溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
?
?
?
生產中會生成大量的系統日志、應用程序日志、安全日志等等,通過對日志的分析,可了解服務器的負載、健康狀態,可分析客戶的分布情況、客戶的行為,甚至基于這些分析可做出預測;
?
一般采集流程:
日志產出-->采集-->存儲-->分析-->存儲-->可視化;
采集(logstash、flume(apache)、scribe(facebook));
?
開源實時日志分析,ELK平臺:
logstash收集日志,存放到ES集群中,kibana從ES中查詢數據生成圖表,返回browser;
?
離線分析;
在線分析,一份生成日志,一份傳給大數據實時處理服務;
實時處理技術:storm、spark;
?
?
分析的前提:
半結構化數據:日志是半結構化數據,是有組織的,有格式的數據,可分割成行和列,可當作表來處理,也可分析里面的數據;
?
文本分析:日志是文本文件,需要依賴文件io、字符串操作、正則等技術,通過這些技術能把日志中需要的數據提取出來;
?
例:
123.125.71.36 - - [06/Apr/2017:18:09:25 +0800] "GET / HTTP/1.1" 200 8642 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"
?
提取數據:
1、用空格分割;
方1:

方2:先空格分割,遇""[]特殊處理;
?
2、用正則提取;
?
1、
import datetime
?
logs = '''123.125.71.36 - - [06/Apr/2017:18:09:25 +0800]
"GET / HTTP/1.1" 200 8642 "-"
"Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"'''
?
names = ('remote','','','datetime','request','status','length','','useragent')
?
ops = (None,None,None,lambda timestr: datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z'),
?????? lambda request: dict(zip(['method','url','protocol'],request.split())),int,int,None,None)
?
def extract(line):
??? fields = []
??? flag = False
??? tmp = ''
?
??? for field in line.split():
??? #???? print(field)
??????? if not flag and (field.startswith('[') or field.startswith('"')):
??????????? if field.endswith(']') or field.endswith('"'):
??????????????? fields.append(field.strip())
??????????? else:
??????????????? tmp += field[1:]
??? #???????????? print(tmp)
??????????????? flag = True
??????????? continue
?
??????? if flag:
??????????? if field.endswith(']') or field.endswith('"'):
??????????????? tmp += ' ' + field[:-1]
??????????????? fields.append(tmp)
??????????????? flag = False
??????????????? tmp = ''
??????????? else:
?????????? ?????tmp += ' ' + field
??????????? continue
?
??????? fields.append(field)
??? print(fields)
???
??? info = {}
??? for i,field in enumerate(fields):
#???????? print(i,field)
??????? name = names[i]
??????? op = ops[i]
??????? if op:
??????????? info[name] = (op(field),op)
??? return info
?
print(extract(logs))
輸出:
['123.125.71.36', '-', '-', '06/Apr/2017:18:09:25 +0800', 'GET / HTTP/1.1', '200', '8642', '"-"', 'Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)']
Out[16]:
{'datetime': (datetime.datetime(2017, 4, 6, 18, 9, 25, tzinfo=datetime.timezone(datetime.timedelta(0, 28800))),
? <function __main__.<lambda>>),
?'length': (8642, int),
?'request': ({'method': 'GET', 'protocol': 'HTTP/1.1', 'url': '/'},
? <function __main__.<lambda>>),
?'status': (200, int)}
?
2、
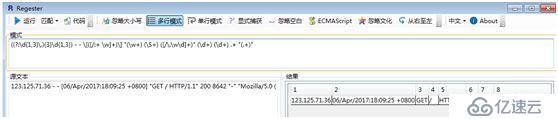
((?:\d{1,3}\.){3}\d{1,3}) - - \[([/:+ \w]+)\] "(\w+) (\S+) ([/\.\w\d]+)" (\d+) (\d+) .+ "(.+)"
?
import datetime
import re
?
