溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“線程池的創建方式有哪些”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“線程池的創建方式有哪些”吧!
什么是線程池?
線程池(ThreadPool)是一種基于池化思想管理和使用線程的機制。它是將多個線程預先存儲在一個“池子”內,當有任務出現時可以避免重新創建和銷毀線程所帶來性能開銷,只需要從“池子”內取出相應的線程執行對應的任務即可。
池化思想在計算機的應用也比較廣泛,比如以下這些:
內存池(Memory Pooling):預先申請內存,提升申請內存速度,減少內存碎片。
連接池(Connection Pooling):預先申請數據庫連接,提升申請連接的速度,降低系統的開銷。
實例池(Object Pooling):循環使用對象,減少資源在初始化和釋放時的昂貴損耗。
線程池的優勢主要體現在以下 4 點:
鴻蒙官方戰略合作共建——HarmonyOS技術社區
降低資源消耗:通過池化技術重復利用已創建的線程,降低線程創建和銷毀造成的損耗。
提高響應速度:任務到達時,無需等待線程創建即可立即執行。
提高線程的可管理性:線程是稀缺資源,如果無限制創建,不僅會消耗系統資源,還會因為線程的不合理分布導致資源調度失衡,降低系統的穩定性。使用線程池可以進行統一的分配、調優和監控。
提供更多更強大的功能:線程池具備可拓展性,允許開發人員向其中增加更多的功能。比如延時定時線程池ScheduledThreadPoolExecutor,就允許任務延期執行或定期執行。
同時阿里巴巴在其《Java開發手冊》中也強制規定:線程資源必須通過線程池提供,不允許在應用中自行顯式創建線程。
說明:線程池的好處是減少在創建和銷毀線程上所消耗的時間以及系統資源的開銷,解決資源不足的問題。如果不使用線程池,有可能造成系統創建大量同類線程而導致消耗完內存或者“過度切換”的問題。
知道了什么是線程池以及為什要用線程池之后,我們再來看怎么用線程池。
線程池使用
線程池的創建方法總共有 7 種,但總體來說可分為 2 類:
一類是通過 ThreadPoolExecutor 創建的線程池;
另一個類是通過 Executors 創建的線程池。
線程池的創建方式總共包含以下 7 種(其中 6 種是通過 Executors 創建的,1 種是通過 ThreadPoolExecutor 創建的):
鴻蒙官方戰略合作共建——HarmonyOS技術社區
Executors.newFixedThreadPool:創建一個固定大小的線程池,可控制并發的線程數,超出的線程會在隊列中等待;
Executors.newCachedThreadPool:創建一個可緩存的線程池,若線程數超過處理所需,緩存一段時間后會回收,若線程數不夠,則新建線程;
Executors.newSingleThreadExecutor:創建單個線程數的線程池,它可以保證先進先出的執行順序;
Executors.newScheduledThreadPool:創建一個可以執行延遲任務的線程池;
Executors.newSingleThreadScheduledExecutor:創建一個單線程的可以執行延遲任務的線程池;
Executors.newWorkStealingPool:創建一個搶占式執行的線程池(任務執行順序不確定)【JDK 1.8 添加】。
ThreadPoolExecutor:最原始的創建線程池的方式,它包含了 7 個參數可供設置,后面會詳細講。
單線程池的意義從以上代碼可以看出 newSingleThreadExecutor 和 newSingleThreadScheduledExecutor 創建的都是單線程池,那么單線程池的意義是什么呢?答:雖然是單線程池,但提供了工作隊列,生命周期管理,工作線程維護等功能。
那接下來我們來看每種線程池創建的具體使用。
1.FixedThreadPool
創建一個固定大小的線程池,可控制并發的線程數,超出的線程會在隊列中等待。
使用示例如下:
public static void fixedThreadPool() { // 創建 2 個數據級的線程池 ExecutorService threadPool = Executors.newFixedThreadPool(2); // 創建任務 Runnable runnable = new Runnable() { @Override public void run() { System.out.println("任務被執行,線程:" + Thread.currentThread().getName()); } }; // 線程池執行任務(一次添加 4 個任務) // 執行任務的方法有兩種:submit 和 execute threadPool.submit(runnable); // 執行方式 1:submit threadPool.execute(runnable); // 執行方式 2:execute threadPool.execute(runnable); threadPool.execute(runnable); }執行結果如下:

如果覺得以上方法比較繁瑣,還用更簡單的使用方法,如下代碼所示:
public static void fixedThreadPool() { // 創建線程池 ExecutorService threadPool = Executors.newFixedThreadPool(2); // 執行任務 threadPool.execute(() -> { System.out.println("任務被執行,線程:" + Thread.currentThread().getName()); }); }2.CachedThreadPool
創建一個可緩存的線程池,若線程數超過處理所需,緩存一段時間后會回收,若線程數不夠,則新建線程。
使用示例如下:
public static void cachedThreadPool() { // 創建線程池 ExecutorService threadPool = Executors.newCachedThreadPool(); // 執行任務 for (int i = 0; i < 10; i++) { threadPool.execute(() -> { System.out.println("任務被執行,線程:" + Thread.currentThread().getName()); try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { } }); } }執行結果如下:
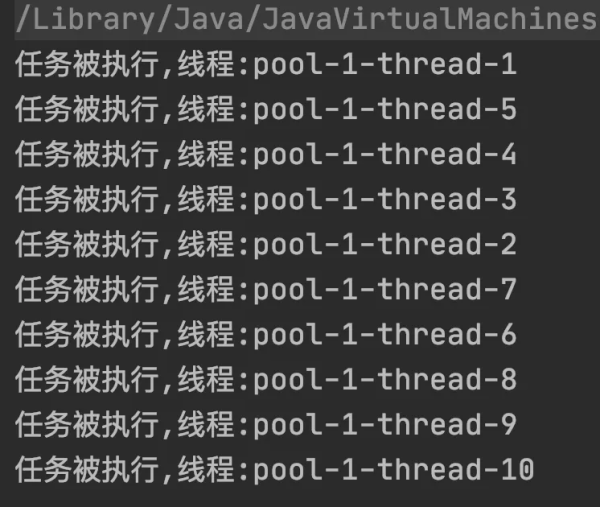
從上述結果可以看出,線程池創建了 10 個線程來執行相應的任務。
3.SingleThreadExecutor
創建單個線程數的線程池,它可以保證先進先出的執行順序。
使用示例如下:
public static void singleThreadExecutor() { // 創建線程池 ExecutorService threadPool = Executors.newSingleThreadExecutor(); // 執行任務 for (int i = 0; i < 10; i++) { final int index = i; threadPool.execute(() -> { System.out.println(index + ":任務被執行"); try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { } }); } }執行結果如下:

4.ScheduledThreadPool
創建一個可以執行延遲任務的線程池。
使用示例如下:
public static void scheduledThreadPool() { // 創建線程池 ScheduledExecutorService threadPool = Executors.newScheduledThreadPool(5); // 添加定時執行任務(1s 后執行) System.out.println("添加任務,時間:" + new Date()); threadPool.schedule(() -> { System.out.println("任務被執行,時間:" + new Date()); try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { } }, 1, TimeUnit.SECONDS); }執行結果如下:

從上述結果可以看出,任務在 1 秒之后被執行了,符合我們的預期。
5.SingleThreadScheduledExecutor
創建一個單線程的可以執行延遲任務的線程池。
使用示例如下:
public static void SingleThreadScheduledExecutor() { // 創建線程池 ScheduledExecutorService threadPool = Executors.newSingleThreadScheduledExecutor(); // 添加定時執行任務(2s 后執行) System.out.println("添加任務,時間:" + new Date()); threadPool.schedule(() -> { System.out.println("任務被執行,時間:" + new Date()); try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { } }, 2, TimeUnit.SECONDS); }執行結果如下:

從上述結果可以看出,任務在 2 秒之后被執行了,符合我們的預期。
6.newWorkStealingPool
創建一個搶占式執行的線程池(任務執行順序不確定),注意此方法只有在 JDK 1.8+ 版本中才能使用。
使用示例如下:
public static void workStealingPool() { // 創建線程池 ExecutorService threadPool = Executors.newWorkStealingPool(); // 執行任務 for (int i = 0; i < 10; i++) { final int index = i; threadPool.execute(() -> { System.out.println(index + " 被執行,線程名:" + Thread.currentThread().getName()); }); } // 確保任務執行完成 while (!threadPool.isTerminated()) { } }執行結果如下:
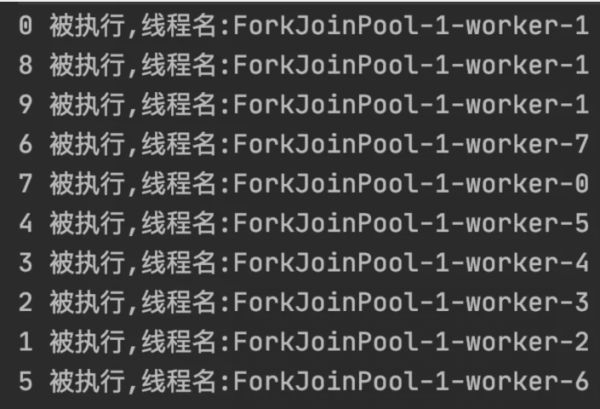
從上述結果可以看出,任務的執行順序是不確定的,因為它是搶占式執行的。
7.ThreadPoolExecutor
最原始的創建線程池的方式,它包含了 7 個參數可供設置。
使用示例如下:
public static void myThreadPoolExecutor() { // 創建線程池 ThreadPoolExecutor threadPool = new ThreadPoolExecutor(5, 10, 100, TimeUnit.SECONDS, new LinkedBlockingQueue<>(10)); // 執行任務 for (int i = 0; i < 10; i++) { final int index = i; threadPool.execute(() -> { System.out.println(index + " 被執行,線程名:" + Thread.currentThread().getName()); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } }); } }執行結果如下:
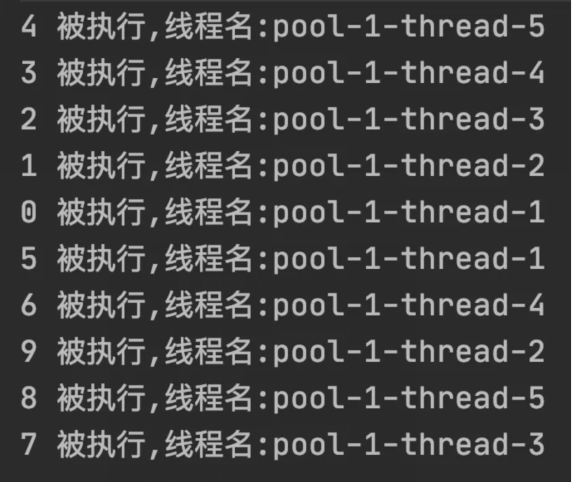
ThreadPoolExecutor 參數介紹
ThreadPoolExecutor 最多可以設置 7 個參數,如下代碼所示:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { // 省略... }7 個參數代表的含義如下:
參數 1:corePoolSize
核心線程數,線程池中始終存活的線程數。
參數 2:maximumPoolSize
最大線程數,線程池中允許的最大線程數,當線程池的任務隊列滿了之后可以創建的最大線程數。
參數 3:keepAliveTime
最大線程數可以存活的時間,當線程中沒有任務執行時,最大線程就會銷毀一部分,最終保持核心線程數量的線程。
參數 4:unit:
單位是和參數 3 存活時間配合使用的,合在一起用于設定線程的存活時間 ,參數 keepAliveTime 的時間單位有以下 7 種可選:
TimeUnit.DAYS:天
TimeUnit.HOURS:小時
TimeUnit.MINUTES:分
TimeUnit.SECONDS:秒
TimeUnit.MILLISECONDS:毫秒
TimeUnit.MICROSECONDS:微妙
TimeUnit.NANOSECONDS:納秒
參數 5:workQueue
一個阻塞隊列,用來存儲線程池等待執行的任務,均為線程安全,它包含以下 7 種類型:
ArrayBlockingQueue:一個由數組結構組成的有界阻塞隊列。
LinkedBlockingQueue:一個由鏈表結構組成的有界阻塞隊列。
SynchronousQueue:一個不存儲元素的阻塞隊列,即直接提交給線程不保持它們。
PriorityBlockingQueue:一個支持優先級排序的無界阻塞隊列。
DelayQueue:一個使用優先級隊列實現的無界阻塞隊列,只有在延遲期滿時才能從中提取元素。
LinkedTransferQueue:一個由鏈表結構組成的無界阻塞隊列。與SynchronousQueue類似,還含有非阻塞方法。
LinkedBlockingDeque:一個由鏈表結構組成的雙向阻塞隊列。
較常用的是 LinkedBlockingQueue 和 Synchronous,線程池的排隊策略與 BlockingQueue 有關。
參數 6:threadFactory
線程工廠,主要用來創建線程,默認為正常優先級、非守護線程。
參數 7:handler
拒絕策略,拒絕處理任務時的策略,系統提供了 4 種可選:
AbortPolicy:拒絕并拋出異常。
CallerRunsPolicy:使用當前調用的線程來執行此任務。
DiscardOldestPolicy:拋棄隊列頭部(最舊)的一個任務,并執行當前任務。
DiscardPolicy:忽略并拋棄當前任務。
默認策略為 AbortPolicy。
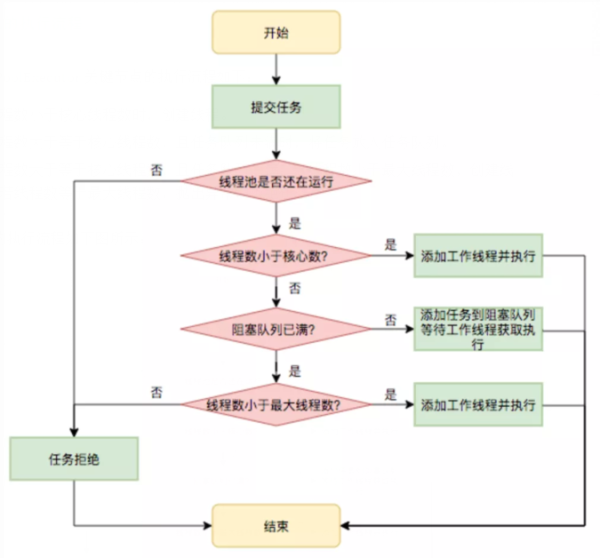
線程池的執行流程
ThreadPoolExecutor 關鍵節點的執行流程如下:
當線程數小于核心線程數時,創建線程。
當線程數大于等于核心線程數,且任務隊列未滿時,將任務放入任務隊列。
當線程數大于等于核心線程數,且任務隊列已滿:若線程數小于最大線程數,創建線程;若線程數等于最大線程數,拋出異常,拒絕任務。
線程池的執行流程如下圖所示:
線程拒絕策略
我們來演示一下 ThreadPoolExecutor 的拒絕策略的觸發,我們使用 DiscardPolicy 的拒絕策略,它會忽略并拋棄當前任務的策略,實現代碼如下:
public static void main(String[] args) { // 任務的具體方法 Runnable runnable = new Runnable() { @Override public void run() { System.out.println("當前任務被執行,執行時間:" + new Date() + " 執行線程:" + Thread.currentThread().getName()); try { // 等待 1s TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } } }; // 創建線程,線程的任務隊列的長度為 1 ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1, 1, 100, TimeUnit.SECONDS, new LinkedBlockingQueue<>(1), new ThreadPoolExecutor.DiscardPolicy()); // 添加并執行 4 個任務 threadPool.execute(runnable); threadPool.execute(runnable); threadPool.execute(runnable); threadPool.execute(runnable); }我們創建了一個核心線程數和最大線程數都為 1 的線程池,并且給線程池的任務隊列設置為 1,這樣當我們有 2 個以上的任務時就會觸發拒絕策略,執行的結果如下圖所示:

從上述結果可以看出只有兩個任務被正確執行了,其他多余的任務就被舍棄并忽略了。其他拒絕策略的使用類似,這里就不一一贅述了。
自定義拒絕策略
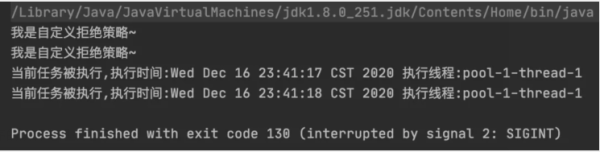
除了 Java 自身提供的 4 種拒絕策略之外,我們也可以自定義拒絕策略,示例代碼如下:
public static void main(String[] args) { // 任務的具體方法 Runnable runnable = new Runnable() { @Override public void run() { System.out.println("當前任務被執行,執行時間:" + new Date() + " 執行線程:" + Thread.currentThread().getName()); try { // 等待 1s TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } } }; // 創建線程,線程的任務隊列的長度為 1 ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1, 1, 100, TimeUnit.SECONDS, new LinkedBlockingQueue<>(1), new RejectedExecutionHandler() { @Override public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) { // 執行自定義拒絕策略的相關操作 System.out.println("我是自定義拒絕策略~"); } }); // 添加并執行 4 個任務 threadPool.execute(runnable); threadPool.execute(runnable); threadPool.execute(runnable); threadPool.execute(runnable); }程序的執行結果如下:
究竟選用哪種線程池?
經過以上的學習我們對整個線程池也有了一定的認識了,那究竟該如何選擇線程池呢?
我們來看下阿里巴巴《Java開發手冊》給我們的答案:
【強制】線程池不允許使用 Executors 去創建,而是通過 ThreadPoolExecutor 的方式,這樣的處理方式讓寫的同學更加明確線程池的運行規則,規避資源耗盡的風險。
說明:Executors 返回的線程池對象的弊端如下:
1) FixedThreadPool 和 SingleThreadPool:允許的請求隊列長度為 Integer.MAX_VALUE,可能會堆積大量的請求,從而導致 OOM。
2)CachedThreadPool:允許的創建線程數量為 Integer.MAX_VALUE,可能會創建大量的線程,從而導致 OOM。
所以綜上情況所述,我們推薦使用 ThreadPoolExecutor 的方式進行線程池的創建,因為這種創建方式更可控,并且更加明確了線程池的運行規則,可以規避一些未知的風險。
感謝各位的閱讀,以上就是“線程池的創建方式有哪些”的內容了,經過本文的學習后,相信大家對線程池的創建方式有哪些這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





