溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Java內存模型之重排序的示例分析,希望大家閱讀完這篇文章之后都有所收獲,下面讓我們一起去探討吧!
如果兩個操作訪問同一個變量,而且這兩個操作中有一個操作為寫操作,此時這兩個操作之間存在數據依賴性。數據依賴性分為三種,如表所示:
| 名稱 | 代碼示例 | 說明 |
|---|---|---|
| 寫后讀 | a=1;b=a; | 寫一個變量后,再讀這個位置 |
| 寫后寫 | a=1;a=2; | 寫一個變量后,在寫這個變量 |
| 讀后寫 | a=b;b=1; | 讀一個變量后,再寫這個變量 |
上面的這三種情況,只要重排序了兩個操作的執行順序,程序的執行結果就會被改變。編譯器和處理器針對單個處理器中執行的指令序列和單個線程中執行的操作重排序時,會遵守數據依賴性,編譯器和處理器不會改變存在數據依賴關系的兩個操作的執行順序。(不同處理器和不同線程之間的數據依賴性不被編譯器和處理器考慮)。
as-if-serial語義指的是:不管怎么重排序,單線程執行程序的執行結果不能被改變。編譯器、runtime和處理器都必須遵守as-if-serial語義。
為了遵守as-if-serial語義,編譯器和處理器不會對存在數據依賴關系的操作做重排序,因為 這種重排序會改變執行結果。但是,如果操作之間不存在數據依賴關系,這些操作就可能被編譯器和處理器重排序。
舉例說明,計算圓面積的代碼示例:
double pi = 3.14; // A double r = 1.0; // B double area = pi * r; // C
上面3個操作的數據依賴關系如下所示:
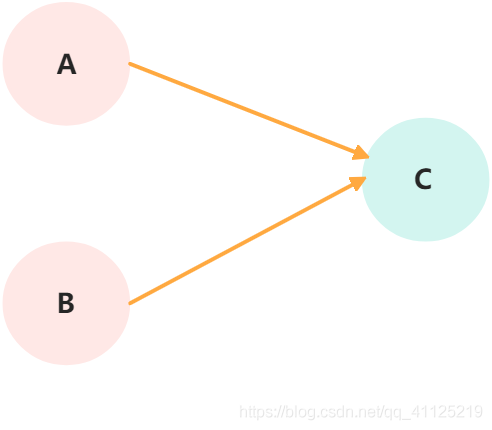
3個操作之間的依賴關系
解釋:A和B之間存在數據依賴關系,同時B和C之間也存在數據依賴關系。因此在最終執行的指令序列中,C不可能被排到A和B的前面(C排到A和B的前面,程序的結果將會被改變)。但A和B之間沒有數據依賴關系,編譯器和處理器可重排序A和B之間的執行順序。
重排序后存在如下的執行可能:
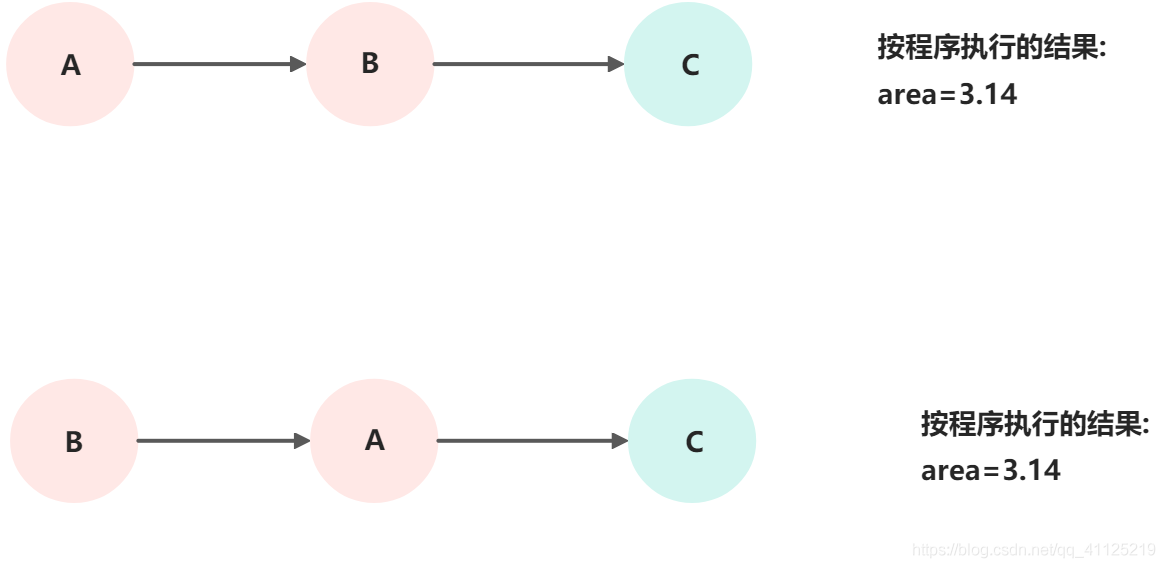
