溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
對正則表達式有基本了解的讀者,一定不會陌生『\d』、『[a-z]+』之類的表達式,前者匹配一個數字字符,后者匹配一個以上的小寫英文字母。但是如果你用過vi、grep、awk、sed之類Linux/Unix下的工具或許會發現,這些工具雖然支持正則表達式,語法卻很不一樣,照通常習慣的辦法寫的『\d』、『[a-z]+』之類的正則表達式,往往不是無法識別就是匹配錯誤。而且,這些工具自身之間也存在差異,同樣的結構,有時需要轉義有時不需要轉義。這,究竟是為什么呢? 原因在于,Unix/Linux下的工具大多采用POSIX規范,同時,POSIX規范又可分為兩種流派(flavor)。所以,首先有必要了解一下POSIX規范。
常見的正則表達式記法,其實都源于Perl,實際上,正則表達式從Perl衍生出一個顯赫的流派,叫做PCRE(Perl Compatible Regular Expression),『\d』、『\w』、『\s』之類的記法,就是這個流派的特征。但是在PCRE之外,正則表達式還有其它流派,比如下面要介紹的POSIX規范的正則表達式。 POSIX的全稱是Portable Operating System Interface for uniX,它由一系列規范構成,定義了UNIX操作系統應當支持的功能,所以“POSIX規范的正則表達式”其實只是“關于正則表達式的POSIX規范”,它定義了BRE(Basic Regular Expression,基本型正則表達式)和ERE(Extended Regular Express,擴展型正則表達式)兩大流派。在兼容POSIX的UNIX系統上,grep和egrep之類的工具都遵循POSIX規范,一些數據庫系統中的正則表達式也符合POSIX規范。
1.1 BRE
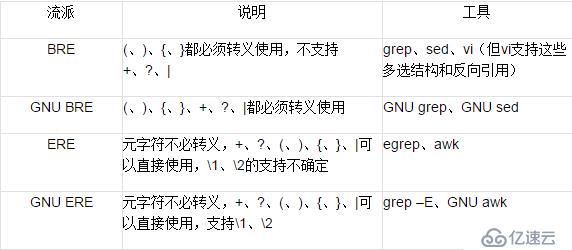
在Linux/Unix常用工具中,grep、vi、sed都屬于BRE這一派,它的語法看起來比較奇怪,元字符『(』、『)』、『{』、『}』必須轉義之后才具有特殊含義,所以正則表達式『(a)b』只能匹配字符串 (a)b而不是字符串ab;正則表達式『a{1,2}』只能匹配字符串a{1,2},正則表達式『a\{1,2\}』才能匹配字符串a或者aa。 之所以這么麻煩,是因為這些工具的誕生時間很早,正則表達式的許多功能卻是逐步發展演化出來的,之前這些元字符可能并沒有特殊的含義;為保證向后兼容,就只能使用轉義。而且有些功能甚至根本就不支持,比如BRE就不支持『+』和『?』量詞,也不支持多選結構『(…|…)』和反向引用『\1』、『\2』…。 不過今天,純粹的BRE已經很少見了,畢竟大家已經認為正則表達式“理所應當”支持多選結構和反向引用等功能,沒有確實太不方便。所以雖然vi屬于BRE流派,但提供了這些功能。GNU也對BRE做了擴展,支持『+』、『?』、『|』,只是使用時必須寫成『\+』、『\?』、『\|』,而且也支持『\1』、『\2』之類反向引用。這樣,GNU的grep等工具雖然名義上屬于BRE流,但更確切的名稱是GNU BRE。
1.2 ERE
在Linux/Unix常用工具中,egrep、awk則屬于ERE這一派,。雖然BRE名為“基本”而ERE名為“擴展”,但ERE并不要求兼容BRE的語法,而是自成一體。因此其中的元字符不用轉義(在元字符之前添加反斜線會取消其特殊含義),所以『(ab|cd)』就可以匹配字符串ab或者cd,量詞『+』、『?』、『{n,m}』可以直接使用。ERE并沒有明確規定支持反向引用,但是不少工具都支持『\1』、『\2』之類的反向引用。 GNU出品的egrep等工具就屬于ERE流(更準確的名字是GNU ERE),但因為GNU已經對BRE做了不少擴展,所謂的GNU ERE其實只是個說法而已,它有的功能GNU BRE都有了,只是元字符不需要轉義而已。 下面的表格簡要說明了幾種POSIX流派的區別[1](其實,現在的BRE和ERE在功能上并沒有什么區別,主要的差異是在元字符的轉義上)。 幾種POSIX流派的說明