# logs = '''123.125.71.36 - - [06/Apr/2017:18:09:25 +0800] "GET / HTTP/1.1" 200 8642 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"'''
?
ops = {
??? 'datetime': lambda timestr: datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z'),
??? 'status': int,
??? 'length': int
}
?
pattern = '''(?P<remote>(?:\d{1,3}\.){3}\d{1,3}) - - \[(?P<datetime>[/:+ \w]+)\] "(?P<method>\w+) (?P<request>\S+) (?P<protocol>[/\.\w\d]+)" (?P<status>\d+) (?P<length>\d+) .+ "(?P<useragent>.+)"'''
?
regex = re.compile(pattern)
?
def extract(line)->dict:
??? matcher = regex.match(line)
??? info = None
??? if matcher:
??????? info = {k:ops.get(k,lambda x:x)(v) for k,v in matcher.groupdict().items()}
??? return info
?
# print(extract(logs))
?
def load(path:str):?? #裝載日志文件
??? with open(path) as f:
??????? for line in f:
??????????? d = extract(line)
??????????? if d:
??????????????? yield d?? #生成器函數
??????????? else:
??????????????? continue?? #不合格數據,pycharm中左下角TODO(view-->Status Bar)
?
g = load('access.log')
print(next(g))
print(next(g))
print(next(g))
?
# for i in g:
#???? print(i)
輸出:
{'remote': '123.125.71.36', 'datetime': datetime.datetime(2017, 4, 6, 18, 9, 25, tzinfo=datetime.timezone(datetime.timedelta(0, 28800))), 'method': 'GET', 'request': '/', 'protocol': 'HTTP/1.1', 'status': 200, 'length': 8642, 'useragent': 'Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)'}
{'remote': '112.64.118.97', 'datetime': datetime.datetime(2017, 4, 6, 19, 13, 59, tzinfo=datetime.timezone(datetime.timedelta(0, 28800))), 'method': 'GET', 'request': '/favicon.ico', 'protocol': 'HTTP/1.1', 'status': 200, 'length': 4101, 'useragent': 'Dalvik/2.1.0 (Linux; U; Android 5.1.1; SM-G9250 Build/LMY47X)'}
{'remote': '119.123.183.219', 'datetime': datetime.datetime(2017, 4, 6, 20, 59, 39, tzinfo=datetime.timezone(datetime.timedelta(0, 28800))), 'method': 'GET', 'request': '/favicon.ico', 'protocol': 'HTTP/1.1', 'status': 200, 'length': 4101, 'useragent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}
注:
代碼若在jupyter下,注意logs中內容不能換行;
?
?
?
滑動窗口:
或叫時間窗口,時間窗口函數,在數據分析領域極其重要;
很多數據,如日志,都是和時間相關的,都是按時間順序產生的,在數據分析時,要按照時間來求值;
interval,表示每一次求值的時間間隔;
width,時間窗口寬度,指一次求值的時間窗口寬度,每個時間窗口的數據不均勻;
?
當width > interval
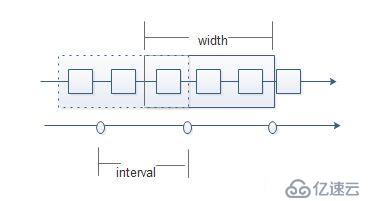
有重疊;
?
當width = interval
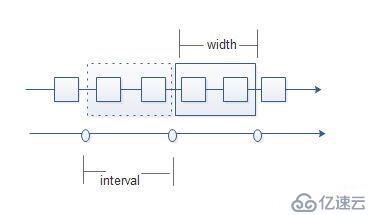

數據求值沒有重疊;
?
當width < interval
一般不采納這種方案,會有數據缺失;
如業務數據有1000萬條,要求每次漏幾個,這不影響統計趨勢;
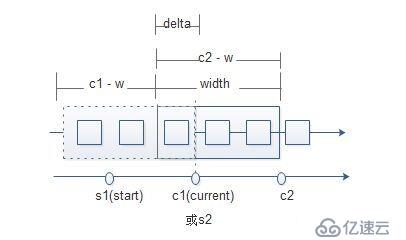
c2 = c1 - delta
delta = width - interval
delta = 0時,width = interval
?
時序數據,運維環境中,日志、監控等產生的數據是按時間先后產生并記錄下來的,與時間相關的數據,一般按時間對數據進行分析;
數據分析基本程序結構:
?
