溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“如何零基礎開始寫Python爬蟲”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“如何零基礎開始寫Python爬蟲”吧!
- ? -并非開始都是最容易的
剛開始對爬蟲不是很了解,又沒有任何的計算機、編程基礎,確實有點懵逼。從哪里開始,哪些是最開始應該學的,哪些應該等到有一定基礎之后再學,也沒個清晰的概念。
因為是 Python 爬蟲嘛,Python 就是必備的咯,那先從 Python 開始吧。于是看了一些教程和書籍,了解基本的數據結構,然后是列表、字典、元組,各種函數和控制語句(條件語句、循環語句)。
學了一段時間,才發現自己還沒接觸到真正的爬蟲呢,而且純理論學習很快就忘了,回去復習又太浪費時間,簡直不要太絕望。把 Python 的基礎知識過了一遍之后,我竟然還沒裝一個可以敲代碼的IDE,想想就哭笑不得。
- ? -開始直接上手
轉機出現在看過一篇爬蟲的技術文章后,清晰的思路和通俗易懂的語言讓我覺得,這才是我想學的爬蟲。于是決定先配一個環境,試試看爬蟲到底是怎么玩的。(當然你可以理解為這是浮躁,但確實每個小白都想去做直觀、有反饋的事情)
因為怕出錯,裝了比較保險的 Anaconda,用自帶的 Jupyter Notebook 作為IDE來寫代碼。看到很多人說因為配置環境出各種BUG,簡直慶幸。很多時候打敗你的,并不是事情本身,說的就是爬蟲配置環境這事兒。
遇到的另一個問題是,Python 的爬蟲可以用很多包或者框架來實現,應該選哪一種呢?我的原則就是是簡單好用,寫的代碼少,對于一個小白來說,性能、效率什么的,統統被我 pass 了。于是開始接觸 urllib、美麗湯(BeautifulSoup),因為聽別人說很簡單。
我上手的***個案例是爬取豆瓣的電影,無數人都推薦把豆瓣作為新手上路的實例,因為頁面簡單且反爬蟲不嚴。照著一些爬取豆瓣電影的入門級例子開始看,從這些例子里面,了解了一點點爬蟲的基本原理:下載頁面、解析頁面、定位并抽取數據。
當然并沒有去系統看 urllib 和 BeautifulSoup 了,我需要把眼前實例中的問題解決,比如下載、解析頁面,基本都是固定的語句,直接用就行,我就先不去學習原理了。

用 urllib 下載和解析頁面的固定句式
當然 BeautifulSoup 中的基本方法是不能忽略的,但也無非是 find、get_text() 之類,信息量很小。就這樣,通過別人的思路和自己查找美麗湯的用法,完成了豆瓣電影的基本信息爬取。
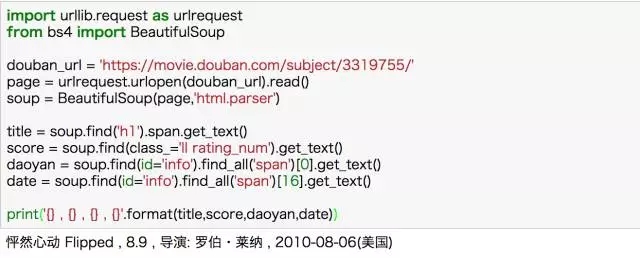
用 BeautifulSoup 爬取豆瓣電影詳情
- ? -爬蟲漸入佳境
有了一些套路和形式,就會有目標,可以接著往下學了。還是豆瓣,自己去摸索爬取更多的信息,爬取多部電影,多個頁面。這個時候就發現基礎不足了,比如爬取多個元素、翻頁、處理多種情況等涉及的語句控制,又比如提取內容時涉及到的字符串、列表、字典的處理,還遠遠不夠。
