溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了SQLite中如何實現一個查詢規劃器,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
1.0 介紹
查詢規劃器的任務是找到最好的算法或者說“查詢計劃”來完成一條SQL語句。早在SQLite 3.8.0版本,查詢規劃器的組成部分已經被重寫使它可以運行更快并且生成更好的查詢計劃。這種重寫被稱作“下一代查詢規劃器”或者“NGQP”。
這篇文章重新概括了查詢規劃的重要性,提出來一些查詢規劃固有的問題,并且概括了NGQP是如何解決這些問題。
我們知道的是,NGQP(下一代查詢規劃器)幾乎總是比舊版本的查詢規劃器好。然而,也許有的應用程序在舊版本的查詢規劃器中已經不知不覺依賴了一些不確定或者不是很好的特性,這時候將查詢規劃器更新升級到NGQP,這些應用程序可能會導致程序閃退現象。NGQP必須考慮這種風險,提供一系列的檢查項來減小風險和解決可能會引起的問題。
在NGOP上關注此文檔。對于更一般的sqlite查詢規劃器以及涵蓋sqlite整個歷史的概述,請參閱:“sqlite查詢優化程序概述”。
2.0 背景
對于用簡單的幾個指數對單個表的查詢,通常會有一個明顯的最佳的算法選擇。但是對于更大更復雜的查詢,諸如眾多指數與子查詢的多路連接,對于計算結果,可能有數百,數千或者數百萬的合理算法。如此查詢規劃的工作是選擇一個單一的“最好”的有眾多可能性的查詢計劃。
查詢規劃器是什么使得SQL數據庫引擎變得如此驚人的有用與強大。(這是真正的所有的sql數據庫引擎,不只是sqlite。)查詢規劃器使得編程人員從苦差事中選擇一個特定的查詢計劃之中釋放出來。從而允許程序員在更高級別的應用問題里和向最終端用戶提供更多的價值之上可以關注更多的心理能量。對于簡單的查詢,查詢計劃的選擇是顯而易見的,雖然是方便的,但并不是很重要的。但是作為應用程序,架構與查詢將會變得越來越復雜化。一個聰明的查詢規劃可以大大地加速和簡化應用程序開發的工作。它告訴數據庫引擎有什么內容需求是有著驚人的力量的,然后,讓數據庫引擎找出最好的辦法檢索那些內容。
寫一個好的查詢規劃器是藝術多于科學。查詢規劃器必須要有不完整的信息。它不能決定將多久采取任何特別的計劃,而實際上無需運行此計劃。因此,當比較兩個或多個計劃時,找出哪些是“最好的”,查詢規劃器會做出一些假設和猜測,那些假設和猜測有時候會出錯。一個好的查詢計劃要求能找到正確的解決方案,而這些問題是程序員很少考慮的。
2.1 sqlite之中的查詢規劃器
sqlite的計算使用嵌套循環聯接,一個循環中每個標的連接(額外的循環可能會在WHERE句子中插入IN和OR運算符。sqlite認為那些考慮太多啦,但為了簡單起見,我們可以在這篇文章之中可以忽略它。)在每次循環時,一個或者更多的指數被使用,并被加速搜索,或者一個循環可能是“全表掃描”讀取表中每一行。因此,查詢規劃分解成兩個子任務:
采摘的各種循環的嵌套順序。
選擇每個循環的良好指數。
采摘嵌套順序一般是更具挑戰性地問題。
一旦建立連接的嵌套順序,每個循環指數的選擇通常是顯而易見的。
2.2 SQLite查詢規劃器穩定性保證
對于給出的任何SQL語句,SQLite 通常情況下會選擇相同的查詢規劃假如:
數據庫的schema沒有明顯的改變,例如添加或刪除索引(indices),
ANALYZE命令沒有返回
SQLite在編譯時沒有使用SQLITE_ENABLE_STAT3或者SQLITE_ENABLE_STAT4,并且
