溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“為什么繼承Python內置類型會出問題”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“為什么繼承Python內置類型會出問題”吧!
1、內置類型有哪些?
在正式開始之前,我們首先要科普一下:哪些是 Python 的內置類型?
根據官方文檔的分類,內置類型(Built-in Types)主要包含如下內容:
詳細文檔:https://docs.python.org/3/library/stdtypes.html
其中,有大家熟知的數字類型、序列類型、文本類型、映射類型等等,當然還有我們之前介紹過的布爾類型、...對象 等等。
在這么多內容里,本文只關注那些作為可調用對象(callable)的內置類型,也就是跟內置函數(built-in function)在表面上相似的那些:int、str、list、tuple、range、set、dict……
這些類型(type)可以簡單理解成其它語言中的類(class),但是 Python 在此并沒有用習慣上的大駝峰命名法,因此容易讓人產生一些誤解。
在 Python 2.2 之后,這些內置類型可以被子類化(subclassing),也就是可以被繼承(inherit)。
2、內置類型的子類化
眾所周知,對于某個普通對象 x,Python 中求其長度需要用到公共的內置函數 len(x),它不像 Java 之類的面向對象語言,后者的對象一般擁有自己的 x.length() 方法。(PS:關于這兩種設計風格的分析,推薦閱讀 這篇文章)
現在,假設我們要定義一個列表類,希望它擁有自己的 length() 方法,同時保留普通列表該有的所有特性。
實驗性的代碼如下(僅作演示):
# 定義一個list的子類 class MyList(list): def length(self): return len(self)
我們令 MyList這個自定義類繼承 list,同時新定義一個 length() 方法。這樣一來,MyList 就擁有 append()、pop() 等等方法,同時還擁有 length() 方法。
# 添加兩個元素 ss = MyList() ss.append("Python") ss.append("貓") print(ss.length()) # 輸出:2前面提到的其它內置類型,也可以這樣作子類化,應該不難理解。
順便發散一下,內置類型的子類化有何好處/使用場景呢?
有一個很直觀的例子,當我們在自定義的類里面,需要頻繁用到一個列表對象時(給它添加/刪除元素、作為一個整體傳遞……),這時候如果我們的類繼承自 list,就可以直接寫 self.append()、self.pop(),或者將 self 作為一個對象傳遞,從而不用額外定義一個列表對象,在寫法上也會簡潔一些。
還有其它的好處/使用場景么?歡迎大家留言討論~~
3、內置類型子類化的“問題”
終于要進入本文的正式主題了:)
通常而言,在我們教科書式的認知中,子類中的方法會覆蓋父類的同名方法,也就是說,子類方法的查找優先級要高于父類方法。
下面看一個例子,父類 Cat,子類 PythonCat,都有一個 say() 方法,作用是說出當前對象的 inner_voice:
# Python貓是一只貓 class Cat(): def say(self): return self.inner_voice() def inner_voice(self): return "喵" class PythonCat(Cat): def inner_voice(self): return "喵喵"
當我們創建子類 PythonCat 的對象時,它的 say() 方法會優先取到自己定義出的 inner_voice() 方法,而不是 Cat 父類的 inner_voice() 方法:
my_cat = PythonCat() # 下面的結果符合預期 print(my_cat.inner_voice()) # 輸出:喵喵 print(my_cat.say()) # 輸出:喵喵
這是編程語言約定俗成的慣例,是一個基本原則,學過面向對象編程基礎的同學都應該知道。
然而,當 Python 在實現繼承時,似乎不完全會按照上述的規則運作。它分為兩種情況:
符合常識:對于用 Python 實現的類,它們會遵循“子類先于父類”的原則
違背常識:對于實際是用 C 實現的類(即str、list、dict等等這些內置類型),在顯式調用子類方法時,會遵循“子類先于父類”的原則;但是,**在存在隱式調用時,**它們似乎會遵循“父類先于子類”的原則,即通常的繼承規則會在此失效
對照 PythonCat 的例子,相當于說,直接調用 my_cat.inner_voice() 時,會得到正確的“喵喵”結果,但是在調用 my_cat.say() 時,則會得到超出預期的“喵”結果。
下面是《流暢的Python》中給出的例子(12.1章節):
class DoppelDict(dict): def __setitem__(self, key, value): super().__setitem__(key, [value] * 2) dd = DoppelDict(one=1) # {'one': 1} dd['two'] = 2 # {'one': 1, 'two': [2, 2]} dd.update(three=3) # {'three': 3, 'one': 1, 'two': [2, 2]}
在這個例子中,dd['two'] 會直接調用子類的__setitem__()方法,所以結果符合預期。如果其它測試也符合預期的話,最終結果會是{'three': [3, 3], 'one': [1, 1], 'two': [2, 2]}。
然而,初始化和 update() 直接調用的分別是從父類繼承的__init__()和__update__(),再由它們隱式地調用__setitem__()方法,此時卻并沒有調用子類的方法,而是調用了父類的方法,導致結果超出預期!
