溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
因為TCP/IP協議只支持字節數組的傳輸,不能直接傳對象。對象序列化的結果一定是字節數組!當兩個進程在進行遠程通信時,彼此可以發送各種類型的數據。無論是何種類型的數據,都會以二進制序列的形式在網絡上傳送。發送方需要把這個對象轉換為字節序列,才能在網絡上傳送;接收方則需要把字節序列再恢復為對象。
序列化(serialization):及有序的列,數據轉換成二進制的有序的過程
協議:規定序列化和反序列化的轉換方式及就是把數據保存成二進制存儲起來,其是定義的規則,其規則稱為協議如果規定了協議,則可以進行序列化和反序列化,其協議是由版本的,約定協議后進行處理反序列化(deserialization):將有序的二進制序列轉換成某種對象(字典,列表等)稱為反序列化
持久化:序列化保存到文件就是持久化,序列化未必會持久化,序列化往往是傳輸或存儲。可以將數據序列化后持久化,或者網絡傳輸,也可以將從文件或網絡接受到的字節序列反序列化。
pickle python中的序列化,反序列化模塊,其局限是僅限于傳輸的兩端都是python的情況,且盡量保持兩端的版本一致
dumps 對象序列化,在內存中
dump 對象序列化到文件對象,就是存入文件
loads 對象反序列化
load 對象反序列化,從文件中讀取數據
#!/usr/local/bin/python3.6
#coding:utf-8
from pickle import *
from pathlib import Path
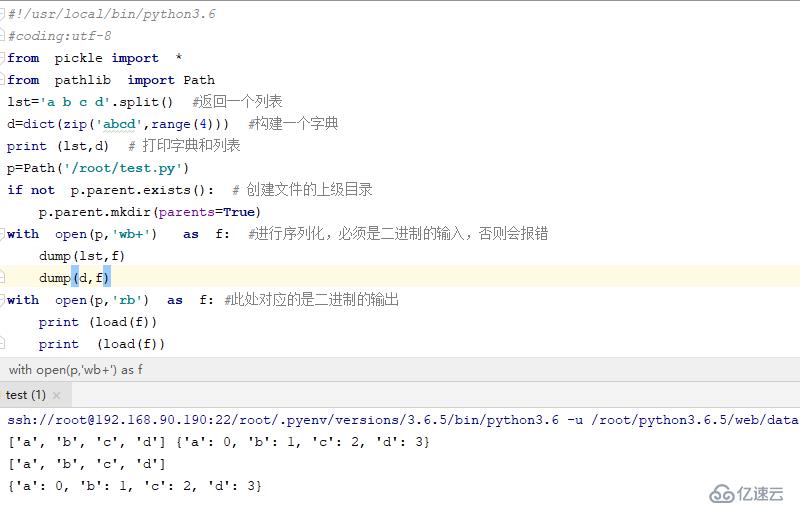
lst='a b c d'.split() #返回一個列表
d=dict(zip('abcd',range(4))) #構建一個字典
print (lst,d) # 打印字典和列表
p=Path('/root/test.py')
if not p.parent.exists(): # 創建文件的上級目錄
p.parent.mkdir(parents=True)
with open(p,'wb+') as f: #進行序列化,必須是二進制的輸入,否則會報錯
dump(lst,f)
dump(d,f)
with open(p,'rb') as f: #此處對應的是二進制的輸出
print (load(f))