使用相同版本的SQLite
SQLite的穩定性保證意味著你在測試中高效的運行查詢操作,并且你的應用沒有更改schema,那么SQLite不會突然選擇開始使用一個不同的查詢規劃,那樣有可能在你把你的應用發布給用戶之后造成性能問題。如果在實驗室里你的應用是工作的,那它在部署之后同樣可以工作。
企業級的客戶端/服務器SQL數據庫通常不能做這樣的保證。在客戶端/服務器SQL數據庫引擎里,服務器跟蹤統計表的大小和索引(indices)的數量,查詢規劃器根據這些統計信息選擇最優的規劃。一旦在數據庫的內容通過增刪改改變,統計信息的改變有可能引起對于某些特定的查詢,查詢規劃器使用不同的查詢規劃。通常新的規劃對于更改過的數據結構來說更好。但有時新的查詢規劃會導致性能的下降。在使用客戶端/服務器數據庫引擎時,通常會有一個數據庫管理員(DBA)來處理這些罕見的問題。但是DBA們不能在像SQLite這樣的嵌入式數據庫中修復該問題,所以SQLite需要小心的確保查詢規劃在部署之后不會被意外的改變。
SQLite穩定性保證適用于傳統的查詢規劃和NGQP。
需要注意的很重要的一點是SQLite版本的改變可能引起查詢規劃的改變。同版本的SQLite通常會選擇相同的查詢規劃,但是如果你把你的應用重新連接到了不同版本的SQLite上,那么查詢規劃可能會改變。在很罕見的情況下,SQLite版本的改變會引起性能衰減。這是一個你應該考慮把你的應用靜態的連接到SQLite而不是使用一個系統范圍(system-wide)的SQLite共享庫的原因,因為它有可能在你不知情或者不能控制的情況下改變。
3.0 一個棘手的情況
"TPC-H Q8"是一個來自于Transaction Processing Performance Council的測試查詢。查詢規劃器在3.7.17以及之前版本的SQLite中沒有為TPC-H Q8選擇一個好的規劃。并且被認定再怎么調整傳統查詢規劃器也不能修復這個問題。為了給TPC-H Q8查詢尋找一個好的好的解決方案,并且能夠持續的改進SQLite查詢規劃器的質量,我們有必要重新設計查詢規劃器。這個部分將解釋為什么重新設計是有必要的,NGQP有什么不同和設法解決TPC-H Q8問題。
3.1 查詢細節
TPC-H Q8 是一個8路的join。基于以上所看到的,查詢規劃器的主要任務是確定這八次循環最好的嵌套順序,從而將完成join操作的工作量最小化。下圖就是TPC-H Q8例子的簡單模型:
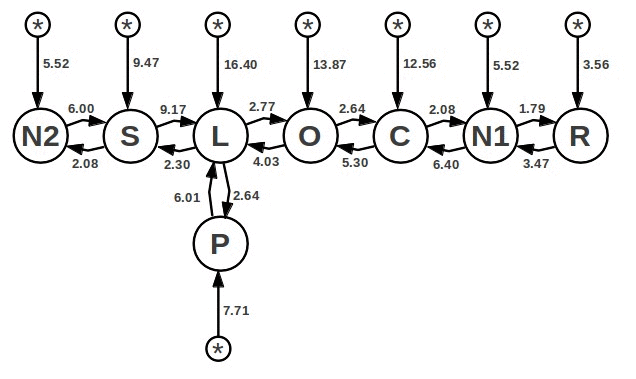
在這個圖表中,在查詢語句中的from從句部分的8個表都被表示成一個大的圓形,并用from從句的名字標識:N2, S, L, P, O, C, N1 和R。圖中的弧線代表計算圓弧起點的表格做外連接所對應的預估開銷。舉個例子,S內連接L的開銷是2.30,S外連接L的開銷是9.17。
這兒的“資源消耗”是通過對數運算算出來的。由于循環是嵌套的,因此總的資源消耗是相乘得到的,而不是相加。通常都認為圖帶的是要累加的權重,然而這兒的圖顯示的是各種資源消耗求對數后的值。上圖顯示S位于L內部要少消耗大約6.87,轉換后就是S循環位于L循環內部的查詢比S循環位于L循環外部的查詢要運行快大約963倍。
從標記為“*”的小圓圈開始的箭頭表示單獨運行每個循環所消耗的資源。外循環一定消耗的是“*”所消耗資源。內循環可以選擇消耗"*"所消耗的資源,或者選擇其余項中的一個為外部循環所消耗的資源,無論選擇哪個都是為了得到最低的資源消耗。你可以把“*”所消耗的資源看作是圖中其他節點中的任意一個到當前節點的多個弧線的簡寫表示。因此說這樣的圖是“完整的”,也就是說圖中的每一對節點間都有兩個方向的弧線(一些是非常明顯的,一些則是隱含的)。
