溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“有哪些高性能開發”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“有哪些高性能開發”吧!
I/O優化:零拷貝技術
上面的工作線程,從磁盤讀文件、再通過網絡發送數據,數據從磁盤到網絡,兜兜轉轉需要拷貝四次,其中CPU親自搬運都需要兩次。
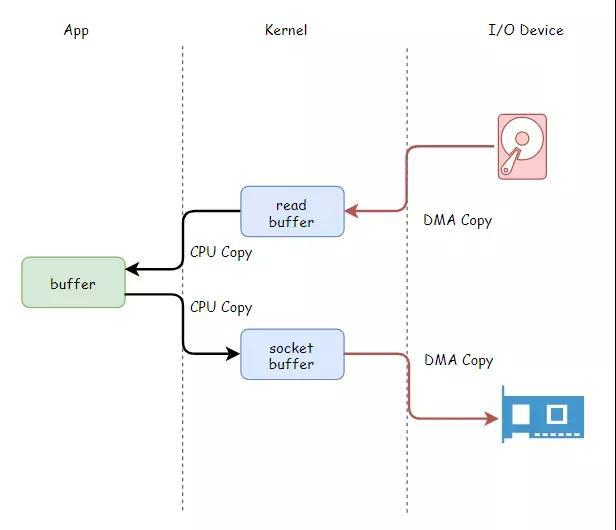
零拷貝技術,解放CPU,文件數據直接從內核發送出去,無需再拷貝到應用程序緩沖區,白白浪費資源。

Linux API:
ssize_t sendfile( int out_fd, int in_fd, off_t *offset, size_t count );
函數名字已經把函數的功能解釋的很明顯了:發送文件。指定要發送的文件描述符和網絡套接字描述符,一個函數搞定!
用上了零拷貝技術后開發了2.0版本,圖片加載速度明顯有了提升。不過老板發現同時訪問的人變多了以后,又變慢了,又讓你繼續優化。這個時候,你需要:
I/O優化:多路復用技術
前面的版本中,每個線程都要阻塞在recv等待對方的請求,這來訪問的人多了,線程開的就多了,大量線程都在阻塞,系統運轉速度也隨之下降。
這個時候,你需要多路復用技術,使用select模型,將所有等待(accept、recv)都放在主線程里,工作線程不需要再等待。
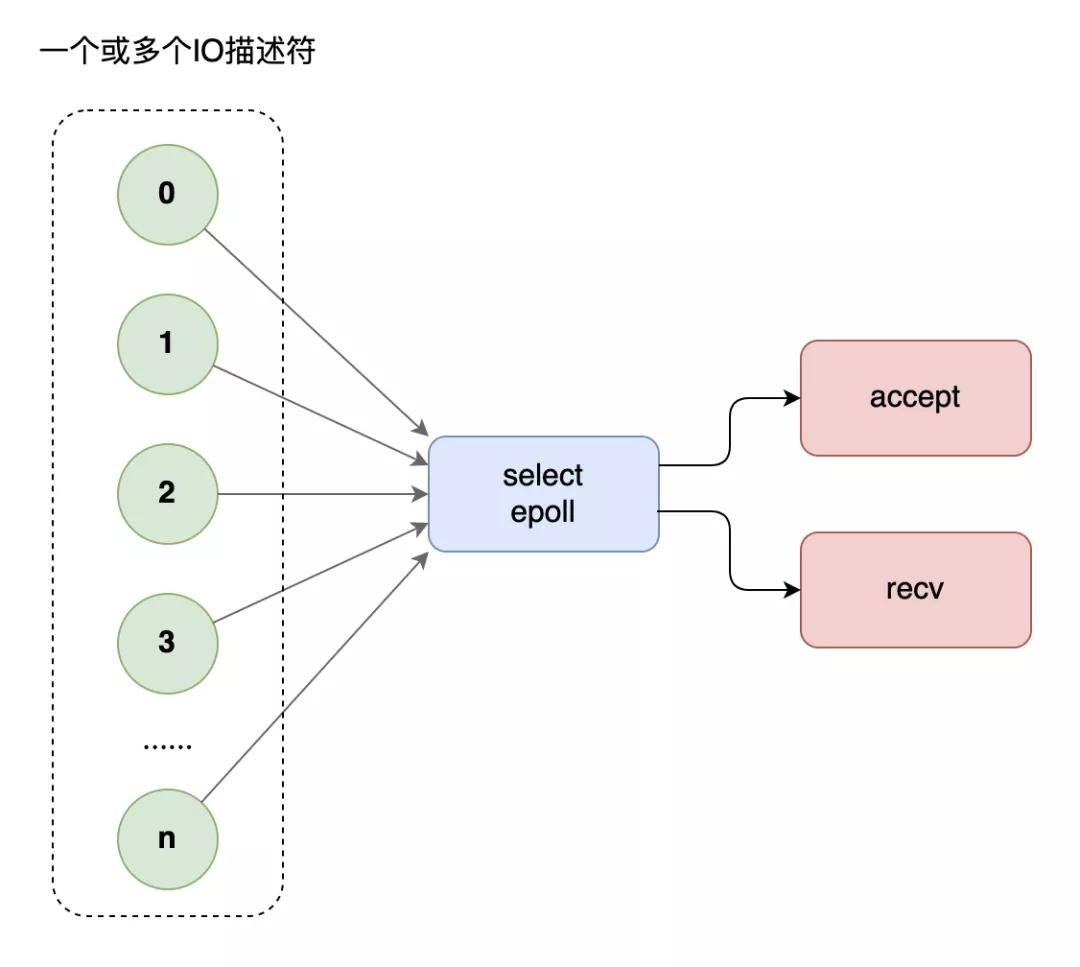
過了一段時間之后,網站訪問的人越來越多了,就連select也開始有點應接不暇,老板繼續讓你優化性能。
