溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關Linux實時補丁是否即將合并進Linux 5.3,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
Linux PREEMPT_RT 補丁終于要合并進Linux 5.3了。意味著開發了十幾年的實時補丁將得以和主線Linux 協同發展。
所謂實時,就是一個特定任務的執行時間必須是確定的,可預測的,并且在任何情況下都能保證任務的時限(最大執行時間限制)。實時又分軟實時和硬實時,所謂軟實時,就是對任務執行時限的要求不那么嚴苛,即使在一些情況下不能滿足時限要求,也不會對系統本身產生致命影響,例如,媒體播放系統就是軟實時的,它需要系統能夠在1秒鐘播放24幀,但是即使在一些嚴重負載的情況下不能在1秒鐘內處理24幀,也是可以接受的。所謂硬實時,就是對任務的執行時限的要求非常嚴格,無論在什么情況下,任務的執行實現必須得到絕對保證,否則將產生災難性后果,例如,飛行器自動駕駛和導航系統就是硬實時的,它必須要求系統能在限定的時限內完成特定的任務,否則將導致重大事故,如碰撞或爆炸等。
那么,如何判斷一個系統是否是實時的呢?主要有以下兩個指標:
1. 中斷延遲
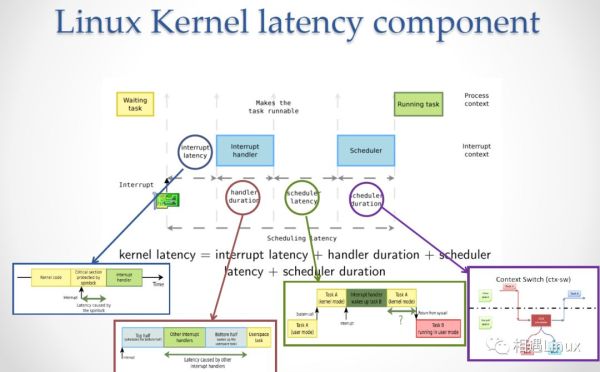
中斷延遲就是從一個外部事件發生到相應的中斷處理函數的第一條指令開始執行所需要的時間。很多實時任務是靠中斷驅動的,而且中斷事件必須在限定的時限內處理,否則將產生災難性后果,因此中斷延遲對于實時系統來說,是一個非常重要的指標。
2. 搶占延遲
有時也稱調度延遲,搶占延遲就是從一個外部事件發生到相應的處理該事件的任務的第一條命令開始執行的時間。大多數實時系統都是處理一些周期性的或非周期性的重復事件,事件產生的頻度就確定了任務的執行時限,因此每次事件發生時,相應的處理任務必須及時響應處理,否則將無法滿足時限。搶占延遲就反映了系統的響應及時程度。
如果以上兩個指標是確定的,可預測的,那么就可以說系統是實時的。
對系統實時性的影響因素既有硬件方面的,也有軟件方面的。
現代的高性能的硬件都使用了cache技術來彌補CPU和內存間的性能差距,但是cache卻嚴重地影響著實時性,指令或數據在cache中的執行時間和指令或數據不在cache中的執行時間差距是非常巨大的,可能差幾個數量級,因此為了保證執行時間的確定性和可預測性,來滿足實時需要,一些系統就失效了cache或使用沒有cache的CPU。
另一個硬件方面的影響因素就是虛存管理,對于多用戶多任務的操作系統,它確實非常有用,它使得系統能夠執行比物理內存更大的任務,而且各任務互不影響,完全有自己的獨立的地址空間。但是虛存管理的缺頁機制嚴重地影響了任務執行時間的可預測性和確定性,任務執行時使用缺頁機制調入訪問的指令或數據和被執行的指令和數據已經在內存中需要的執行時間的差距是非常大的。因此一些實時系統就不使用虛存技術,例如 Wind River的VxWorks。
在軟件方面,影響因素包括關中斷、不可搶占、一些O(n)的算法。
前面已經提到,中斷延遲是衡量系統實時性的一個重要指標。關中斷就導致了中斷無法被響應,增加了中斷延遲。
前面提到的搶占延遲也是衡量系統實時性的重要指標。如果發生實時事件時系統是不可搶占的,搶占延遲就會增加。
Linux在設計之初沒有對實時性進行任何考慮,因此非實時性絕非偶然。Linus考慮的是資源共享,吞吐率最大化。但是隨著Linux的快速發展,它的應用已經遠遠超出了Linus自己的想象。Linux的開放性已經對很多種架構的支持使得它在嵌入式系統中得到了廣泛的應用,但是許多嵌入式系統的實時性要求使得Linux在嵌入式領域的應用受到了一定的障礙,因此人們要求Linux需要實時性的呼聲越來越高。
Linux的開放性和低成本是實時Linux發展的優勢,越來越多的研究機構和商業團體開展了實時Linux的研究與開發,其中最著名的就是FSMLab的Rtlinux和TimeSys Linux。還有一個就是Ingo's RT patch。
標準Linux有幾個機制嚴重地影響了實時性。
1.內核不可搶占
在Linux 2.4和以前的版本,內核是不可搶占的,也就是說,如果當前任務運行在內核態,即使當前有更緊急的任務需要運行,當前任務也不能被搶占。因此那個緊急任務必須等到當前任務執行完內核態的操作返回用戶態后或當前任務因需要等待某些條件滿足而主動讓出CPU才能被考慮執行,這很明顯嚴重影響搶占延遲。
在Linux 2.6中,內核已經可以搶占,因而實時性得到了加強。但是內核中仍有大量的不可搶占區域, 如由自旋鎖 (spinlock)保護的臨界區,以及一些顯式使用preempt_disable失效搶占的臨界區。