print (load(f))結果如下
#!/usr/local/bin/python3.6
#coding:utf-8
from pickle import *
from pathlib import Path
d=dict(zip('mysql',range(5)))
s=dumps(d) #進行序列化
print (s) # 正常情況的輸出
print (loads(s)) # 進行反序列化并輸出結果如下 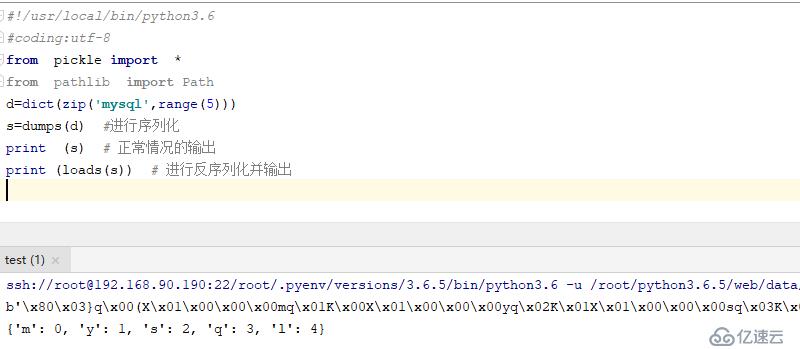
切換3.5環境進行查看處理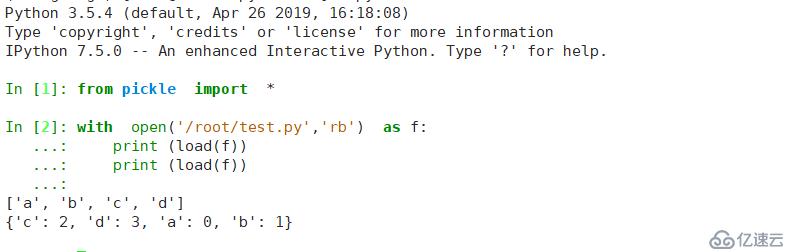
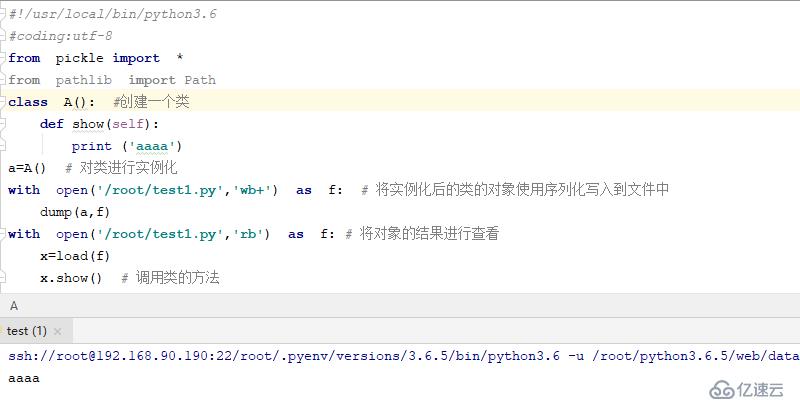
對類的處理
#!/usr/local/bin/python3.6
#coding:utf-8
from pickle import *
from pathlib import Path
class A(): #創建一個類
def show(self):
print ('aaaa')
a=A() # 對類進行實例化
with open('/root/test1.py','wb+') as f: # 將實例化后的類的對象使用序列化寫入到文件中
dump(a,f)
with open('/root/test1.py','rb') as f: # 將對象的結果進行查看
x=load(f)
x.show()結果如下

#!/usr/local/bin/python3.6
#coding:utf-8
from pickle import *
from pathlib import Path
class A(): #創建一個類
def show(self):
print ('aaaa')
print ('bbbbb')
a=A() # 對類進行實例化
with open('/root/test1.py','wb+') as f: # 將實例化后的類的對象使用序列化寫入到文件中
dump(a,f)
with open('/root/test1.py','rb') as f: # 將對象的結果進行查看
x=load(f)
x.show() # 調用類的方法查看結果 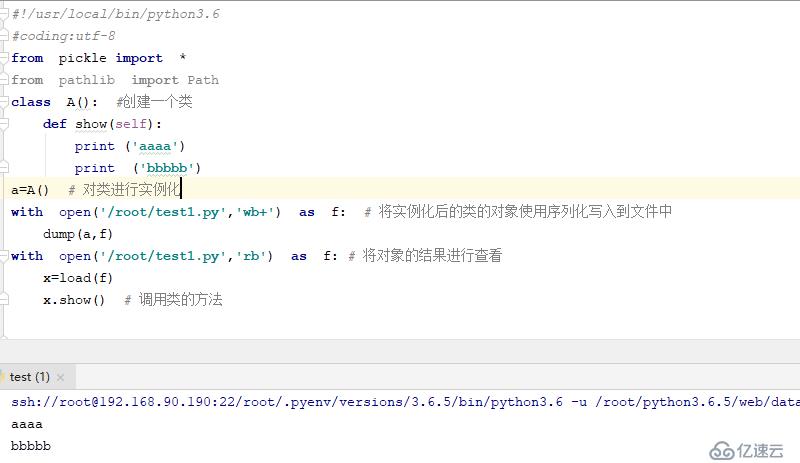
寫入的數據如下