這個時候,你需要升級多路復用模型為epoll。
select有三弊,epoll有三優。
select底層采用數組來管理套接字描述符,同時管理的數量有上限,一般不超過幾千個,epoll使用樹和鏈表來管理,同時管理數量可以很大。
select不會告訴你到底哪個套接字來了消息,你需要一個個去詢問。epoll直接告訴你誰來了消息,不用輪詢。
select進行系統調用時還需要把套接字列表在用戶空間和內核空間來回拷貝,循環中調用select時簡直浪費。epoll統一在內核管理套接字描述符,無需來回拷貝。
用上了epoll多路復用技術,開發了3.0版本,你的網站能同時處理很多用戶請求了。
但是貪心的老板還不滿足,不舍得升級硬件服務器,卻讓你進一步提高服務器的吞吐量。你研究后發現,之前的方案中,工作線程總是用到才創建,用完就關閉,大量請求來的時候,線程不斷創建、關閉、創建、關閉,開銷挺大的。這個時候,你需要:
線程池技術
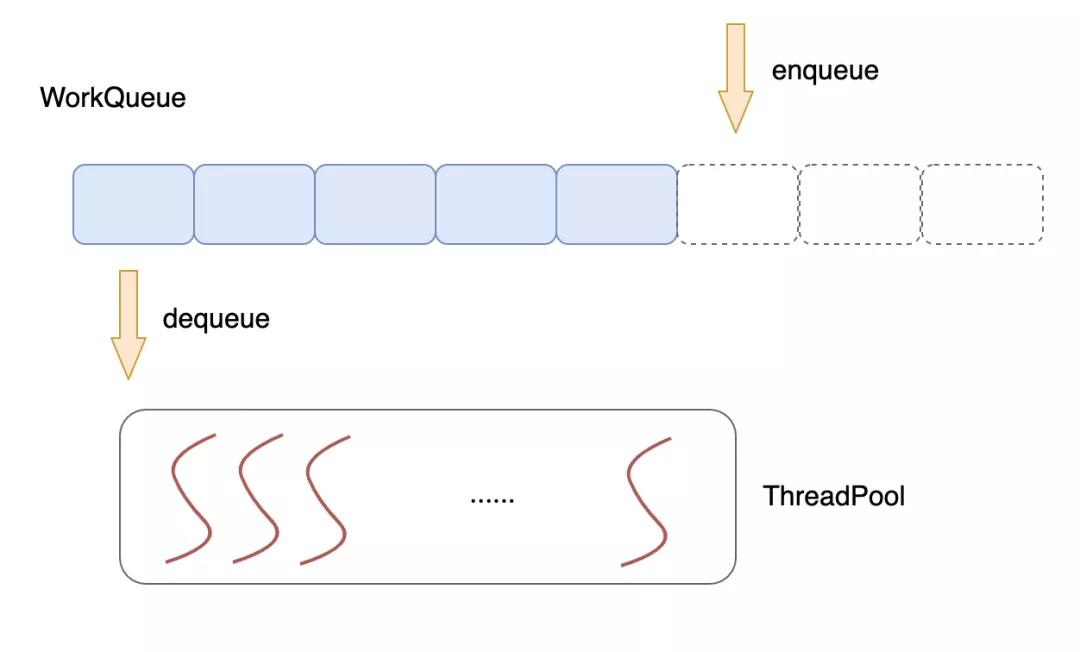
我們可以在程序一開始啟動后就批量啟動一波工作線程,而不是在有請求來的時候才去創建,使用一個公共的任務隊列,請求來臨時,向隊列中投遞任務,各個工作線程統一從隊列中不斷取出任務來處理,這就是線程池技術。
多線程技術的使用一定程度提升了服務器的并發能力,但同時,多個線程之間為了數據同步,常常需要使用互斥體、信號、條件變量等手段來同步多個線程。這些重量級的同步手段往往會導致線程在用戶態/內核態多次切換,系統調用,線程切換都是不小的開銷。
在線程池技術中,提到了一個公共的任務隊列,各個工作線程需要從中提取任務進行處理,這里就涉及到多個工作線程對這個公共隊列的同步操作。
