溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹如何讀懂開源日志管理方案ELK和EFK的區別,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
前言
主流的 ELK (Elasticsearch, Logstash, Kibana) 目前已經轉變為 EFK (Elasticsearch, Filebeat or Fluentd, Kibana) 比較重,對于容器云的日志方案業內也普遍推薦采用 Fluentd,我們一起來看下從 ELK 到 EFK 發生了哪些變化,與此同時我也推薦大家了解下 Grafana Loki
ELK 和 EFK 概述
隨著現在各種軟件系統的復雜度越來越高,特別是部署到云上之后,再想登錄各個節點上查看各個模塊的 log,基本是不可行了。因為不僅效率低下,而且有時由于安全性,不可能讓工程師直接訪問各個物理節點。而且現在大規模的軟件系統基本都采用集群的部署方式,意味著對每個 service,會啟動多個完全一樣的 POD 對外提供服務,每個 container 都會產生自己的 log,僅從產生的 log 來看,你根本不知道是哪個 POD 產生的,這樣對查看分布式的日志更加困難。
所以在云時代,需要一個收集并分析 log 的解決方案。首先需要將分布在各個角落的 log 收集到一個集中的地方,方便查看。收集了之后,還可以進行各種統計分析,甚至用流行的大數據或 maching learning 的方法進行分析。當然,對于傳統的軟件部署方式,也需要這樣的 log 的解決方案,不過本文主要從云的角度來介紹。
ELK 就是這樣的解決方案,而且基本就是事實上的標準。ELK 是三個開源項目的首字母縮寫,如下:
E: Elasticsearch L: Logstash K: Kibana
Logstash 的主要作用是收集分布在各處的 log 并進行處理;Elasticsearch 則是一個集中存儲 log 的地方,更重要的是它是一個全文檢索以及分析的引擎,它能讓用戶以近乎實時的方式來查看、分析海量的數據。Kibana 則是為 Elasticsearch 開發的前端 GUI,讓用戶可以很方便的以圖形化的接口查詢 Elasticsearch 中存儲的數據,同時也提供了各種分析的模塊,比如構建 dashboard 的功能。
我個人認為將 ELK 中的 L 理解成 Logging Agent 更合適。Elasticsearch 和 Kibana 基本就是存儲、檢索和分析 log 的標準方案,而 Logstash 則并不是唯一的收集 log 的方案,Fluentd 和 Filebeats 也能用于收集 log。所以現在網上有 ELK,EFK 之類的縮寫。
一般采用的架構如下圖所示。通常一個小型的 cluster 有三個節點,在這三個節點上可能會運行幾十個甚至上百個容器。而我們只需要在每個節點上啟動一個 logging agent 的實例(在 kubernetes 中就是 DaemonSet 的概念)即可。
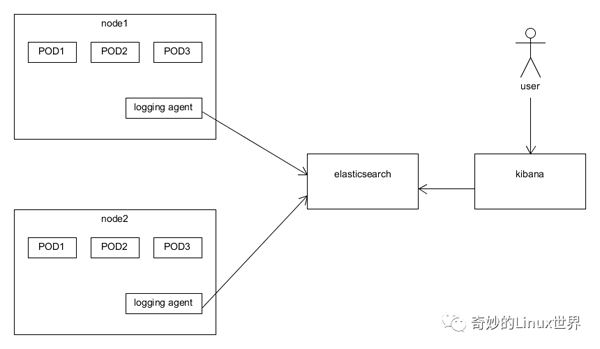
Filebeats、Logstash、Fluentd 三者的區別和聯系
這里有必要對 Filebeats、Logstash 和 Fluentd 三者之間的聯系和區別做一個簡要的說明。Filebeats 是一個輕量級的收集本地 log 數據的方案,官方對 Filebeats 的說明如下。可以看出 Filebeats 功能比較單一,它僅僅只能收集本地的 log,但并不能對收集到的 Log 做什么處理,所以通常 Filebeats 通常需要將收集到的 log 發送到 Logstash 做進一步的處理。
Filebeat is a log data shipper for local files. Installed as an agent on your servers, Filebeat monitors the log directories or specific log files, tails the files, and forwards them either to Elasticsearch or Logstash for indexing
Logstash 和 Fluentd 都具有收集并處理 log 的能力,網上有很多關于二者的對比,提供一個寫得比較好的文章鏈接如下。功能上二者旗鼓相當,但 Logstash 消耗更多的 memory,對此 Logstash 的解決方案是使用 Filebeats 從各個葉子節點上收集 log,當然 Fluentd 也有對應的 Fluent Bit。
https://logz.io/blog/fluentd-Logstash/
另外一個重要的區別是 Fluentd 抽象性做得更好,對用戶屏蔽了底層細節的繁瑣。作者的原話如下:
Fluentd’s approach is more declarative whereas Logstash’s method is procedural. For programmers trained in procedural programming, Logstash’s configuration can be easier to get started. On the other hand, Fluentd’s tag-based routing allows complex routing to be expressed cleanly.
