溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關Java并發編程之ConcurrentLinkedQueue源碼的示例分析的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
并編程中,一般需要用到安全的隊列,如果要自己實現安全隊列,可以使用2種方式:
方式1:加鎖,這種實現方式就是我們常說的阻塞隊列。
方式2:使用循環CAS算法實現,這種方式實現隊列稱之為非阻塞隊列。
從點到面, 下面我們來看下非阻塞隊列經典實現類:ConcurrentLinkedQueue (JDK1.8版)
ConcurrentLinkedQueue 是一個基于鏈接節點的無界線程安全的隊列。當我們添加一個元素的時候,它會添加到隊列的尾部,當我們獲取一個元素時,它會返回隊列頭部的元素。它采用了“wait-free”算法來實現,用CAS實現了非阻塞的線程安全隊列。當多個線程共享訪問一個公共 collection 時,ConcurrentLinkedQueue 是一個恰當的選擇。此隊列不允許使用 null 元素,因為移除元素時實際是將節點中item置為null,如果元素本身為null,則跟刪除有沖突
我們首先看一下ConcurrentLinkedQueue的類圖結構先,好有一個內部邏輯有一個大概的印象,如下圖所示:
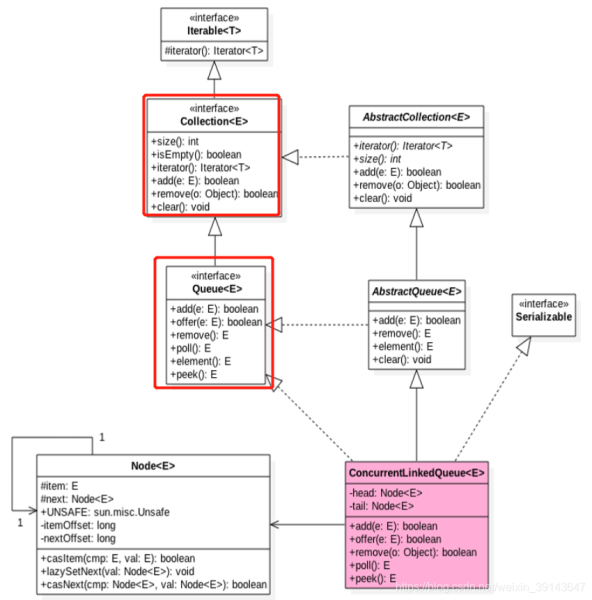
主要屬性head節點,tail節點
// 鏈表頭節點 private transient volatile Node<E> head; // 鏈表尾節點 private transient volatile Node<E> tail;
主要內部類Node
類Node在static方法里獲取到item和next的內存偏移量,之后通過casItem和casNext更改item值和next節點
private static class Node<E> {
volatile E item;
volatile Node<E> next;
/**
* Constructs a new node. Uses relaxed write because item can
* only be seen after publication via casNext.
*/
Node(E item) {
//將item存放在本節點的itemOffset偏移量位置的內存里
UNSAFE.putObject(this, itemOffset, item);//設置this對象的itemoffset位置
}
//更新item值
boolean casItem(E cmp, E val) {
//this對象的itemoffset位置存放的值如果和期望值cmp相等,則替換為val
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
void lazySetNext(Node<E> val) {
//this對象的nextOffset位置存入val
UNSAFE.putOrderedObject(this, nextOffset, val);
}
//更新next節點值
boolean casNext(Node<E> cmp, Node<E> val) {
//this對象的nextOffset位置存放的值如果和期望值cmp相等,則替換為val
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
//當前節點存放的item的內存偏移量
private static final long itemOffset;
//當前節點的next節點的內存偏移量
private static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Node.class;
itemOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("item"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}concurrentlinkedqueue同樣在static方法里獲取到head和tail的內存偏移量:之后通過casHead和casTail更改head節點和tail節點值
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = ConcurrentLinkedQueue.class;
headOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("head"));
tailOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("tail"));
} catch (Exception e) {
throw new Error(e);
}
}
private boolean casTail(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, tailOffset, cmp, val);
}
private boolean casHead(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, headOffset, cmp, val);
}無參構造函數,head=tail=new Node<E>(null)=空節點(里面無item值)
集合構造函數(集合中每個元素不能為null):就是將集合中的元素挨個鏈起來
//無參構造函數,head=tail=new Node<E>(null)=空節點
//初始一個為空的ConcurrentLinkedQueue,此時head和tail都指向一個item為null的節點
public ConcurrentLinkedQueue() {
// 初始化頭尾節點
head = tail = new Node<E>(null);
}
//集合構造函數:就是將集合中的元素挨個鏈起來