有沒有一些輕量級的方案來實現多線程安全的訪問數據呢?這個時候,你需要:
無鎖編程技術
多線程并發編程中,遇到公共數據時就需要進行線程同步。而這里的同步又可以分為阻塞型同步和非阻塞型同步。
阻塞型同步好理解,我們常用的互斥體、信號、條件變量等這些操作系統提供的機制都屬于阻塞型同步,其本質都是要加“鎖”。

與之對應的非阻塞型同步就是在無鎖的情況下實現同步,目前有三類技術方案:
Wait-free
Lock-free
Obstruction-free
三類技術方案都是通過一定的算法和技術手段來實現不用阻塞等待而實現同步,這其中又以Lock-free最為應用廣泛。
Lock-free能夠廣泛應用得益于目前主流的CPU都提供了原子級別的read-modify-write原語,這就是著名的CAS(Compare-And-Swap)操作。在Intel x86系列處理器上,就是cmpxchg系列指令。
// 通過CAS操作實現Lock-free do { ... } while(!CAS(ptr,old_data,new_data ))我們常常見到的無鎖隊列、無鎖鏈表、無鎖HashMap等數據結構,其無鎖的核心大都來源于此。在日常開發中,恰當的運用無鎖化編程技術,可以有效地降低多線程阻塞和切換帶來的額外開銷,提升性能。
服務器上線了一段時間,發現服務經常崩潰異常,排查發現是工作線程代碼bug,一崩潰整個服務都不可用了。于是你決定把工作線程和主線程拆開到不同的進程中,工作線程崩潰不能影響整體的服務。這個時候出現了多進程,你需要:
進程間通信技術
提起進程間通信,你能想到的是什么?
管道
命名管道
socket
消息隊列
信號
信號量
共享內存
以上各種進程間通信的方式詳細介紹和比較,推薦一篇文章一文掌握進程間通信,這里不再贅述。
