溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Python中怎么抓取并存儲網頁數據,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
第一步:嘗試請求
首先進入b站首頁,點擊排行榜并復制鏈接
https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3
現在啟動Jupyter notebook,并運行以下代碼
import requests url = 'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3' res = requests.get('url') print(res.status_code) #200在上面的代碼中,我們完成了下面三件事
導入requests
使用get方法構造請求
使用status_code獲取網頁狀態碼
可以看到返回值是200,表示服務器正常響應,這意味著我們可以繼續進行。
第二步:解析頁面
在上一步我們通過requests向網站請求數據后,成功得到一個包含服務器資源的Response對象,現在我們可以使用.text來查看其內容

可以看到返回一個字符串,里面有我們需要的熱榜視頻數據,但是直接從字符串中提取內容是比較復雜且低效的,因此我們需要對其進行解析,將字符串轉換為網頁結構化數據,這樣可以很方便地查找HTML標簽以及其中的屬性和內容。
在Python中解析網頁的方法有很多,可以使用正則表達式,也可以使用BeautifulSoup、pyquery或lxml,本文將基于BeautifulSoup進行講解.
Beautiful Soup是一個可以從HTML或XML文件中提取數據的第三方庫.安裝也很簡單,使用pip install bs4安裝即可,下面讓我們用一個簡單的例子說明它是怎樣工作的
from bs4 import BeautifulSoup page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser') title = soup.title.text print(title) # 熱門視頻排行榜 - 嗶哩嗶哩 (゜-゜)つロ 干杯~-bilibili
在上面的代碼中,我們通過bs4中的BeautifulSoup類將上一步得到的html格式字符串轉換為一個BeautifulSoup對象,注意在使用時需要制定一個解析器,這里使用的是html.parser。
接著就可以獲取其中的某個結構化元素及其屬性,比如使用soup.title.text獲取頁面標題,同樣可以使用soup.body、soup.p等獲取任意需要的元素。
第三步:提取內容
在上面兩步中,我們分別使用requests向網頁請求數據并使用bs4解析頁面,現在來到最關鍵的步驟:如何從解析完的頁面中提取需要的內容。
在Beautiful Soup中,我們可以使用find/find_all來定位元素,但我更習慣使用CSS選擇器.select,因為可以像使用CSS選擇元素一樣向下訪問DOM樹。
現在我們用代碼講解如何從解析完的頁面中提取B站熱榜的數據,首先我們需要找到存儲數據的標簽,在榜單頁面按下F12并按照下圖指示找到
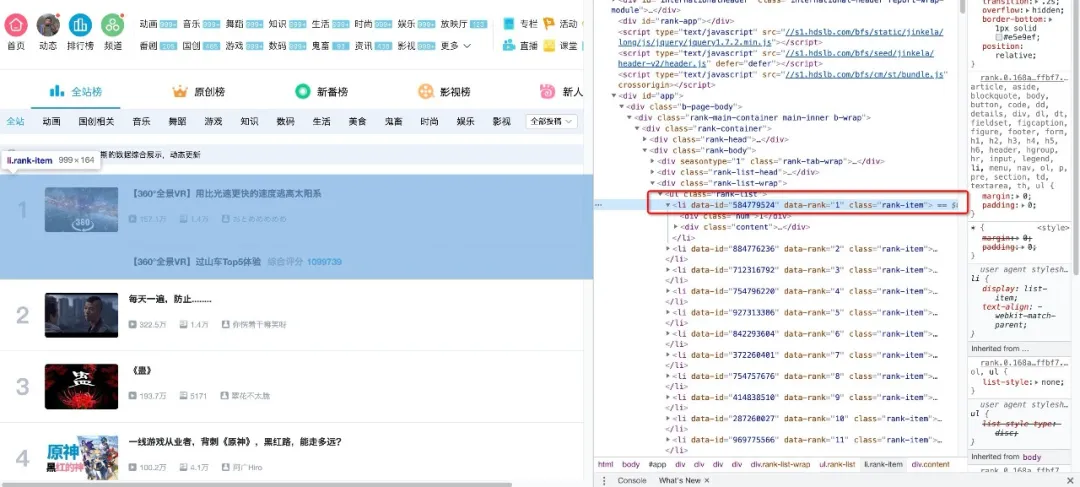
可以看到每一個視頻信息都被包在class="rank-item"的li標簽下,那么代碼就可以這樣寫
all_products = [] products = soup.select('li.rank-item') for product in products: rank = product.select('div.num')[0].text name = product.select('div.info > a')[0].text.strip() play = product.select('span.data-box')[0].text comment = product.select('span.data-box')[1].text up = product.select('span.data-box')[2].text url = product.select('div.info > a')[0].attrs['href'] all_products.append({ "視頻排名":rank, "視頻名": name, "播放量": play, "彈幕量": comment, "up主": up, "視頻鏈接": url })在上面的代碼中,我們先使用soup.select('li.rank-item'),此時返回一個list包含每一個視頻信息,接著遍歷每一個視頻信息,依舊使用CSS選擇器來提取我們要的字段信息,并以字典的形式存儲在開頭定義好的空列表中。
可以注意到我用了多種選擇方法提取去元素,這也是select方法的靈活之處,感興趣的讀者可以進一步自行研究。
第四步:存儲數據
通過前面三步,我們成功的使用requests+bs4從網站中提取出需要的數據,最后只需要將數據寫入Excel中保存即可。
如果你對pandas不熟悉的話,可以使用csv模塊寫入,需要注意的是設置好編碼encoding='utf-8-sig',否則會出現中文亂碼的問題
import csv keys = all_products[0].keys() with open('B站視頻熱榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file: dict_writer = csv.DictWriter(output_file, keys) dict_writer.writeheader() dict_writer.writerows(all_products)如果你熟悉pandas的話,更是可以輕松將字典轉換為DataFrame,一行代碼即可完成
import pandas as pd keys = all_products[0].keys() pd.DataFrame(all_products,columns=keys).to_csv('B站視頻熱榜TOP100.csv', encoding='utf-8-sig')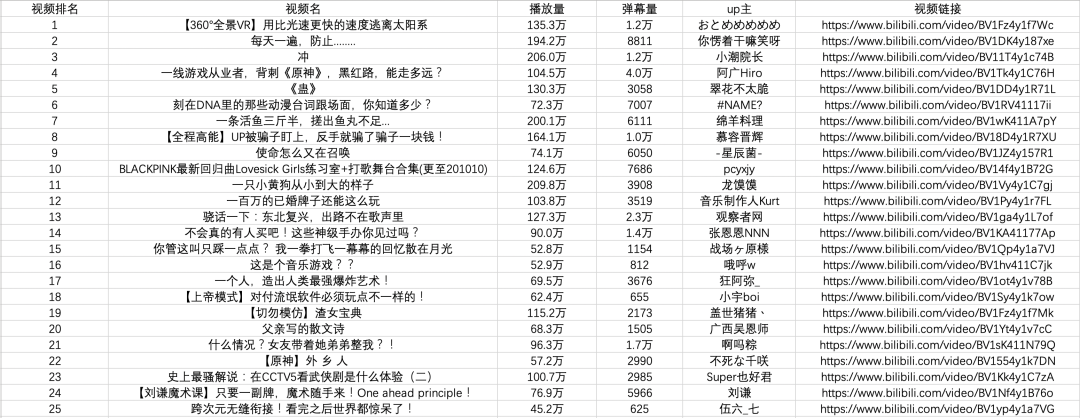
上述內容就是Python中怎么抓取并存儲網頁數據,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





