溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“關于Java IO的知識點有哪些”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“關于Java IO的知識點有哪些”吧!
Java IO流是一個龐大的生態環境,其內部提供了很多不同的輸入流和輸出流,細分下去還有字節流和字符流,甚至還有緩沖流提高 IO 性能,轉換流將字節流轉換為字符流······看到這些就已經對 IO 產生恐懼了,在日常開發中少不了對文件的 IO 操作,雖然 apache 已經提供了 Commons IO 這種封裝好的組件,但面對特殊場景時,我們仍需要自己去封裝一個高性能的文件 IO 工具類,本文將會解析 Java IO 中涉及到的各個類,以及講解如何正確、高效地使用它們。
我們會以一個經典的燒開水的例子通俗地講解它們之間的區別
類型燒開水BIO一直監測著某個水壺,該水壺燒開水后再監測下一個水壺NIO每隔一段時間就看看所有水壺的狀態,哪個水壺燒開水就去處理哪個水壺AIO不用監測水壺,每個水壺燒開水后都會主動通知線程說:“我的水燒開了,來處理我吧”
BIO (同步阻塞 I/O)
這里假設一個燒開水的場景,有一排水壺在燒開水,BIO的工作模式就是, 小菠蘿一直看著著這個水壺,直到這個水壺燒開,才去處理下一個水壺。線程在等待水壺燒開的時間段什么都沒有做。
NIO(同步非阻塞 I/O)
還拿燒開水來說,NIO的做法是小菠蘿一邊玩著手機,每隔一段時間就看一看每個水壺的狀態,看看是否有水壺的狀態發生了改變,如果某個水壺燒開了,可以先處理那個水壺,然后繼續玩手機,繼續隔一段時間又看看每個水壺的狀態。
AIO (異步非阻塞 I/O)
小菠蘿覺得每隔一段時間就去看一看水壺太費勁了,于是購買了一批燒開水時可以嗶嗶響的水壺,于是開始燒水后,小菠蘿就直接去客廳玩手機了,水燒開時,就發出“嗶嗶”的響聲,通知小菠蘿來關掉水壺。
知識科普:我們知道任何一個文件都是以二進制形式存在于設備中,計算機就只有 0 和 1,你能看見的東西全部都是由這兩個數字組成,你看這篇文章時,這篇文章也是由01組成,只不過這些二進制串經過各種轉換演變成一個個文字、一張張圖片躍然屏幕上。
而流就是將這些二進制串在各種設備之間進行傳輸,如果你覺得有些抽象,我舉個例子就會好理解一些:
下圖是一張圖片,它由01串組成,我們可以通過程序把一張圖片拷貝到一個文件夾中,
把圖片轉化成二進制數據集,把數據一點一點地傳遞到文件夾中 , 類似于水的流動 , 這樣整體的數據就是一個數據流
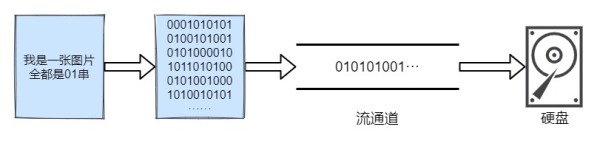
IO 流讀寫數據的特點:
順序讀寫。讀寫數據時,大部分情況下都是按照順序讀寫,讀取時從文件開頭的第一個字節到最后一個字節,寫出時也是也如此(RandomAccessFile 可以實現隨機讀寫)
字節數組。讀寫數據時本質上都是對字節數組做讀取和寫出操作,即使是字符流,也是在字節流基礎上轉化為一個個字符,所以字節數組是 IO 流讀寫數據的本質。
根據數據流向不同分類:輸入流 和 輸出流
輸入流:從磁盤或者其它設備中將數據輸入到進程中
輸出流:將進程中的數據輸出到磁盤或其它設備上保存

圖示中的硬盤只是其中一種設備,還有非常多的設備都可以應用在IO流中,例如:打印機、硬盤、顯示器、手機······
根據處理數據的基本單位不同分類:字節流 和 字符流
字節流:以字節(8 bit)為單位做數據的傳輸
字符流:以字符為單位(1字符 = 2字節)做數據的傳輸
字符流的本質也是通過字節流讀取,Java 中的字符采用 Unicode 標準,在讀取和輸出的過程中,通過以字符為單位,查找對應的碼表將字節轉換為對應的字符。
面對字節流和字符流,很多讀者都有疑惑:什么時候需要用字節流,什么時候又要用字符流?
我這里做一個簡單的概括,你可以按照這個標準去使用:
字符流只針對字符數據進行傳輸,所以如果是文本數據,優先采用字符流傳輸;除此之外,其它類型的數據(圖片、音頻等),最好還是以字節流傳輸。
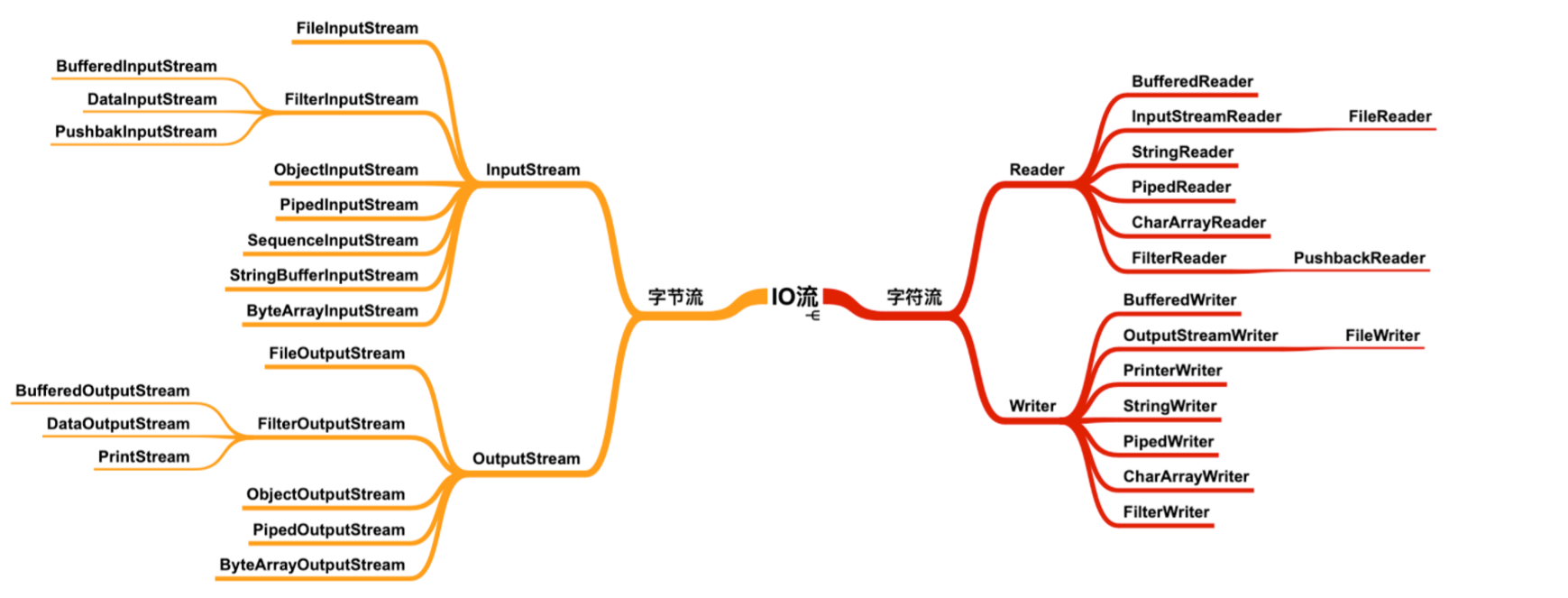
根據這兩種不同的分類,我們就可以做出下面這個表格,里面包含了 IO 中最核心的 4 個頂層抽象類:
數據流向 / 數據類型字節流字符流輸入流InputStreamReader輸出流OutputStreamWriter
現在看 IO 是不是有一些思路了,不會覺得很混亂了,我們來看這四個類下的所有成員。
[來自于 cxuan 的 《Java基礎核心總結》]
看到這么多的類是不是又開始覺得混亂了,不要慌,字節流和字符流下的輸入流和輸出流大部分都是一一對應的,有了上面的表格支撐,我們不需要再擔心看見某個類會懵逼的情況了。
看到 Stream 就知道是字節流,看到 Reader / Writer 就知道是字符流。
這里還要額外補充一點:Java IO 提供了字節流轉換為字符流的轉換類,稱為轉換流。
轉換流 / 數據類型字節流與字符流之間的轉換(輸入)字節流 => 字符流InputStreamReader(輸出)字符流 => 字節流OutputStreamWriter
注意字節流與字符流之間的轉換是有嚴格定義的:
輸入流:可以將字節流 => 字符流
輸出流:可以將字符流 => 字節流
為什么在輸入流不能字符流 => 字節流,輸出流不能字節流 => 字符流?