對于本地進程間需要高頻次的大量數據交互,首推共享內存這種方案。
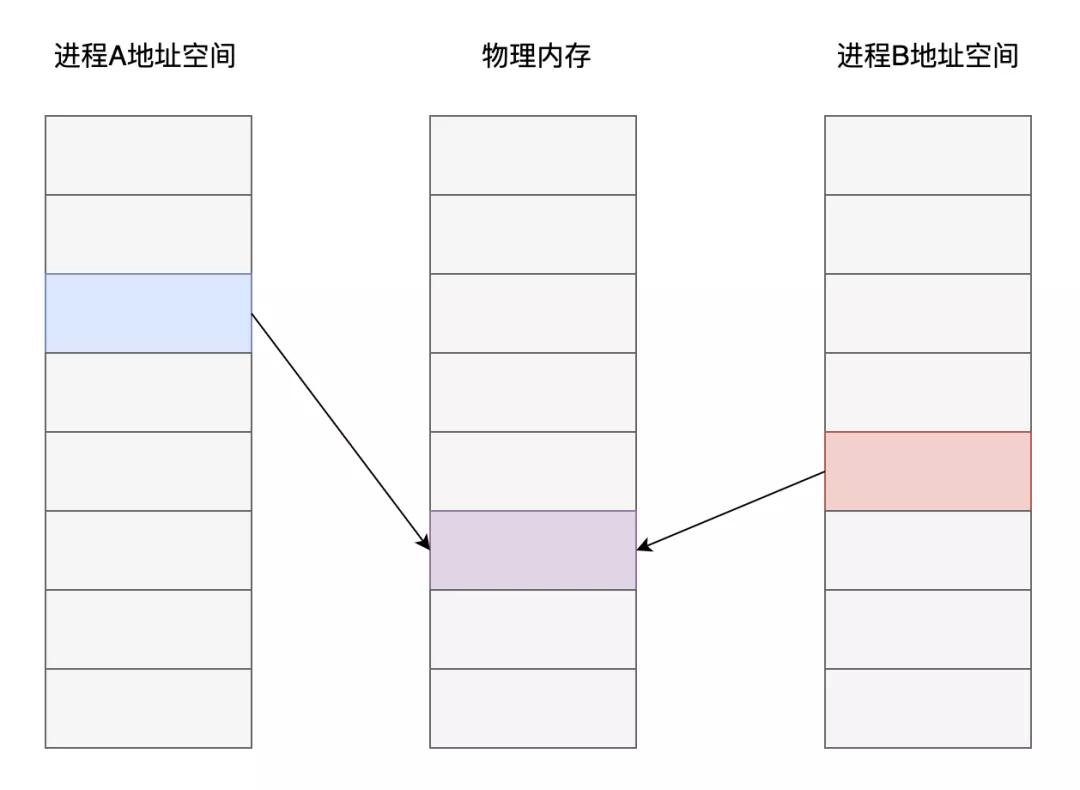
現代操作系統普遍采用了基于虛擬內存的管理方案,在這種內存管理方式之下,各個進程之間進行了強制隔離。程序代碼中使用的內存地址均是一個虛擬地址,由操作系統的內存管理算法提前分配映射到對應的物理內存頁面,CPU在執行代碼指令時,對訪問到的內存地址再進行實時的轉換翻譯。
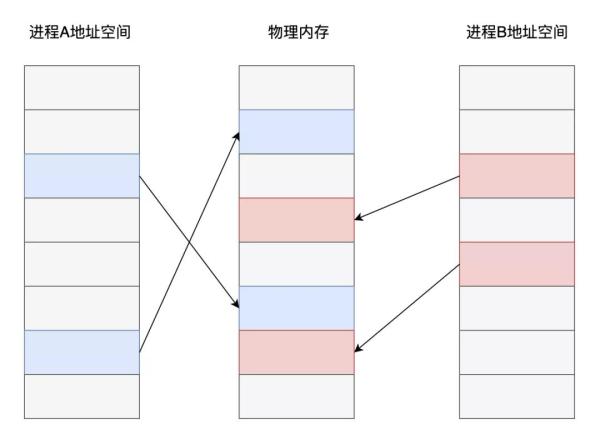
從上圖可以看出,不同進程之中,雖然是同一個內存地址,最終在操作系統和CPU的配合下,實際存儲數據的內存頁面卻是不同的。
而共享內存這種進程間通信方案的核心在于:如果讓同一個物理內存頁面映射到兩個進程地址空間中,雙方不是就可以直接讀寫,而無需拷貝了嗎?
當然,共享內存只是最終的數據傳輸載體,雙方要實現通信還得借助信號、信號量等其他通知機制。
用上了高性能的共享內存通信機制,多個服務進程之間就可以愉快的工作了,即便有工作進程出現Crash,整個服務也不至于癱瘓。
不久,老板增加需求了,不再滿足于只能提供靜態網頁瀏覽了,需要能夠實現動態交互。這一次老板還算良心,給你加了一臺硬件服務器。
于是你用Java/PHP/Python等語言搞了一套web開發框架,單獨起了一個服務,用來提供動態網頁支持,和原來等靜態內容服務器配合工作。
這個時候你發現,靜態服務和動態服務之間經常需要通信。
一開始你用基于HTTP的RESTful接口在服務器之間通信,后來發現用JSON格式傳輸數據效率低下,你需要更高效的通信方案。
這個時候你需要:
RPC && 序列化技術
什么是RPC技術?