尋找最佳查詢規劃的問題就等同于尋找圖中訪問每個節點僅僅一次的最小消耗路徑。
(附注:TPC-H Q8圖里的資源消耗的評估是由SQLite 3.7.16里的 查詢規劃器計算,并使用自然對數轉換得來的 。)
3.2 復雜性
上面所展示的查詢規劃器問題是簡化版的。資源的消耗可以估計出來。我們只有實際運行了循環之后才能知道運行這個循環真正的資源消耗是多少 。SQLite是根據WHERE子句的約束和可以使用的索引來估計運行循環的資源消耗的。這樣的估計通常都八九不離十,不過有時候估計的結果卻脫離現實。使用ANALYZE命令收集數據庫的其他統計信息有時候可以讓SQLite對消耗的資源的評估更準確。
消耗的資源是由多個數字組成的,而不是像上圖一樣只是有一個單獨的數字組成。SQLite針對每個循環的不同階段計算出幾個不同的評估的消耗的資源。例如 ,“初始化”資源耗費僅僅發生在查詢啟動的哪個時候。初始化消耗的資源是對沒有索引的表進行自動索引所消耗的資源 。接著是運行循環的每一步所消耗的資源。最后評估循環自動生成的行數,行數是評估內循環所消耗資源所必需的信息。如果查詢含有ORDER BY子句,那么排序所消耗的資源也要考慮。
常用的查詢里的依賴并不一定在一個單獨的循環上,因此依賴的模型可能無法用圖來表示。例如,WHERE子句的約束之一可能是S.a=L.b+P.c,這就隱含地說S循環一定是L和P的內循環。這樣的依賴不可能用圖來表示 ,因為沒有辦法繪出同時從兩個或者兩個以上節點出發的一條弧線。
如果查詢包含有ORDER BY子句或者GROUP BY子句,或者查詢使用了DISTINCT關鍵字,那么就會自動對行進行排序,形成一個圖,選擇遍歷這個圖的路徑就顯得尤為便利,因此也不需要單獨進行排序了。自動刪除ORDER BY子句可以讓性能有巨大的變化,因此要完成規劃器的完整實現,這也是一個需要考慮的因素。
在TPC-H Q8查詢里,所有的初始化資源消耗是微不足道的,各個節點之前都存在依賴,而且沒有ORDER BY,GROUP BY或者DISTINCT子句。因此,對TPC-H Q8來說,上圖足以表示計算資源消耗所需的東西。通常的查詢可能涉及到許多其他復雜的情形,為了能夠清晰的說明問題,這篇文章的后續部分就忽略了使問題復雜化的許多因素。
3.3 尋找最佳查詢規劃
在版本3.8.0之前,SQLite一直使用“最近鄰居” 或者“NN"試探法尋找最佳查詢規劃。NN試探法對圖進行一次單獨的遍歷,總是選擇消耗最低的哪個弧線作為下一步。大多數情況下,NN試探法運行的非常地好。而且,NN試探法也很快,因此SQLite即便是達到64個連接的情況下也能夠快速的找到很好的規劃。與此相反,可以運行更大量搜索的其他數據庫引擎在同一連接中表的數目大于10或者15時就會停止不動。
很不幸,NN試探法對TPC-H Q8所計算出的查詢規劃不是最佳的。由NN試探法計算出的規劃是R-N1-N2-S-C-O-L-P,其資源消耗是36.92。前一句的意思是: R表運行在最外層循環,N1是位于緊接著的內部循環,N2是位于第三個循環,以此類推到P,它位于最內層的循環。遍歷此圖的(由窮舉搜索可得到的)最短路徑是P-L-O-C-N1-R-S-N2,此時的資源耗費是27.38。差異看起來似乎并不大,不過,要記得消耗的資源是經過對數運算計算出來的,因此最短路徑比由NN試探法得出的路徑快幾乎750倍。