總結:as-if-serial語義吧單線程程序保護起來了,遵守as-if-serial語義的編譯器、runtime和處理器共同為編寫單線程程序的程序員創建了一個錯誤的幻覺:單線程程序是按程序的順序來執行的。as-if-serial語義使單線程程序員無需擔心重排序會干擾他們,也無需擔心內存可見性問題。
根據happens-before的程序規則,上面計算圓的面積的示例代碼存在3個happens-before關系。
1.A happens-before B
2.B happens-before C
3.A happens-before C
A happens-before C是根據1和2推導出來的。
雖然A happens-before B但是實際執行時B卻可以排在A前面執行(在上面的執行圖中)。如果A happens-before B,JMM并不要求A一定要在B之前執行,JMM僅僅要求前一個操作(執行的結果)對后一個操作可見,且前一個操作按順序排在第二個操作之前。這里A的執行結果不需要對B可見;而且重排序操作A和操作B后的執行結果,與A和操作B按happens-before順序執行的結果一致。在這種情況下,JMM會認為這種重排序并不非法(not illegal),JMM運行這種重排序。
在計算機中,軟件技術和硬件技術有一個共同目標:再不改變程序執行結果的前提下,盡可能提高并行度。編譯器和處理區遵從這一目標,從happens-before的定義我們可以看出,JMM同樣也遵循這一目標。
重排序是否會影響多線程的執行結果呢?
package com.lizba.p1;
/**
* <p>
*
* </p>
*
* @Author: Liziba
* @Date: 2021/6/7 23:01
*/
public class ReorderExample {
// 定義變量a
int a = 0;
// flag變量是個標記,用來標志變量a是否被寫入
boolean flag = false;
public void writer() {
a = 1; // 1
flag = true; // 2
}
public void reader() {
if (flag) { // 3
int i = a * a; // 4
System.out.println("i:" + i);
}
}
/**
* 測試
*
* @param args
*/
public static void main(String[] args) {