public ConcurrentLinkedQueue(Collection<? extends E> c) {
Node<E> h = null, t = null;
for (E e : c) {
checkNotNull(e);
Node<E> newNode = new Node<E>(e);
if (h == null)
h = t = newNode;
else {
t.lazySetNext(newNode);//可以理解為一種懶加載, 將t的next值設置為newNode
t = newNode;
}
}
if (h == null)
h = t = new Node<E>(null);
head = h;
tail = t;
}
private static void checkNotNull(Object v) {
if (v == null)
throw new NullPointerException();
}
//putObjectVolatile的內存非立即可見版本,
//寫后結果并不會被其他線程看到,通常是幾納秒后被其他線程看到,這個時間比較短,所以代價可以接收
void lazySetNext(Node<E> val) {
UNSAFE.putOrderedObject(this, nextOffset, val);
}獲取到當前尾節點p=tail:
如果p.next=null,代表是真正的尾節點,將新節點鏈入p.next=newNode。此時檢查tail是否還是p,如果不是p了,此時更新tail為最新的newNode(只有在tail節點后面tail.next成功添加的元素才不需要更新tail,其實更新不更新tail是交替的,即每添加倆次更新一次tail)。
如果p.next=p,此時其實是p.next==p==null,此時代表p被刪除了,此時需要從新的tail節點檢查,如果此時tail節點還是原來的tail(原來的tail在p前面,肯定也被刪除了),那就只能從head節點開始遍歷了
如果p.next!=null,代表有別的線程搶先添加元素了,此時需要繼續p=p.next遍歷獲取是null的節點(此時需要如果tail變了就使用新的tail往后遍歷)
public boolean offer (E e){
//先檢查元素是否為null,是null則拋出異常 不是null,則構造新節點準備入隊
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
//初始p指針和t指針都指向尾節點,p指針用來向隊列后面推移,t指針用來判斷尾節點是否改變
Node<E> t = tail, p = t;
for (; ; ) {
Node<E> q = p.next;
if (q == null) {//p.next為null,則代表p為尾節點,則將p.next指向新節點
// p is last node
if (p.casNext(null, newNode)) {
/**
* 如果p!=t,即p向后推移了,t沒動,則此時同時將tail更新
* 不符合條件不更新tail,這里可以看出并不是每入隊一個節點都會更新tail的
* 而此時真正的尾節點其實是newNode了,所以tail不一定是真正的尾節點,
* tail的更新具有滯后性,這樣設計提高了入隊的效率,不用每入隊一個,更新一次
*尾節點
*/
if (p != t)
casTail(t, newNode); // Failure is OK.
return true;
}
// Lost CAS race to another thread; re-read next
} else if (p == q)
/**
* 如果p.next和p相等,這種情況是出隊時的一種哨兵節點代表已被遺棄刪除,
* 那就是有線程在一直刪除節點,刪除到了p.next 那此時如果有線程已經更新了tail,那就從p指向tail再開始繼續像后推移
* 如果始終沒有線程更新tail,則p指針從head開始向后推移
*
* p從head開始推移的原因:tail沒有更新,以前的tail肯定在哨兵節點的前面(因為此循環是從tail向后推移到哨兵節點的),
* 而head節點一定在哨兵節點的后面(出隊時只有更新了head節點,才會把前面部分的某個節點置為哨兵節點)
* 此時其實是一種tail在head之前,但實際上tail已經無用了,哨兵之前的節點都無用了,
* 等著其他線程入隊時更新尾節點tail,此時的tail才有用所以從head開始,從head開始可以找到任何節點
*
*/
p = (t != (t = tail)) ? t : head;
else
/**
* p.next和p不相等時,此時p應該向后推移到p.next,即p=p.next,
* 如果next一直不為null一直定位不到尾節點,會一直next,
* 但是中間會優先判斷tail是否已更新,如果tail已更新則p直接從tail向后推移即可。就沒必要一直next了。
*/
// Check for tail updates after two hops.
p = (p != t && t != (t = tail)) ? t : q;
}
}poll出隊:
獲取到當前頭節點p=head:如果成功設置了item為null,即p.catItem(item,null),
如果此時被其他線程搶走消費了,此時需要p=p.next,向后繼續爭搶消費,直到成功執行p.catItem(item,null),此時檢查p是不是head節點,如果不是更新p.next為頭結點
public E poll() {
restartFromHead:
for (;;) {
// p節點表示首節點,即需要出隊的節點
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
// 如果p節點的元素不為null,則通過CAS來設置p節點引用的元素為null,如果成功則返回p節點的元素
if (item != null && p.casItem(item, null)) {
// Successful CAS is the linearization point
// for item to be removed from this queue.