雖然作者說是要中立的對二者(Logstash 和 Fluentd)進行對比,但實際上偏向性很明顯了:)。本文也主要基于 Fluentd 進行介紹,不過總體思路都是相通的。
額外說一點,Filebeats、Logstash、Elasticsearch 和 Kibana 是屬于同一家公司的開源項目,官方文檔如下:
https://www.elastic.co/guide/index.html
Fluentd 則是另一家公司的開源項目,官方文檔如下:
https://docs.fluentd.org
關于 ELK
ELK 簡介
ELK 是 Elastic 公司提供的一套完整的日志收集以及展示的解決方案,是三個產品的首字母縮寫,分別是 Elasticsearch、Logstash 和 Kibana。

Elasticsearch 是實時全文搜索和分析引擎,提供搜集、分析、存儲數據三大功能
Logstash 是一個用來搜集、分析、過濾日志的工具
Kibana 是一個基于 Web 的圖形界面,用于搜索、分析和可視化存儲在 Elasticsearch 指標中的日志數據
ELK 日志處理流程

上圖展示了在 Docker 環境下,一個典型的 ELK 方案下的日志收集處理流程:
Logstash 從各個 Docker 容器中提取日志信息
Logstash 將日志轉發到 Elasticsearch 進行索引和保存
Kibana 負責分析和可視化日志信息
由于 Logstash 在數據收集上并不出色,而且作為 Agent,其性能并不達標。基于此,Elastic 發布了 beats 系列輕量級采集組件。
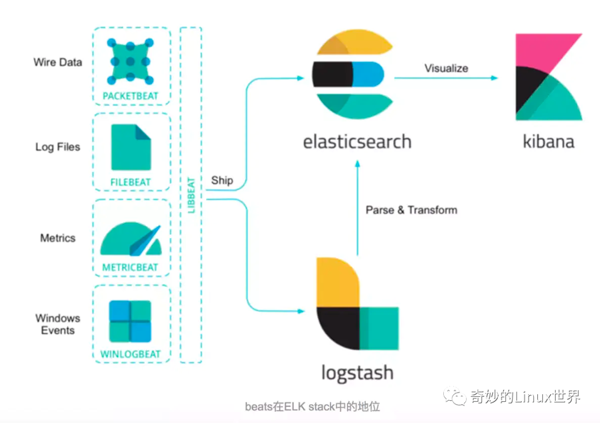
這里我們要實踐的 Beat 組件是 Filebeat,Filebeat 是構建于 beats 之上的,應用于日志收集場景的實現,用來替代 Logstash Forwarder 的下一代 Logstash 收集器,是為了更快速穩定輕量低耗地進行收集工作,它可以很方便地與 Logstash 還有直接與 Elasticsearch 進行對接。
本次實驗直接使用 Filebeat 作為 Agent,它會收集我們在第一篇《Docker logs & logging driver》中介紹的 json-file 的 log 文件中的記錄變動,并直接將日志發給 Elasticsearch 進行索引和保存,其處理流程變為下圖,你也可以認為它可以稱作 EFK。

ELK 套件的安裝
本次實驗我們采用 Docker 方式部署一個最小規模的 ELK 運行環境,當然,實際環境中我們或許需要考慮高可用和負載均衡。
首先拉取一下 sebp/elk 這個集成鏡像,這里選擇的 tag 版本是 latest:
docker pull sebp/elk:latest
注:由于其包含了整個 ELK 方案,所以需要耐心等待一會。
通過以下命令使用 sebp/elk 這個集成鏡像啟動運行 ELK:
docker run -it -d --name elk \ -p 5601:5601 \ -p 9200:9200 \ -p 5044:5044 \ sebp/elk:latest
運行完成之后就可以先訪問一下 http://192.168.4.31:5601 看看 Kibana 的效果:
當然,目前沒有任何可以顯示的 ES 的索引和數據,再訪問一下 http://192.168.4.31:9200 看看 Elasticsearch 的 API 接口是否可用:

如果啟動過程中發現一些錯誤,導致 ELK 容器無法啟動,可以參考《ElasticSearch 啟動常見錯誤》 一文。如果你的主機內存低于 4G,建議增加配置設置 ES 內存使用大小,以免啟動不了。例如下面增加的配置,限制 ES 內存使用最大為 1G:
docker run -it -d --name elk \ -p 5601:5601 \ -p 9200:9200 \ -p 5044:5044 \ -e ES_MIN_MEM=512m \ -e ES_MAX_MEM=1024m \ sebp/elk:latest