在存儲設備上,所有數據都是以字節為單位存儲的,所以輸入到內存時必定是以字節為單位輸入,輸出到存儲設備時必須是以字節為單位輸出,字節流才是計算機最根本的存儲方式,而字符流是在字節流的基礎上對數據進行轉換,輸出字符,但每個字符依舊是以字節為單位存儲的。
在這里需要額外插入一個小節講解節點流和處理流。
節點流:節點流是真正傳輸數據的流對象,用于向特定的一個地方(節點)讀寫數據,稱為節點流。例如 FileInputStream
處理流:處理流是對節點流的封裝,使用外層的處理流讀寫數據,本質上是利用節點流的功能,外層的處理流可以提供額外的功能。處理流的基類都是以 Filter 開頭。
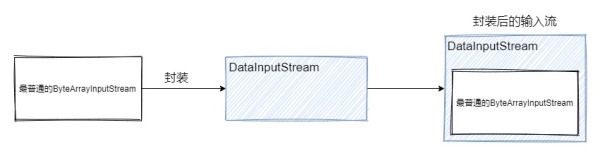
上圖將 ByteArrayInputStream 封裝成 DataInputStream,可以將輸入的字節數組轉換為對應數據類型的數據。例如希望讀入int類型數據,就會以2個字節為單位轉換為一個數字。
Java 提供了 File類,它指向計算機操作系統中的文件和目錄,通過該類只能訪問文件和目錄,無法訪問內容。 它內部主要提供了 3種操作:
訪問文件的屬性:絕對路徑、相對路徑、文件名······
文件檢測:是否文件、是否目錄、文件是否存在、文件的讀/寫/執行權限······
操作文件:創建目錄、創建文件、刪除文件······
上面舉例的操作都是在開發中非常常用的,File 類遠不止這些操作,更多的操作可以直接去 API 文檔中根據需求查找。
訪問文件的屬性:
API功能String getAbsolutePath()返回該文件處于系統中的絕對路徑名String getPath()返回該文件的相對路徑,通常與 new File() 傳入的路徑相同String getName()返回該文件的文件名
文件檢測:
API功能boolean isFIle()校驗該路徑指向是否一個文件boolean isDirectory()校驗該路徑指向是否一個目錄boolean isExist()校驗該路徑指向的文件/目錄是否存在boolean canWrite()校驗該文件是否可寫boolean canRead()校驗該文件是否可讀boolean canExecute()校驗該文件/目錄是否可以被執行
操作文件:
API功能mkdirs()遞歸創建多個文件夾,路徑中間有可能某些文件夾不存在createNewFile()創建新文件,它是一個原子操作,有兩步:檢查文件是否存在、創建新文件delete()刪除文件或目錄,刪除目錄時必須保證該目錄為空
文件的讀/寫/執行權限,在 Windows 中通常表現不出來,而在 Linux 中可以很好地體現這一點,原因是 Linux 有嚴格的用戶權限分組,不同分組下的用戶對文件有不同的操作權限,所以這些方法在 Linux 下會比在 Windows 下更好理解。下圖是 redis 文件夾中的一些文件的詳細信息,被紅框標注的是不同用戶的執行權限:
r(Read):代表該文件可以被當前用戶讀,操作權限的序號是 4
w(Write):代表該文件可以被當前用戶寫,操作權限的序號是 2
x(Execute):該文件可以被當前用戶執行,操作權限的序號是 1
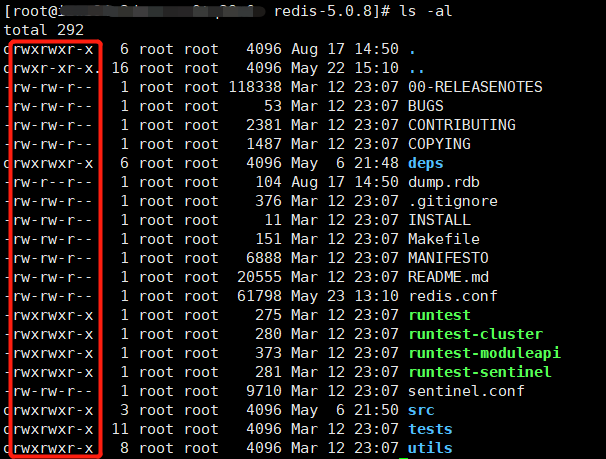
root root 分別代表:當前文件的所有者,當前文件所屬的用戶分組。Linux 下文件的操作權限分為三種用戶:
文件所有者:擁有的權限是紅框中的前三個字母,-代表沒有某個權限
文件所在組的所有用戶:擁有的權限是紅框中的中間三個字母
其它組的所有用戶:擁有的權限是紅框中的最后三個字母
回顧流的分類有2種:
根據數據流向分為輸入流和輸出流
根據數據類型分為字節流和字符流
所以,本小節將以字節流和字符流作為主要分割點,在其內部再細分為輸入流和輸出流進行講解。
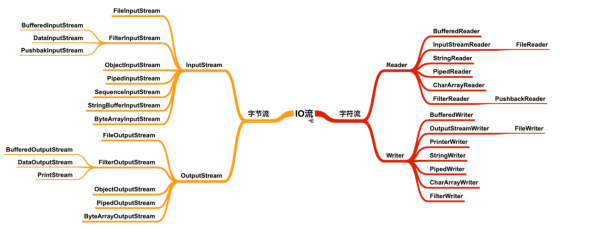
字節流對象大部分輸入流和輸出流都是成雙成對地出現,所以學習的時候可以將輸入流和輸出流一一對應的流對象關聯起來,輸入流和輸出流只是數據流向不同,而處理數據的方式可以是相同的。
注意不要認為用什么流讀入數據,就需要用對應的流寫出數據,在 Java 中沒有這么規定,下圖只是各個對象之間的一個對應關系,不是兩個類使用時必須強制關聯使用。
下面有非常多的類,我會介紹基類的方法,了解這些方法是非常有必要的,子類的功能基于父類去擴展,只有真正了解父類在做什么,學習子類的成本就會下降。
InputStream 是字節輸入流的抽象基類,提供了通用的讀方法,讓子類使用或重寫它們。下面是 InputStream 常用的重要的方法。
重要方法功能public abstract int read()從輸入流中讀取下一個字節,讀到尾部時返回 -1public int read(byte b[])從輸入流中讀取長度為 b.length 個字節放入字節數組 b 中public int read(byte b[], int off, int len)從輸入流中讀取指定范圍的字節數據放入字節數組 b 中public void close()關閉此輸入流并釋放與該輸入流相關的所有資源
還有其它一些不太常用的方法,我也列出來了。
其它方法功能public long skip(long n)跳過接下來的 n 個字節,返回實際上跳過的字節數public long available()返回下一次可讀取(跳過)且不會被方法阻塞的字節數的估計值public synchronized void mark(int readlimit)標記此輸入流的當前位置,對 reset() 方法的后續調用將會重新定位在 mark() 標記的位置,可以重新讀取相同的字節public boolean markSupported()判斷該輸入流是否支持 mark() 和 reset() 方法,即能否重復讀取字節public synchronized void reset()將流的位置重新定位在最后一次調用 mark() 方法時的位置
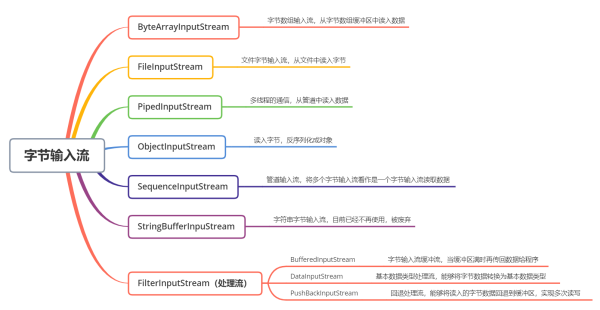
(1)ByteArrayInputStream
ByteArrayInputStream 內部包含一個 buf 字節數組緩沖區,該緩沖區可以從流中讀取的字節數,使用 pos 指針指向讀取下一個字節的下標位置,內部還維護了一個count 屬性,代表能夠讀取 count 個字節。