這個問題的一個解決方法就是更改SQLite,讓它使用窮舉搜索獲取最佳路徑。然而,窮舉搜索所需要的時間與K成正比!(K是連接涉及的表數目),因此當有10個以上的連接的時候,運行sqlite3_prepare()所耗費的時間丟非常大。
3.4 N個最近鄰居試探法或者"N3"試探法
下一代查詢規劃器使用新的試探法查找遍歷圖的最佳路徑:"N個最近鄰居試探法"(后面就叫"N3")。用N3的話,每一步就不是僅僅選擇一個最近鄰居,N3算法在每一步要跟蹤N個最佳路徑,這兒N是個小整數。
假設N=4,那么對TPC-H Q8圖來說 ,第一步找到可訪問任何單個節點的四個最短路徑:
R (cost: 3.56)
N1 (cost: 5.52)
N2 (cost: 5.52)
P (cost: 7.71)
第二步找到以前一步找到的四個最短路徑之一開始的可訪問兩個節點的四個最短路徑。這種情況下,兩個或者兩個以上的路徑是可以的(這樣的路徑具有相同的可訪問的節點集,可能順序不同),只要記住是必須保持第一步的路徑和最低資源消耗路徑就可以。我們找到以下路徑:
R-N1 (cost: 7.03)
R-N2 (cost: 9.08)
N2-N1 (cost: 11.04)
R-P {cost: 11.27}
第三步以可訪問兩個節點四個最短路徑為起點,找到可訪問三個節點的四個最短路徑:
R-N1-N2 (cost: 12.55)
R-N1-C (cost: 13.43)
R-N1-P (cost: 14.74)
R-N2-S (cost: 15.08)
以此類推。TPC-H Q8查詢有8個節點,因此如此的過程總共重復8次。在通常K個連接的情況下,存儲需求復雜度是O(N),計算的時間復雜度是O(K*N),它明顯比O(2 K)方案快多了。
然而,N選擇哪個值呢?你可以試試N=K,此時這種算法的復雜度是O(K2) ,實際上仍然非常相當快,由于K的最大值為64,而且K很少超過10。不過這仍然不足以解決TPC-H Q8問題。如果TPC-H Q8查詢進行時N=8,此時N3算法得到的查詢規劃是R-N1-C-O-L-S-N2-P,此時資源耗費是29.78。這對NN算法進行了很大的改進,不過仍然不是最佳的。當N=10或者更大時,N3才能找到TPC-H Q8查詢的最佳查詢規劃。
下一代查詢規劃的最初實現對簡單查詢選N=1,兩個連接就選N=5,三個或者更多表連接選擇N=10。后續的發布版可能要更改N值得選擇規則。
4.0 升級到下一代查詢規劃器的風險
對大多數應用來說,從舊查詢規劃器升級到下一代查詢規劃器不需要多想,或者不需要花很多功夫就可以做到。只要簡單地把舊的SQLite版本換成較新的SQLite版本,然后重新編譯就行,此時運行應用就會快很多。不需要對復雜過程的API進行更改或者修正。
然而,像其他查詢器更換一樣,升級到下一代查詢規劃器確實可以引起性能下降這樣的小風險。出現這種問題不是因為下一代查詢規劃器不正確、或者說漏洞多,或者說比舊的查詢規劃器差。假若選擇索引的信息確定,那么下一代查詢規劃器總能選擇一個比以前好的或者說更優秀的規劃。存在的問題是某些應用也許使用了低質量的、沒有多少選擇性的索引,而且無法運行ANALYZE。舊的查詢規劃器對每個查詢都查看了許多但比現在要少的可能的查詢實現,因此如果運氣好的話,這樣的規劃器可能就碰到好的規劃。而另一方面,下一代查詢規劃器查看了更多地查詢規劃實現,所以理論上來講,它可能選擇另一個性能更好的查詢規劃,如果此時索引運行良好,而實際運行中性能卻有所下降,那么可能是數據的分布引起的.