例:
一函數,無限的生成隨機數函數,產生時間相關的數據,返回->時間+隨機數;
每次取3個數據,求平均值;
import random
import datetime
?
# def source():
#???? while True:
#???????? yield datetime.datetime.now(),random.randint(1,100)
?
# i = 0
# for x in source():
#???? print(x)
#???? i += 1
#???? if i > 100:
# ????????break
?
# for _ in range(100):
#???? print(next(source()))
?
def source():
??? while True:
??????? yield {'value': random.randint(1,100),'datetime':datetime.datetime.now()}
?
src = source()
# lst = []
# lst.append(next(src))
# lst.append(next(src))
# lst.append(next(src))
lst = [next(src) for _ in range(3)]
?
def handler(iterable):
??? values = [x['value'] for x in iterable]
??? return sum(values) // len(values)
?
print(lst)
print(handler(lst))
?
?
?
窗口函數:
import datetime
import re
?
# logs = '''123.125.71.36 - - [06/Apr/2017:18:09:25 +0800] "GET / HTTP/1.1" 200 8642 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"'''
?
ops = {
??? 'datetime': lambda timestr: datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z'),
??? 'status': int,
??? 'length': int
}
?
pattern = '''(?P<remote>(?:\d{1,3}\.){3}\d{1,3}) - - \[(?P<datetime>[/:+ \w]+)\] "(?P<method>\w+) (?P<request>\S+) (?P<protocol>[/\.\w\d]+)" (?P<status>\d+) (?P<length>\d+) .+ "(?P<useragent>.+)"'''
?
regex = re.compile(pattern)
?
def extract(line)->dict:
??? matcher = regex.match(line)
??? info = None
??? if matcher:
??????? info = {k:ops.get(k,lambda x:x)(v) for k,v in matcher.groupdict().items()}
??? return info
?
# print(extract(logs))
?
def load(path:str):
??? with open(path) as f:
??????? for line in f:
??????????? d = extract(line)
??????????? if d:
??????????????? yield d
??????????? else:
??????????????? continue
?
# g = load('access.log')
# print(next(g))
# print(next(g))
# print(next(g))
?
# for i in g:
#???? print(i)
?
def window(src,handler,width:int,interval:int):
??? # src = {'remote': '112.64.118.97', 'datetime': datetime.datetime(2017, 4, 6, 19, 13, 59, tzinfo=datetime.timezone(datetime.timedelta(0, 28800))), 'method': 'GET', 'request': '/favicon.ico', 'protocol': 'HTTP/1.1', 'status': 200, 'length': 4101, 'useragent': 'Dalvik/2.1.0 (Linux; U; Android 5.1.1; SM-G9250 Build/LMY47X)'}
??? start = datetime.datetime.strptime('1970/01/01 01:01:01 +0800','%Y/%m/%d %H:%M:%S %z')
??? current = datetime.datetime.strptime('1970/01/01 01:01:02 +0800','%Y/%m/%d %H:%M:%S %z')
??? seconds = width - interval
??? delta = datetime.timedelta(seconds)
??? buffer = []
?
??? for x in src:
??????? if x:
??????????? buffer.append(x)
??????????? current = x['datetime']
??????? if (current-start).total_seconds() >= interval:
??????????? ret = handler(buffer)
??????????? # print(ret)
??????????? start = current
??????????? # tmp = []
??????????? # for i in buffer:
??????????? #???? if i['datetime'] > current - delta:
??????????? #???? ????tmp.append(i)
??????????? buffer = [i for i in buffer if i['datetime'] > current - delta]
?
def donothing_handler(iterable:list):
??? print(iterable)
??? return iterable
?
def handler(iterable:list):
??? pass?? #TODO
?
def size_handler(iterable:list):
??? pass?? #TODO
?