必須保證 pos 嚴格小于 count,而 count 嚴格小于 buf.length 時,才能夠從緩沖區中讀取數據
(2)FileInputStream
文件輸入流,從文件中讀入字節,通常對文件的拷貝、移動等操作,可以使用該輸入流把文件的字節讀入內存中,然后再利用輸出流輸出到指定的位置上。
(3)PipedInputStream
管道輸入流,它與 PipedOutputStream 成對出現,可以實現多線程中的管道通信。PipedOutputStream 中指定與特定的 PipedInputStream 連接,PipedInputStream 也需要指定特定的 PipedOutputStream 連接,之后輸出流不斷地往輸入流的 buffer 緩沖區寫數據,而輸入流可以從緩沖區中讀取數據。
(4)ObjectInputStream
對象輸入流,用于對象的反序列化,將讀入的字節數據反序列化為一個對象,實現對象的持久化存儲。
(5)PushBackInputStream
它是 FilterInputStream 的子類,是一個處理流,它內部維護了一個緩沖數組buf。
在讀入字節的過程中可以將讀取到的字節數據回退給緩沖區中保存,下次可以再次從緩沖區中讀出該字節數據。所以PushBackInputStream 允許多次讀取輸入流的字節數據,只要將讀到的字節放回緩沖區即可。
需要注意的是如果回推字節時,如果緩沖區已滿,會拋出 IOException 異常。
它的應用場景:對數據進行分類規整。
假如一個文件中存儲了數字和字母兩種類型的數據,我們需要將它們交給兩種線程各自去收集自己負責的數據,如果采用傳統的做法,把所有的數據全部讀入內存中,再將數據進行分離,面對大文件的情況下,例如1G、2G,傳統的輸入流在讀入數組后,由于沒有緩沖區,只能對數據進行拋棄,這樣每個線程都要讀一遍文件。
使用 PushBackInputStream 可以讓一個專門的線程讀取文件,喚醒不同的線程讀取字符:
第一次讀取緩沖區的數據,判斷該數據由哪些線程讀取
回退數據,喚醒對應的線程讀取數據
重復前兩步
關閉輸入流
到這里,你是否會想到 AQS 的 Condition 等待隊列,多個線程可以在不同的條件上等待被喚醒。
(6)BufferedInputStream
緩沖流,它是一種處理流,對節點流進行封裝并增強,其內部擁有一個 buffer 緩沖區,用于緩存所有讀入的字節,當緩沖區滿時,才會將所有字節發送給客戶端讀取,而不是每次都只發送一部分數據,提高了效率。
(7)DataInputStream
數據輸入流,它同樣是一種處理流,對節點流進行封裝后,能夠在內部對讀入的字節轉換為對應的 Java 基本數據類型。
(8)SequenceInputStream
將兩個或多個輸入流看作是一個輸入流依次讀取,該類的存在與否并不影響整個 IO 生態,在程序中也能夠做到這種效果
(9)StringBufferInputStream
將字符串中每個字符的低 8 位轉換為字節讀入到字節數組中,目前已過期
InputStream 總結:
InputStream 是所有輸入字節流的抽象基類
ByteArrayInputStream 和 FileInputStream 是兩種基本的節點流,他們分別從字節數組 和 本地文件中讀取數據
DataInputStream、BufferedInputStream 和 PushBackInputStream 都是處理流,對基本的節點流進行封裝并增強
PipiedInputStream 用于多線程通信,可以與其它線程公用一個管道,讀取管道中的數據。
ObjectInputStream 用于對象的反序列化,將對象的字節數據讀入內存中,通過該流對象可以將字節數據轉換成對應的對象
OutputStream 是字節輸出流的抽象基類,提供了通用的寫方法,讓繼承的子類重寫和復用。
方法功能public abstract void write(int b)將指定的字節寫出到輸出流,寫入的字節是參數 b 的低 8 位public void write(byte b[])將指定字節數組中的所有字節寫入到輸出流當中public void write(byte b[], int off, int len)指定寫入的起始位置 offer,字節數為 len 的字節數組寫入到輸出流當中public void flush()刷新此輸出流,并強制寫出所有緩沖的輸出字節到指定位置,每次寫完都要調用public void close()關閉此輸出流并釋放與此流關聯的所有系統資源
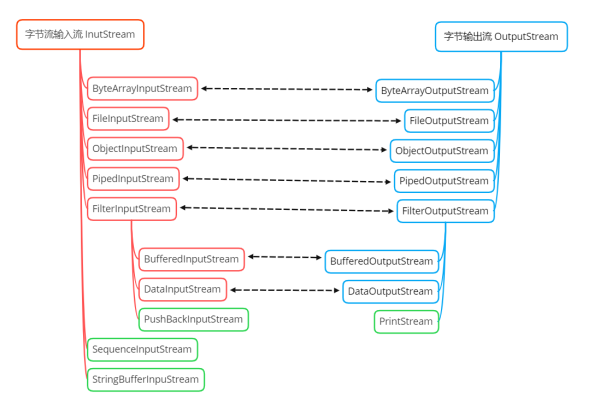
OutputStream 中大多數的類和 InputStream 是對應的,只不過數據的流向不同而已。從上面的圖可以看出:
OutputStream 是所有輸出字節流的抽象基類
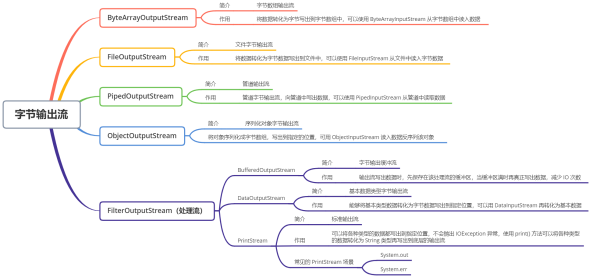
ByteArrayOutputStream 和 FileOutputStream 是兩種基本的節點流,它們分別向字節數組和本地文件寫出數據
DataOutputStream、BufferedOutputStream 是處理流,前者可以將字節數據轉換成基本數據類型寫出到文件中;后者是緩沖字節數組,只有在緩沖區滿時,才會將所有的字節寫出到目的地,減少了 IO 次數。
PipedOutputStream 用于多線程通信,可以和其它線程共用一個管道,向管道中寫入數據
ObjectOutputStream 用于對象的序列化,將對象轉換成字節數組后,將所有的字節都寫入到指定位置中
PrintStream 在 OutputStream 基礎之上提供了增強的功能,即可以方便地輸出各種類型的數據(而不僅限于byte型)的格式化表示形式,且 PrintStream 的方法從不拋出 IOEception,其原理是寫出時將各個數據類型的數據統一轉換為 String 類型,我會在講解完
字符流對象也會有對應關系,大多數的類可以認為是操作的數據從字節數組變為字符,類的功能和字節流對象是相似的。
字符輸入流和字節輸入流的組成非常相似,字符輸入流是對字節輸入流的一層轉換,所有文件的存儲都是字節的存儲,在磁盤上保留的不是文件的字符,而是先把字符編碼成字節,再保存到文件中。在讀取文件時,讀入的也是一個一個字節組成的字節序列,而 Java 虛擬機通過將字節序列,按照2個字節為單位轉換為 Unicode 字符,實現字節到字符的映射。