技術要點:
只要下一代查詢規劃器可以訪問SQLITE STAT1文件里準確的ANALYZE數據,那么它總是能找到與以前查詢規劃器等同的或者性能更好的查詢規劃。
只要查詢模式不包含最左邊字段具有相同值且有超過10或者20行的索引,那么下一代查詢規劃器總是能找到一個好的查詢規劃。
并不是所有的應用都滿足上面條件。幸運的是,即便不滿足這些條件,下一代查詢規劃器通常仍然能找到好的查詢規劃。不過,性能下降這種情況也有可能出現(不過很少)。
4.1范例分析:升級Fossil使用下一代查詢規器
Fossil DVCS是用來追蹤全部SQLite源代碼的版本控制系統。Fossil軟件倉庫就是一個SQLite數據庫文件。(作為單獨的練習,我們邀請讀者對這種遞歸式的應用查詢規劃器進行深入思考。)Fossil既是SQLite的版本控制系統,也是SQLite的測試平臺。無論什么時候對SQLite進行強化,Fossil都是對這些強化進行測試和評估的首批應用之一。所以Fossil最早采用下一代查詢規劃器。
很不幸,下一代查詢規劃器引起了Fossil性能下降。
Fossil用到許多報表,其中之一就是單個分支上所做更改的時間表,它顯示了這個分支的所有合并和刪除。查看 http://www.sqlite.org/src/timeline?nd&n=200&r=trunk就可以看到時間報表的典型例子。通常生成這樣的報表只需要幾毫秒。然而,升級到下一代查詢規劃器之后,我們發現對倉庫的主干分支生成這樣的報表竟然需要近10秒的時間。
用來生成分支時間表的核心查詢如下。(我們不期望讀者理解這個查詢的細節。下面將給出說明。)
SELECT blob.rid AS blobRid, uuid AS uuid, datetime(event.mtime,'localtime') AS timestamp, coalesce(ecomment, comment) AS comment, coalesce(euser, user) AS user, blob.rid IN leaf AS leaf, bgcolor AS bgColor, event.type AS eventType, (SELECT group_concat(substr(tagname,5), ', ') FROM tag, tagxref WHERE tagname GLOB 'sym-*' AND tag.tagid=tagxref.tagid AND tagxref.rid=blob.rid AND tagxref.tagtype>0) AS tags, tagid AS tagid, brief AS brief, event.mtime AS mtime FROM event CROSS JOIN blob WHERE blob.rid=event.objid AND (EXISTS(SELECT 1 FROM tagxref WHERE tagid=11 AND tagtype>0 AND rid=blob.rid) OR EXISTS(SELECT 1 FROM plink JOIN tagxref ON rid=cid WHERE tagid=11 AND tagtype>0 AND pid=blob.rid) OR EXISTS(SELECT 1 FROM plink JOIN tagxref ON rid=pid WHERE tagid=11 AND tagtype>0 AND cid=blob.rid)) ORDER BY event.mtime DESC LIMIT 200;
