溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“如何用Python寫一個電信客戶流失預測模型”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“如何用Python寫一個電信客戶流失預測模型”吧!
01、商業理解
流失客戶是指那些曾經使用過產品或服務,由于對產品失去興趣等種種原因,不再使用產品或服務的顧客。
電信服務公司、互聯網服務提供商、保險公司等經常使用客戶流失分析和客戶流失率作為他們的關鍵業務指標之一,因為留住一個老客戶的成本遠遠低于獲得一個新客戶。
預測分析使用客戶流失預測模型,通過評估客戶流失的風險傾向來預測客戶流失。由于這些模型生成了一個流失概率排序名單,對于潛在的高概率流失客戶,他們可以有效地實施客戶保留營銷計劃。
下面我們就教你如何用Python寫一個電信用戶流失預測模型,以下是具體步驟和關鍵代碼。
02、數據理解
此次分析數據來自于IBM Sample Data Sets,統計自某電信公司一段時間內的消費數據。共有7043筆客戶資料,每筆客戶資料包含21個字段,其中1個客戶ID字段,19個輸入字段及1個目標字段-Churn(Yes代表流失,No代表未流失),輸入字段主要包含以下三個維度指標:用戶畫像指標、消費產品指標、消費信息指標。字段的具體說明如下:

03、數據讀入和概覽
首先導入所需包。
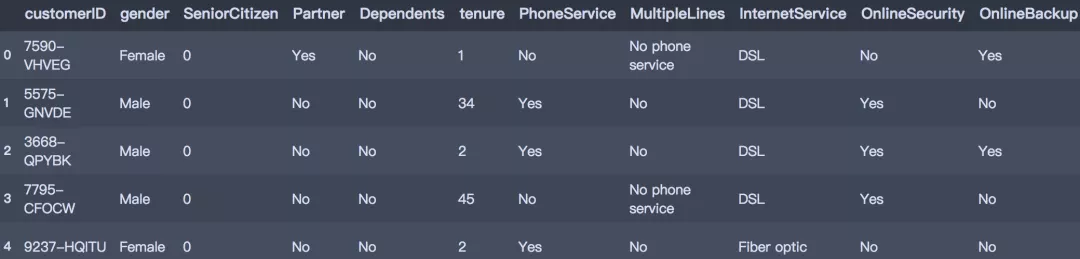
df = pd.read_csv('./Telco-Customer-Churn.csv') df.head()讀入數據集
df = pd.read_csv('./Telco-Customer-Churn.csv')
df.head()
04、數據初步清洗
首先進行初步的數據清洗工作,包含錯誤值和異常值處理,并劃分類別型和數值型字段類型,其中清洗部分包含:
OnlineSecurity、OnlineBackup、DeviceProtection、TechSupport、StreamingTV、StreamingMovies:錯誤值處理
TotalCharges:異常值處理
tenure:自定義分箱
定義類別型和數值型字段