2.中斷關閉
Linux在一些同步操作中使用了中斷關閉指令,中斷關閉將增大中斷延遲,降低系統的實時性。
3.自旋鎖(spinlock)
自旋鎖是在可搶占內核和SMP情況下對共享資源的一種同步機制,一般地一個任務對共享資源的訪問是非常短暫的,如果兩個任務競爭一個共享的資源時,沒有得到資源的任務將自旋以等待另一個任務使用完該共享資源。這種鎖機制是非常高效的,但是在保持自旋鎖期間將失效搶占,這意味著搶占延遲將增加。在內核中,自旋鎖的使用非常普遍,有的甚至對整個一個數組或鏈表的遍歷過程都使用自旋鎖。因此搶占延遲非常不確定。
4.中斷總是最高優先級的
在Linux中,中斷(包括軟中斷)是最高優先級的,不論在任何時刻,只要產生中斷事件,內核將立即執行相應的中斷處理函數以及軟中斷,等到所有掛起的中斷和軟中斷處理完畢有才執行正常的任務。因此在標準的Linux系統上,實時任務根本不可能得到實時性保證。例如,假設在一個標準Linux系統上運行了一個實時任務(即使用了SCHED_FIFO調度策略),但是該系統有非常繁重的網絡負載和I/O負載,那么系統可能一直處在中斷處理狀態而沒有機會運行任何任務,這樣實時任務將永遠無法運行,搶占延遲將是無窮大。因此,如果這種機制不改,實時Linux將永遠無法實現。
5.調度算法和調度點
即使內核是可搶占的,也不是在任何地方可以發生調度,例如在中斷上下文,一個中斷處理函數可能喚醒了某一高優先級進程,但是該進程并不能立即運行,因為在中斷上下文不能發生調度,中斷處理完了之后內核還要執行掛起的軟中斷,如果之前發生中斷的時候是在spin_lock臨界區,還有等待執行完臨界區的代碼,等它們全部處理完之后才有機會調度剛才喚醒的進程。
Ingo Molnar 的實時補丁是完全開源的,它采用的實時實現技術完全類似于Timesys Linux,而且中斷線程化的代碼是基于TimeSys Linux的中斷線程化代碼的。這些實時實現技術包括:中斷線程化(包括IRQ和softirq)、用Mutex取代spinlock、優先級繼承和死鎖檢測、等待隊列優先級化等。
該實時實現包含了以前的VP補丁(在內核郵件列表這么稱呼,即Voluntary Preemption),VP補丁由針對2.4內核的低延遲補丁(low latency patch)演進而來,它使用兩種方法來實現低延遲:
一種就是鎖分解,即把大循環中保持的鎖分解為每一輪循環中都獲得鎖和釋放鎖,典型的代碼結構示例如下:鎖分解前:
spin_lock(&x_lock); for (…) { some operations; … } spin_unlock(&x_lock);鎖分解后:
for (…) { spin_lock(&x_lock); some operations; … spin_unlock(&x_lock); }另一種是增加搶占點,即自愿被搶占,下面是一個鼠標驅動的例子:
未增加搶占點以前在文件driver/char/tty_io.c中的一段代碼:
/* Do the write .. */ for (;;) { size_t size = count; if (size > chunk) size = chunk; ret = -EFAULT; if (copy_from_user(tty->write_buf, buf, size)) break; lock_kernel(); ret = write(tty, file, tty->write_buf, size); unlock_kernel(); if (ret <= 0) break; written += ret; buf += ret; count -= ret; if (!count) break; ret = -ERESTARTSYS; if (signal_pending(current)) break; }增加搶占點之后:
/* Do the write .. */ for (;;) { size_t size = count; if (size > chunk) size = chunk; ret = -EFAULT; if (copy_from_user(tty->write_buf, buf, size)) break; lock_kernel(); ret = write(tty, file, tty->write_buf, size); unlock_kernel(); if (ret <= 0) break; written += ret; buf += ret; count -= ret; if (!count) break; ret = -ERESTARTSYS; if (signal_pending(current)) break; cond_resched(); }語句cond_resched()將判斷是否有進程需要搶占當前進程,如果是將立即發生調度,這就是增加的強占點。