此處寫入的數據未發生改變,但其在類中增加了數據,此處記錄的是模塊名和類名。若在不同的平臺進行操作,則會報錯
切換3.5環境,報錯,因為其中沒有這個test的模塊名沒有對應的classA,因此會報錯。
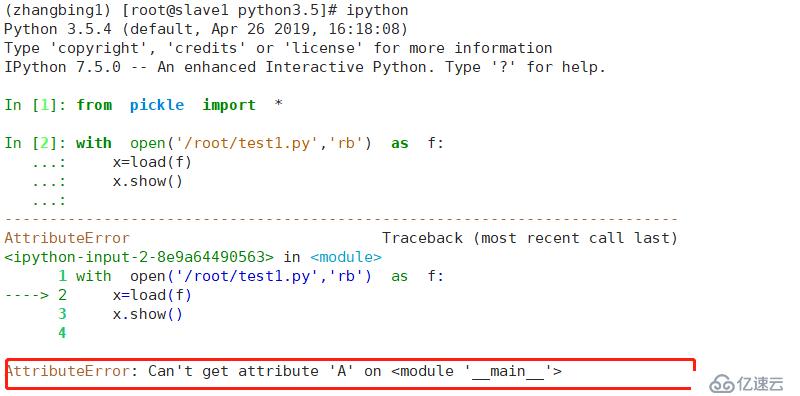
對象序列化
#!/usr/local/bin/python3.6
#coding:utf-8
from pickle import *
from pathlib import Path
class A(): #創建一個類
def __init__(self): #對類進行初始化的操作,及就是在對象賦值時,此類會被帶入其中
self.tttt='abcdf'
a=A() # 對類進行實例化
with open('/root/test1.py','wb+') as f: # 將實例化后的類的對象使用序列化寫入到文件中
dump(a,f)
with open('/root/test1.py','rb') as f: # 將對象的結果進行查看
x=load(f)
print (x.tttt) # 調用類的方法查看如下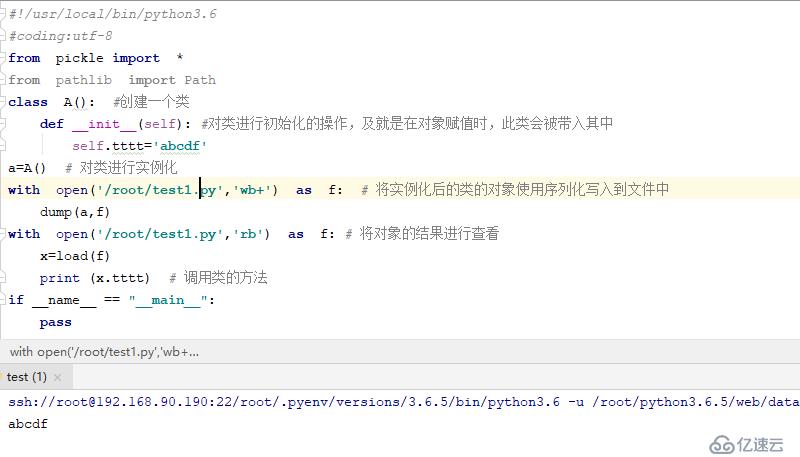
查看寫入數據,其發生了變化
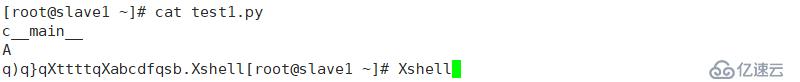
但其切換環境,還是不能找到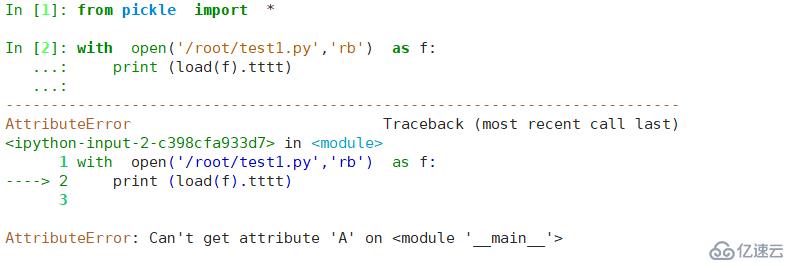
RPC 雛形:
遠程過程調用: 及遠程調用某個模塊的函數來實現其過程的調用 ,必須要保證遠程的函數和本地需要的函數一致并且必須存在,否則會報錯
通過網絡傳輸,不需要持久化,進行類的一致性
對于非自定義類,兩邊一致,不需要,若是自定義類,則需要兩端保持一致
應用:
本地序列化的情況,應用較少
一般來說,大多數應用場景在網絡中,將數據序列化后通過網絡傳輸到遠程結點,遠程服務器上的服務接受到數據后進行反序列化,就可以使用了。
但是,需要注意的是,遠端接受端,反序列化時必須有對應的數據類型,否則就會報錯,尤其是自定義類,必須遠程存在
目前,大多數項目都不是單機,不是單服務,需要通過網絡將數據傳送到其他結點上,這就需要大量的序列化,反序列化。
但是python程序之間還可以使用pickple解決序列化,反序列化,如果是跨平臺,跨語言,跨協議pickle就不適合了,就需要公共協議,如XML/Json /protocol Buffer等。