# 錯誤值處理 repl_columns = ['OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport','StreamingTV', 'StreamingMovies'] for i in repl_columns: df[i] = df[i].replace({'No internet service' : 'No'}) # 替換值SeniorCitizendf["SeniorCitizen"] = df["SeniorCitizen"].replace({1: "Yes", 0: "No"}) # 替換值TotalChargesdf['TotalCharges'] = df['TotalCharges'].replace(' ', np.nan) # TotalCharges空值:數據量小,直接刪除df = df.dropna(subset=['TotalCharges']) df.reset_index(drop=True, inplace=True) # 重置索引# 轉換數據類型df['TotalCharges'] = df['TotalCharges'].astype('float') # 轉換tenuredef transform_tenure(x): if x <= 12: return 'Tenure_1' elif x <= 24: return 'Tenure_2' elif x <= 36: return 'Tenure_3' elif x <= 48: return 'Tenure_4' elif x <= 60: return 'Tenure_5' else: return 'Tenure_over_5' df['tenure_group'] = df.tenure.apply(transform_tenure) # 數值型和類別型字段Id_col = ['customerID'] target_col = ['Churn'] cat_cols = df.nunique()[df.nunique() < 10].index.tolist() num_cols = [i for i in df.columns if i not in cat_cols + Id_col] print('類別型字段:\n', cat_cols) print('-' * 