溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何優化Python代碼,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
優化是什么?
首先定義什么是優化。我們將使用一個直觀的示例進行此操作。
這是我們的問題:
假設給定一個數組,其中每個索引代表一個城市,該索引的值代表該城市與下一個城市之間的距離。假設我們有兩個索引,我們需要計算這兩個索引之間的總距離。簡單來說,我們需要找到兩個給定索引之間距離的總和。

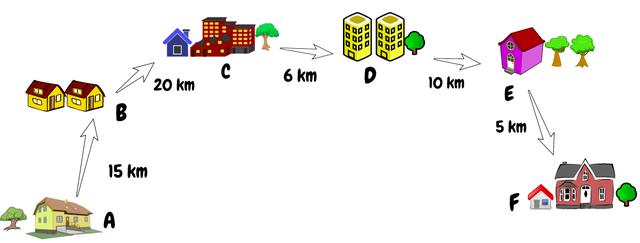
首先想到的是,一個簡單的FOR循環在這里可以很好地工作。但是,如果有100,000多個城市,而我們每秒接收50,000多個查詢,該怎么辦?你是否仍然認為FOR循環可以為我們的問題提供足夠好的解決方案?
FOR循環并不能提供足夠好的方案。這時候優化就派上用場了
簡單地說,代碼優化意味著在生成正確結果的同時減少執行任何任務的操作數。
讓我們計算一下FOR循環執行此任務所需的操作數:

我們必須在上面的數組中找出索引1和索引3的城市之間的距離。

對于較小的數組大小,循環的性能良好
如果數組大小為100,000,查詢數量為50,000,該怎么辦?

這是一個很大的數字。如果數組的大小和查詢數量進一步增加,我們的FOR循環將花費大量時間。你能想到一種優化的方法,使我們在使用較少數量的解決方案時可以產生正確的結果嗎?
在這里,我將討論一個更好的解決方案,通過使用前綴數組來計算距離來解決這個問題。讓我們看看它是如何工作的:

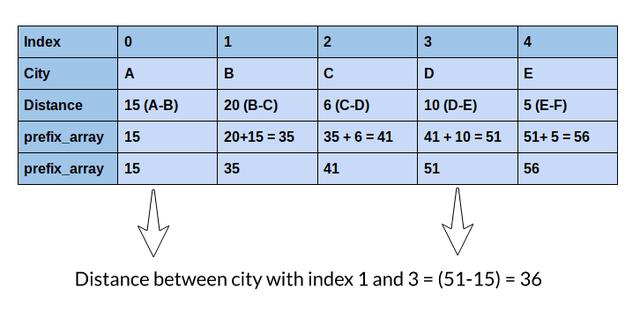

你能理解嗎?我們只需一次操作就可以得到相同的距離!關于此方法的最好之處在于,無論索引之間的差是1還是100,000,都只需執行一個操作即可計算任意兩個索引之間的距離。
我創建了一個樣本數據集,其數組大小為100,000和50,000個查詢。你可以自己執行代碼來比較兩者所用的時間
注意:數據集總共有50,000個查詢,你可以更改參數execute_queries以執行最多50,000個查詢,并查看每種方法執行任務所花費的時間。
import time from tqdm import tqdm data_file = open('sample-data.txt', 'r') distance_between_city = data_file.readline().split() queries = data_file.readlines() print('SIZE OF ARRAY = ', len(distance_between_city)) print('TOTAL NUMBER OF QUERIES = ', len(queries)) data_file.close() # 分配要執行的查詢數 execute_queries = 2000 print('\n\nExecuting',execute_queries,'Queries') # FOR循環方法 # 讀取文件并存儲距離和查詢 start_time_for_loop = time.time() data_file = open('sample-data.txt', 'r') distance_between_city = data_file.readline().split() queries = data_file.readlines() # 存儲距離的列表 distances_for_loop = [] # 計算開始索引和結束索引之間的距離的函數 def calculateDistance(startIndex, endIndex): distance = 0 for number in range(startIndex, endIndex+1, 1): distance += int(distance_between_city[number]) return distance for query in tqdm(queries[:execute_queries]): query = query.split() startIndex = int(query[0]) endIndex = int(query[1]) distances_for_loop.append(calculateDistance(startIndex,endIndex)) data_file.close() # 獲取結束時間 end_time_for_loop = time.time() print('\n\nTime Taken to execute task by for loop :', (end_time_for_loop-start_time_for_loop),'seconds') # 前綴數組方法 # 讀取文件并存儲距離和查詢 start_time_for_prefix = time.time() data_file = open('sample-data.txt', 'r') distance_between_city = data_file.readline().split() queries = data_file.readlines() # 存儲距離列表 distances_for_prefix_array = [] # 創建前綴數組 prefix_array = [] prefix_array.append(int(distance_between_city[0])) for i in range(1, 100000, 1): prefix_array.append((int(distance_between_city[i]) + prefix_array[i-1])) for query in tqdm(queries[:execute_queries]): query = query.split() startIndex = int(query[0]) endIndex = int(query[1]) if startIndex == 0: distances_for_prefix_array.append(prefix_array[endIndex]) else: distances_for_prefix_array.append((prefix_array[endIndex]-prefix_array[startIndex-1])) data_file.close() end_time_for_prefix = time.time() print('\n\nTime Taken by Prefix Array to execute task is : ', (end_time_for_prefix-start_time_for_prefix), 'seconds') # 檢查結果 correct = True for result in range(0,execute_queries): if distances_for_loop[result] != distances_for_prefix_array[result] : correct = False if correct: print('\n\nDistance calculated by both the methods matched.') else: print('\n\nResults did not matched!!')結果極大的節省了時間,這就是優化Python代碼的重要性。我們不僅節省時間,而且還可以節省很多計算資源!
你可能想知道這些如何應用于數據科學項目。你可能已經注意到,很多時候我們必須對大量數據點執行相同的查詢。在數據預處理階段尤其如此。
我們必須使用一些優化的技術而不是基本的編程來盡可能快速高效地完成工作。因此,這里我將分享一些我用來改進和優化Python代碼的優秀技術
1. Pandas.apply() | 特征工程的鉆石級函數
Pandas已經是一個高度優化的庫,但是我們大多數人仍然沒有充分利用它。現在你思考一下在數據科學中會使用它的常見地方。
我能想到的一項是特征工程,我們使用現有特征創建新特征。最有效的方法之一是使用Pandas.apply()。
在這里,我們可以傳遞用戶定義的函數,并將其應用于Pandas序列化數據的每個數據點。它是Pandas庫中很好的插件之一,因為此函數可以根據所需條件選擇性隔離數據。所以,我們可以有效地將其用于數據處理任務。
讓我們使用Twitter情緒分析數據來計算每條推文的字數。我們將使用不同的方法,例如dataframe iterrows方法,NumPy數組和apply方法。你可以從此處下載數據集(https://datahack.analyticsvidhya.com/contest/practice-problem-twitter-sentiment-analysis/?utm_source=blog&utm_medium=4-methods-optimize-python-code-data-science)。