RPC全稱Remote Procedure Call,遠程過程調用。我們平時編程中,隨時都在調用函數,這些函數基本上都位于本地,也就是當前進程某一個位置的代碼塊。但如果要調用的函數不在本地,而在網絡上的某個服務器上呢?這就是遠程過程調用的來源。
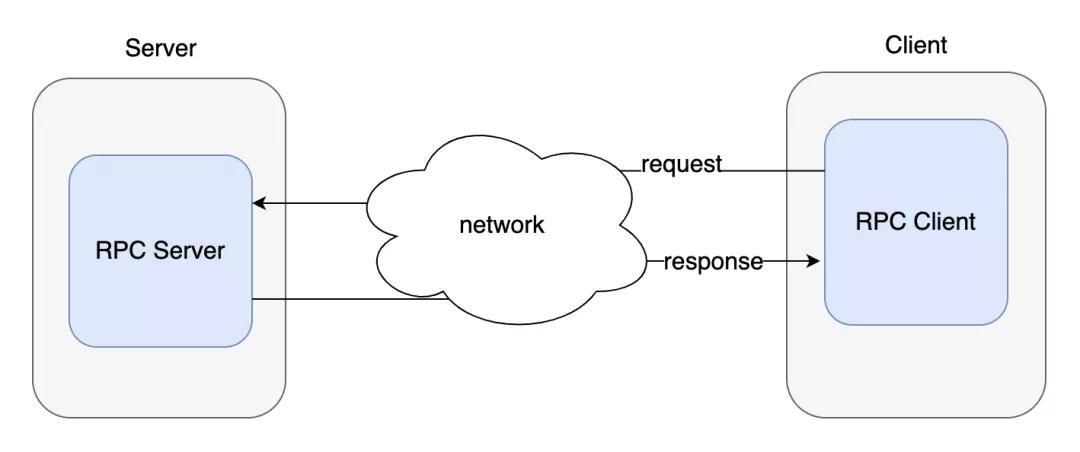
從圖中可以看出,通過網絡進行功能調用,涉及參數的打包解包、網絡的傳輸、結果的打包解包等工作。而其中對數據進行打包和解包就需要依賴序列化技術來完成。
什么是序列化技術?

序列化簡單來說,是將內存中的對象轉換成可以傳輸和存儲的數據,而這個過程的逆向操作就是反序列化。序列化 && 反序列化技術可以實現將內存對象在本地和遠程計算機上搬運。好比把大象關進冰箱門分三步:
將本地內存對象編碼成數據流
通過網絡傳輸上述數據流
將收到的數據流在內存中構建出對象
序列化技術有很多免費開源的框架,衡量一個序列化框架的指標有這么幾個:
是否支持跨語言使用,能支持哪些語言
是否只是單純的序列化功能,包不包含RPC框架
序列化傳輸性能
擴展支持能力(數據對象增刪字段后,前后的兼容性)
是否支持動態解析(動態解析是指不需要提前編譯,根據拿到的數據格式定義文件立即就能解析)
下面流行的三大序列化框架protobuf、thrift、avro的對比:
ProtoBuf:
廠商:Google
支持語言:C++、Java、Python等
動態性支持:較差,一般需要提前編譯
是否包含RPC:否
簡介:ProtoBuf是谷歌出品的序列化框架,成熟穩定,性能強勁,很多大廠都在使用。自身只是一個序列化框架,不包含RPC功能,不過可以與同是Google出品的GPRC框架一起配套使用,作為后端RPC服務開發的黃金搭檔。

缺點是對動態性支持較弱,不過在更新版本中這一現象有待改善。總體來說,ProtoBuf都是一款非常值得推薦的序列化框架。
Thrift
廠商:Facebook
支持語言:C++、Java、Python、PHP、C#、Go、JavaScript等
動態性支持:差
是否包含RPC:是
簡介:這是一個由Facebook出品的RPC框架,本身內含二進制序列化方案,但Thrift本身的RPC和數據序列化是解耦的,你甚至可以選擇XML、JSON等自定義的數據格式。在國內同樣有一批大廠在使用,性能方面和ProtoBuf不分伯仲。缺點和ProtoBuf一樣,對動態解析的支持不太友好。
Avro
支持語言:C、C++、Java、Python、C#等
動態性支持:好
是否包含RPC:是
簡介:這是一個源自于Hadoop生態中的序列化框架,自帶RPC框架,也可獨立使用。相比前兩位最大的優勢就是支持動態數據解析。

為什么我一直在說這個動態解析功能呢?在之前的一段項目經歷中,軒轅就遇到了三種技術的選型,擺在我們面前的就是這三種方案。需要一個C++開發的服務和一個Java開發的服務能夠進行RPC。
Protobuf和Thrift都需要通過“編譯”將對應的數據協議定義文件編譯成對應的C++/Java源代碼,然后合入項目中一起編譯,從而進行解析。
當時,Java項目組同學非常強硬的拒絕了這一做法,其理由是這樣編譯出來的強業務型代碼融入他們的業務無關的框架服務,而業務是常變的,這樣做不夠優雅。
最后,經過測試,最終選擇了AVRO作為我們的方案。Java一側只需要動態加載對應的數據格式文件,就能對拿到的數據進行解析,并且性能上還不錯。(當然,對于C++一側還是選擇了提前編譯的做法)
自從你的網站支持了動態能力,免不了要和數據庫打交道,但隨著用戶的增長,你發現數據庫的查詢速度越來越慢。
這個時候,你需要:
數據庫索引技術
想想你手上有一本數學教材,但是目錄被人給撕掉了,現在要你翻到講三角函數的那一頁,你該怎么辦?