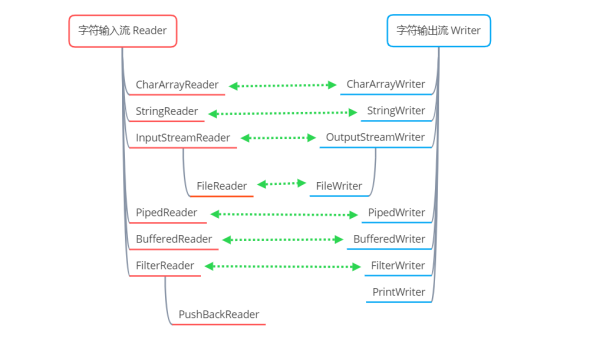
Reader 是字符輸入流的抽象基類,它內部的重要方法如下所示。
重要方法方法功能public int read(java.nio.CharBuffer target)將讀入的字符存入指定的字符緩沖區中public int read()讀取一個字符public int read(char cbuf[])讀入字符放入整個字符數組中abstract public int read(char cbuf[], int off, int len)將字符讀入字符數組中的指定范圍中
還有其它一些額外的方法,與字節輸入流基類提供的方法是相同的,只是作用的對象不再是字節,而是字符。
Reader 是所有字符輸入流的抽象基類
CharArrayReader 和 StringReader 是兩種基本的節點流,它們分別從讀取 字符數組 和 字符串 數據,StringReader 內部是一個 String 變量值,通過遍歷該變量的字符,實現讀取字符串,本質上也是在讀取字符數組
PipedReader 用于多線程中的通信,從共用地管道中讀取字符數據
BufferedReader 是字符輸入緩沖流,將讀入的數據放入字符緩沖區中,實現高效地讀取字符
InputStreamReader 是一種轉換流,可以實現從字節流轉換為字符流,將字節數據轉換為字符
Reader 是字符輸出流的抽象基類,它內部的重要方法如下所示。
重要方法方法功能public void write(char cbuf[])將 cbuf 字符數組寫出到輸出流abstract public void write(char cbuf[], int off, int len)將指定范圍的 cbuf 字符數組寫出到輸出流public void write(String str)將字符串 str 寫出到輸出流,str 內部也是字符數組public void write(String str, int off, int len)將字符串 str 的某一部分寫出到輸出流abstract public void flush()刷新,如果數據保存在緩沖區,調用該方法才會真正寫出到指定位置abstract public void close()關閉流對象,每次 IO 執行完畢后都需要關閉流對象,釋放系統資源
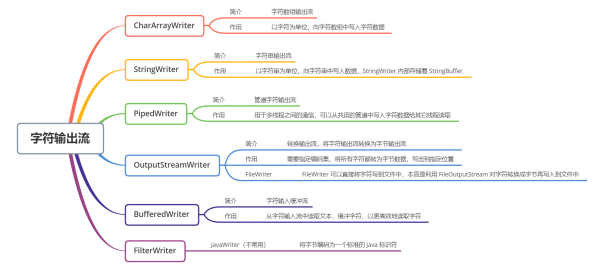
Writer 是所有的輸出字符流的抽象基類
CharArrayWriter、StringWriter 是兩種基本的節點流,它們分別向Char 數組、字符串中寫入數據。StringWriter 內部保存了 StringBuffer 對象,可以實現字符串的動態增長
PipedWriter 可以向共用的管道中寫入字符數據,給其它線程讀取。
BufferedWriter 是緩沖輸出流,可以將寫出的數據緩存起來,緩沖區滿時再調用 flush() 寫出數據,減少 IO 次數。
PrintWriter 和 PrintStream 類似,功能和使用也非常相似,只是寫出的數據是字符而不是字節。
OutputStreamWriter 將字符流轉換為字節流,將字符寫出到指定位置
從任何地方把數據讀入到內存都是先以字節流形式讀取,即使是使用字符流去讀取數據,依然成立,因為數據永遠是以字節的形式存在于互聯網和硬件設備中,字符流是通過字符集的映射,才能夠將字節轉換為字符。
所以 Java 提供了兩種轉換流:
InputStreamReader:從字節流轉換為字符流,將字節數據轉換為字符數據讀入到內存
OutputStreamWriter:從字符流轉換為字節流,將字符數據轉換為字節數據寫出到指定位置
了解了 Java 傳統的 BIO 中字符流和字節流的主要成員之后,至少要掌握以下兩個關鍵點:
傳統的 BIO 是以流為基本單位處理數據的,想象成水流,一點點地傳輸字節數據,IO 流傳輸的過程永遠是以字節形式傳輸。
字節流和字符流的區別在于操作的數據單位不相同,字符流是通過將字節數據通過字符集映射成對應的字符,字符流本質上也是字節流。
接下來我們再繼續學習 NIO 知識,NIO 是當下非常火熱的一種 IO 工作方式,它能夠解決傳統 BIO 的痛點:阻塞。
BIO 如果遇到 IO 阻塞時,線程將會被掛起,直到 IO 完成后才喚醒線程,線程切換帶來了額外的開銷。
BIO 中每個 IO 都需要有對應的一個線程去專門處理該次 IO 請求,會讓服務器的壓力迅速提高。
我們希望做到的是當線程等待 IO 完成時能夠去完成其它事情,當 IO 完成時線程可以回來繼續處理 IO 相關操作,不必干干的坐等 IO 完成。在 IO 處理的過程中,能夠有一個專門的線程負責監聽這些 IO 操作,通知服務器該如何操作。所以,我們聊到 IO,不得不去接觸 NIO 這一塊硬骨頭。
我們來看看 BIO 和 NIO 的區別,BIO 是面向流的 IO,它建立的通道都是單向的,所以輸入和輸出流的通道不相同,必須建立2個通道,通道內的都是傳輸0101001···的字節數據。
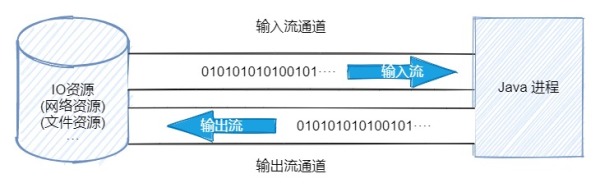
而在 NIO 中,不再是面向流的 IO 了,而是面向緩沖區,它會建立一個通道(Channel),該通道我們可以理解為鐵路,該鐵路上可以運輸各種貨物,而通道上會有一個緩沖區(Buffer)用于存儲真正的數據,緩沖區我們可以理解為一輛火車。
通道(鐵路)只是作為運輸數據的一個連接資源,而真正存儲數據的是緩沖區(火車)。即通道負責傳輸,緩沖區負責存儲。
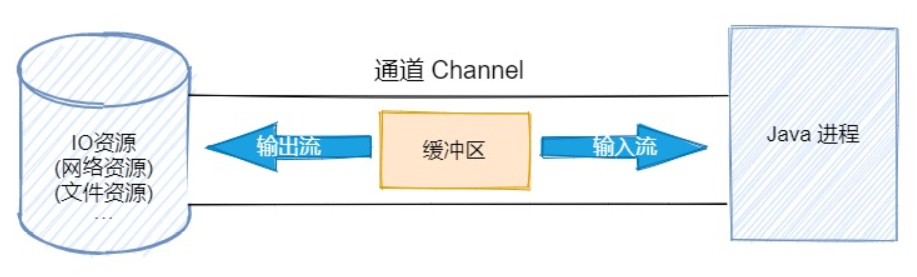
理解了上面的圖之后,BIO 和 NIO 的主要區別就可以用下面這個表格簡單概括。
BIONIO面向流(Stream)面向緩沖區(Buffer)單向通道雙向通道阻塞 IO非阻塞 IO選擇器(Selectors)
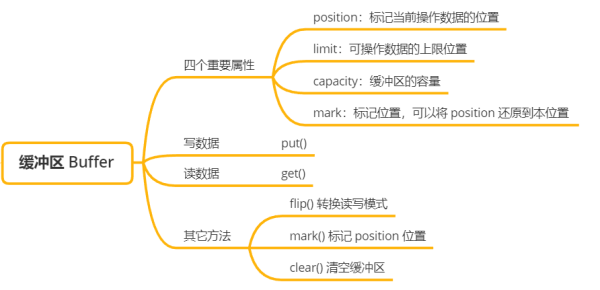
緩沖區是存儲數據的區域,在 Java 中,緩沖區就是數組,為了可以操作不同數據類型的數據,Java 提供了許多不同類型的緩沖區,除了布爾類型以外,其它基本數據類型都有對應的緩沖區數組對象。