這個查詢不是特別復雜,不過,即便這樣,它仍然可以替代上百行,也許是上千行處理過程代碼。這個查詢的要點是:向下掃描EVENT表,查找滿足下列三個條件中任何一個的最新的200條提交記錄:
此提交含有"trunk"標簽。
此提交有個子提交含有“trunk"標簽。
此提交有個父提交含有“trunk"標簽。
第一個條件將顯示所有主干分支上的提交,第二個和第三個條件包含合并到主干分支,或者由主干分支產生的提交。這三個條件是通過在此查詢的WHERE子句中用OR連接三個EXISTS語句實現的。使用下一代查詢規劃器引起的性能下降是由第二個和第三個條件產生的。兩個條件里存在的問題是相同的,因此我們只看第二個條件。第二個條件的子查詢可以重寫為如下語句(把次要的和不重要的進行了簡化):
SELECT 1 FROM plink JOIN tagxref ON tagxref.rid=plink.cid WHERE tagxref.tagid=$trunk AND plink.pid=$ckid;
PLINK表保存著各個提交之間的父子關系。TAGXREF表把標簽映射到提交上。作為參考,對這兩個表進行查詢的模式的相關部分顯示如下:
CREATE TABLE plink( pid INTEGER REFERENCES blob, cid INTEGER REFERENCES blob ); CREATE UNIQUE INDEX plink_i1 ON plink(pid,cid); CREATE TABLE tagxref( tagid INTEGER REFERENCES tag, mtime TIMESTAMP, rid INTEGER REFERENCE blob, UNIQUE(rid, tagid) ); CREATE INDEX tagxref_i1 ON tagxref(tagid, mtime);
實現這樣的查詢只有兩個方法值得考慮。(當然可能還有許多其他算法,不過它們中的任何一個都不是“最佳”算法的競爭者。
查找提交$ckid的所有子提交,然后對每一個進行測試,看看是否有子提交包含$trunk標簽
查找所有包含$trunk標簽的提交,然后對每個這樣的提交進行測試,看看是否有$ckid提交的子提交。
僅憑直覺,我們人類認為第一個算法是最佳選擇。每個提交可能有幾個子提交(其中有一個提交是我們最常用到的。),然后對每個子提交進行測試,用對數運算計算出查找到$trunk標簽的時間。實際上,算法1確實較快。然而下一代查詢規劃器卻沒有使用人們直覺上的最佳選擇。下一代查詢規劃器一定是選擇了很難得算法,算法2在數學上相對稍微難些。這是因為:在沒有其他信息的情況下下一代查詢規劃器一定假設PLINK_I1和TAGXREF_I1索引具有同等的質量和同等的可選擇性。算法2使用了TAGXREF_I1索引的一個字段,PLINK_I1索引的兩個字段,而算法1只是使用了這兩個索引的第一個字段。正是由于算法2使用了多個字段的索引,所以下一代查詢規劃器才會以自己的標準正確地確定它作為兩種算法中性能較好的算法。兩個算法所花費的時間非常接近,算法2 只是勉強稍稍領先算法1。不過,這種情況下,選擇算法2確實是正確的。
很不幸,在實際的應用中算法2比算法1要慢些。
