溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“怎么使用Python進行數據科學研究”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“怎么使用Python進行數據科學研究”吧!
1. 為何選擇Python?
Python作為一種語言,十項全能,易于學習,安裝簡單。同時有很多擴展,非常適合進行數據科學研究。像Google、Instagram、Youtube、Reddit等明星網站都在用Python搭建核心業務。
Python不僅僅用于數據科學,還使用Python來做更多的工作——如編寫腳本、構建API、構建網站等等。
關于Python的幾點重要事項需要注意。
目前,有兩種常用的Python版本。它們是版本2和3。大多數教程和本文將默認使用的是Python的***版本Python 3。但有時會遇到使用Python 2的書籍或文章。版本之間的差異并不大,但有時在運行版本3時復制和粘貼版本2代碼將無法正常工作,因此需要進行一些輕微的編輯。
要注意Python十分介意空白的地方(即空格和返回字符)。如果把空格放在錯誤的地方,程序很可能會產生錯誤。
與其他語言相比,Python不需要管理內存,也有良好的社區支持。
2. 安裝Python
安裝用于數據科學的Python的***方法是使用Anaconda發行版。
Anacoda有你使用Python進行數據科學研究所需的資料,包括將在本文中介紹的許多軟件包。
單擊Products - > Distribution并向下滾動,可以看到適用于Mac,Windows和Linux的安裝程序。即使Mac上已經有Python,也應該考慮安裝Anaconda發行版,因為有利于安裝其他軟件包。
此外,還可以去官方Python網站下載安裝程序。
包管理器:
包是一段Python代碼,而不是語言的一部分,包對于執行某些任務非常有幫助。通過包,我們可以復制并粘貼代碼,然后將其放在Python解釋器(用于運行代碼)可以找到的地方。
但這很麻煩,每次啟動新項目或更新包時都必須進行內容的復制和粘貼操作。因此,我們可以使用包管理器。Anaconda發行版中自帶包管理器。如果沒有,建議安裝pip。
無論選擇哪一個,都可以在終端(或命令提示符)上使用命令輕松安裝和更新軟件包。
3. 使用Python進行數據科學研究
Python迎合許多不同開發人員的技術要求(Web開發人員,數據分析師,數據科學家),因此使用該語言具有很多不同的編程方法。
Python是一種解釋型語言,不必將代碼編譯成可執行文件,只需將包含代碼的文本文檔傳遞給解釋器即可。
快速瀏覽一下與Python解釋器交互的不同方法吧。
(1) 在終端
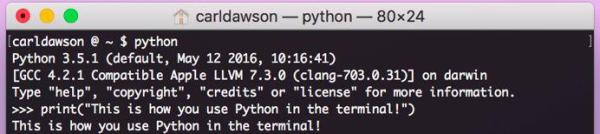
如果打開終端(或命令提示符)并鍵入單詞'Python',將啟動一個shell會話。可以在對話中輸入有效的Python命令,以實現相應的程序操作。
這可以是快速調試某些東西的好方法,但即使是一個小項目,在終端中調試也很困難。
(2) 使用文本編輯器


如果你在文本文件中編寫一系列Python命令并使用.py擴展名保存它,則可以使用終端導航到該文件,并通過輸入python YOUR_FILE_NAME.py來運行該程序。
這與在終端中逐個輸入命令基本相同,只是更容易修復錯誤并更改程序的功能。
(3) 在IDE中

IDE是一種專業級軟件,可以進行軟件項目管理。
IDE的一個好處是,使用調試功能可以告訴你在嘗試運行程序之前出錯的位置。
某些IDE附帶了項目模板(用于特定任務),你可以使用這些模板根據***實踐設置項目。
(4) Jupyter Notebooks
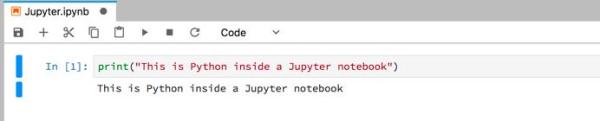
這些方法都不是用python進行數據科學的***方式,***是使用Jupyter Notebooks。
Jupyter Notebooks使你能夠一次運行一“塊”代碼,這意味著你可以在決定下一步做什么之前看到輸出信息-這在數據科學項目中非常重要,我們經常需要在獲取輸出之前查看圖表。
如果你正在使用Anaconda,且已經安裝了Jupyter lab。要啟動它,只需要在終端中輸入'jupyter lab'即可。
如果正在使用pip,則必須使用命令'python pip install jupyter'安裝Jupyter lab。
4. Python中的數字計算
NumPy軟件包中包含許多有用的函數,用于執行數據科學工作所需的數學運算。
它作為Anaconda發行版的一部分安裝,并且使用pip安裝,就像安裝Jupyter Notbooks一樣簡單('pip install numpy')。
我們在數據科學中需要做的最常見的數學運算是矩陣乘法,計算向量的點積,改變數組的數據類型以及創建數組!