每種協議都有自己的負載,其所使用的場景都不一樣,二進制的操作不一定適用于所有的場景。但越是底層的協議,越需要二進制傳輸
JSON(JavaScript object notation,JS 對象標記)是一種輕量級的數據交換格式,它基于ECMAscript(w3c制定的JS規范)的一個子集,采用完全獨立于編程語言的文本格式來存儲和表示數據
其key必須是字符串,其值可以是下面類型
雙引號引起來的字符串,數值,true和false,null(None),對象(字典),數組(列表)這些都是值
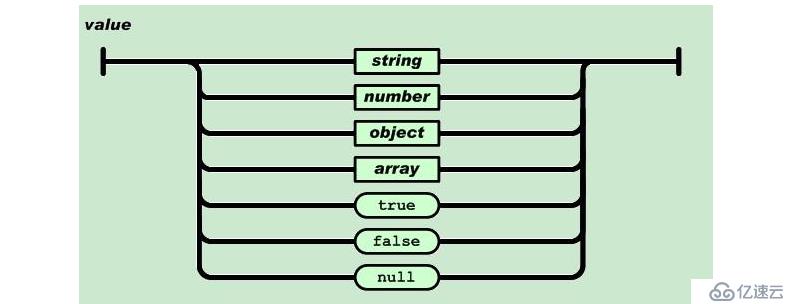
此處表示了JSON值支持的數據類型
1 string:
字符串,由雙引號包圍起來的任意字符的組合,可以有轉義字符
2 number :
數值,有正負數,整數,浮點數
3 對象:
無序的鍵值對集合
格式:{key1:value1,...keyn:valuen}
key 必須是字符串,需要使用雙引號包圍這個字符串,value可以是任意合法的值
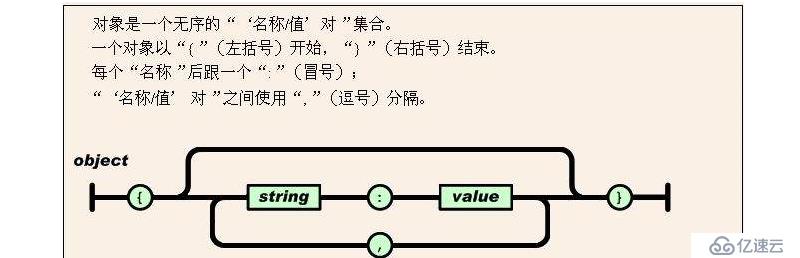
其表示要么是{},要么有key,value,若key:value完成,則后面不能有逗號,一旦有逗號,則表示后面還有數據
4 數組 :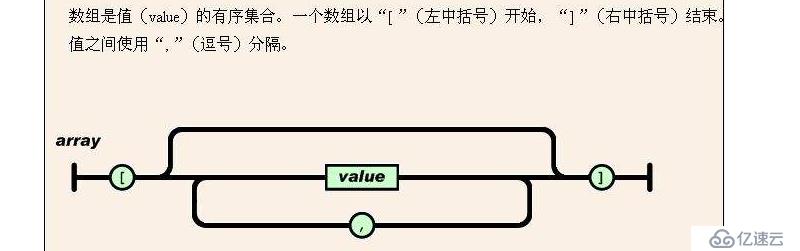
同上,一旦有逗號,則表示后面還有數據
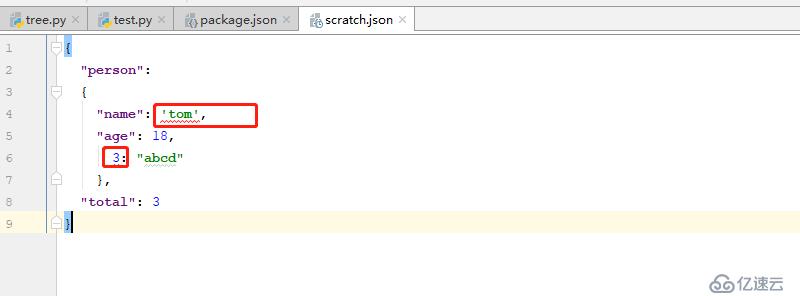
此處的問題是,其json文件的鍵是非字符串,其值的字符串不是使用雙引號括起來的,因此其會出現報錯的情況
5 null 相當于python的None
6 布爾型 false(False) true(True)
dumps json 編碼
dump json 編碼并存入文件
loads json 解碼
load json 解碼,從文件讀取數據
#!/usr/local/bin/python3.6
#coding:utf-8
from json import *
d={'a':1,'b':{'c':{'d':[1,23,4,5]}},'e':None,'f':True,'g':False} #構造字典
print (d) # 輸出字典
print (dumps(d)) #對字典對象進行序列化