若啟動容器的時候提示 max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] 請參考
# 編輯 sysctl.con vi /etc/sysctl.conf # 添加下面配置 vm.max_map_count=655360 # 然后執行命令 sysctl -p
Filebeat 配置
安裝 Filebeat
Download Filebeat
這里我們通過 rpm 的方式下載 Filebeat,注意這里下載和我們 ELK 對應的版本(ELK 是 7.6.1,這里也是下載 7.6.1,避免出現錯誤):
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.6.1-x86_64.rpm rpm -ivh filebeat-7.6.1-x86_64.rpm
配置 Filebeat
這里我們需要告訴 Filebeat 要監控哪些日志文件 及 將日志發送到哪里去,因此我們需要修改一下 Filebeat 的配置:
nano /etc/filebeat/filebeat.yml
要修改的內容為:
(1)監控哪些日志
filebeat.inputs: # Each - is an input. Most options can be set at the input level, so # you can use different inputs for various configurations. # Below are the input specific configurations. - type: log # Change to true to enable this input configuration. enabled: true # Paths that should be crawled and fetched. Glob based paths. paths: - /var/lib/docker/containers/*/*.log
這里指定 paths:/var/lib/docker/containers/*/*.log,另外需要注意的是將 enabled 設為 true。
(2)將日志發到哪里
#-------------------------- Elasticsearch output ------------------------------ output.elasticsearch: # Array of hosts to connect to. hosts: ["192.168.4.31:9200"] # Optional protocol and basic auth credentials. #protocol: "https" #username: "elastic" #password: "changeme"
這里指定直接發送到 Elasticsearch,配置一下 ES 的接口地址即可。
注意:如果要發到 Logstash,請使用后面這段配置,將其取消注釋進行相關配置即可:
#----------------------------- Logstash output -------------------------------- #output.Logstash: # The Logstash hosts #hosts: ["localhost:9200"] # Optional SSL. By default is off. # List of root certificates for HTTPS server verifications #ssl.certificate_authorities: ["/etc/pki/root/ca.pem"] # Certificate for SSL client authentication #ssl.certificate: "/etc/pki/client/cert.pem" # Client Certificate Key #ssl.key: "/etc/pki/client/cert.key"
啟動 Filebeat