30) print('數值型字段:\n', num_cols)類別型字段: ['gender', 'SeniorCitizen', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod', 'Churn', 'tenure_group'] ------------------------------ 數值型字段: ['tenure', 'MonthlyCharges', 'TotalCharges']
05、探索性分析
對指標進行歸納梳理,分用戶畫像指標,消費產品指標,消費信息指標。探索影響用戶流失的關鍵因素。
1. 目標變量Churn分布
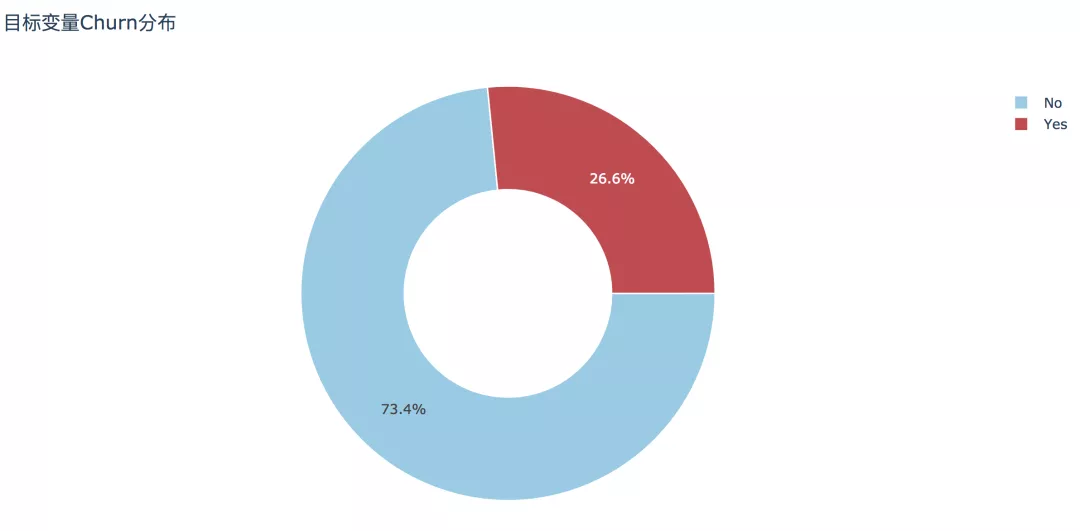
經過初步清洗之后的數據集大小為7032條記錄,其中流失客戶為1869條,占比26.6%,未流失客戶占比73.4%。
df['Churn'].value_counts() No 5163 Yes 1869 Name: Churn, dtype: int64
trace0 = go.Pie(labels=df['Churn'].value_counts().index, values=df['Churn'].value_counts().values, hole=.5, rotation=90, marker=dict(colors=['rgb(154,203,228)', 'rgb(191,76,81)'], line=dict(color='white', width=1.3)) )data = [trace0] layout = go.Layout(title='目標變量Churn分布') fig = go.Figure(data=data, layout=layout) py.offline.plot(fig, filename='./html/整體流失情況分布.html')
2.性別
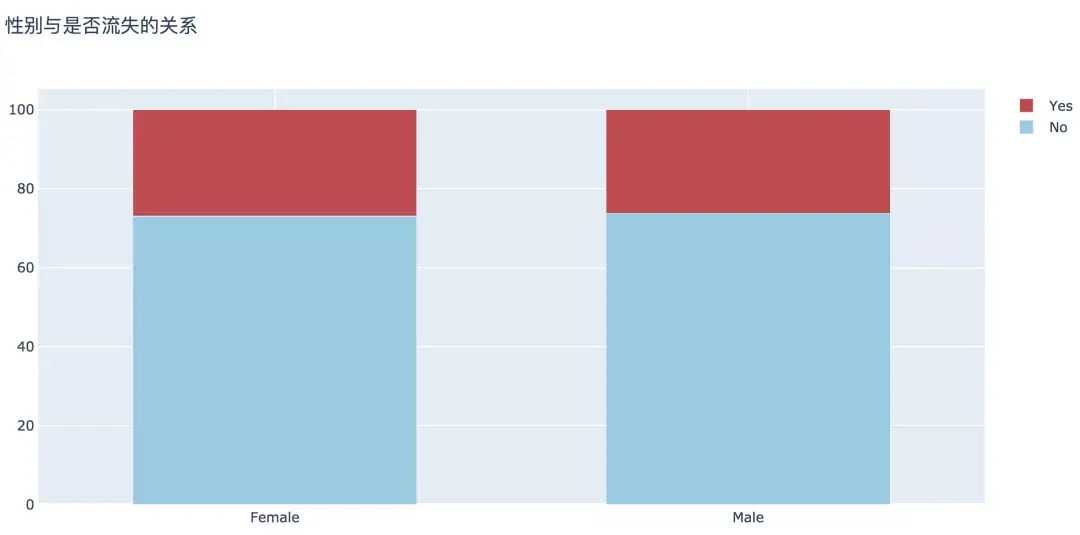
分析可見,男性和女性在客戶流失比例上沒有顯著差異。
plot_bar(input_col='gender', target_col='Churn', title_name='性別與是否流失的關系')
3. 老年用戶
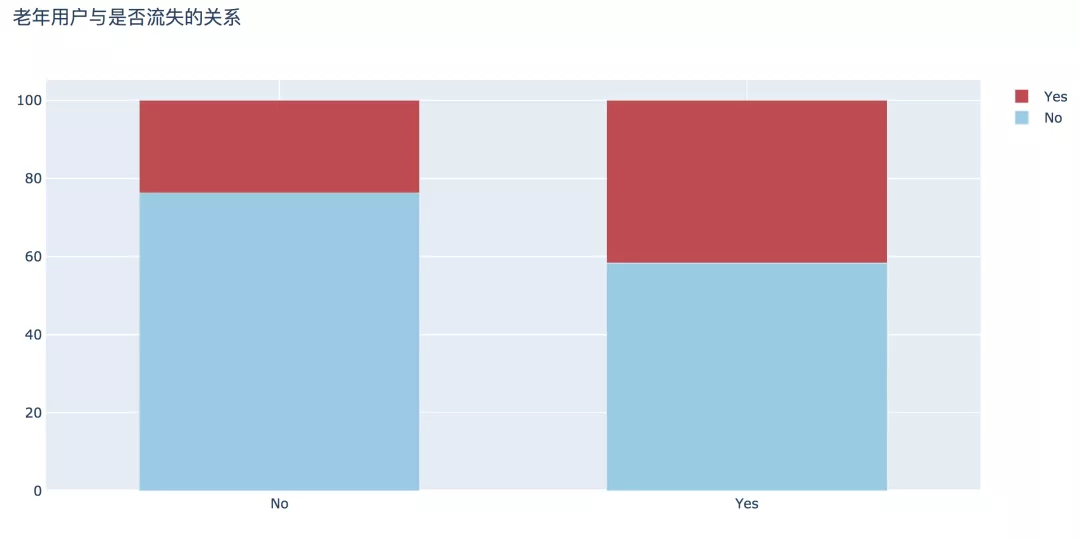