官方 Python 這種實現雙重規則的做法,有點違背大家的常識,如果不加以注意,搞不好就容易踩坑。
那么,為什么會出現這種例外的情況呢?
4、內置類型的方法的真面目
我們知道了內置類型不會隱式地調用子類覆蓋的方法,接著,就是Python貓的刨根問底時刻:為什么它不去調用呢?
《流暢的Python》書中沒有繼續追問,不過,我試著胡亂猜測一下(應該能從源碼中得到驗證):內置類型的方法都是用 C 語言實現的,事實上它們彼此之間并不存在著相互調用,所以就不存在調用時的查找優先級問題。
也就是說,前面的“__init__()和__update__()會隱式地調用__setitem__()方法”這種說法并不準確!
這幾個魔術方法其實是相互獨立的!__init__()有自己的 setitem 實現,并不會調用父類的__setitem__(),當然跟子類的__setitem__()就更沒有關系了。
從邏輯上理解,字典的__init__()方法中包含__setitem__()的功能,因此我們以為前者會調用后者,**這是慣性思維的體現,**然而實際的調用關系可能是這樣的:
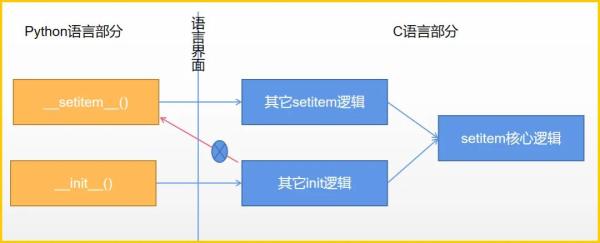
左側的方法打開語言界面之門進入右側的世界,在那里實現它的所有使命,并不會折返回原始界面查找下一步的指令(即不存在圖中的紅線路徑)。不折返的原因很簡單,即 C 語言間代碼調用效率更高,實現路徑更短,實現過程更簡單。
同理,dict 類型的 get() 方法與__getitem__()也不存在調用關系,如果子類只覆蓋了__getitem__()的話,當子類調用 get() 方法時,實際會使用到父類的 get() 方法。(PS:關于這一點,《流暢的Python》及 PyPy 文檔的描述都不準確,它們誤以為 get() 方法會調用__getitem__())
也就是說,Python 內置類型的方法本身不存在調用關系,盡管它們在底層 C 語言實現時,可能存在公共的邏輯或能被復用的方法。
我想到了“Python為什么”系列曾分析過的《Python 為什么能支持任意的真值判斷?》。在我們寫if xxx時,它似乎會隱式地調用__bool__()和__len__()魔術方法,然而實際上程序依據 POP_JUMP_IF_FALSE 指令,會直接進入純 C 代碼的邏輯,并不存在對這倆魔術方法的調用!