為什么沒有布爾類型的緩沖區呢?
在 Java 中,boolean 類型數據只占用 1 bit,而在 IO 傳輸過程中,都是以字節為單位進行傳輸的,所以 boolean 的 1 bit 完全可以使用 byte 類型的某一位,或者 int 類型的某一位來表示,沒有必要為了這 1 bit 而專門提供多一個緩沖區。
緩沖區解釋ByteBuffer存儲字節數據的緩沖區CharBuffer存儲字符數據的緩沖區ShortBuffer存儲短整型數據的緩沖區IntBuffer存儲整型數據的緩沖區LongBuffer存儲長整型數據的緩沖區FloatBuffer存儲單精度浮點型數據的緩沖區DoubleBuffer存儲雙精度浮點型數據的緩沖區
分配一個緩沖區的方式都高度一致:使用allocate(int capacity)方法。
例如需要分配一個 1024 大小的字節數組,代碼就是下面這樣子。
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
緩沖區讀寫數據的兩個核心方法:
put():將數據寫入到緩沖區中
get():從緩沖區中讀取數據
緩沖區的重要屬性:
capacity:緩沖區中最大存儲數據的容量,一旦聲明則無法改變
limit:表示緩沖區中可以操作數據的大小,limit 之后的數據無法進行讀寫。必須滿足 limit <= capacity
position:當前緩沖區中正在操作數據的下標位置,必須滿足 position <= limit
mark:標記位置,調用 reset() 將 position 位置調整到 mark 屬性指向的下標位置,實現多次讀取數據
緩沖區為高效讀寫數據而提供的其它輔助方法:
flip():可以實現讀寫模式的切換,我們可以看看里面的源碼
public final Buffer flip() { limit = position; position = 0; mark = -1; return this; }調用 flip() 會將可操作的大小 limit 設置為當前寫的位置,操作數據的起始位置 position 設置為 0,即從頭開始讀取數據。
rewind():可以將 position 位置設置為 0,再次讀取緩沖區中的數據
clear():清空整個緩沖區,它會將 position 設置為 0,limit 設置為 capacity,可以寫整個緩沖區
更多的方法可以去查閱 API 文檔,本文礙于篇幅原因就不貼出其它方法了,主要是要理解緩沖區的作用
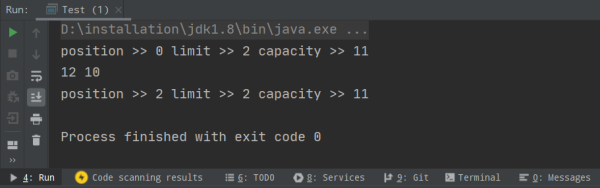
我們來看一個簡單的例子
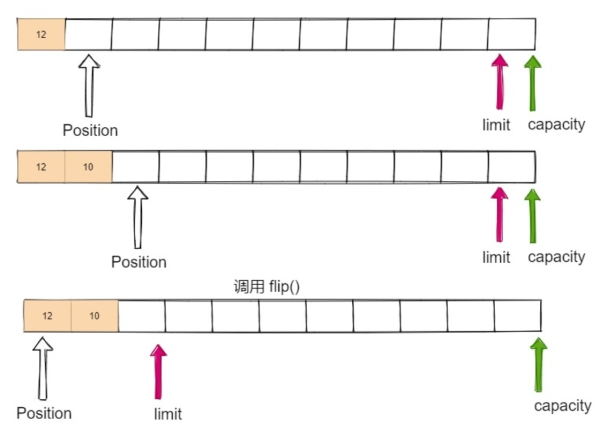
public Class Main { public static void main(String[] args) { // 分配內存大小為11的整型緩存區 IntBuffer buffer = IntBuffer.allocate(11); // 往buffer里寫入2個整型數據 for (int i = 0; i < 2; ++i) { int randomNum = new SecureRandom().nextInt(); buffer.put(randomNum); } // 將Buffer從寫模式切換到讀模式 buffer.flip(); System.out.println("position >> " + buffer.position() + "limit >> " + buffer.limit() + "capacity >> " + buffer.capacity()); // 讀取buffer里的數據 while (buffer.hasRemaining()) { System.out.println(buffer.get()); } System.out.println("position >> " + buffer.position() + "limit >> " + buffer.limit() + "capacity >> " + buffer.capacity()); }}執行結果如下圖所示,首先我們往緩沖區中寫入 2 個數據,position 在寫模式下指向下標 2,然后調用 flip() 方法切換為讀模式,limit 指向下標 2,position 從 0 開始讀數據,讀到下標為 2 時發現到達 limit 位置,不可繼續讀。
整個過程可以用下圖來理解,調用 flip() 方法以后,讀出數據的同時 position 指針不斷往后挪動,到達 limit 指針的位置時,該次讀取操作結束。
介紹完緩沖區后,我們知道它是存儲數據的空間,進程可以將緩沖區中的數據讀取出來,也可以寫入新的數據到緩沖區,那緩沖區的數據從哪里來,又怎么寫出去呢?接下來我們需要學習傳輸數據的介質:通道(Channel)
上面我們介紹過,通道是作為一種連接資源,作用是傳輸數據,而真正存儲數據的是緩沖區,所以介紹完緩沖區后,我們來學習通道這一塊。
通道是可以雙向讀寫的,傳統的 BIO 需要使用輸入/輸出流表示數據的流向,在 NIO 中可以減少通道資源的消耗。
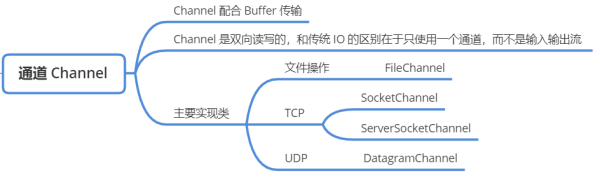
通道類都保存在 java.nio.channels 包下,我們日常用到的幾個重要的類有 4 個:
IO 通道類型具體類文件 IOFileChannel(用于文件讀寫、操作文件的通道)
TCP 網絡 IOSocketChannel(用于讀寫數據的 TCP 通道)、
ServerSocketChannel(監聽客戶端的連接)
UDP 網絡 IODatagramChannel(收發 UDP 數據報的通道)
可以通過 getChannel() 方法獲取一個通道,支持獲取通道的類如下:
文件 IO:FileInputStream、FileOutputStream、RandomAccessFile
TCP 網絡 IO:Socket、ServerSocket
UDP 網絡 IO:DatagramSocket
我們來看一個利用通道拷貝文件的例子,需要下面幾個步驟:
打開原文件的輸入流通道,將字節數據讀入到緩沖區中
打開目的文件的輸出流通道,將緩沖區中的數據寫到目的地
關閉所有流和通道(重要!)