老年用戶流失比例更高,為41.68%,比非老年用戶高近兩倍,此部分原因有待進一步探討。
plot_bar(input_col='SeniorCitizen', target_col='Churn', title_name='老年用戶與是否流失的關系')
4. 是否有配偶
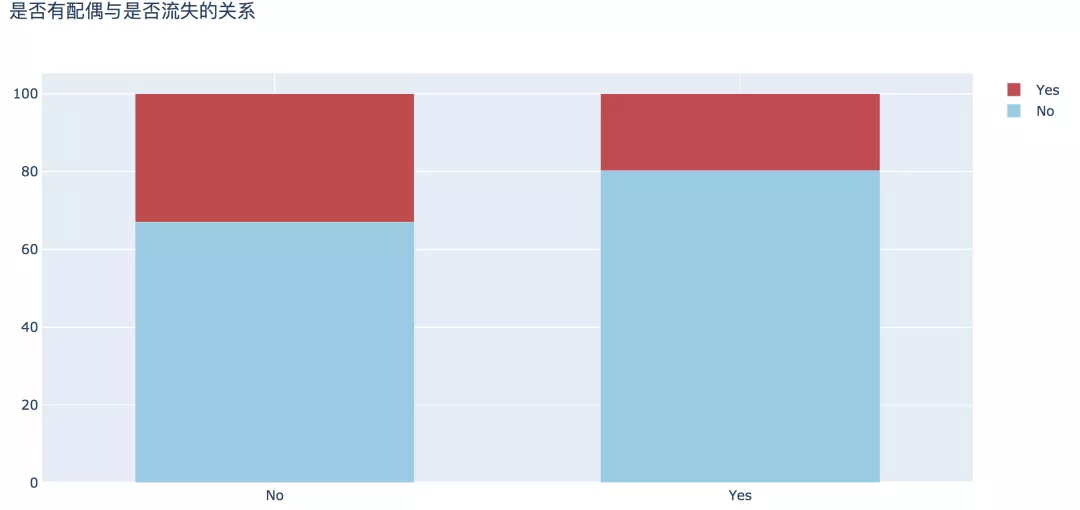
從婚姻情況來看,數據顯示,未婚人群中流失的比例比已婚人數高出13%。
plot_bar(input_col='Partner', target_col='Churn', title_name='是否有配偶與是否流失的關系')
5. 上網時長
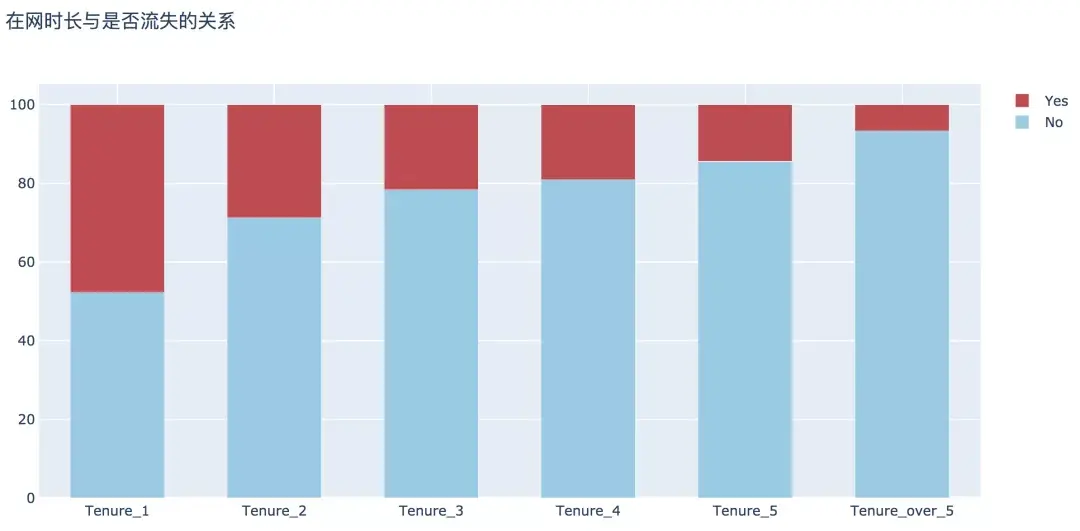
經過分析,這方面可以得出兩個結論:
用戶的在網時長越長,表示用戶的忠誠度越高,其流失的概率越低;
新用戶在1年內的流失率顯著高于整體流失率,為47.68%。
plot_bar(input_col='tenure_group', target_col='Churn', title_name='在網時長與是否流失的關系')
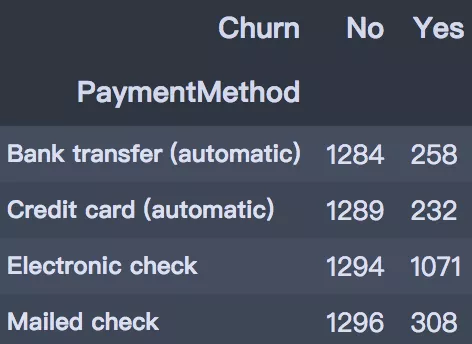
6. 付款方式
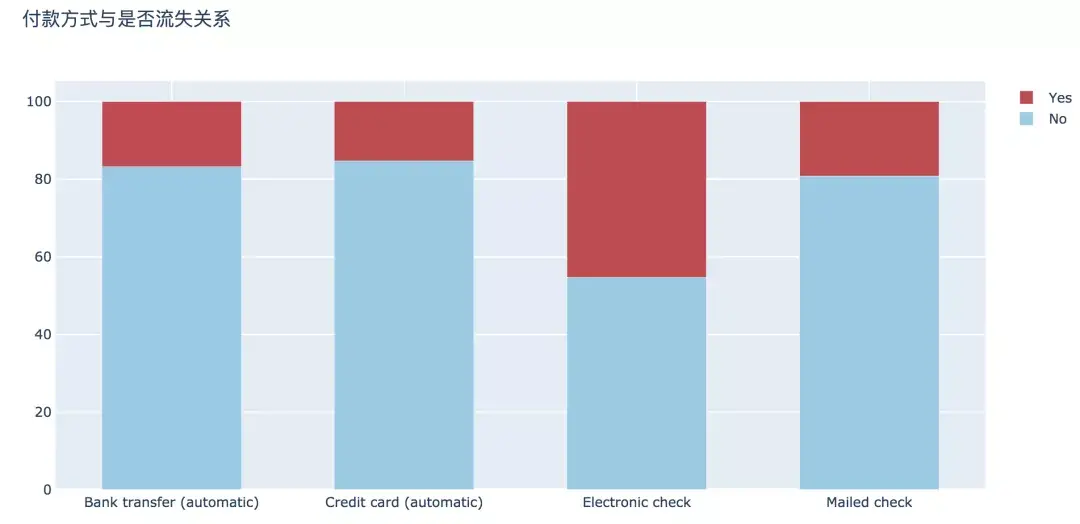
支付方式上,支付上,選擇電子支票支付方式的用戶流失最高,達到45.29%,其他三種支付方式的流失率相差不大。
pd.crosstab(df['PaymentMethod'], df['Churn'])
plot_bar(input_col='PaymentMethod', target_col='Churn', title_name='付款方式與是否流失關系')
7. 月費用
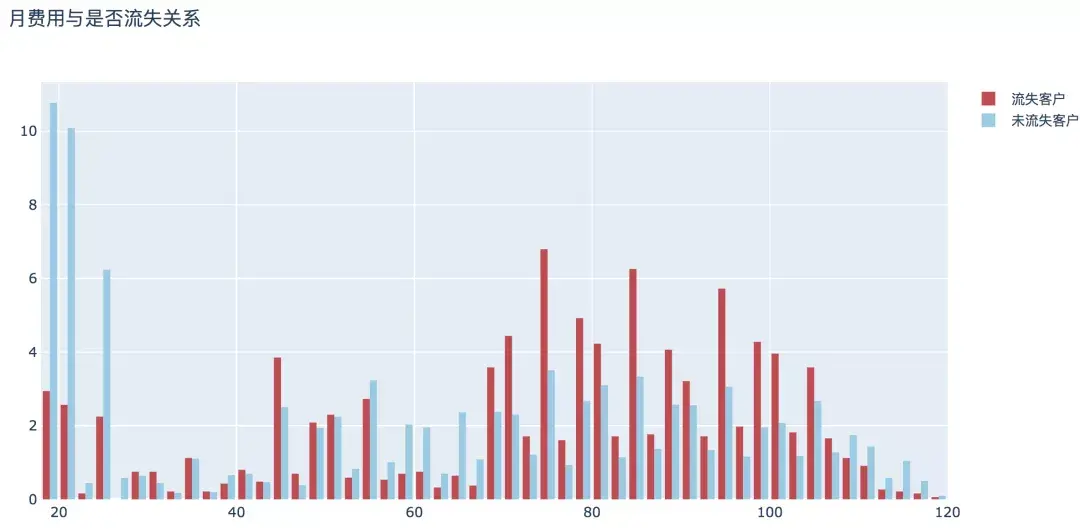
整體來看,隨著月費用的增加,流失用戶的比例呈現高高低低的變化,月消費80-100元的用戶相對較高。
plot_histogram(input_col='MonthlyCharges', title_name='月費用與是否流失關系')
8. 數值型屬性相關性
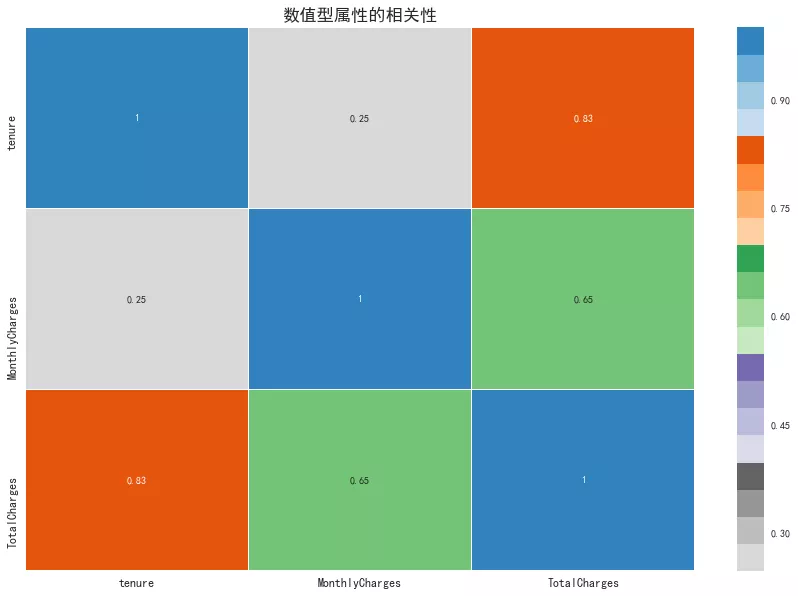