沒有了目錄,你只有兩種辦法,要么一頁一頁的翻,要么隨機翻,直到找到三角函數的那一頁。
對于數據庫也是一樣的道理,如果我們的數據表沒有“目錄”,那要查詢滿足條件的記錄行,就得全表掃描,那可就惱火了。所以為了加快查詢速度,得給數據表也設置目錄,在數據庫領域中,這就是索引。
一般情況下,數據表都會有多個字段,那根據不同的字段也就可以設立不同的索引。
索引的分類
主鍵索引
聚集索引
非聚集索引
主鍵我們都知道,是唯一標識一條數據記錄的字段(也存在多個字段一起來唯一標識數據記錄的聯合主鍵),那與之對應的就是主鍵索引了。
聚集索引是指索引的邏輯順序與表記錄的物理存儲順序一致的索引,一般情況下主鍵索引就符合這個定義,所以一般來說主鍵索引也是聚集索引。但是,這不是絕對的,在不同的數據庫中,或者在同一個數據庫下的不同存儲引擎中還是有不同。
聚集索引的葉子節點直接存儲了數據,也是數據節點,而非聚集索引的葉子節點沒有存儲實際的數據,需要二次查詢。
索引的實現原理
索引的實現主要有三種:
B+樹
哈希表
位圖
其中,B+樹用的最多,其特點是樹的節點眾多,相較于二叉樹,這是一棵多叉樹,是一個扁平的胖樹,減少樹的深度有利于減少磁盤I/O次數,適宜數據庫的存儲特點。

哈希表實現的索引也叫散列索引,通過哈希函數來實現數據的定位。哈希算法的特點是速度快,常數階的時間復雜度,但缺點是只適合準確匹配,不適合模糊匹配和范圍搜索。
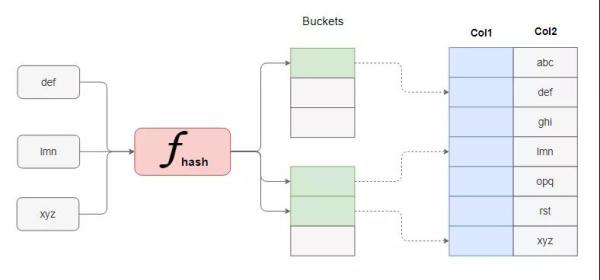
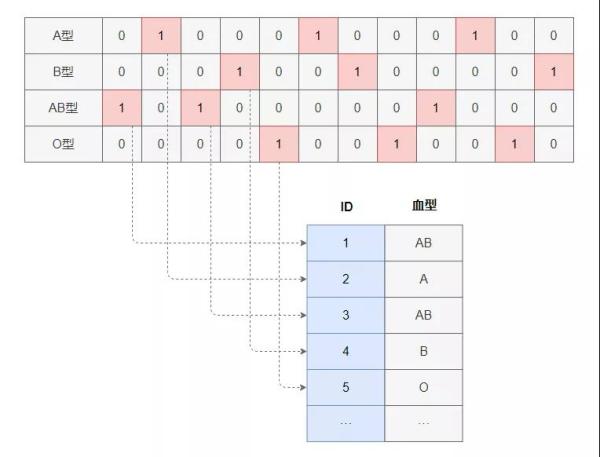
位圖索引相對就少見了。想象這么一個場景,如果某個字段的取值只有有限的少數幾種可能,比如性別、省份、血型等等,針對這樣的字段如果用B+樹作為索引的話會出現什么情況?會出現大量索引值相同的葉子節點,這實際上是一種存儲浪費。
位圖索引正是基于這一點進行優化,針對字段取值只有少量有限項,數據表中該列字段出現大量重復時,就是位圖索引一展身手的時機。
所謂位圖,就是Bitmap,其基本思想是對該字段每一個取值建立一個二進制位圖來標記數據表的每一條記錄的該列字段是否是對應取值。
索引雖好,但也不可濫用,一方面索引最終是要存儲到磁盤上的,無疑會增加存儲開銷。另外更重要的是,數據表的增刪操作一般會伴隨對索引的更新,因此對數據庫的寫入速度也是會有一定影響。
你的網站現在訪問量越來越大了,同時在線人數大大增長。然而,大量用戶的請求帶來了后端程序對數據庫大量的訪問。漸漸的,數據庫的瓶頸開始出現,無法再支持日益增長的用戶量。老板再一次給你下達了性能提升的任務。
緩存技術 && 布隆過濾器
從物理CPU對內存數據的緩存到瀏覽器對網頁內容的緩存,緩存技術遍布于計算機世界的每一個角落。
面對當前出現的數據庫瓶頸,同樣可以用緩存技術來解決。
每次訪問數據庫都需要數據庫進行查表(當然,數據庫自身也有優化措施),反映到底層就是進行一次或多次的磁盤I/O,但凡涉及I/O的就會慢下來。如果是一些頻繁用到但又不會經常變化的數據,何不將其緩存在內存中,不必每一次都要找數據庫要,從而減輕對數據庫對壓力呢?