出現這樣的問題是因為索引并不是具有同等質量。一個提交有可能只有一個子提交。這樣PLINK_I1索引的第一個字段通常縮減值對一行進行搜索。不過由于成千上萬的提交都包含有"trunk"標簽,所以TAGXREF_I1的第一個字段對縮減搜索不會有多大幫助。
下一代查詢規劃器是沒有辦法知道TAGXREF_I1在這樣的查詢中幾乎沒有什么用處,除非在數據庫上運行ANALYZE。ANALYZE命令 收集了各個索引的質量統計信息,并把 這些統計信息存儲到SQLITE_STAT1表里。如果下一代查詢規劃器能夠訪問這些統計信息 ,那么在很大程度上它就會非常容易地選擇算法1作為最佳算法。
難道舊查詢規劃器沒有選擇算法2?很簡單:因為NN算法甚至從來都沒有考慮到算法2。這類規劃問題的圖示如下:
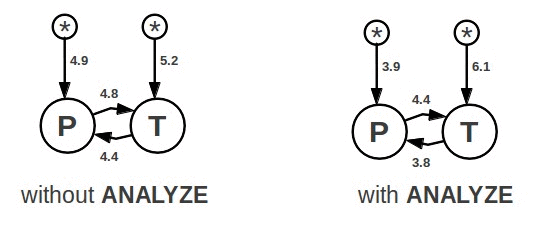
在如左圖那樣“沒有運行ANALYZE“的情況下,NN算法選擇循環P9PLINK)作為外循環,因為4.9比5.2要小,結果就是選擇P-T路徑,即算法1。NN算法只是在每一步查找一個最佳選擇路徑,因此它完全忽略了這樣一個事實:5.2+4.4是比4.9+4.8性能稍稍有些好的規劃。然而N3算法對著兩個連接追蹤了5個最佳路徑,因此它最終選擇了T-P路徑,因為這條路徑的總體資源消耗要少一些。路徑T-P就是算法2。
注意: 如果運行了ANALYZE,那么對資源消耗的評估就更加接近于現實,這樣NN和N3都選擇算法1。
(附注:最新的兩圖中對資源消耗的評估是下一代查詢規劃器使用以2為底的對數算法計算得出來的,而且與舊查詢規劃器相比假設的資源消耗稍微有些不同。因此,最后兩個圖中的資源消耗評估不能與TPC-H Q8圖里的資源消耗評估進行比較。)
4.2 問題修正
對資源倉庫數據庫運行ANALYZE可立即修復這類性能問題。然而,無論是否對資源倉庫是否進行分析,我們都要求Fossil十分強壯,而且總是能夠快速地運行。基于這個原因,我們修改查詢使用CROSS JOIN操作符而不使用常用的JOIN操作符。SQLite將不會對CROSS JOIN連接的表重新排序。這個功能是SQLite中長期都有的一個功能,做這么特別的設計就是允許具有豐富經驗的開發人員能夠強制SQLite執行特定的嵌套循環順序。一旦某個連接更改為(增加了一個關鍵字的)CROSS JOIN這樣的連接,下一代查詢規劃器就不管是否使用ANALYZE收集統計統計信息都強制選擇稍稍快一點的算法1。
我們說算法1"快一些“,不過,嚴格來說這么說不準確。對一個常見的存儲倉庫運行算法1是快一些,不過,可能構建這樣一種資源倉庫:對資源倉庫的每一次提交都是提交給不同的名字唯一的分支上,而且所有的提交都是根提交的子提交。這種情況下,TAGXREF_I1與PLINK_I1相比就具有更多的可選項了,此時算法2才真正快一些。然而實際中這樣的資源倉庫極不可能出現,所以使用CROSS JOIN語法硬編碼嵌套循環的順序是解決這種情形下存在問題的適合方案。
5.0 避免或者修正查詢規劃器問題的方法一覽表
不要驚慌!查詢規劃器選擇差的規劃這種情況實際上是非常罕見的。你未必會在應用中碰到這樣的問題。如果你沒有性能方面問題,那么你就不必為此而擔心。
創建正確的索引。大多數SQL性能問題不是因為查詢規劃器問題而引起的,而是因為缺少合適的索引。確保索引可以促進所有大型的查詢。大多數性能問題都可以使用一個或者兩個CREATE INDEX命令來解決,而不需要對應用代碼進行修改。