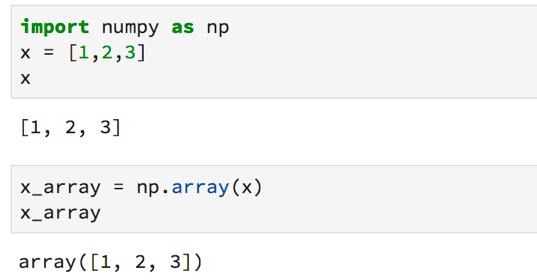
以下是如何將列表編入NumPy數組的方法:
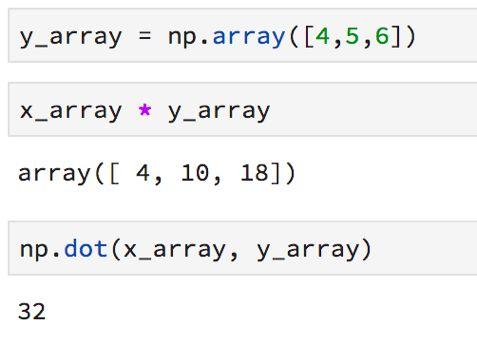
以下是如何在NumPy中進行數組乘法和計算點積的方法:
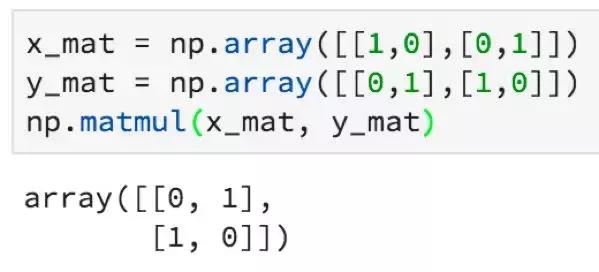
以下是如何在NumPy中進行矩陣乘法:
5. Python中的統計分析
Scipy包中包含專門用于統計的模塊(包的代碼的子部分)。
你可以使用'from scipy import stats'命令將其導入(在程序中使其功能可用)到你的筆記本中。該軟件包包含計算數據統計測量、執行統計測試、計算相關性、匯總數據和研究各種概率分布所需的一切。
以下是使用Scipy快速訪問數組的匯總統計信息(最小值,***值,均值,方差,偏斜和峰度)的方法:

6. Python中的數據操作
數據科學家必須花費大量的時間來清理和整理數據。幸運的是,Pandas軟件包可以幫助我們用代碼而不是手工來完成這項工作。
使用Pandas執行的最常見任務是從CSV文件和數據庫中讀取數據。
它還具有強大的語法,可以將不同的數據集組合在一起(數據集在Pandas中稱為DataFrame)并執行數據操作。
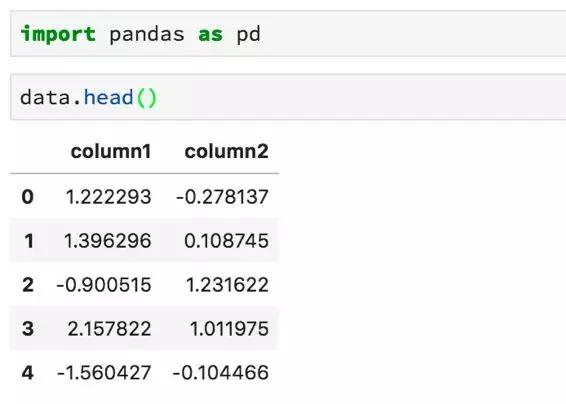
使用.head方法查看DataFrame的前幾行:
使用方括號選擇一列:
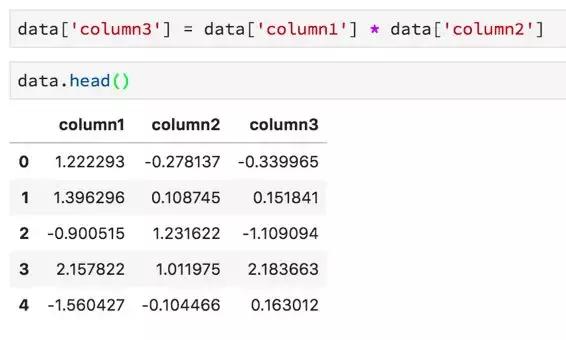
通過組合其他列來創建新列:
7. 在Python中使用數據庫
為了使用pandas read_sql方法,必須提前建立與數據庫的連接。
連接數據庫最安全的方法是使用Python的SQLAlchemy包。
SQL本身就是一種語言,并且連接到數據庫的方式取決于你正在使用的數據庫。
8. Python中的數據工程
有時我們傾向于在數據作為Pandas DataFrame形式到達我們的項目之前,對其進行一些計算。
如果你正在使用數據庫或從Web上抓取數據(并將其存儲在某處),那么移動數據并對其進行轉換的過程稱為ETL(提取,轉換,加載)。
你從一個地方提取數據,對其進行一些轉換(通過添加數據來總結數據,查找均值,更改數據類型等),然后將其加載到可以訪問的位置。
有一個非常酷的工具叫做Airflow,它非常善于幫助管理ETL工作流程。更好的是,它是用Python編寫的,由Airbnb開發。
9. Python中的大數據工程
有時ETL過程可能非常慢。如果你有數十億行數據(或者如果它們是一種奇怪的數據類型,如文本),可以使用許多不同的計算機分別進行處理轉換,并在***一秒將所有數據整合到一起。
這種架構模式稱為MapReduce,它很受Hadoop的歡迎。
如今,很多人使用Spark來做這種數據轉換/檢索工作,并且有一個Spark的Python接口叫做PySpark。
MapReduce架構和Spark都是非常復雜的工具,這里我不詳細介紹。只要知道它們的存在,如果你發現自己正在處理非常緩慢的ETL過程,PySpark可能會有所幫助。
10. Python中的進一步統計
我們已經知道可以使用Scipy的統計模塊運行統計測試、計算描述性統計、p值以及偏斜和峰度等事情,但Python還能做些什么呢?