有需求就有市場,有市場就會有產品,以memcached和Redis為代表的內存對象緩存系統應運而生。
緩存系統有三個著名的問題:
緩存穿透: 緩存設立的目的是為了一定層面上截獲到數據庫存儲層的請求。穿透的意思就在于這個截獲沒有成功,請求最終還是去到了數據庫,緩存沒有產生應有的價值。
緩存擊穿: 如果把緩存理解成一面擋在數據庫面前的墻壁,為數據庫“抵御”查詢請求,所謂擊穿,就是在這面墻壁上打出了一個洞。一般發生在某個熱點數據緩存到期,而此時針對該數據的大量查詢請求來臨,大家一股腦的懟到了數據庫。
緩存雪崩: 理解了擊穿,那雪崩就更好理解了。俗話說得好,擊穿是一個人的雪崩,雪崩是一群人的擊穿。如果緩存這堵墻上處處都是洞,那這面墻還如何屹立?吃棗藥丸。
關于這三個問題的更詳細闡述,推薦一篇文章什么是緩存系統的三座大山。
有了緩存系統,我們就可以在向數據庫請求之前,先詢問緩存系統是否有我們需要的數據,如果有且滿足需要,我們就可以省去一次數據庫的查詢,如果沒有,我們再向數據庫請求。
注意,這里有一個關鍵的問題,如何判斷我們要的數據是不是在緩存系統中呢?
進一步,我們把這個問題抽象出來:如何快速判斷一個數據量很大的集合中是否包含我們指定的數據?
這個時候,就是布隆過濾器大顯身手的時候了,它就是為了解決這個問題而誕生的。那布隆過濾器是如何解決這個問題的呢?
先回到上面的問題中來,這其實是一個查找問題,對于查找問題,最常用的解決方案是搜索樹和哈希表兩種方案。
因為這個問題有兩個關鍵點:快速、數據量很大。樹結構首先得排除,哈希表倒是可以做到常數階的性能,但數據量大了以后,一方面對哈希表的容量要求巨大,另一方面如何設計一個好的哈希算法能夠做到如此大量數據的哈希映射也是一個難題。
對于容量的問題,考慮到只需要判斷對象是否存在,而并非拿到對象,我們可以將哈希表的表項大小設置為1個bit,1表示存在,0表示不存在,這樣大大縮小哈希表的容量。
而對于哈希算法的問題,如果我們對哈希算法要求低一些,那哈希碰撞的機率就會增加。那一個哈希算法容易沖突,那就多弄幾個,多個哈希函數同時沖突的概率就小的多。
布隆過濾器就是基于這樣的設計思路:
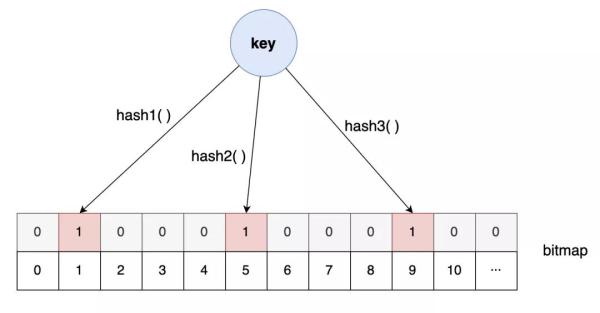
當設置對應的key-value時,按照一組哈希算法的計算,將對應比特位置1。
但當對應的key-value刪除時,卻不能將對應的比特位置0,因為保不準其他某個key的某個哈希算法也映射到了同一個位置。
也正是因為這樣,引出了布隆過濾器的另外一個重要特點:布隆過濾器判定存在的實際上不一定存在,但判定不存在的則一定不存在。
你們公司網站的內容越來越多了,用戶對于快速全站搜索的需求日益強烈。這個時候,你需要:
全文搜索技術
對于一些簡單的查詢需求,傳統的關系型數據庫尚且可以應付。但搜索需求一旦變得復雜起來,比如根據文章內容關鍵字、多個搜索條件但邏輯組合等情況下,數據庫就捉襟見肘了,這個時候就需要單獨的索引系統來進行支持。

