic_csr_storage:實現csr和csc動態存儲的數據結構,將底層的數組替換為鏈表,然后使用鏈表的迭代器數組來實現記錄行或列的起始位置。
dynamic_local_graph:實現圖的動態存儲的類,圖的動態存儲針對的情況是批量更新,而不是隨機插入。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





