溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關jupyter中讀取錯誤格式文件如何解決,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
使用pandas讀取xml文件報錯
“ Unsupported format, or corrupt file: Expected BOF record; found b'<?xml ve' ”
轉換文件格式,使用excel打開xml文件 選擇:文件—>另存為---->彈框
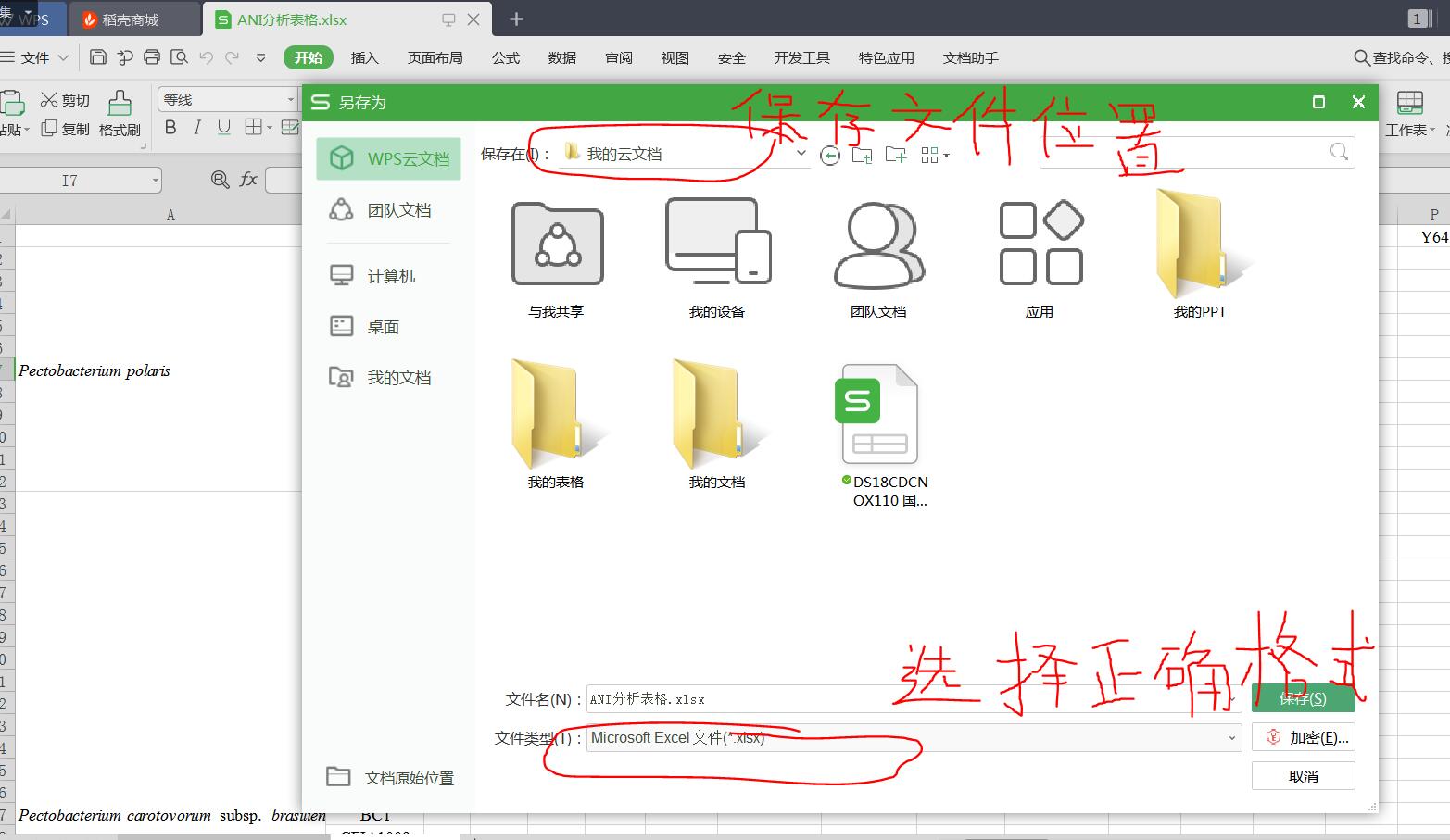
保存以后,再次用pandas讀取對應格式的文件讀取即可
補充:
在jupyter中讀取CSV文件時出現‘utf-8' codec can't decode byte 0xd5 in position 0: invalid continuation byte解決方法
導入 import pandas as pd
使用pd.read_csv()讀csv文件時,出現如下錯誤:
UnicodeDecodeError: ‘utf-8' codec can't decode byte 0xd5 in position 0: invalid continuation byte
CSV文件不是UTF-8進行編碼,而是用gbk進行編碼的。jupyter-notebook使用的Python解釋器的系統編碼默認使用UTF-8.
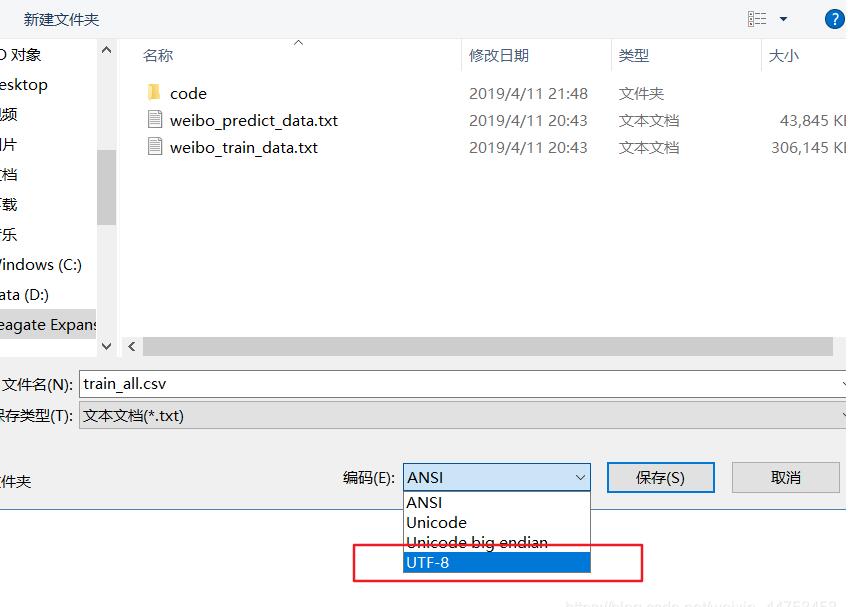
1.找到使用的csv文件--->鼠標右鍵--->打開方式---->選擇記事本
2.打開文件選擇“文件”----->"另存為“,我們可以看到默認編碼是:ANSI,選擇UTF-8重新保存一份,再使用pd.read_csv()打開就不會保存了

使用pd.read()讀取CSV文件時,進行編碼
pd.read(filename,encoding='gbk')
比如:

以上就是jupyter中讀取錯誤格式文件如何解決,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