如今行業內廣泛使用的ElasticSearch(簡稱ES)就是一套強大的搜索引擎。集全文檢索、數據分析、分布式部署等優點于一身,成為企業級搜索技術的首選。

ES使用RESTful接口,使用JSON作為數據傳輸格式,支持多種查詢匹配,為各主流語言都提供了SDK,易于上手。
另外,ES常常和另外兩個開源軟件Logstash、Kibana一起,形成一套日志收集、分析、展示的完整解決方案:ELK架構。

其中,Logstash負責數據的收集、解析,ElasticSearch負責搜索,Kibana負責可視化交互,成為不少企業級日志分析管理的鐵三角。
無論我們怎么優化,一臺服務器的力量終究是有限的。公司業務發展迅猛,原來的服務器已經不堪重負,于是公司采購了多臺服務器,將原有的服務都部署了多份,以應對日益增長的業務需求。
現在,同一個服務有多個服務器在提供服務了,需要將用戶的請求均衡的分攤到各個服務器上,這個時候,你需要:
負載均衡技術
顧名思義,負載均衡意為將負載均勻平衡分配到多個業務節點上去。
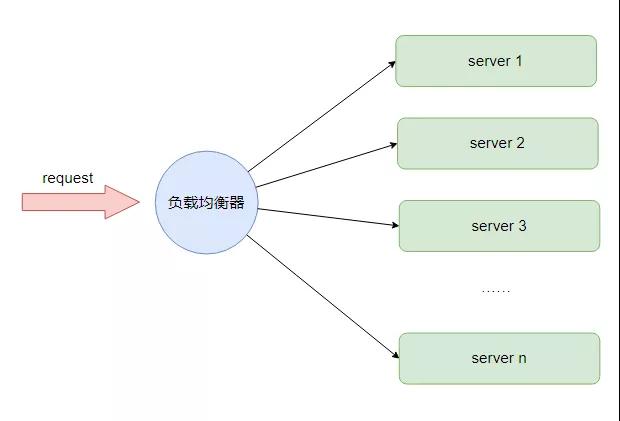
和緩存技術一樣,負載均衡技術同樣存在于計算機世界到各個角落。
按照均衡實現實體,可以分為軟件負載均衡(如LVS、Nginx、HAProxy)和硬件負載均衡(如A10、F5)。
按照網絡層次,可以分為四層負載均衡(基于網絡連接)和七層負載均衡(基于應用內容)。
按照均衡策略算法,可以分為輪詢均衡、哈希均衡、權重均衡、隨機均衡或者這幾種算法相結合的均衡。
而對于現在遇到等問題,可以使用nginx來實現負載均衡,nginx支持輪詢、權重、IP哈希、最少連接數目、最短響應時間等多種方式的負載均衡配置。
輪詢
upstream web-server { server 192.168.1.100; server 192.168.1.101; }權重
upstream web-server { server 192.168.1.100 weight=1; server 192.168.1.101 weight=2; }IP哈希值
upstream web-server { ip_hash; server 192.168.1.100 weight=1; server 192.168.1.101 weight=2; }最少連接數目
upstream web-server { ip_hash; server 192.168.1.100 weight=1; server 192.168.1.101 weight=2; }最短響應時間
upstream web-server { server 192.168.1.100 weight=1; server 192.168.1.101 weight=2; fair; }感謝各位的閱讀,以上就是“有哪些高性能開發”的內容了,經過本文的學習后,相信大家對有哪些高性能開發這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