為了能并入主流內核,Ingo Molnar的實時補丁也采用了非常靈活的策略,它支持四種搶占模式:
1.No Forced Preemption (Server),這種模式等同于沒有使能搶占選項的標準內核,主要適用于科學計算等服務器環境。
2.Voluntary Kernel Preemption (Desktop),這種模式使能了自愿搶占,但仍然失效搶占內核選項,它通過增加搶占點縮減了搶占延遲,因此適用于一些需要較好的響應性的環境,如桌面環境,當然這種好的響應性是以犧牲一些吞吐率為代價的。
3.Preemptible Kernel (Low-Latency Desktop),這種模式既包含了自愿搶占,又使能了可搶占內核選項,因此有很好的響應延遲,實際上在一定程度上已經達到了軟實時性。它主要適用于桌面和一些嵌入式系統,但是吞吐率比模式2更低。
4.Complete Preemption (Real-Time),這種模式使能了所有實時功能,因此完全能夠滿足軟實時需求,它適用于延遲要求為100微秒或稍低的實時系統。
實現實時是以犧牲系統的吞吐率為代價的,因此實時性越好,系統吞吐率就越低。
它自2004年10月發布以來一直更新很頻繁,幾乎每天都有新版本發布中。
中斷線程化是實現Linux實時性的一個重要步驟,在Linux標準內核中,中斷是最高優先級的執行單元,不管內核當時處理什么,只要有中斷事件,系統將立即響應該事件并執行相應的中斷處理代碼,除非當時中斷關閉(即使用local_irq_disable失效了IRQ)。因此,如果系統有嚴重的網絡或I/O負載,中斷將非常頻繁,實時任務將很難有機會運行,也就是說,毫無實時性可言。中斷線程化之后,中斷將作為內核線程運行而且賦予不同的實時優先級,實時任務可以有比中斷線程更高的優先級,這樣,實時任務就可以作為最高優先級的執行單元來運行,即使在嚴重負載下仍有實時性保證。
中斷線程化的另一個重要原因是spinlock被mutex取代。中斷處理代碼中大量地使用了spinlock,當spinlock被mutex取代之后,中斷處理代碼就有可能因為得不到鎖而需要被掛到等待隊列上,但是只有可調度的進程才可以這么做,如果中斷處理代碼仍然使用原來的spinlock,則spinlock取代mutex的努力將大打折扣,因此為了滿足這一要求,中斷必須被線程化,包括IRQ和softirq。
在Ingo Molnar的實時補丁中,中斷線程化的實現方法是:
對于IRQ,在內核初始化階段init(該函數在內核源碼樹的文件init/main.c中定義)調用init_hardirqs(該函數在內核源碼樹的文件kernel/irq/manage.c中定義)來為每一個IRQ創建一個內核線程,IRQ號為0的中斷賦予實時優先級49,IRQ號為1的賦予實時優先級48,依次類推直到25,因此任何IRQ線程的最低實時優先級為25。原來的 do_IRQ 被分解成兩部分,架構相關的放在類似于arch/*/kernel/irq.c的文件中,名稱仍然為do_IRQ,而架構獨立的部分被放在IRQ子系統的位置kernel/irq/handle.c中,名稱為__do_IRQ。當發生中斷時,CPU將執行do_IRQ來處理相應的中斷,do_IRQ將做了必要的架構相關的處理后調用__do_IRQ。函數__do_IRQ將判斷該中斷是否已經被線程化(如果中斷描述符的狀態字段不包含SA_NODELAY標志說明中斷被線程化了),如果是將喚醒相應的處理線程,否則將直接調用handle_IRQ_event(在IRQ子系統位置的kernel/irq/handle.c文件中)來處理。對于已經線程化的情況,中斷處理線程被喚醒并開始運行后,將調用do_hardirq(在源碼樹的IRQ子系統位置的文件kernel/irq/manage.c中定義)來處理相應的中斷,該函數將判斷是否有中斷需要被處理(中斷描述符的狀態標志IRQ_INPROGRESS),如果有就調用handle_IRQ_event來處理。handle_IRQ_event將直接調用相應的中斷處理句柄來完成中斷處理。
如果某個中斷需要被實時處理,它可以用SA_NODELAY標志來聲明自己非線程化,例如:
系統的時鐘中斷就是,因為它被用來維護系統時間以及定時器等,所以不應當被線程化。
static struct irqaction irq0 = { timer_interrupt, SA_INTERRUPT | SA_NODELAY, CPU_MASK_NONE, "timer", NULL, NULL};這是在靜態聲明時指定不要線程化,也可以在調用request_irq時指定,如:
static struct irqaction irq0 = { timer_interrupt, SA_INTERRUPT | SA_NODELAY, CPU_MASK_NONE, "timer", NULL, NULL};對于softirq,標準Linux內核已經使用內核線程的方式來處理,只是Ingo Molnar的實時補丁做了修改使其易于被搶占,改進了實時性,具體的修改包括:
把ksoftirqd的優先級設置為nice值為-10,即它的優先級高于普通的用戶態進程和內核態線程,但它不是實時線程,因此這樣一來softirq對實時性的影響將顯著減小。
在處理軟中斷期間,搶占是使能的,這使得實時性更進一步地增強。
在處理軟中斷的函數___do_softirq中,每次處理完一個待處理的軟中斷后,都將調用cond_resched_all(),這顯著地增加了調度點數,提高了整個系統的實時性。
增加了兩個函數_do_softirq和___do_softirq,其中___do_softirq就是原來的__do_softirq,只是增加了調度點。__do_softirq則是對___do_softirq的包裝,_do_softirq是對do_softirq的替代,但保留do_softirq用于一些特殊需要。
spinlock是一個高效的共享資源同步機制,在SMP(對稱多處理器Symmetric Multiple Proocessors)的情況下,它用于保護共享資源,如全局的數據結構或一個只能獨占的硬件資源。但是spinlock保持期間將使搶占失效,用spinlock保護的區域稱為臨界區(Critical Section),在內核中大量地使用了spinlock,有大量的臨界區存在,因此它們將嚴重地影響著系統的實時性。Ingo Molnar的實時補丁使用mutex來替換spinlock,它的意圖是讓spinlock可搶占,但是可搶占后將產生很多后續影響。
Spinlock失效搶占的目的是避免死鎖。Spinlock如果可搶占了,一個spinlock的競爭者將可能搶占該spinlock的保持者來運行,但是由于得不到spinlock將自旋在那里,如果競爭者的優先級高于保持者的優先級,將形成一種死鎖的局面,因為保持者無法得到運行而永遠不能釋放spinlock,而競爭者由于不能得到一個不可能釋放的spinlock而永遠自旋在那里。
由于中斷處理函數也可以使用spinlock,如果它使用的spinlock已經被一個進程保持,中斷處理函數將無法繼續進行,從而形成死鎖,這樣的spinlock在使用時應當中斷失效來避免這種死鎖的情況發生。標準linux內核就是這么做的,中斷線程化之后,中斷失效就沒有必要,因為遇到這種狀況后,中斷線程將掛在等待隊列上并放棄CPU讓別的線程或進程來運行。
等待隊列就是解決這種死鎖僵局的方法,在Ingo Molnar的實時補丁中,每個spinlock都有一個等待隊列,該等待隊列是按進程或線程的優先級排隊的。如果一個進程或線程競爭的spinlock已經被另一個線程保持,它將把自己掛在該spinlock的優先級化的等待隊列上,然后發生調度把CPU讓給別的進程或線程。
需要特別注意,對于非線程化的中斷,必須使用原來的spinlock,原因前面已經講得很清楚。
原來的spinlock結構如下:
typedef struct { volatile unsigned long lock; # ifdef CONFIG_DEBUG_SPINLOCK unsigned int magic; # endif # ifdef CONFIG_PREEMPT unsigned int break_lock; # endif } spinlock_t;它非常簡潔,替換成mutex之后,它的結構為:
typedef struct { struct rt_mutex lock; unsigned int break_lock; } spinlock_t;其中struct rt_mutex結構如下:
struct rt_mutex { raw_spinlock_t wait_lock; struct plist wait_list; struct task_struct *owner; int owner_prio; # ifdef CONFIG_RT_DEADLOCK_DETECT int save_state; struct list_head held_list; unsigned long acquire_eip; char *name, *file; int line; # endif };類型raw_spinlock_t就是原來的spinlock_t。在結構struct rt_mutex中的wait_list字段就是優先級化的等待隊列。