// 如果p != h,則更新head
if (p != h) // hop two nodes at a time
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
// 如果頭節點的元素為空或頭節點發生了變化,這說明頭節點已經被另外一個線程修改了。
// 那么獲取p節點的下一個節點,如果p節點的下一節點為null,則表明隊列已經空了
else if ((q = p.next) == null) {
// 更新頭結點
updateHead(h, p);
return null;
}
// p == q,則使用新的head重新開始
else if (p == q)
continue restartFromHead;
// 如果下一個元素不為空,則將頭節點的下一個節點設置成頭節點
else
p = q;
}
}
}offer:
找到尾節點,將新節點鏈入到尾節點后面,tail.next=newNode,
由于多線程操作,所以拿到p=tail后cas操作執行p.next=newNode可能由于被其他線程搶去而執行不成功,此時需要p=p.next向后遍歷,直到找到p.next=null的目標節點。繼續嘗試向其后面添加元素,添加成功后檢查p是否是tail,如果不是tail,則更新tail=p,添加不成功繼續向后next遍歷
poll:
獲取到當前頭節點p=head:如果成功設置了item為null,即p.catItem(item,null),
如果此時被其他線程搶走消費了,此時需要p=p.next,向后繼續爭搶消費,直到成功執行p.catItem(item,null),此時檢查p是不是head節點,如果不是更新頭結點head=p.next(因為p已經刪除了)
更新tail和head:
不是每次添加都更新tail,而是間隔一次更新一次(head也是一樣道理):第一個搶到的線程拿到tail執行成功tail.next=newNode1此時不更新tail,那么第二個線程再執行成功添加p.next=newNode2會判斷出p是newNode1而不是tail,所以就更新tail為newNode2。
tail節點不總是最后一個,head節點不總是第一個設計初衷:
讓tail節點永遠作為隊列的尾節點,這樣實現代碼量非常少,而且邏輯非常清楚和易懂。但是這么做有個缺點就是每次都需要使用循環CAS更新tail節點。如果能減少CAS更新tail節點的次數,就能提高入隊的效率。
在JDK 1.7的實現中,doug lea使用hops變量來控制并減少tail節點的更新頻率,并不是每次節點入隊后都將 tail節點更新成尾節點,而是當tail節點和尾節點的距離大于等于常量HOPS的值(默認等于1)時才更新tail節點,tail和尾節點的距離越長使用CAS更新tail節點的次數就會越少,但是距離越長帶來的負面效果就是每次入隊時定位尾節點的時間就越長,因為循環體需要多循環一次來定位出尾節點,但是這樣仍然能提高入隊的效率,因為從本質上來看它通過增加對volatile變量的讀操作來減少了對volatile變量的寫操作,而對volatile變量的寫操作開銷要遠遠大于讀操作,所以入隊效率會有所提升。
在JDK 1.8的實現中,tail的更新時機是通過p和t是否相等來判斷的,其實現結果和JDK 1.7相同,即當tail節點和尾節點的距離大于等于1時,更新tail。
1. 簡單,只需理解基本的概念,就可以編寫適合于各種情況的應用程序;2. 面向對象;3. 分布性,Java是面向網絡的語言;4. 魯棒性,java提供自動垃圾收集來進行內存管理,防止程序員在管理內存時容易產生的錯誤。;5. 安全性,用于網絡、分布環境下的Java必須防止病毒的入侵。6. 體系結構中立,只要安裝了Java運行時系統,就可在任意處理器上運行。7. 可移植性,Java可以方便地移植到網絡上的不同機器。8.解釋執行,Java解釋器直接對Java字節碼進行解釋執行。
感謝各位的閱讀!關于“Java并發編程之ConcurrentLinkedQueue源碼的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