print (loads((dumps(d)))) # 對結果進行反序列化結果如下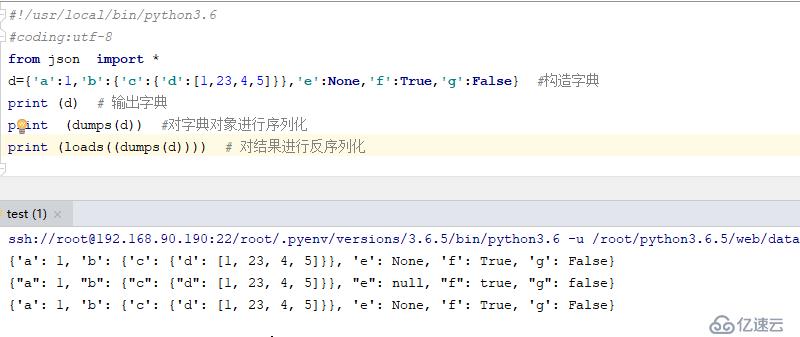
#!/usr/local/bin/python3.6
#coding:utf-8
from json import *
class A(): # 創建一個類
def show(self):
return 'mysql'
print (dumps(A().show())) # 對類進行實例化并調用其方法返回結果進行序列化
print (loads(dumps(A().show()))) # 對其進行反序列化結果如下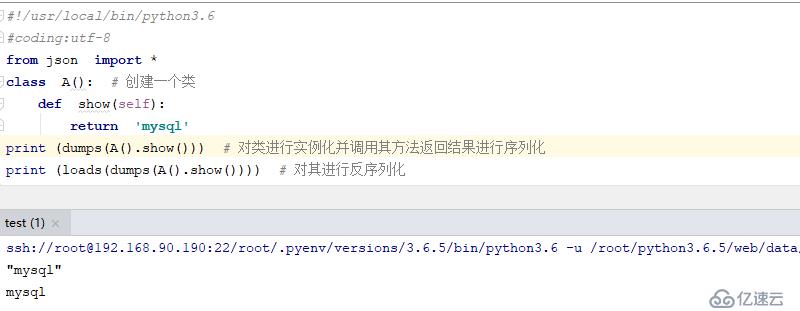
一般的json編碼的數據很少落地,數據都是通過網絡傳輸,傳輸的時候,要考慮壓縮它,本質上來說它就是一個文本,一個字符串,json很廣泛,幾乎所有的編程語言都支持它。
messagepack 是一個基于二進制高效的對象序列化類庫,可用于跨語言通信,其可以像JSON那樣,在許多語言之間交換結構對象,但是其比JSON更快速更輕巧。其支持python,ruby,Java,C/C++等眾多語言,兼容JSON和pickle
pip install msgpack-pythonpackb 序列化對象,提供了dumps來兼容pickle和json
unpackb 反序列化對象,提供了loads來兼容pack序列化對象保存到文件對象,提供了dump來兼容
unpack 反序列化對象保存到文件對象,提供了load來兼容
#!/usr/local/bin/python3.6
#coding:utf-8
from msgpack import *
import sys
d={'a':1234,'b':['abc',{'c':234}],'d':True,'e':False,'f':None} # 構建一個字典
b=packb(d) # 進行序列化操作
print (b) # 打印
print (unpackb(b)) #進行反序列化操作
print (unpackb(b,encoding='utf-8')) #通過制定編碼方式輸出結果如下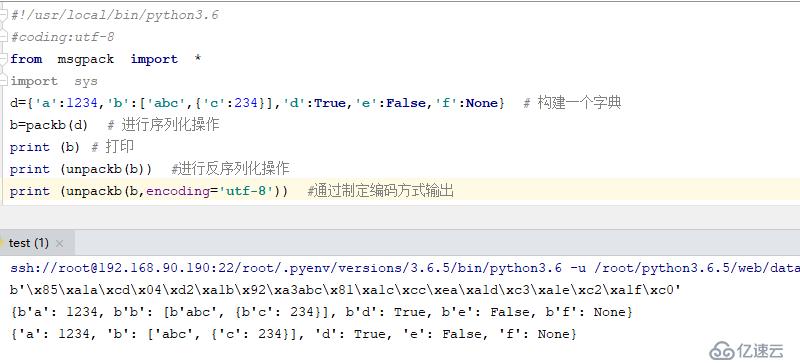
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