# window(load('access.log'),donothing_handler,8,5)
# window(load('access.log'),donothing_handler,10,5)
window(load('access.log'),donothing_handler,5,5)
輸出:
[{'remote': '123.125.71.36', 'datetime': datetime.datetime(2017, 4, 6, 18, 9, 25, tzinfo=datetime.timezone(datetime.timedelta(0, 28800))), 'method': 'GET', 'request': '/', 'protocol': 'HTTP/1.1', 'status': 200, 'length': 8642, 'useragent': 'Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)'}]
[{'remote': '112.64.118.97', 'datetime': datetime.datetime(2017, 4, 6, 19, 13, 59, tzinfo=datetime.timezone(datetime.timedelta(0, 28800))), 'method': 'GET', 'request': '/favicon.ico', 'protocol': 'HTTP/1.1', 'status': 200, 'length': 4101, 'useragent': 'Dalvik/2.1.0 (Linux; U; Android 5.1.1; SM-G9250 Build/LMY47X)'}]
[{'remote': '119.123.183.219', 'datetime': datetime.datetime(2017, 4, 6, 20, 59, 39, tzinfo=datetime.timezone(datetime.timedelta(0, 28800))), 'method': 'GET', 'request': '/favicon.ico', 'protocol': 'HTTP/1.1', 'status': 200, 'length': 4101, 'useragent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}]
?
?
?
分發:
生產者消費者模型:
對于一個監控系統,需要處理很多數據,包括日志;
要有數據的采集、分析;
被監控對象,即數據的producer生產者,數據的處理程序,即數據的consumer消費者;
傳統的生產者消費者模型,生產者生產,消費者消費,這種模型有些問題,開發的代碼耦合太高,如果生產規模擴大,不易擴展,生產和消費的速度難匹配;
?
queue隊列,食堂打飯;
producer-consumer,賣包子;消費速度 >= 生產速度;解決辦法:queue,作用:解耦(在程序間實現解耦(服務間解耦))、緩沖;
?
注:
zeromq,底層通信協議用;
大多數*mq,都是消費隊列;
kafka,性能極高;
FIFO,先進先出;
LIFO,后進先出;
?
數據的生產是不穩定的,會造成短時間數據的潮涌,需要緩沖;
消費者消費能力不一樣,有快有慢,消費者可以自己決定消費緩沖區中的數據;
單機可用queue(內建模塊)構建進程內的隊列,滿足多個線程間的生產消費需要;
大型系統可使用第三方消息中間件,rabbitmq、rocketmq、kafka;
?
queue模塊:
queue.Queue(maxsize=0),queue提供了一個FIFO先進先出的隊列Queue,創建FIFO隊列,返回Queue對象;maxsize <= 0,隊列長度沒有限制;
?
q = queue.Queue()
?
q.get(block=True,timeout=None),從隊列中移除元素并返回這個元素,只要get過即拿走就沒了;
block阻塞,timeout超時;
若block=True,是阻塞,timeout=None,就是一直阻塞,timeout有值,即阻塞到一定秒數拋Empty異常;
若blcok=False,是非阻塞,timeout將被忽略,要么成功返回一個元素,要么拋Empty異常;
?
q.get_nowait(),等價于q.get(block=False)或q.get(False),即要么成功返回一個元素,要么拋Empty異常;這種阻塞效果,要多線程中舉例;
?
q.put(item,block=True,timeout=None),把一個元素加入到隊列中去,
block=True,timeout=None,一直阻塞直至有空位放元素;
block=True,timeout=5,阻塞5秒拋Full異常;
block=False,timeout失效,立即返回,能塞進去就塞,不能則拋Full異常;
?
q.put_nowait(item),等價于q.put(item,False);
?
注:
Queue的長度是個近似值,不準確,因為生產消費一直在進行;
q.get(),只要get過,即拿走,數據就沒了;而kafka中,拿走數據后,kafka中仍保留有,由consumer來清理;
?
例:
from queue import Queue
import random
?
q = Queue()
?
q.put(random.randint(1,100))
q.put(random.randint(1,100))
?
print(q.get())
print(q.get())
# print(q.get())?? #block
print(q.get(timeout=3))
輸出:
2
35
Traceback (most recent call last):
? File "/home/python/magedu/projects/cmdb/queue_Queue.py", line 12, in <module>
??? print(q.get(timeout=3))
? File "/ane/python3.6/lib/python3.6/queue.py", line 172, in get
? ??raise Empty
queue.Empty
?