你應該知道的一個特殊包是Lifelines包。
使用Lifelines包,你可以從稱為生存分析的統計子字段計算各種函數。
生存分析有很多應用。我們可以用它來預測客戶流失(當客戶取消訂閱時)以及零售商店何時可能會被盜竊。
這些與包的創造者想象它將被用于完全不同(生存分析傳統上是醫學統計工具)的領域。但這只是展示了構建數據科學問題的不同方式!
11. Python中的機器學習
這是一個重要的主題,機器學習正在風靡世界,是數據科學家工作的重要組成部分。
簡而言之,機器學習是一組允許計算機將輸入數據映射到輸出數據的技術。有一些情況并非如此,但它們屬于少數,以這種方式考慮ML通常很有幫助。
Python有兩個非常好的機器學習包。
(1) Scikit-Learn
在使用Python進行機器學習的時候都會花大部分時間用于使用Scikit-Learn包(有時縮寫為sklearn)。
這個包實現了一大堆機器學習算法,并通過一致的語法公開它們。這使得數據科學家很容易充分利用每種算法。
使用Scikit-Learn的一般框架是這樣的——將數據集拆分為訓練和測試數據集:

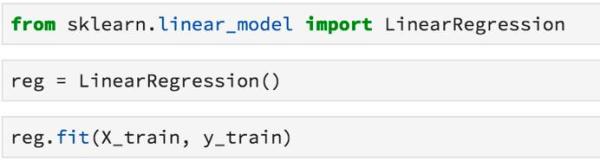
實例化并訓練一個模型:
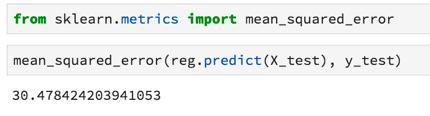
使用metrics模塊測試模型的工作情況:
(2) XGBoost
在Python中常用于機器學習的第二個包是XGBoost。
Scikit-Learn實現了一系列算法,XGBoost只實現了一個梯度提升的決策樹。
最近這個包(和算法)因其在Kaggle比賽(任何人都可以參加的在線數據科學比賽)上被使用而取得成功,變得非常受歡迎。
訓練模型的工作方式與Scikit-Learn算法的工作方式大致相同。
12. Python中的深度學習
Scikit-Learn中提供的機器學習算法幾乎可以滿足任何問題。話雖這么說,但有時你需要使用***進的算法。
由于使用它們的系統幾乎優于其他所有類算法,因此深度神經網絡的普及率急劇上升。
但是很難說神經網絡正在做什么以及它為什么這樣做。因此,它們在金融、醫學、法律和相關專業中的使用并未得到廣泛認可。
神經網絡的兩大類是卷積神經網絡(用于對圖像進行分類并完成計算機視覺中的許多其他任務)和循環神經網絡(用于理解和生成文本)。
探索神經網工作時超出了本文的范圍的機理,如果你想做這類工作,只要知道你需要尋找的包是TensorFlow(Google contibution!)還是Keras。
Keras本質上是TensorFlow的包裝器,使其更易于使用。
13. Python中的數據科學API
一旦訓練了模型,就可以在其他軟件中訪問它的預測,方法是創建一個API。
API允許模型從外部源一次一行地接收數據并返回預測。因為Python是一種通用的編程語言,也可用于創建Web服務,所以很容易使用Python通過API為模型提供服務。
如果需要構建API,應該查看pickle和Flask。Pickle允許訓練有素的模型被保存在硬盤驅動器上,以便以后使用。而Flask是創建Web服務的最簡單方法。
14. Python中的Web應用程序
***,如果你想圍繞數據科學項目構建功能齊全的Web應用程序,則應使用Django框架。
Django在Web開發社區非常受歡迎,并且用于構建Instagram和Pinterest的***個版本(以及許多其他版本)。
到此,相信大家對“怎么使用Python進行數據科學研究”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