從相關性矩陣圖可以看出,用戶的往來期間和總費用呈現高度相關,往來期間越長,則總費用越高。月消費和總消費呈現顯著相關。
plt.figure(figsize=(15, 10)) sns.heatmap(df.corr(), linewidths=0.1, cmap='tab20c_r', annot=True) plt.title('數值型屬性的相關性', fontdict={'fontsize': 'xx-large', 'fontweight':'heavy'}) plt.xticks(fontsize=12) plt.yticks(fontsize=12) plt.show()06、特征選擇
使用統計檢定方式進行特征篩選。
# 刪除tenure df = df.drop('tenure', axis=1) from feature_selection import Feature_select# 劃分X和yX = df.drop(['customerID', 'Churn'], axis=1) y = df['Churn'] fs = Feature_select(num_method='anova', cate_method='kf', pos_label='Yes') x_sel = fs.fit_transform(X, y) 2020 09:30:02 INFO attr select success! After select attr: ['DeviceProtection', 'MultipleLines', 'OnlineSecurity', 'TechSupport', 'tenure_group', 'PaperlessBilling', 'InternetService', 'PaymentMethod', 'SeniorCitizen', 'MonthlyCharges', 'Dependents', 'Partner', 'Contract', 'StreamingTV', 'TotalCharges', 'StreamingMovies', 'OnlineBackup']經過特征篩選,gender和PhoneService字段被去掉。
07、建模前處理
在python中,為滿足建模需要,一般需要對數據做以下處理:
對于二分類變量,編碼為0和1;