由于 Filebeat 在安裝時已經注冊為 systemd 的服務,所以只需要直接啟動即可:
systemctl start filebeat
設置開機啟動:
systemctl enable filebeat
檢查 Filebeat 啟動狀態:
systemctl status filebeat
上述操作總結為腳本為:
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.6.1-x86_64.rpm rpm -ivh filebeat-7.6.1-x86_64.rpm echo "please input elk host_ip" read host_ip sed -i "s/ enabled: false/ enabled: true/g" /etc/filebeat/filebeat.yml sed -i "s/\/var\/log\/\*.log/\/var\/lib\/docker\/containers\/\*\/\*.log/g" /etc/filebeat/filebeat.yml sed -i "s/localhost:9200/${host_ip}:9200/g" /etc/filebeat/filebeat.yml systemctl start filebeat systemctl enable filebeat systemctl status filebeatKibana 配置
接下來我們就要告訴 Kibana,要查詢和分析 Elasticsearch 中的哪些日志,因此需要配置一個 Index Pattern。從 Filebeat 中我們知道 Index 是 filebeat-timestamp 這種格式,因此這里我們定義 Index Pattern 為 filebeat-*
點擊 Next Step,這里我們選擇 Time Filter field name 為 @timestamp:
單擊 Create index pattern 按鈕,即可完成配置。
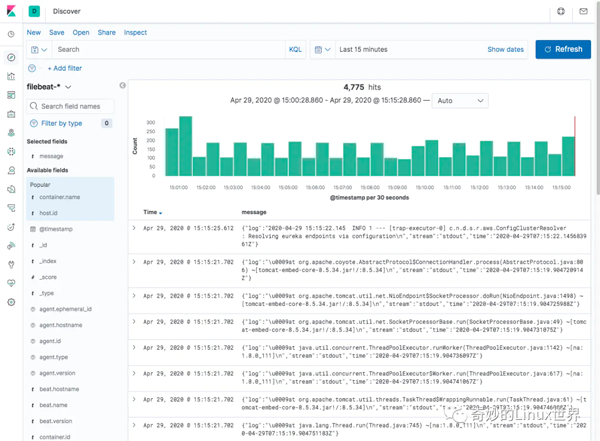
這時我們單擊 Kibana 左側的 Discover 菜單,即可看到容器的日志信息啦:
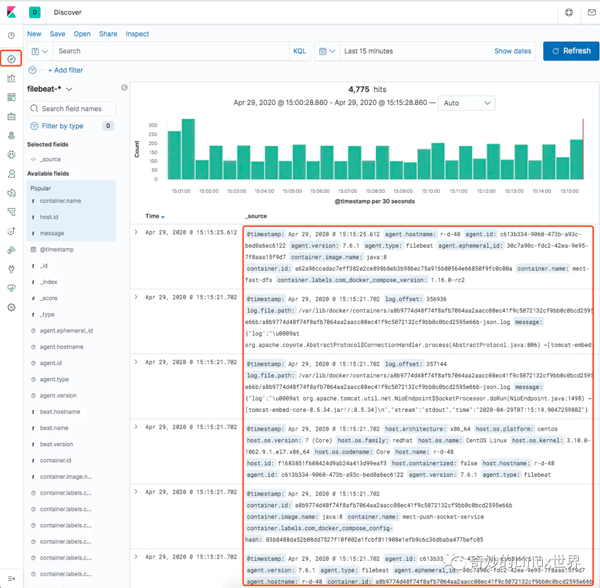
仔細看看細節,我們關注一下 message 字段:

可以看到,我們重點要關注的是 message,因此我們也可以篩選一下只看這個字段的信息:
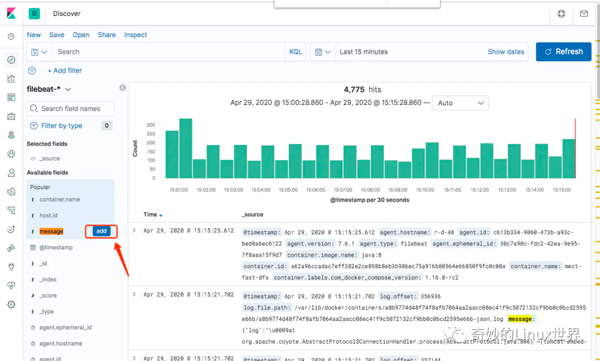
這里只是樸素的展示了導入 ELK 的日志信息,實際上 ELK 還有很多很豐富的玩法,例如分析聚合、炫酷 Dashboard 等等。筆者在這里也是初步使用,就介紹到這里啦。
Fluentd 引入
關于 Fluentd
前面我們采用的是 Filebeat 收集 Docker 的日志信息,基于 Docker 默認的 json-file 這個 logging driver,這里我們改用 Fluentd 這個開源項目來替換 json-file 收集容器的日志。
Fluentd 是一個開源的數據收集器,專為處理數據流設計,使用 JSON 作為數據格式。它采用了插件式的架構,具有高可擴展性高可用性,同時還實現了高可靠的信息轉發。Fluentd 也是云原生基金會 (CNCF) 的成員項目之一,遵循 Apache 2 License 協議,其 GitHub 地址為:https://github.com/fluent/fluentd/。Fluentd 與 Logstash 相比,比占用內存更少、社區更活躍,兩者的對比可以參考這篇文章《Fluentd vs Logstash》。
因此,整個日志收集與處理流程變為下圖,我們用 Filebeat 將 Fluentd 收集到的日志轉發給 Elasticsearch。
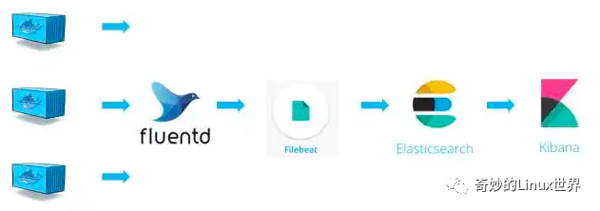
當然,我們也可以使用 Fluentd 的插件(fluent-plugin-elasticsearch)直接將日志發送給 Elasticsearch,可以根據自己的需要替換掉 Filebeat,從而形成 Fluentd => Elasticsearch => Kibana 的架構,也稱作 EFK。