final ReorderExample re = new ReorderExample();
new Thread() {
public void run() {
re.writer();
}
}.start();
new Thread() {
public void run() {
re.reader();
}
}.start();
}
}這里假設兩個線程A和B,A首先執行write(),B再執行readr()。線程B在執行操作4時,能否看到線程A在操作1對共享變量a的寫入呢?
答案是:不一定能!
由于操作1和操作2沒有數據依賴關系,編譯器和處理器可以對這兩個操作重排序;同樣,操作3和操作4沒有數據依賴關系,編譯器和處理器也可以多這兩個操作重排序。
假設操作1和操作2重排序:(虛箭線代表錯誤的讀操作)
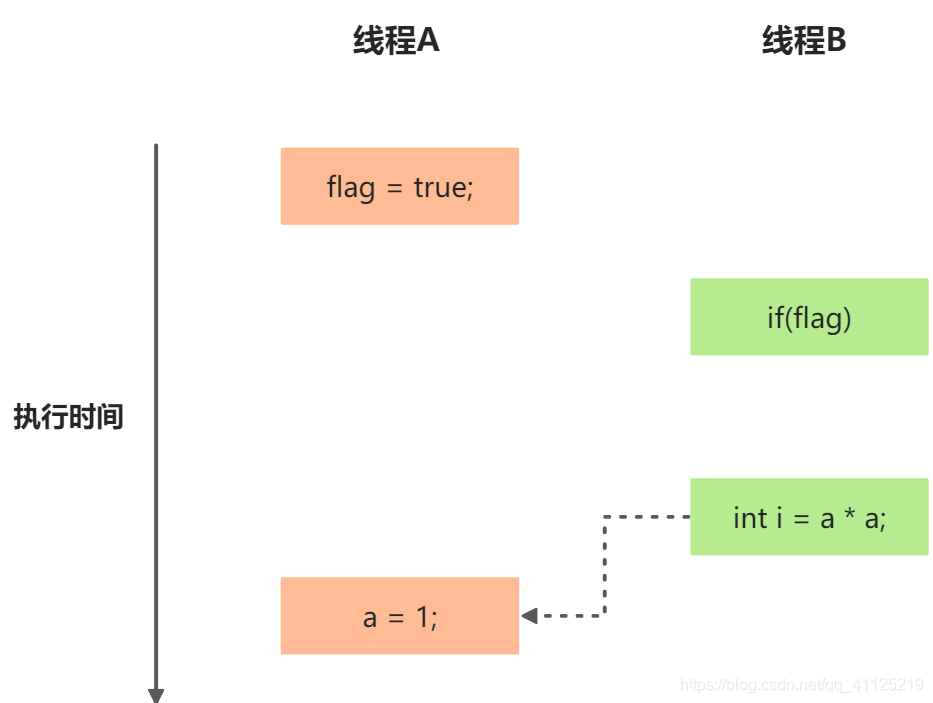
程序執行時序圖
如上圖操作1和操作2發生了重排序。程序執行時,線程A首先寫標記變量flag,隨后線程B讀取這個變量,條件判斷為真,線程B讀取變量a的值。此時,變量a還沒有被線程A寫入,在這里多線程程序的語義被重排序破壞了。
假設操作3和操作4重排序:
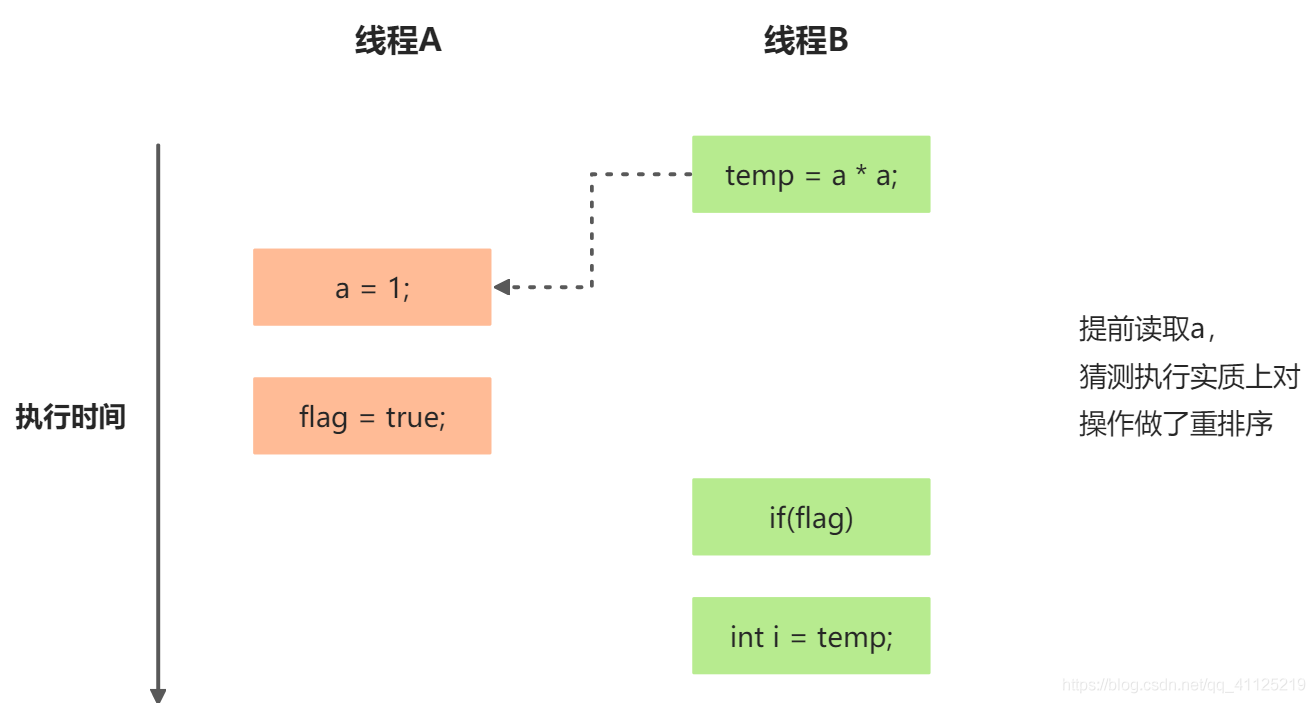
程序執行時序圖
在上述執行方式的程序中,操作3和操作4存在控制依賴關系。當代碼中存在控制依賴性時,會影響指令并行度。為此編譯器和處理器會采用猜測(Speculation)執行來克服控制相關性對并行度的影響。以處理器的猜測執行為例,執行現場B的處理器可提前讀取并行計算a*a,然后計算結果保存到一個名為重排序緩沖(Recorder Buffer, ROB)的硬件緩存中。當操作3的條件判斷為真時,就把計算結果寫入變量i中。
在上圖中可以看出,猜測執行實質上對操作3和4做了重排序。重排序在這里破壞了多線程程序的語義!
在單線程程序中,對存在控制依賴性的操作重排序,不會改變執行結果(這也是as-if-serial語義允許對存在控制依賴的操作做重排序的原因);但是在多線程中,對存在控制依賴的操作重排序,可能會改變程序的執行結果。
看完了這篇文章,相信你對“Java內存模型之重排序的示例分析”有了一定的了解,如果想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