分發器的實現:
生產者(數據源)生產數據,緩沖到消息隊列中;
數據處理流程:數據加載-->提取-->分析(滑動窗口函數);
?
處理大量數據時,對于一個數據源來說,需要多個消費者處理,但如何分配數據?
需要一個分發器(調度器),把數據分發給不同的消費者處理;
每一個消費者拿到數據后,有自己的處理函數,所以要有一種注冊機制;
數據加載-->提取-->分發-->分析函數1|分析函數2,一個數據通過分發器,發送給n個消費者,分析函數1|分析函數2為不同的handler,不同的窗口寬度,間隔時間;
?
如何分發?
一對多,副本發送(一個數據通過分發器,發送到n個消費者),用輪詢;
?
MQ?
在生產者和消費者之間用消息隊列,那么所有的消費者共用一個消息隊列?(這需要解決爭搶的問題);還是各自擁有一個消息隊列?(較容易);
?
注冊?
在調度器內部記錄有哪些消費者,記錄消費者自己的隊列;
?
線程?
由于一條數據會被多個不同的注冊過的handler處理,所以最好的方式是多線程;
注:
import threading
t = threading.Thread(target=window,args=(src,handler,width,interval))?? #target,線程中運行的函數,args,這個函數運行時需要的實參用tuple
t.start()
?
分析功能:
分析日志很重要,通過海量數據的分析就能知道是否遭受了***,是否是爬取的高峰期,是否有盜鏈;
分析的邏輯放到handler中;
window僅通過時間窗口挪動取數據,不要將其的功能做的豐富全面,若需統一處理,獨立出單獨的函數;
?
注:
爬蟲:baiduspider,googlebot,SEO,http,request,response;
?
狀態碼分析:
狀態碼中包含了很多信息;
304,服務器收到客戶端提交的請求數,發現資源未變化,要求browser使用靜態資源的緩存;
404,server找不到請求的資源;
304占比大,說明靜態緩存效果明顯;
404占比大,說明出現了錯誤鏈接,或深度嗅探網站資源;
若400,500占比突然開始增大,網站一定出問題了;
?
import datetime
import re
from queue import Queue
import threading
?
# logs = '''123.125.71.36 - - [06/Apr/2017:18:09:25 +0800] "GET / HTTP/1.1" 200 8642 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"'''
?
ops = {
??? 'datetime': lambda timestr: datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z'),
??? 'status': int,
??? 'length': int
}
?
pattern = '''(?P<remote>(?:\d{1,3}\.){3}\d{1,3}) - - \[(?P<datetime>[/:+ \w]+)\] "(?P<method>\w+) (?P<request>\S+) (?P<protocol>[/\.\w\d]+)" (?P<status>\d+) (?P<length>\d+) .+ "(?P<useragent>.+)"'''
?
regex = re.compile(pattern)
?
def extract(line)->dict:
??? matcher = regex.match(line)
??? info = None
??? if matcher:
??????? info = {k:ops.get(k,lambda x:x)(v) for k,v in matcher.groupdict().items()}
??? return info
?
# print(extract(logs))
?
def load(path:str):
??? with open(path) as f:
??????? for line in f:
??????????? d = extract(line)
??????????? if d:
??????????????? yield d
??????????? else:
??????????????? continue
?
# g = load('access.log')
# print(next(g))
# print(next(g))
# print(next(g))
?
# for i in g:
#???? print(i)
?