再回去補充 Python 的基礎知識,就很有針對性,而且能馬上能用于解決問題,也就理解得更深刻。這樣直到把豆瓣的TOP250圖書和電影爬下來,基本算是了解了一個爬蟲的基本過程了。
BeautifulSoup 還算不錯,但需要花一些時間去了解一些網頁的基本知識,否則一些元素的定位和選取還是會頭疼。
后來認識到 xpath 之后相見恨晚,這才是入門必備利器啊,直接Chrome復制就可以了,指哪打哪。即便是要自己寫 xpath,以w3school上幾頁的 xpath 教程,一個小時也可以搞定了。requests 貌似也比 urllib 更好用,但摸索總歸是試錯的過程,試錯成本就是時間。
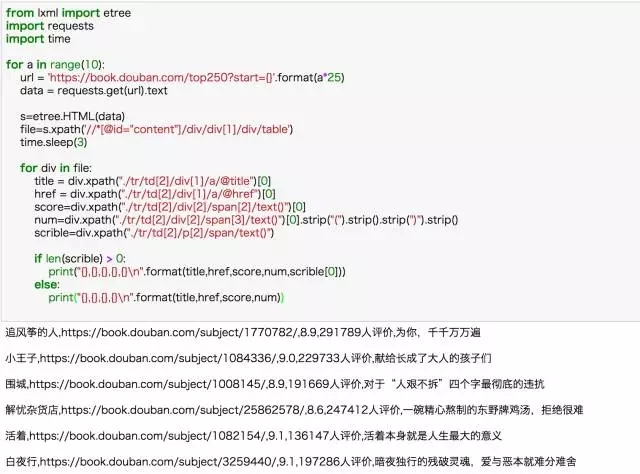
requests+xpath 爬取豆瓣TOP250圖書信息
- ? -跟反爬蟲杠上了
通過 requests+xpath,我可以去爬取很多網站網站了,后來自己練習了小豬的租房信息和當當的圖書數據。爬拉勾的時候就發現問題了,首先是自己的請求根本不會返回信息,原來要將自己的爬蟲偽裝成瀏覽器,終于知道別人代碼中那一坨 headers 信息是干啥的了?。

在爬蟲中添加 headers 信息,偽裝成真實用戶
接著是各種定位不到元素,然后知道了這是異步加載,數據根本不在網頁源代碼中,需要通過抓包來獲取網頁信息。于是在各種 JS、XHR的文件中 preview,尋找包含數據的鏈接。
當然知乎還好,本身加載的文件不多,找到了 json 文件直接獲取對應的數據。(這里要安利一個chrome插件:jsonview,讓小白輕松看懂 json 文件)
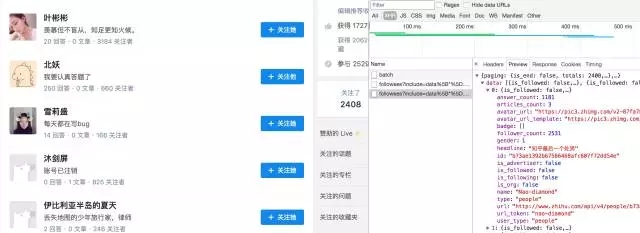
瀏覽器抓取 JavaScript 加載的數據
在這里就對反爬蟲有了認識,當然這還是最基本的,更嚴格的IP限制、驗證碼、文字加密等等,可能還會遇到很多難題。但是目前的問題能夠解決不就很好了嗎,逐個擊破才能更高效地學習。
比如后來在爬其他網站的時候就被封了IP,簡單的可以通過 time.sleep() 控制爬取頻率的方法解決,限制比較嚴格或者需要保證爬取速度,就要用代理IP來解決。
當然,后來也試了一下 Selenium,這個就真的是按照真實的用戶瀏覽行為(點擊、搜索、翻頁)來實現爬蟲,所以對于那些反爬蟲特別厲害的網站,又沒有辦法解決,Selenium 是一個超級好用的東東,雖然速度稍微慢點。
- ? -嘗試強大的 Scrapy 框架
有了 requests+xpath 和抓包大法,就可以做很多事情了,豆瓣各分類下的電影,58同城、知乎、拉勾這些網站基本都沒問題。不過,當爬取的數據量級很大,而且需要靈活地處理各個模塊的話,會顯得很力不從心。
于是了解到強大的 Scrapy 框架,它不僅能便捷地構建 Request,還有強大的 Selector 能夠方便地解析 Response,然而最讓人驚喜的還是它超高的性能,可以將爬蟲工程化、模塊化。