對于多分類變量,進行one_hot編碼;
對于數值型變量,部分模型如KNN、神經網絡、Logistic需要進行標準化處理。
# 篩選變量 select_features = x_sel.columns# 建模數據df_model = pd.concat([df['customerID'], df[select_features], df['Churn']], axis=1)Id_col = ['customerID']target_col = ['Churn']# 分類型cat_cols = df_model.nunique()[df_model.nunique() < 10].index.tolist() # 二分類屬性 binary_cols = df_model.nunique()[df_model.nunique() == 2].index.tolist() # 多分類屬性 multi_cols = [i for i in cat_cols if i not in binary_cols] # 數值型 num_cols = [i for i in df_model.columns if i not in cat_cols + Id_col] # 二分類-標簽編碼 le = LabelEncoder() for i in binary_cols: df_model[i] = le.fit_transform(df_model[i]) # 多分類-啞變量轉換 df_model = pd.get_dummies(data=df_model, columns=multi_cols) df_model.head()
08、模型建立和評估
首先使用分層抽樣的方式將數據劃分訓練集和測試集。
# 重新劃分 X = df_model.drop(['customerID', 'Churn'], axis=1) y = df_model['Churn'] # 分層抽樣X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0, stratify=y) print(X_train.shape, X_test.shape, y_train.shape, y_test.shape) #修正索引for i in [X_train, X_test, y_train, y_test]: i.index = range(i.shape[0])
(5625, 31) (1407, 31) (5625,) (1407,)