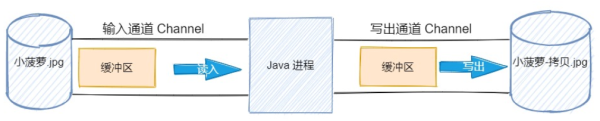
這是一張小菠蘿的照片,它存在于d:\小菠蘿\文件夾下,我們將它拷貝到 d:\小菠蘿分身\ 文件夾下。
public class Test { /** 緩沖區的大小 */ public static final int SIZE = 1024; public static void main(String[] args) throws IOException { // 打開文件輸入流 FileChannel inChannel = new FileInputStream("d:\小菠蘿\小菠蘿.jpg").getChannel(); // 打開文件輸出流 FileChannel outChannel = new FileOutputStream("d:\小菠蘿分身\小菠蘿-拷貝.jpg").getChannel(); // 分配 1024 個字節大小的緩沖區 ByteBuffer dsts = ByteBuffer.allocate(SIZE); // 將數據從通道讀入緩沖區 while (inChannel.read(dsts) != -1) { // 切換緩沖區的讀寫模式 dsts.flip(); // 將緩沖區的數據通過通道寫到目的地 outChannel.write(dsts); // 清空緩沖區,準備下一次讀 dsts.clear(); } inChannel.close(); outChannel.close(); } }我畫了一張圖幫助你理解上面的這一個過程。
有人會問,NIO 的文件拷貝和傳統 IO 流的文件拷貝有何不同呢?我們在編程時感覺它們沒有什么區別呀,貌似只是 API 不同罷了,我們接下來就去看看這兩者之間的區別吧。
這個時候就要來了解了解操作系統底層是怎么對 IO 和 NIO 進行區別的,我會用盡量通俗的文字帶你理解,可能并不是那么嚴謹。
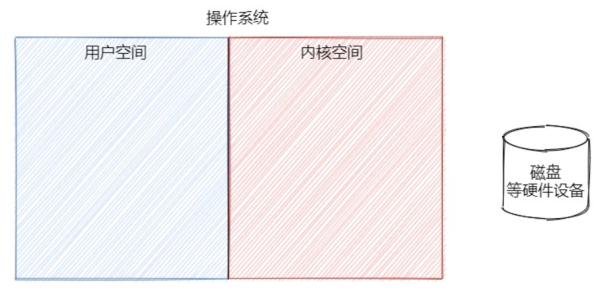
操作系統最重要的就是內核,它既可以訪問受保護的內存,也可以訪問底層硬件設備,所以為了保護內核的安全,操作系統將底層的虛擬空間分為了用戶空間和內核空間,其中用戶空間就是給用戶進程使用的,內核空間就是專門給操作系統底層去使用的。
接下來,有一個 Java 進程希望把小菠蘿這張圖片從磁盤上拷貝,那么內核空間和用戶空間都會有一個緩沖區
這張照片就會從磁盤中讀出到內核緩沖區中保存,然后操作系統將內核緩沖區中的這張圖片字節數據拷貝到用戶進程的緩沖區中保存下來,
對應著下面這幅圖
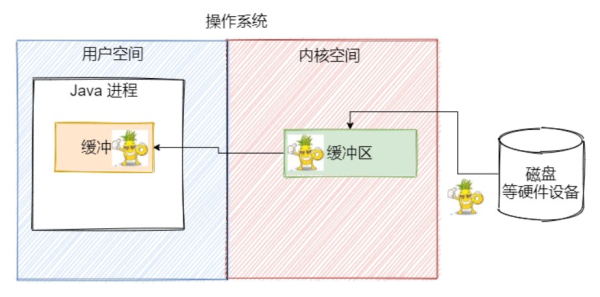
然后用戶進程會希望把緩沖區中的字節數據寫到磁盤上的另外一個地方,會將數據拷貝到 Socket 緩沖區中,最終操作系統再將 Socket 緩沖區的數據寫到磁盤的指定位置上。
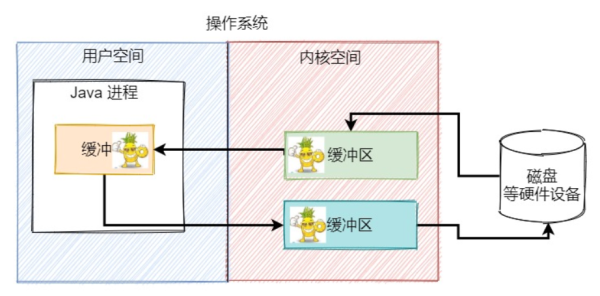
這一輪操作下來,我們數數經過了幾次數據的拷貝?4 次。有 2 次是內核空間和用戶空間之間的數據拷貝,這兩次拷貝涉及到用戶態和內核態的切換,需要CPU參與進來,進行上下文切換。而另外 2 次是硬盤和內核空間之間的數據拷貝,這個過程利用到 DMA與系統內存交換數據,不需要 CPU 的參與。
導致 IO 性能瓶頸的原因:內核空間與用戶空間之間數據過多無意義的拷貝,以及多次上下文切換
操作狀態用戶進程請求讀取數據用戶態 -> 內核態操作系統內核返回數據給用戶進程內核態 -> 用戶態用戶進程請求寫數據到硬盤用戶態 -> 內核態操作系統返回操作結果給用戶進程內核態 -> 用戶態
在用戶空間與內核空間之間的操作,會涉及到上下文的切換,這里需要 CPU 的干預,而數據在兩個空間之間來回拷貝,也需要 CPU 的干預,這無疑會增大 CPU 的壓力,NIO 是如何減輕 CPU 的壓力?運用操作系統的零拷貝技術。
所以,操作系統出現了一個全新的概念,解決了 IO 瓶頸:零拷貝。零拷貝指的是內核空間與用戶空間之間的零次拷貝。
零拷貝可以說是 IO 的一大救星,操作系統底層有許多種零拷貝機制,我這里僅針對 Java NIO 中使用到的其中一種零拷貝機制展開講解。
在 Java NIO 中,零拷貝是通過用戶空間和內核空間的緩沖區共享一塊物理內存實現的,也就是說上面的圖可以演變成這個樣子。
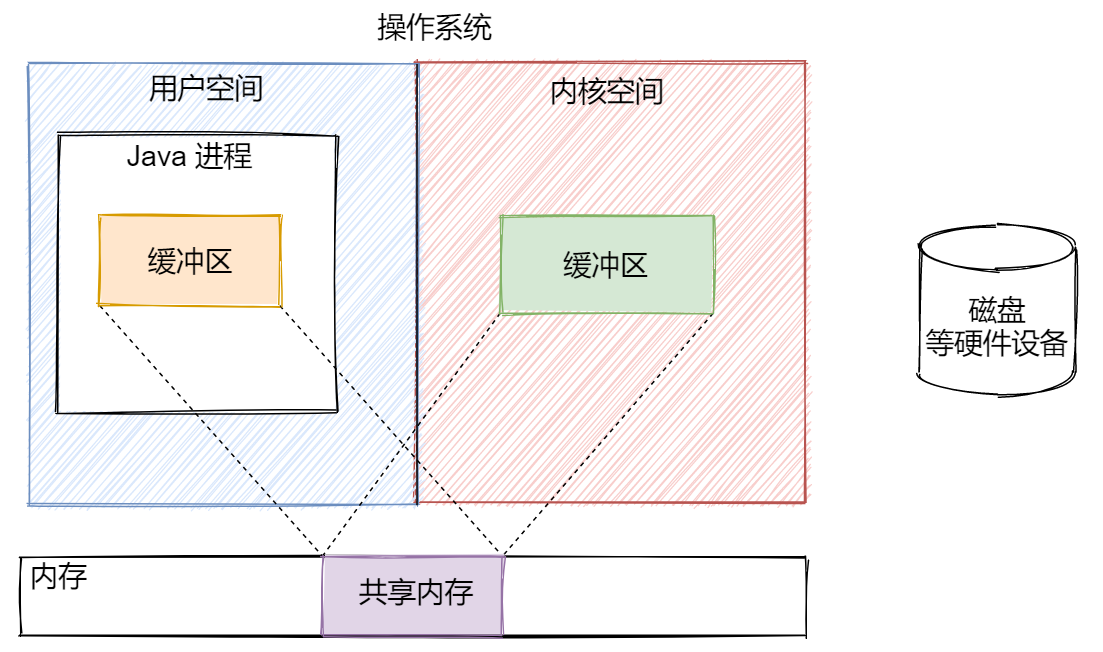
這時,無論是用戶空間還是內核空間操作自己的緩沖區,本質上都是操作這一塊共享內存中的緩沖區數據,省去了用戶空間和內核空間之間的數據拷貝操作。
現在我們重新來拷貝文件,就會變成下面這個步驟:
用戶進程通過系統調用 read() 請求讀取文件到用戶空間緩沖區(第一次上下文切換),用戶態 -> 核心態,數據從硬盤讀取到內核空間緩沖區中(第一次數據拷貝)
系統調用返回到用戶進程(第二次上下文切換),此時用戶空間與內核空間共享這一塊內存(緩沖區),所以不需要從內核緩沖區拷貝到用戶緩沖區
用戶進程發出 write() 系統調用請求寫數據到硬盤上(第三次上下文切換),此時需要將內核空間緩沖區中的數據拷貝到內核的 Socket 緩沖區中(第二次數據拷貝)
由 DMA 將 Socket 緩沖區的內容寫到硬盤上(第三次數據拷貝),write() 系統調用返回(第四次上下文切換)
整個過程就如下面這幅圖所示。
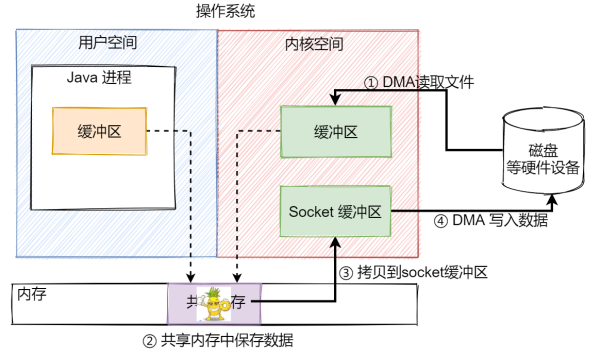
圖中,需要 CPU 參與工作的步驟只有第③個步驟,對比于傳統的 IO,CPU 需要在用戶空間與內核空間之間參與拷貝工作,需要無意義地占用 2 次 CPU 資源,導致 CPU 資源的浪費。
下面總結一下操作系統中零拷貝的優點:
降低 CPU 的壓力:避免 CPU 需要參與內核空間與用戶空間之間的數據拷貝工作