因此,在意識到 C 實現的特殊方法間相互獨立之后,我們再回頭看內置類型的子類化,就會有新的發現:
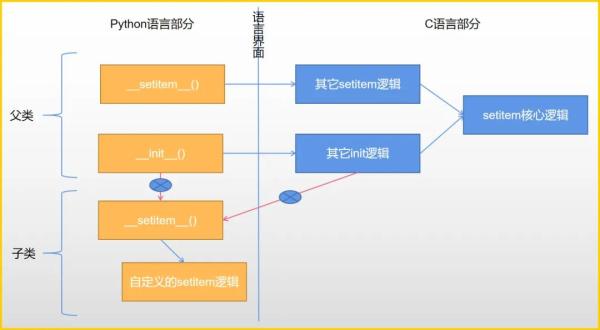
父類的__init__()魔術方法會打破語言界面實現自己的使命,然而它跟子類的__setitem__()并不存在通路,即圖中紅線路徑不可達。
特殊方法間各行其是,由此,我們會得出跟前文不同的結論:實際上 Python 嚴格遵循了“子類方法先于父類方法”繼承原則,并沒有破壞常識!
最后值得一提的是,__missing__()是一個特例。《流暢的Python》僅僅簡單而含糊地寫了一句,沒有過多展開。
經過初步實驗,我發現當子類定義了此方法時,get() 讀取不存在的 key 時,正常返回 None;但是 __getitem__() 和 dd['xxx'] 讀取不存在的 key 時,都會按子類定義的__missing__()進行處理。
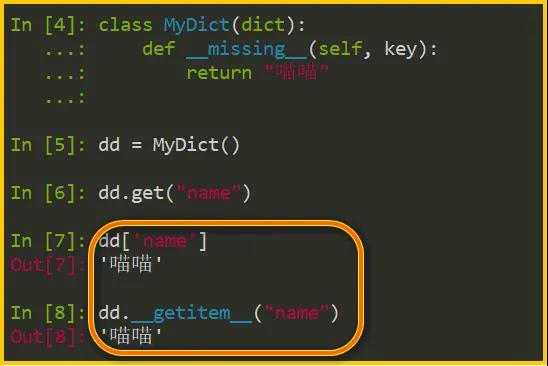
我還沒空深入分析,懇請知道答案的同學給我留言。
5、內置類型子類化的最佳實踐
綜上所述,內置類型子類化時并沒有出問題,只是由于我們沒有認清特殊方法(C 語言實現的方法)的真面目,才會導致結果偏差。
那么,這又召喚出了一個新的問題:如果非要繼承內置類型,最佳的實踐方式是什么呢?
首先,如果在繼承內置類型后,并不重寫(overwrite)它的特殊方法的話,子類化就不會有任何問題。
其次,如果繼承后要重寫特殊方法的話,記得要把所有希望改變的方法都重寫一遍,例如,如果想改變 get() 方法,就要重寫 get() 方法,如果想改變 __getitem__()方法,就要重寫它……
但是,如果我們只是想重寫某種邏輯(即 C 語言的部分),以便所有用到該邏輯的特殊方法都發生改變的話,例如重寫__setitem__()的邏輯,同時令初始化和update()等操作跟著改變,那么該怎么辦呢?
我們已知特殊方法間不存在復用,也就是說單純定義新的__setitem__()是不夠的,那么,怎么才能對多個方法同時產生影響呢?
PyPy 這個非官方的 Python 版本發現了這個問題,它的做法是令內置類型的特殊方法發生調用,建立它們之間的連接通路。
官方 Python 當然也意識到了這么問題,不過它并沒有改變內置類型的特性,而是提供出了新的方案:UserString、UserList、UserDict……

除了名字不一樣,基本可以認為它們等同于內置類型。
這些類的基本邏輯是用 Python 實現的,相當于是把前文 C 語言界面的某些邏輯搬到了 Python 界面,在左側建立起調用鏈,如此一來,就解決了某些特殊方法的復用問題。
對照前文的例子,采用新的繼承方式后,結果就符合預期了:
from collections import UserDict class DoppelDict(UserDict): def __setitem__(self, key, value): super().__setitem__(key, [value] * 2) dd = DoppelDict(one=1) # {'one': [1, 1]} dd['two'] = 2 # {'one': [1, 1], 'two': [2, 2]} dd.update(three=3) # {'one': [1, 1], 'two': [2, 2], 'three': [3, 3]}顯然,如果要繼承 str/list/dict 的話,最佳的實踐就是繼承collections庫提供的那幾個類。
感謝各位的閱讀,以上就是“為什么繼承Python內置類型會出問題”的內容了,經過本文的學習后,相信大家對為什么繼承Python內置類型會出問題這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