# def window(src,handler,width:int,interval:int):
#???? # src = {'remote': '112.64.118.97', 'datetime': datetime.datetime(2017, 4, 6, 19, 13, 59, tzinfo=datetime.timezone(datetime.timedelta(0, 28800))), 'method': 'GET', 'request': '/favicon.ico', 'protocol': 'HTTP/1.1', 'status': 200, 'length': 4101, 'useragent': 'Dalvik/2.1.0 (Linux; U; Android 5.1.1; SM-G9250 Build/LMY47X)'}
#???? start = datetime.datetime.strptime('1970/01/01 01:01:01 +0800','%Y/%m/%d %H:%M:%S %z')
#???? current = datetime.datetime.strptime('1970/01/01 01:01:02 +0800','%Y/%m/%d %H:%M:%S %z')
#???? seconds = width - interval
#???? delta = datetime.timedelta(seconds)
#???? buffer = []
#
#???? for x in src:
#???????? if x:
#???????????? buffer.append(x)
#??????????? ?current = x['datetime']
#???????? if (current-start).total_seconds() >= interval:
#???????????? ret = handler(buffer)
#???????????? # print(ret)
#???????????? start = current
#???????????? # tmp = []
#???????????? # for i in buffer:
#???????????? #???? if i['datetime'] > current - delta:
#???????????? #???????? tmp.append(i)
#???????????? buffer = [i for i in buffer if i['datetime'] > current - delta]
?
# window(load('access.log'),donothing_handler,8,5)
# window(load('access.log'),donothing_handler,10,5)
# window(load('access.log'),donothing_handler,5,5)
?
def window(src:Queue,handler,width:int,interval:int):
??? # src = {'remote': '112.64.118.97', 'datetime': datetime.datetime(2017, 4, 6, 19, 13, 59, tzinfo=datetime.timezone(datetime.timedelta(0, 28800))), 'method': 'GET', 'request': '/favicon.ico', 'protocol': 'HTTP/1.1', 'status': 200, 'length': 4101, 'useragent': 'Dalvik/2.1.0 (Linux; U; Android 5.1.1; SM-G9250 Build/LMY47X)'}
??? start = datetime.datetime.strptime('1970/01/01 00:01:01 +0800','%Y/%m/%d %H:%M:%S %z')
??? current = datetime.datetime.strptime('1970/01/01 01:01:02 +0800','%Y/%m/%d %H:%M:%S %z')
??? delta = datetime.timedelta(width-interval)
??? buffer = []
?
??? while True:
??????? data = src.get()
??????? if data:
??????????? buffer.append(data)
??????????? current = data['datetime']
??????? if (current-start).total_seconds() >= interval:
??????????? ret = handler(buffer)
??????????? # print(ret)
??????????? start = current
??????????? buffer = [i for i in buffer if i['datetime'] > current - delta]
?
def donothing_handler(iterable:list):
??? print(iterable)
??? return iterable
?
def handler(iterable:list):
??? pass?? #TODO
?
def size_handler(iterable:list):
??? pass?? #TODO
?
def status_handler(iterable:list):
??? d = {}
??? for item in iterable:
??????? key = item['status']
??????? if key not in d.keys():
??????????? d[key] = 0
??????? d[key] += 1
??? total = sum(d.values())
??? print({k:v/total*100 for k,v in d.items()})?? #return
?
def dispatcher(src):
??? queues = []
??? threads = []
??? def reg(handler,width,interval):
??????? q = Queue()
??????? queues.append(q)
??????? t = threading.Thread(target=window,args=(q,handler,width,interval))
??????? threads.append(t)
??? def run():
??????? for t in threads:
??????????? t.start()
??????? for x in src:
??????????? for q in queues:
??????????????? q.put(x)
??? return reg,run
?
reg,run = dispatcher(load('access.log'))
reg(status_handler,8,5)
run()
?
?
?
日志文件加載:
改為接受一批;
如果一批路徑,迭代每一個路徑;
如果路徑是一個普通文件,按行讀取內容(假設是日志文件);
如果路徑是一個目錄,就遍歷路徑下的所有普通文件,每一個文件按行處理,不遞歸處理子目錄;
?
def openfile(path:str):
??? with open(path) as f:
??????? for line in f:
??????????? d = extract(line)
??????????? if d:
??????????????? yield d
??????????? else:
??????????????? continue
?
def load(*paths):
??? for file in paths:
??????? p = Path(file)
??????? if not p.exists():
??????????? continue
??????? if p.is_dir():
??????????? for x in p.iterdir():
??????????????? if x.is_file():
??????????????????? # for y in openfile(str(x)):
??????????????????? #?? ??yield y
??????????????????? yield from openfile(str(x))
??????? elif p.is_file():
??????????? # for y in openfile(str(p)):
??????????? #???? yield y
??????????? yield from openfile(str(p))
?