減少不必要的拷貝:避免用戶空間與內核空間之間需要進行數據拷貝
上面的圖示可能并不嚴謹,對于你理解零拷貝會有一定的幫助,關于零拷貝的知識點可以去查閱更多資料哦,這是一門大學問。
介紹完通道后,我們知道它是用于傳輸數據的一種介質,而且是可以雙向讀寫的,那么如果放在網絡 IO 中,這些通道如果有數據就緒時,服務器是如何發現并處理的呢?接下來我們去學習 NIO 中的最后一個重要知識點:選擇器(Selector)
選擇器是提升 IO 性能的靈魂之一,它底層利用了多路復用 IO機制,讓選擇器可以監聽多個 IO 連接,根據 IO 的狀態響應到服務器端進行處理。通俗地說:選擇器可以監聽多個 IO 連接,而傳統的 BIO 每個 IO 連接都需要有一個線程去監聽和處理。

圖中很明顯的顯示了在 BIO 中,每個 Socket 都需要有一個專門的線程去處理每個請求,而在 NIO 中,只需要一個 Selector 即可監聽各個 Socket 請求,而且 Selector 并不是阻塞的,所以不會因為多個線程之間切換導致上下文切換帶來的開銷。
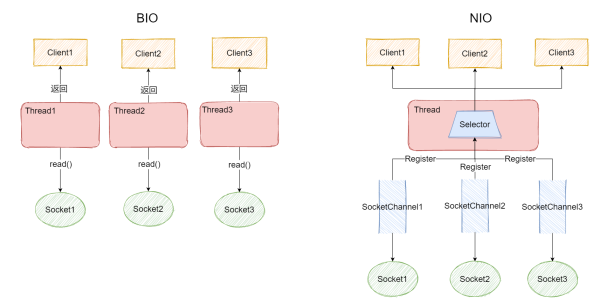
在 Java NIO 中,選擇器是使用 Selector 類表示,Selector 可以接收各種 IO 連接,在 IO 狀態準備就緒時,會通知該通道注冊的 Selector,Selector 在下一次輪詢時會發現該 IO 連接就緒,進而處理該連接。
Selector 選擇器主要用于網絡 IO當中,在這里我會將傳統的 BIO Socket 編程和使用 NIO 后的 Socket 編程作對比,分析 NIO 為何更受歡迎。首先先來了解 Selector 的基本結構。
重要方法方法解析open()打開一個 Selector 選擇器int select()阻塞地等待就緒的通道int select(long timeout)最多阻塞 timeout 毫秒,如果是 0 則一直阻塞等待,如果是 1 則代表最多阻塞 1 毫秒int selectNow()非阻塞地輪詢就緒的通道
在這里,你會看到 select() 和它的重載方法是會阻塞的,如果用戶進程輪詢時發現沒有就緒的通道,操作系統有兩種做法:
一直等待直到一個就緒的通道,再返回給用戶進程
立即返回一個錯誤狀態碼給用戶進程,讓用戶進程繼續運行,不會阻塞
這兩種方法對應了同步阻塞 IO 和 同步非阻塞 IO ,這里讀者的一點小的觀點,請各位大神批判閱讀
Java 中的 NIO 不能真正意義上稱為 Non-Blocking IO,我們通過 API 的調用可以發現,select() 方法還是會存在阻塞的現象,根據傳入的參數不同,操作系統的行為也會有所不同,不同之處就是阻塞還是非阻塞,所以我更傾向于把 NIO 稱為 New IO,因為它不僅提供了 Non-Blocking IO,而且保留原有的 Blocking IO 的功能。
了解了選擇器之后,它的作用就是:監聽多個 IO 通道,當有通道就緒時選擇器會輪詢發現該通道,并做相應的處理。那么 IO 狀態分為很多種,我們如何去識別就緒的通道是處于哪種狀態呢?在 Java 中提供了選擇鍵(SelectionKey)。
在 Java 中提供了 4 種選擇鍵:
SelectionKey.OP_READ:套接字通道準備好進行讀操作
SelectionKey.OP_WRITE:套接字通道準備好進行寫操作
SelectionKey.OP_ACCEPT:服務器套接字通道接受其它通道
SelectionKey.OP_CONNECT:套接字通道準備完成連接
在 SelectionKey 中包含了許多屬性
channel:該選擇鍵綁定的通道
selector:輪詢到該選擇鍵的選擇器
readyOps:當前就緒選擇鍵的值
interesOps:該選擇器對該通道感興趣的所有選擇鍵
選擇鍵的作用是:在選擇器輪詢到有就緒通道時,會返回這些通道的就緒選擇鍵(SelectionKey),通過選擇鍵可以獲取到通道進行操作。
簡單了解了選擇器后,我們可以結合緩沖區、通道和選擇器來完成一個簡易的聊天室應用。
先說明,這里的代碼非常的臭和長,不推薦細看,直接看注釋附近的代碼即可。
我們在服務器端會開辟兩個線程
Thread1:專門監聽客戶端的連接,并把通道注冊到客戶端選擇器上
Thread2:專門監聽客戶端的其它 IO 狀態(讀狀態),當客戶端的 IO 狀態就緒時,該選擇器會輪詢發現,并作相應處理
public class NIOServer { Selector serverSelector = Selector.open(); Selector clientSelector = Selector.open(); public static void main(String[] args) throws IOException { NIOServer server = nwe NIOServer(); new Thread(() -> { try { // 對應IO編程中服務端啟動 ServerSocketChannel listenerChannel = ServerSocketChannel.open(); listenerChannel.socket().bind(new InetSocketAddress(3333)); listenerChannel.configureBlocking(false); listenerChannel.register(serverSelector, SelectionKey.OP_ACCEPT); server.acceptListener(); } catch (IOException ignored) { } }).start(); new Thread(() -> { try { server.clientListener(); } catch (IOException ignored) { } }).start(); }}// 監聽客戶端連接public void acceptListener() { while (true) { if (serverSelector.select(1) > 0) { Set<SelectionKey> set = serverSelector.selectedKeys(); Iterator<SelectionKey> keyIterator = set.iterator(); while (keyIterator.hasNext()) { SelectionKey key = keyIterator.next(); if (key.isAcceptable()) { try { // (1) 每來一個新連接,注冊到clientSelector SocketChannel clientChannel = ((ServerSocketChannel) key.channel()).accept(); clientChannel.configureBlocking(false); clientChannel.register(clientSelector, SelectionKey.OP_READ); } finally { // 從就緒的列表中移除這個key keyIterator.remove(); } } } } }}// 監聽客戶端的 IO 狀態就緒public void clientListener() { while (true) { // 批量輪詢是否有哪些連接有數據可讀 if (clientSelector.select(1) > 0) { Set<SelectionKey> set = clientSelector.selectedKeys(); Iterator<SelectionKey> keyIterator = set.iterator(); while (keyIterator.hasNext()) { SelectionKey key = keyIterator.next(); // 判斷該通道是否讀就緒狀態 if (key.isReadable()) { try { // 獲取客戶端通道讀入數據 SocketChannel clientChannel = (SocketChannel) key.channel(); ByteBuffer byteBuffer = ByteBuffer.allocate(1024); clientChannel.read(byteBuffer); byteBuffer.flip(); System.out.println( LocalDateTime.now().toString() + " Server 端接收到來自 Client 端的消息: " + Charset.defaultCharset().decode(byteBuffer).toString()); } finally { // 從就緒的列表中移除這個key keyIterator.remove(); key.interestOps(SelectionKey.OP_READ); } } } } }}在客戶端,我們可以簡單的輸入一些文字,發送給服務器
public class NIOClient { public static final int CAPACITY = 1024; public static void main(String[] args) throws Exception { ByteBuffer dsts = ByteBuffer.allocate(CAPACITY); SocketChannel socketChannel = SocketChannel.open(new InetSocketAddress("127.0.0.1", 3333)); socketChannel.configureBlocking(false); Scanner sc = new Scanner(System.in); while (true) { String msg = sc.next(); dsts.put(msg.getBytes()); dsts.flip(); socketChannel.write(dsts); dsts.clear(); } } }下圖可以看見,在客戶端給服務器端發送信息,服務器接收到消息后,可以將該條消息分發給其它客戶端,就可以實現一個簡單的群聊系統,我們還可以給這些客戶端貼上標簽例如用戶姓名,聊天等級······,就可以標識每個客戶端啦。在這里由于篇幅原因,我沒有寫出所有功能,因為使用原生的 NIO 實在是不太便捷。
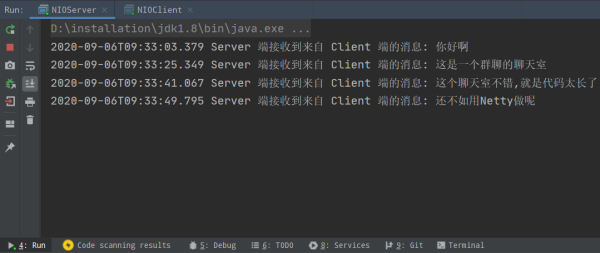
我相信你們都是直接滑下來看這里的,我在寫這段代碼的時候也非常痛苦,甚至有點厭煩 Java 原生的 NIO 編程。實際上我們在日常開發中很少直接用 NIO 進行編程,通常都會用 Netty,Mina 這種服務器框架,它們都是很好地 NIO 技術,對 Java 原生的 NIO 進行了上層的封裝、優化,簡化開發難度,但是在學習框架之前,我們需要了解它底層原生的技術,就像 Spring AOP 的動態代理,Spring IOC 容器的 Map 容器存儲對象,Netty 底層的 NIO 基礎NIO 與 BIO 兩者的對比:同步/非同步、阻塞/非阻塞,在文件 IO 和 網絡 IO 中,使用 NIO 相對于使用 BIO 有什么優勢
到此,相信大家對“關于Java IO的知識點有哪些”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