運行 Fluentd
這里我們通過容器來運行一個 Fluentd 采集器:
docker run -it -d --name fluentd \ -p 24224:24224 \ -p 24224:24224/udp \ -v /etc/fluentd/log:/fluentd/log \ fluent/fluentd:latest
默認 Fluentd 會使用 24224 端口,其日志會收集在我們映射的路徑下。
此外,我們還需要修改 Filebeat 的配置文件,將 / etc/fluentd/log 加入監控目錄下:
#=========================== Filebeat inputs ============================= filebeat.inputs: # Each - is an input. Most options can be set at the input level, so # you can use different inputs for various configurations. # Below are the input specific configurations. - type: log # Change to true to enable this input configuration. enabled: true # Paths that should be crawled and fetched. Glob based paths. paths: - /etc/fluentd/log/*.log
添加監控配置之后,需要重新 restart 一下 filebeat:
systemctl restart filebeat
運行測試容器
為了驗證效果,這里我們 Run 兩個容器,并分別制定其 log-dirver 為 fluentd:
docker run -d \ --log-driver=fluentd \ --log-opt fluentd-address=localhost:24224 \ --log-opt tag="test-docker-A" \ busybox sh -c 'while true; do echo "This is a log message from container A"; sleep 10; done;' docker run -d \ --log-driver=fluentd \ --log-opt fluentd-address=localhost:24224 \ --log-opt tag="test-docker-B" \ busybox sh -c 'while true; do echo "This is a log message from container B"; sleep 10; done;'
這里通過指定容器的 log-driver,以及為每個容器設立了 tag,方便我們后面驗證查看日志。
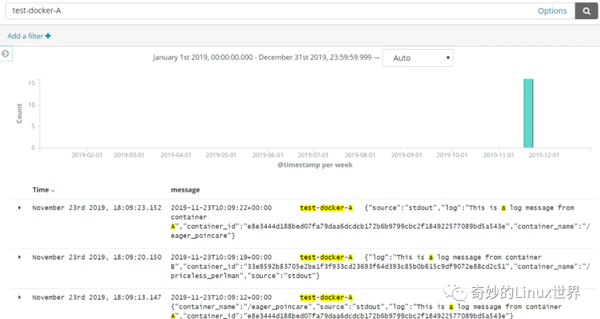
驗證 EFK 效果
這時再次進入 Kibana 中查看日志信息,便可以通過剛剛設置的 tag 信息篩選到剛剛添加的容器的日志信息了:
模擬日志生成壓力測試工具
https://github.com/elastic/rally
https://pypi.org/project/log-generator/
https://github.com/mingrammer/flog
本文從 ELK 的基本組成入手,介紹了 ELK 的基本處理流程,以及從 0 開始搭建了一個 ELK 環境,演示了基于 Filebeat 收集容器日志信息的案例。然后,通過引入 Fluentd 這個開源數據收集器,演示了如何基于 EFK 的日志收集案例。
關于如何讀懂開源日志管理方案ELK和EFK的區別就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