離線日志分析項目:
可指定文件或目錄,對日志進行數據分析;
分析函數可動態注冊;
數據可分發給不同的分析處理程序處理;
?
關鍵步驟:
數據源處理(處理一行行數據);
拿到數據后的處理(作為分析,一小批一小批處理,窗口函數);
分發器(生產者和消費者間作為橋梁作用);
?
?
?
瀏覽器分析:
useragent,指軟件按一定的格式向遠端服務器提供一個標記自己的字符串;
在http協議中,使用user-agent字段傳送一這個字符串,這個值可被修改(想偽裝誰都可以);
格式:([platform details]) [extensions]
例如:"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.72 Safari/537.36"
?
注:
chrome-->console,navigator.userAgent,將內容復制粘貼到傲游的自定義UserAgent中;
?
信息提取模塊:
user-agents、pyyaml、ua-parser;
]$ pip install user-agents pyyaml ua-parser
?
例:
from user_agents import parse
?
u = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.72 Safari/537.36'
ua = parse(u)
?
print(ua.browser)
print(ua.browser.family)
print(ua.browser.version_string)
輸出:
Browser(family='Chrome', version=(28, 0, 1500), version_string='28.0.1500')
Chrome
28.0.1500
?
整合,完整代碼:
import datetime
import re
from queue import Queue
import threading
from pathlib import Path
from user_agents import parse
from collections import defaultdict
?
# logs = '''123.125.71.36 - - [06/Apr/2017:18:09:25 +0800] "GET / HTTP/1.1" 200 8642 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"'''
?
ops = {
??? 'datetime': lambda timestr: datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z'),
??? 'status': int,
??? 'length': int,
??? 'request': lambda request: dict(zip(('method','url','protocol'),request.split())),
??? 'useragent': lambda useragent: parse(useragent)
}
?
# pattern = '''(?P<remote>(?:\d{1,3}\.){3}\d{1,3}) - - \[(?P<datetime>[/:+ \w]+)\] "(?P<method>\w+) (?P<request>\S+) (?P<protocol>[/\.\w\d]+)" (?P<status>\d+) (?P<length>\d+) .+ "(?P<useragent>.+)"'''
pattern = '''(?P<remote>(?:\d{1,3}\.){3}\d{1,3}) - - \[(?P<datetime>[/:+ \w]+)\] "(?P<method>\w+) (?P<url>\S+) (?P<protocol>[/\.\w\d]+)" (?P<status>\d+) (?P<length>\d+) .+ "(?P<useragent>.+)"'''
?
regex = re.compile(pattern)
?
def extract(line)->dict:
??? matcher = regex.match(line)
??? info = None
??? if matcher:
??????? info = {k:ops.get(k,lambda x:x)(v) for k,v in matcher.groupdict().items()}
??? # print(info)
??? return info
?
# print(extract(logs))
?
# def load(path:str):
#???? with open(path) as f:
#???????? for line in f:
#???????????? d = extract(line)
#???????????? if d:
#???????????????? yield d
#???????????? else:
#???????????????? continue
?
def openfile(path:str):
??? with open(path) as f:
??????? for line in f:
??????????? d = extract(line)
??????????? if d:
??????????????? yield d
??????????? else:
??????????????? continue
?
def load(*paths):
??? for file in paths:
??????? p = Path(file)
??????? if not p.exists():
??????????? continue
??????? if p.is_dir():
??????????? for x in p.iterdir():
??????????????? if x.is_file():
??????????????????? # for y in openfile(str(x)):
??????????????????? #?? ??yield y
??????????????????? yield from openfile(str(x))
??????? elif p.is_file():
??????????? # for y in openfile(str(p)):
??????????? #???? yield y
??????????? yield from openfile(str(p))
?
# g = load('access.log')
# print(next(g))
# print(next(g))
# print(next(g))
?
# for i in g:
#???? print(i)
?
