溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
字符串處理
1,字符串分割
(a)split 方法
str1 = "http:// www.qwe, qwe; qwe,qwe" import re re.split(r'[,;\s]\s*',str1) >>> ['http://', 'www.qwe', 'qwe', 'qwe', 'qwe']
一般簡單的可以使用 str.split("xxx")進行分割。但是re.split( ) 用起來更加的靈活。
2, 字符串開頭和結尾
(a) str.startswith( )/str.endswith( )
filename = "http://zaixiankefu.txt"
filename.endswith(".txt")
>>>True
filename.startswith("http:")
>>>True
# startswith( )和 endswith( )可以接收一個元組數據,注意是元組。
choice = (".txt",".avi")
filename.endswith(choice)
>>>True(b) 也可以使用切片來判斷
if filename[:4] == "http" and filename[-4:] == ".txt": return True
3,字符串匹配
簡單的就是str.startswith( ),str.endswith( ),str.find(),前兩種返回時bool 值,find是返回第一次匹配的下標值。
使用正則進行匹配(更多方法參考正則文檔)。
(a)re.match( )
match 總是從字符串開始去匹配 。如匹配則返回一個匹配對象,失敗返回None。
str1 = "2018/12/20" import re re.match(r'\d*/',str1) >>> <_sre.SRE_Match object; span=(0, 5), match='2018/'>
(b) re.search( )
search 會匹配整個字符串。如匹配則返回一個匹配對象,失敗返回None。
re.search(r'/\d*/',str1) >>> <_sre.SRE_Match object; span=(4, 8), match='/12/'>
(c) re.findall( )
findall( )會匹配整個字符串,匹配則返回一個list列表,要么有值要么空
如果返回的值過多,可以使用 finditer( )來替代。
str1 = "www.baidu.com" import re re.finditer(r'w',str1) #會返回一個可迭代對象 >>> <callable_iterator at 0x5be230>
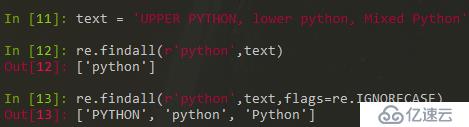
忽略大小寫進行匹配
4,字符串替換
簡單的替換可以使用 str.replace(old,new) 進行操作。
re.sub( )可以更加靈活處理。
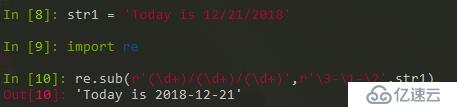
反斜杠數字,例如 \3 指向前面模式的捕獲組號。
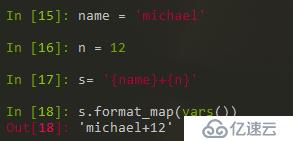
5,字符串中插入變量
使用 format 和 format_map( ) + vars( )來進行處理。
vars( )實現的是在變量域中找到所需的變量。
缺點是,變量缺失后,會直接報錯。如果變量未找到

可以使用類進行包裝。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