避免創建低質量的索引。(用于解決查詢規劃器問題而創建的)低質量索引是這樣的索引:表里的索引最左一個字段具有相同值的行超過10行或者20行。特別注意,避免使用布爾字段或或者“枚舉類型”字段作為索引的最左一字段。
這篇文章的前一段所說的Fossil性能問題是因為TAGXREF表的TAGXREF_I1索引的最左一子段(TAGID字段)具有相同值得項超過1萬。
如果你一定要使用低質量的索引,那么請一定要運行ANALYZE。只要查詢規劃器知道那個索引時低質量的,那么低質量的索引就不會讓它迷惑。查詢規劃器知曉低質量索引的方法是通過SQLITE_STAT1表的內容來實現的,這個表示有ANALYZE命令計算得來的。
當然,ANALYZE只有在數據庫一開始就擁有非常大量的內容的情況下才能夠高效地運行。當你希望創建一個數據庫并累積了大量數據的時候,你可以運行命令"ANALYZE sqlite_master"創建SQLITE_STAT1表,然后(使用常用的INSERT語句)向SQLITE_STAT1表中填入用來說明這樣的數據庫正適合你的應用的內容-也許這樣的內容是你在對實驗室的某個填寫的非常完美的模板數據庫運行ANALYZE命令后所獲得的。
編寫你自己的代碼。增加可以讓你快速且非常容易就能知道哪些查詢需要很多時間,這樣就只運行哪些特別不需要花太長時間的查詢。
如果查詢可能使用沒有運行分析的數據庫上的低質量索引,那么請使用CROSS JOIN語法,強制使用特定的嵌套循環順序。SQLite對CROSS JOIN操作符進行特殊的處理,它強制左表為右表的外部循環。
如果有其他方法實現,那么就避免這么做,因為它與任何一個SQL語言理念里的強大的優點相抵觸,特別是應用開發人不需要了解查詢規劃。如果你使用了CROSS JOIN,那么直到開發周期的后期你也要這么做,而且要在注釋里仔細地說明CROSS JOIN是如何使用的,這樣以后才有可能把它去掉。在開發周期的早期就避免使用CROSS JOIN,因為這么做是不成熟的優化措施,也就是眾所周知的萬惡之源。
使用單目運算符"+",取消WHERE子句某些限制條件。當對某個具體的查詢有更高質量的索引可以使用的時候,如果查詢規劃器仍然堅持選擇差質量的索引,那么請在WHERE子句中謹慎地使用單目運算符"+",這樣做就可以強制查詢規劃器不使用差質量的索引。如果可能的話,就盡量小心地添加這個這個運算符,而且尤其避免在應用開發的周期的早期就使用。特別要注意:給一個與類型密切相關的等號表達式增加單目運算符"+"可能更改這個表達式的結果。
使用INDEXED BY語法,強制有問題的查詢選擇特定的索引。同前兩個標題一樣,如果可能的話,盡量避免使用這個方法,尤其避免在開發的早期這么做,因為很清楚,它是一個不成熟的優化措施。
6.0 結論
SQLite的查詢規劃器做這樣的工作做得非常好:為正在運行的SQL語句選擇快速算法。對舊查詢規劃器來說,這是事實,對新的下一代查詢規劃器來說更是這樣。也許偶然會出現這樣的情況:由于信息不完整,查詢規劃器選擇了稍差的查詢規劃。 與使用舊查詢規劃器相比,使用下一代查詢規劃器這種情形就會更少出現了,不過仍然有可能出現。即便出現了這種極少出現的情況,應用開發人員需要做的是了解和幫助查詢規劃器做正確的事情。通常情況下,下一代查詢規劃器只是對SQLite做了一個新的增強,這種增強可以讓應用運行的更快些,而且不需要開發人員做更多的思考或者動作。
上述內容就是SQLite中如何實現一個查詢規劃器,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