# 保存標準化訓練和測試數據 st = StandardScaler()num_scaled_train = pd.DataFrame(st.fit_transform(X_train[num_cols]), columns=num_cols)num_scaled_test = pd.DataFrame(st.transform(X_test[num_cols]), columns=num_cols) X_train_sclaed = pd.concat([X_train.drop(num_cols, axis=1), num_scaled_train], axis=1) X_test_sclaed = pd.concat([X_test.drop(num_cols, axis=1), num_scaled_test], axis=1)
然后建立一系列基準模型并比較效果。
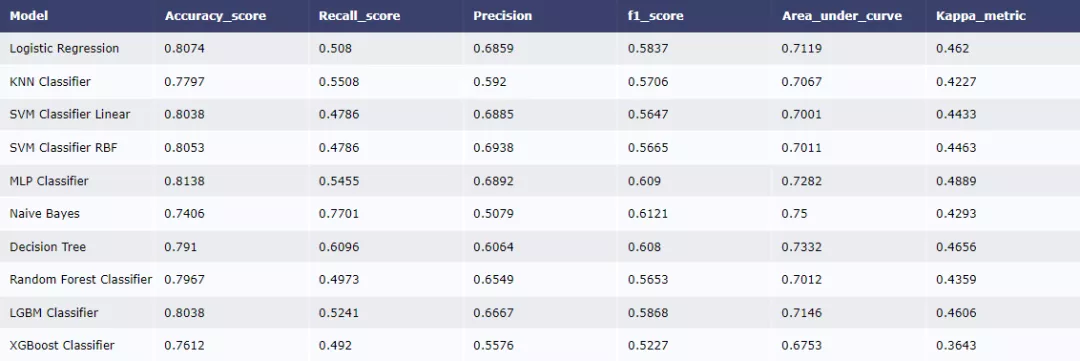
假如我們關注roc指標,從模型表現效果來看,Naive Bayes效果最好。我們也可以對模型進行進一步優化,比如對決策樹參數進行調優。
parameters = {'splitter': ('best','random'), 'criterion': ("gini","entropy"), "max_depth": [*range(3, 20)], }clf = DecisionTreeClassifier(random_state=25) GS = GridSearchCV(clf, parameters, scoring='f1', cv=10) GS.fit(X_train, y_train)print(GS.best_params_) print(GS.best_score_){'criterion': 'entropy', 'max_depth': 5, 'splitter': 'best'} 0.585900839405024clf = GS.best_estimator_ test_pred = clf.predict(X_test)print('測試集:\n', classification_report(y_test, test_pred))測試集: precision recall f1-score support 0 0.86 0.86 0.86 1033 1 0.61 0.61 0.61 374 accuracy 0.79 1407 macro avg 0.73 0.73 0.73 1407 weighted avg 0.79 0.79 0.79 1407
將這棵樹繪制出來。
import graphviz dot_data = tree.export_graphviz(decision_tree=clf, max_depth=3, out_file=None, feature_names=X_train.columns, class_names=['not_churn', 'churn'], filled=True, rounded=True )graph = graphviz.Source(dot_data)
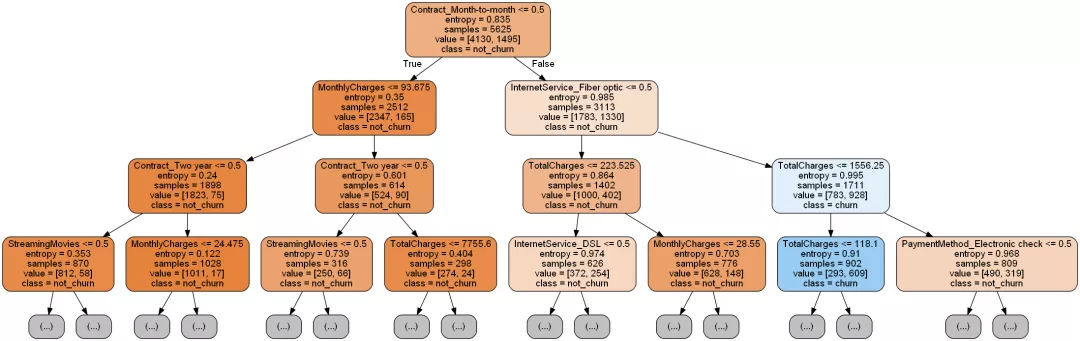
輸出決策樹屬性重要性排序:
imp = pd.DataFrame(zip(X_train.columns, clf.feature_importances_)) imp.columns = ['feature', 'importances'] imp = imp.sort_values('importances', ascending=False) imp = imp[imp['importances'] != 0] table = ff.create_table(np.round(imp, 4)) py.offline.iplot(table)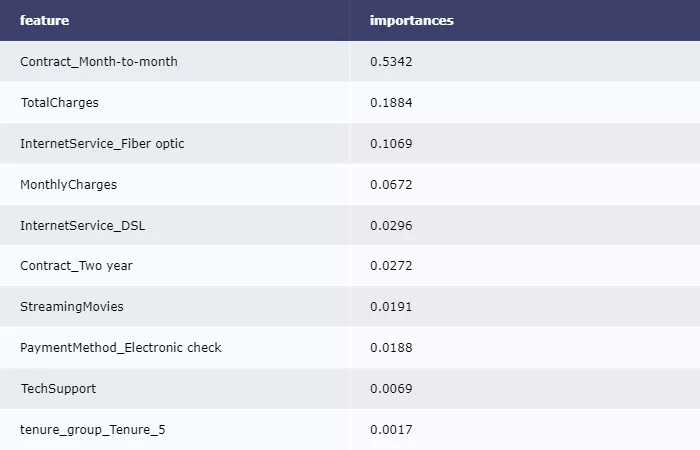
后續優化方向:
數據:分類技術應用在目標類別分布越均勻的數據集時,其所建立之分類器通常會有比較好的分類效能。針對數據在目標字段上分布不平衡,可采用過采樣和欠采樣來處理類別不平衡問題;
屬性:進一步屬性篩選方法和屬性組合;
算法:參數調優;調整預測門檻值來增加預測效能。
到此,相信大家對“如何用Python寫一個電信客戶流失預測模型”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