''' 優化方法:apply方法 ''' # 導入庫 import pandas as pd import numpy as np import time import math data = pd.read_csv('train_E6oV3lV.csv') # 打印頭部信息 print(data.head()) # 使用dataframe iterows計算字符數 print('\n\nUsing Iterrows\n\n') start_time = time.time() data_1 = data.copy() n_words = [] for i, row in data_1.iterrows(): n_words.append(len(row['tweet'].split())) data_1['n_words'] = n_words print(data_1[['id','n_words']].head()) end_time = time.time() print('\nTime taken to calculate No. of Words by iterrows :', (end_time-start_time),'seconds') # 使用Numpy數組計算字符數 print('\n\nUsing Numpy Arrays\n\n') start_time = time.time() data_2 = data.copy() n_words_2 = [] for row in data_2.values: n_words_2.append(len(row[2].split())) data_2['n_words'] = n_words_2 print(data_2[['id','n_words']].head()) end_time = time.time() print('\nTime taken to calculate No. of Words by numpy array : ', (end_time-start_time),'seconds') # 使用apply方法計算字符數 print('\n\nUsing Apply Method\n\n') start_time = time.time() data_3 = data.copy() data_3['n_words'] = data_3['tweet'].apply(lambda x : len(x.split())) print(data_3[['id','n_words']].head()) end_time = time.time() print('\nTime taken to calculate No. of Words by Apply Method : ', (end_time-start_time),'seconds')你可能已經注意到apply方法比iterrows方法快得多。其性能可媲美與NumPy數組,但apply方法提供了更多的靈活性。你可以在此處閱讀apply方法的文檔。(https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.apply.html)
2. Pandas.DataFrame.loc | Python數據處理的技巧
這是我最喜歡的Pandas庫的技巧之一。我覺得對于處理數據任務的數據科學家來說,這是一個必須知道的方法(所以幾乎每個人都是這樣!)
大多數時候,我們只需要根據某些條件來更新數據集中特定列的某些值。Pandas.DataFrame.loc為我們提供了針對此類問題的優化的解決方案。
讓我們使用loc函數解決一個問題。你可以在此處下載將要使用的數據集(https://drive.google.com/file/d/1VwXDA27zgx5jIq8C7NQW0A5rtE95e3XI/view?usp=sharing)。
# 導入庫 import pandas as pd data = pd.read_csv('school.csv') data.head()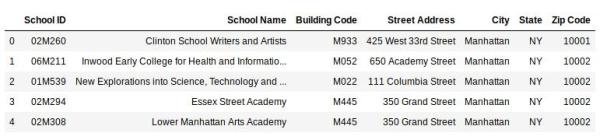
檢查“City”變量的各個值的頻數:
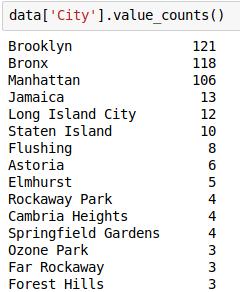
現在,假設我們只需要排名前5位的城市,并希望將其余城市替換為“Others”(其他)城市。因此,讓我們這么寫:
# 將熱門城市保存在列表中 top_cities = ['Brooklyn','Bronx','Manhattan','Jamaica','Long Island City'] # 使用loc更新目標 data.loc[(data.City.isin(top_cities) == False),'City'] = 'Others' # 各個城市的頻數 data.City.value_counts()
Pandas來更新數據的值是非常容易的!這是解決此類數據處理任務的優化方法。
3.在Python中向量化你的函數
擺脫慢循環的另一種方法是對函數進行向量化處理。這意味著新創建的函數將應用于輸入列表,并將返回結果數組。Python中的向量化可以加速計算
讓我們在相同的Twitter Sentiment Analysis數據集對此進行驗證。
''' 優化方法:向量化函數 ''' # 導入庫 import pandas as pd import numpy as np import time import math data = pd.read_csv('train_E6oV3lV.csv') # 輸出頭部信息 print(data.head()) def word_count(x) : return len(x.split()) # 使用Dataframe iterrows 計算詞的個數 print('\n\nUsing Iterrows\n\n') start_time = time.time() data_1 = data.copy() n_words = [] for i, row in data_1.iterrows(): n_words.append(word_count(row['tweet'])) data_1['n_words'] = n_words print(data_1[['id','n_words']].head()) end_time = time.time() print('\nTime taken to calculate No. of Words by iterrows :', (end_time-start_time),'seconds') # 使用向量化方法計算詞的個數 print('\n\nUsing Function Vectorization\n\n') start_time = time.time() data_2 = data.copy() # 向量化函數 vec_word_count = np.vectorize(word_count) n_words_2 = vec_word_count(data_2['tweet']) data_2['n_words'] = n_words_2 print(data_2[['id','n_words']].head()) end_time = time.time() print('\nTime taken to calculate No. of Words by numpy array : ', (end_time-start_time),'seconds')難以置信吧?對于上面的示例,向量化速度提高了80倍!這不僅有助于加速我們的代碼,而且使其變得更整潔。
4. Python中的多進程
多進程是系統同時支持多個處理器的能力。
在這里,我們將流程分成多個任務,并且所有任務都獨立運行。當我們處理大型數據集時,即使apply函數看起來也很慢。
因此,讓我們看看如何利用Python中的多進程庫加快處理速度。
我們將隨機創建一百萬個值,并求出每個值的除數。我們將使用apply函數和多進程方法比較其性能:
# 導入庫 import pandas as pd import math import multiprocessing as mp from random import randint # 計算除數的函數 def countDivisors(n) : count = 0 for i in range(1, (int)(math.sqrt(n)) + 1) : if (n % i == 0) : %%time pool = mp.Pool(processes = (mp.cpu_count() - 1)) answer = pool.map(countDivisors,random_data) pool.close() pool.join() if (n / i == i) : count = count + 1 else : count = count + 2 return count # 創建隨機數 random_data = [randint(10,1000) for i in range(1,1000001)] data = pd.DataFrame({'Number' : random_data }) data.shape
%%time data['Number_of_divisor'] = data.Number.apply(countDivisors)

%%time pool = mp.Pool(processes = (mp.cpu_count() - 1)) answer = pool.map(countDivisors,random_data) pool.close() pool.join()

關于如何優化Python代碼問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