# def window(src,handler,width:int,interval:int):
#???? # src = {'remote': '112.64.118.97', 'datetime': datetime.datetime(2017, 4, 6, 19, 13, 59, tzinfo=datetime.timezone(datetime.timedelta(0, 28800))), 'method': 'GET', 'request': '/favicon.ico', 'protocol': 'HTTP/1.1', 'status': 200, 'length': 4101, 'useragent': 'Dalvik/2.1.0 (Linux; U; Android 5.1.1; SM-G9250 Build/LMY47X)'}
#???? start = datetime.datetime.strptime('1970/01/01 01:01:01 +0800','%Y/%m/%d %H:%M:%S %z')
#???? current = datetime.datetime.strptime('1970/01/01 01:01:02 +0800','%Y/%m/%d %H:%M:%S %z')
#???? seconds = width - interval
#???? delta = datetime.timedelta(seconds)
#???? buffer = []
#
#???? for x in src:
#???????? if x:
#???????????? buffer.append(x)
#???????????? current = x['datetime']
#???????? if (current-start).total_seconds() >= interval:
#???????????? ret = handler(buffer)
#???????????? # print(ret)
#???????????? start = current
#???????????? # tmp = []
#???????????? # for i in buffer:
#?? ??????????#???? if i['datetime'] > current - delta:
#???????????? #???????? tmp.append(i)
#???????????? buffer = [i for i in buffer if i['datetime'] > current - delta]
?
# window(load('access.log'),donothing_handler,8,5)
# window(load('access.log'),donothing_handler,10,5)
# window(load('access.log'),donothing_handler,5,5)
?
def window(src:Queue,handler,width:int,interval:int):
??? # src = {'remote': '112.64.118.97', 'datetime': datetime.datetime(2017, 4, 6, 19, 13, 59, tzinfo=datetime.timezone(datetime.timedelta(0, 28800))), 'method': 'GET', 'request': '/favicon.ico', 'protocol': 'HTTP/1.1', 'status': 200, 'length': 4101, 'useragent': 'Dalvik/2.1.0 (Linux; U; Android 5.1.1; SM-G9250 Build/LMY47X)'}
??? start = datetime.datetime.strptime('1970/01/01 00:01:01 +0800','%Y/%m/%d %H:%M:%S %z')
??? current = datetime.datetime.strptime('1970/01/01 01:01:02 +0800','%Y/%m/%d %H:%M:%S %z')
??? delta = datetime.timedelta(width-interval)
??? buffer = []
?
??? while True:
??????? data = src.get()
??????? if data:
??????????? buffer.append(data)
??????????? current = data['datetime']
??????? if (current-start).total_seconds() >= interval:
?????? ?????ret = handler(buffer)
??????????? # print(ret)
??????????? start = current
??????????? buffer = [i for i in buffer if i['datetime'] > current - delta]
?
def donothing_handler(iterable:list):
??? print(iterable)
??? return iterable
?
def handler(iterable:list):
??? pass?? #TODO
?
def size_handler(iterable:list):
??? pass?? #TODO
?
def status_handler(iterable:list):
??? d = {}
??? for item in iterable:
??????? key = item['status']
??????? if key not in d.keys():
??????????? d[key] = 0
??????? d[key] += 1
??? total = sum(d.values())
??? print({k:v/total*100 for k,v in d.items()})?? #return
?
browsers = defaultdict(lambda :0)
def browser_handler(iterable:list):
??? # browsers = {}
??? for item in iterable:
??????? ua = item['useragent']
??????? key = (ua.browser.family,ua.browser.version_string)
??????? # browsers[key] = browsers.get(key,0) + 1
??????? browsers[key] += 1
??? return browsers
?
def dispatcher(src):
??? queues = []
??? threads = []
??? def reg(handler,width,interval):
??????? q = Queue()
??????? queues.append(q)
??????? t = threading.Thread(target=window,args=(q,handler,width,interval))
??????? threads.append(t)
??? def run():
??????? for t in threads:
??????????? t.start()
??????? for x in src:
??????????? for q in queues:
??????????????? q.put(x)
??? return reg,run
?
reg,run = dispatcher(load('access.log'))
reg(status_handler,8,5)
reg(browser_handler,5,5)
run()
print(browsers)
?
?
?
?
?
?
?
?
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