原來的rwlock_t結構如下:
typedef struct { volatile unsigned long lock; # ifdef CONFIG_DEBUG_SPINLOCK unsigned magic; # endif # ifdef CONFIG_PREEMPT unsigned int break_lock; # endif } rwlock_t;被mutex化的rwlock結構如下:
typedef struct { struct rw_semaphore lock; unsigned int break_lock; } rwlock_t;其中rw_semaphore結構為:
struct rw_semaphore { struct rt_mutex lock; int read_depth; };rwlock_t和spinlock_t沒有本質的不同,只是rwlock_t只能有一個寫者,但可以有多個讀者,因此使用了字段read_depth,其他都等同于spinlock_t。
如果必須使用原來的spinlock,可以把它聲明為raw_spinlock_t,如果必須使用原來的rwlock_t,可以把它聲明為raw_rwlock_t,但是對其進行鎖或解鎖操作時仍然使用同樣的函數,靜態初始化時必須分別使用RAW_SPIN_LOCK_UNLOCKED和RAW_RWLOCK_UNLOCKED。為什么不同的變量類型可以使用同樣的函數操作呢?關鍵在于使用了gcc的內嵌函數__builtin_types_compatible_p,下面以spin_lock為例來說明其中的奧妙:
#define spin_lock(lock) PICK_OP(raw_spinlock_t, spin, _lock, lock)
PICK_OP的定義為:
#define PICK_OP(type, optype, op, lock) \ do { \ if (TYPE_EQUAL((lock), type)) \ _raw_##optype##op((type *)(lock)); \ else if (TYPE_EQUAL(lock, spinlock_t)) \ _spin##op((spinlock_t *)(lock)); \ else __bad_spinlock_type(); \ } while (0)TYPE_EQUAL的定義為:
#define TYPE_EQUAL(lock, type) \ __builtin_types_compatible_p(typeof(lock), type *)
gcc內嵌函數__builtin_types_compatible_p用于判斷一個變量的類型是否為某指定的類型,如果是就返回1,否則返回0。
因此,如果一個spinlock的類型如果是spinlock_t,宏spin_lock的預處理結果將是:
do { if (0) _raw_spin_lock((raw_spinlock_t *)(lock)); else if (1) _spin_lock((spinlock_t *)(lock)); else __bad_spinlock_type; } while (0)如果一個spinlock的類型為raw_spinlock_t,宏spin_lock的預處理結果將是:
do { if (1) _raw_spin_lock((raw_spinlock_t *)(lock)); else if (0) _spin_lock((spinlock_t *)(lock)); else __bad_spinlock_type; } while (0)很明顯,如果類型為spinlock_t,將運行函數_spin_lock,而如果類型為raw_spinlock_t,將運行函數_raw_spin_lock。
_spin_lock是新的spinlock的鎖實現函數,而_raw_spin_lock就是原來的spinlock的鎖實現函數。
等待隊列優先級化的目的是為了更好地改善實時性,因為優先級化后,每次當spinlock保持者釋放鎖時總是喚醒排在最前面的優先級最高的進程或線程,而喚醒的時間復雜度為O(1)。
spinlock被mutex化后會產生優先級逆轉(Priority Inversion)現象。所謂優先級逆轉,就是優先級高的進程由于優先級低的進程保持了競爭資源被迫等待,而讓中間優先級的進程運行,優先級逆轉將導致高優先級進程的搶占延遲增大,中間優先級的進程的執行時間的不確定性導致了高優先級進程搶占延遲的不確定性,因此為了保證實時性,必須消除優先級逆轉現象。
