溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何使用hadoop來提取文件中的指定內容,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
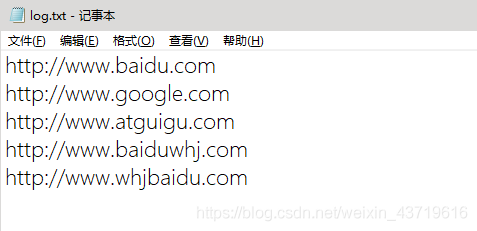
把以下txt中含“baidu”字符串的鏈接輸出到一個文件,否則輸出到另外一個文件。
1.LogMapper.java
package com.whj.mapreduce.outputformat;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class LogMapper extends Mapper<LongWritable,Text,Text,NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 不做任何處理
context.write(value,NullWritable.get());
}
}2.LogReducer.java
package com.whj.mapreduce.outputformat;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class LogReducer extends Reducer<Text,NullWritable,Text,NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
for (NullWritable value : values) {
context.write(key,NullWritable.get());
}
}
}3.LogOutputFormat.java
package com.whj.mapreduce.outputformat;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class LogOutputFormat extends FileOutputFormat<Text,NullWritable> {
@Override
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {
LogRecordWriter lrw = new LogRecordWriter(job);
return lrw;
}
}4.LogRecordWriter.java
package com.whj.mapreduce.outputformat;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import java.io.IOException;
public class LogRecordWriter extends RecordWriter<Text,NullWritable> {
private FSDataOutputStream baiduOut;//ctrl+alt+f
private FSDataOutputStream otherOut;
public LogRecordWriter(TaskAttemptContext job) throws IOException {
//創建兩條流
FileSystem fs = FileSystem.get(job.getConfiguration());
baiduOut = fs.create(new Path("D:\\temp\\outputformat.log"));
otherOut = fs.create(new Path("D:\\temp\\other.log"));
}
@Override
public void write(Text key, NullWritable nullWritable) throws IOException, InterruptedException {
// 具體寫
String log = key.toString();
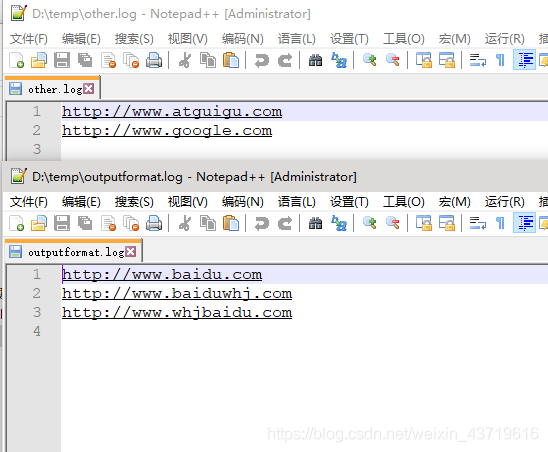
if(log.contains("baidu")){
baiduOut.writeBytes(log+"\n");
}else{
otherOut.writeBytes(log+"\n");
}
}
@Override
public void close(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
//關流
IOUtils.closeStream(baiduOut);
IOUtils.closeStream(otherOut);
}
}5.LogDriver.java
package com.whj.mapreduce.outputformat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class LogDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(LogDriver.class);
job.setMapperClass(LogMapper.class);
job.setReducerClass(LogReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//設置自定義的 outputformat
job.setOutputFormatClass(LogOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path("D:\\input"));
// 雖 然 我 們 自 定 義 了 outputformat , 但 是 因 為 我 們 的 outputformat 繼承自fileoutputformat
//而 fileoutputformat 要輸出一個_SUCCESS 文件,所以在這還得指定一個輸出目錄
FileOutputFormat.setOutputPath(job, new Path("D:\\temp\\logoutput"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
} }
關于“如何使用hadoop來提取文件中的指定內容”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