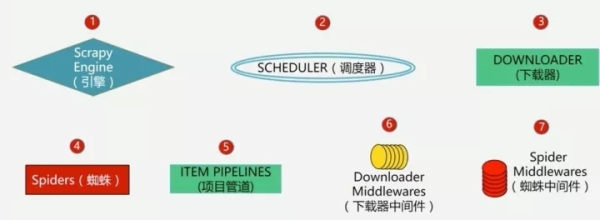
Scrapy 框架的基本組件
學會 Scrapy,自己去嘗試搭建了簡單的爬蟲框架,在做大規模數據爬去的時候能夠結構化、工程化地思考大規模的爬取問題,這使我可以從爬蟲工程的維度去思考問題。
當然 Scrapy 本身的 selector 、中間件、spider 等會比較難理解,還是建議結合具體的例子,參考別人的代碼,去理解其中實現的過程,這樣能夠更好地理解。
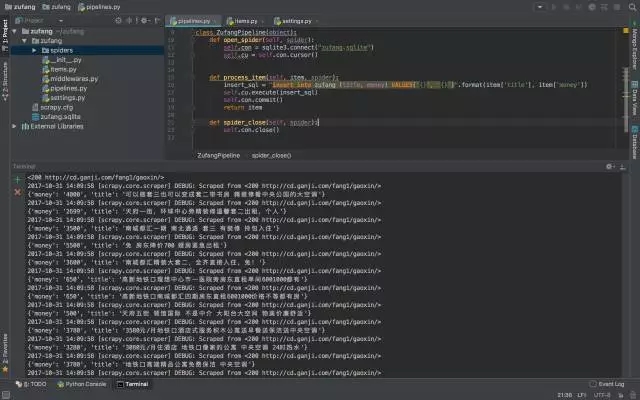
用 Scrapy 爬取了大量租房信息
- ? -本地文件搞不動了,上數據庫
爬回來大量的數據之后就發現,本地的文件存起來非常不方便,即便存下來了,打開大文件電腦會卡得很嚴重。怎么辦呢?果斷上數據庫啊,于是開始入坑 MongoDB。結構化、非結構化的數據都能夠存儲,安裝好 PyMongo,就可以方便地在 Python 中操作數據庫了。
MongoDB 本身安裝會比較麻煩,如果自己一個人去折騰,很有可能會陷入困境。剛開始安裝的時候也是出現各種BUG,幸得大神小X指點,解決了很多問題。
當然對于爬蟲這一塊,并不需要多么高深的數據庫技術,主要是數據的入庫和提取,順帶掌握了基本的插入、刪除等操作。總之,能夠滿足高效地提取爬下來的數據就OK了。
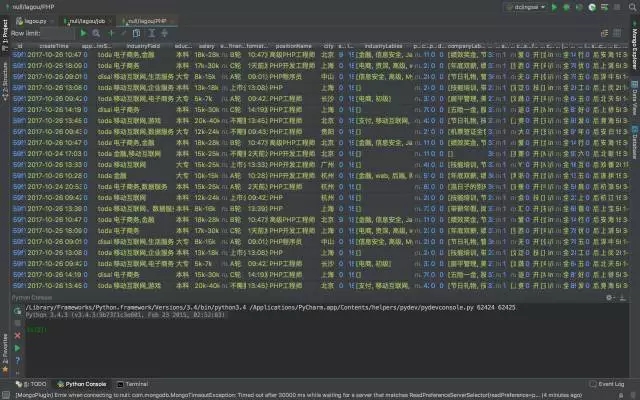
爬取拉勾招聘數據并用 MongoDB 存儲
- ? -傳說中的分布式爬蟲
這個時候,基本上很大一部分的網頁都能爬了,瓶頸就集中到爬取大規模數據的效率。因為學了 Scrapy,于是自然地接觸到一個很厲害的名字:分布式爬蟲。
分布式這個東西,一聽不明覺厲,感覺很恐怖,但其實就是利用多線程的原理讓多個爬蟲同時工作,除了前面學過的 Scrapy 和 MongoDB,好像還需要了解 Redis。
Scrapy 用于做基本的頁面爬取,MongoDB 用于存儲爬取的數據,Redis 則用來存儲要爬取的網頁隊列,也就是任務隊列。
分布式這東西看起來很嚇人,但其實分解開來,循序漸進地學習,也不過如此。
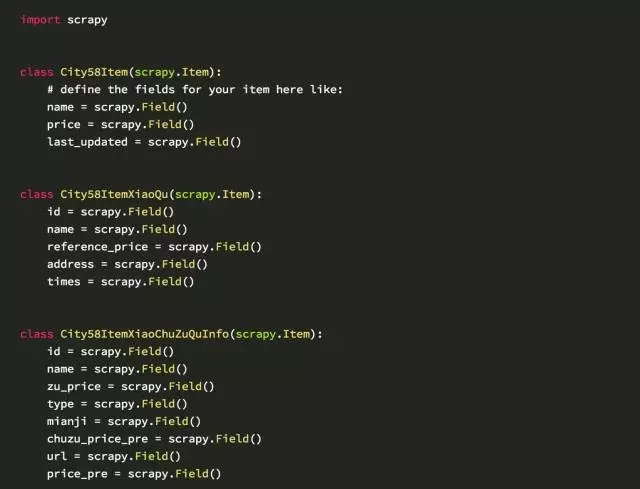
分布式爬58同城:定義項目內容部分
零基礎學習爬蟲,坑確實比較多,總結如下:
1.環境配置,各種安裝包、環境變量,對小白太不友好;
2.缺少合理的學習路徑,上來 Python、HTML 各種學,極其容易放棄;
3.Python有很多包、框架可以選擇,但小白不知道哪個更友好;
4.遇到問題甚至不知道如何描述,更不用說去尋找解決辦法;
5.網上的資料非常零散,而且對小白不友好,很多看起來云里霧里;
6.有些東西看似懂了,但結果自己寫代碼還是很困難;
到此,相信大家對“如何零基礎開始寫Python爬蟲”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