優先級繼承協議(Priority Inheritance Protocol)和優先級頂棚協議(Priority Ceiling Protocol)就是專門針對優先級逆轉問題提出的解決辦法。
所謂優先級繼承,就是spinlock的保持者將繼承高優先級的競爭者進程的優先級,從而能先于中間優先級進程運行,盡可能快地釋放鎖,這樣高優先級進程就能很快得到競爭的spinlock,使得搶占延遲更確定,更短。
所謂優先級頂棚,就是根據靜態分析確定一個spinlock的可能擁有者的最高優先級,然后把spinlock的優先級頂棚設置為該確定的值,每次當進程獲得該spinlock后,就將該進程的優先級設置為spinlock的優先級頂棚值。
Ingo Molnar的實時補丁實現了優先級繼承協議,但沒有實現優先級頂棚協議。
Spinlock被mutex化后引入的另一個問題就是死鎖,典型的死鎖有兩種:
一種為自鎖,即一個spinlock保持者試圖獲得它已經保持的鎖,很顯然,這會導致該進程無法運行而死鎖。
另一種為非順序鎖而導致的,即進程 P1已經保持了spinlock LOCKA但是要獲得進程P2已經保持的spinlock LOCKB,而進程P2要獲得進程P1已經保持的spinlock LOCKA,這樣進程P1和P2都將因為需要得到對方擁有的但永遠不可能釋放的spinlock而死鎖。
Ingo Molnar的實時補丁對這兩種情況進行了檢測,一旦發生這種死鎖,內核將輸出死鎖執行路徑并panic。
Ingo Molnar的實時補丁支持的架構包括i386、x86_64、ppc和mips,基本上含蓋了主流的架構,對于其他的架構,移植起來也是非常容易的。
架構移植主要涉及到以下幾個方面:
1.中斷線程化
中斷線程化有兩種做法,一種是利用IRQ子系統的代碼,另一種是在架構相關的子樹實現,前一種方法利用的是已有的中斷線程化代碼,因此移植時幾乎不需要做什么工作,但是對一些架構,這種方法缺乏靈活性,尤其是一些架構中斷處理比較特別時,可能會是IRQ子系統的中斷線程化代碼部分變的越來越丑陋,因此對于這種架構,后一種方法就有明顯優勢,當然在后一種方法中仍然可以拷貝IRQ子系統內的大部分線程化處理代碼。
中斷線程化要求一些spinlock或rwlock必須是raw_*類型的,而且一些IRQ必須是非線程化的,如時鐘中斷、級聯中斷等。這些是中斷線程化的必要前提。
2.一些架構相關的代碼
有一些變量定義在架構相關的子樹下,如hardirq_preemption等,還有就是需要對entry.S做一些修改,因為增加了一個新的調用preempt_schedule_irq,它要求在調用之前失效中斷。還有就是一些調試代碼支持,那是完全架構相關的必須重新實現,如mcount。
3.架構相關的semaphore定義必須在第四種搶占模式下失效
前面已經講過,如果使能第四種搶占模式,將使用新定義的semaphore,它是架構無關的,相應的處理代碼也是架構無關的,因此原來的架構相關的定義和處理代碼必須失效,這需要修改相應的.h、.c和Makefile。
4.一些spinlock必須聲明為raw_*類型的
在架構相關的子樹中,一些spinlock必須聲明為raw_*類型的,靜態初始化也必須修改為RAW_*,一些外部聲名也得做相應的改動。
5.在打開第四種搶占模式或中斷線程化使能之后,一些編程邏輯要求已經發生了變化。
中斷線程化后,在中斷處理函數中失效中斷不在需要,因為如果中斷處理線程在中斷失效后想得到spinlock時,將可能發生上下文切換,新的實時實現認為這種狀況不應當發生將輸出警告信息。
原來用中斷失效保護共享資源,現在完全可以用搶占失效來替代,因此不是萬不得已,建議不使用中斷失效。在網卡驅動的發送處理函數中不能失效中斷,因此原來顯式得失效中斷的函數應當被替換,如:
local_irq_save應當變成為local_irq_save_nort local_irq_restore應當變成為local_irq_restore_nort
網絡的核心代碼將主動檢測這種情況,如果中斷失效了,將重新打開中斷,但是將輸出警告信息。
在保持了raw_spinlock之后不能在試圖獲得新的spinlock類型的鎖,因為raw_spinlock是搶占失效的,但是新的spinlock卻能夠導致進程睡眠或發生搶占。
對于新的semaphore,必須要求執行down和up操作的是同一個進程,否則優先級繼承和死鎖檢測將無法實現。而且代碼本身也將操作失敗。
以上就是Linux實時補丁是否即將合并進Linux 5.3,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