為了方便查閱,下面再用一張表格列出基本的正則功能在常用工具中的表示法,其中的工具GNU的版本為準。 常用Linux/Unix工具中的表示法
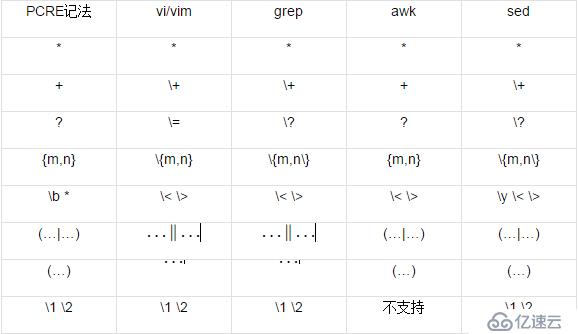
注:PCRE中常用『\b』來表示“單詞的起始或結束位置”,但Linux/Unix的工具中,通常用『\<』來匹配“單詞的起始位置”,用『\>』來匹配“單詞的結束位置”,sed中的『\y』可以同時匹配這兩個位置。
在某些文檔中,你還會發現類似『[:digit:]』、『[:lower:]』之類的表示法,它們看起來不難理解(digit就是“數字”,lower就是“小寫”),但又很奇怪,這就是POSIX字符組。不僅在Linux/Unix的常見工具中,甚至一些變成語言中都出現了這些字符組,為避免困惑,這里有必要簡要介紹它們。
在POSIX規范中,『[a-z]』、『[aeiou]』之類的記法仍然是合法的,其意義與PCRE中的字符組也沒有區別,只是這類記法的準確名稱是POSIX方括號表達式(bracket expression),它主要用在Unix/Linux系統中。POSIX方括號表示法與PCRE字符組的最主要差別在于:POSIX字符組中,反斜線\不是用來轉義的。所以POSIX方括號表示法『[\d]』只能匹配\和d兩個字符,而不是『[0-9]』對應的數字字符。
為了解決字符組中特殊意義字符的轉義問題,POSIX方括號表示法規定,如果要在字符組中表達字符](而不是作為字符組的結束標記),應當讓它緊跟在字符組的開方括號之后,所以POSIX中,正則表達式『[]a]』能匹配的字符就是]和a;如果要在POSIX方括號表示法中表達字符-(而不是范圍表示法),必須將它緊挨在閉方括號]之前,所以『[a-]』能匹配的字符就是a和-。
POSIX規范也定義了POSIX字符組,它近似等價于于PCRE的字符組簡記法,用一個有直觀意義的名字來表示某一組字符,比如digit表示“數字字符”,alpha表示“字母字符”。 不過,POSIX中還有一個值得注意的概念:locale(通常翻譯為“語言環境”)。它是一組與語言和文化相關的設定,包括日期格式、貨幣幣值、字符編碼等等。POSIX字符組的意義會根據locale的變化而變化,下面的表格介紹了常見的POSIX字符組在ASCII語言環境與Unicode語言環境下的意義,供大家參考。
POSIX字符組
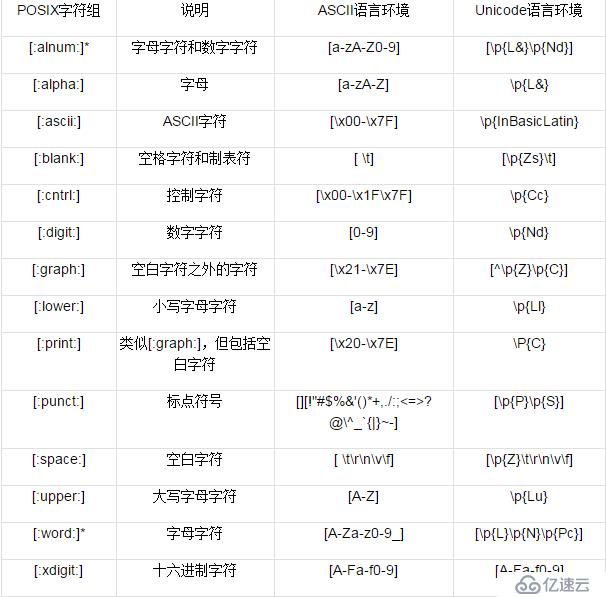
注1:標記*的字符組簡記法并不是POSIX規范中的,但使用很多,一般語言中都提供,文檔中也會出現。
注2:對應的Unicode屬性請參考本系列文章已經刊發過的關于Unicode的部分。
POSIX字符組的使用有所不同。主要區別在于,PCRE字符組簡記法可以脫離方括號直接出現,而POSIX字符組必須出現在方括號內,所以同樣是匹配數字字符,單獨出現時,PCRE中可以直接寫『\d』,而POSIX字符組就必須寫成『[[:digit:]]』。
Linux/Unix下的工具中,一般都可以直接使用POSIX字符組,而PCRE的字符組簡記法『\w』、『\d』等則大多不支持,所以如果你看到『[[:space:]]』而不是『\s』,一定不要感到奇怪。 不過,在常用的編程語言中,Java、PHP、Ruby也支持使用POSIX字符組。其中Java和PHP中的POSIX字符組都是按照ASCII語言環境進行匹配;Ruby的情況則要復雜一點,Ruby 1.8按照ASCII語言環境進行匹配,而且不支持『[:word:]』和『[:alnum:]』,Ruby 1.9按照Unicode語言環境進行匹配,同時支持『[:word:]』和『[:alnum:]』。
說明:關于正則表達式的系列文章到此即告一段落,作者最近已經完成了一本關于正則表達式的書籍,其中更詳細也更全面地講解了正則表達式使用中的各種問題。該書暫定名《正則導引》,預計近期上市,有興趣的讀者敬請關注。
[1] 關于ERE和BRE的詳細規范,可以參考http://pubs.opengroup.org/onlinepubs/009695399/basedefs/xbd_chap09.html。
關于作者
余晟,程序員,曾任抓蝦網高級顧問,現就職于盛大創新院,感興趣的方向包括搜索和分布式算法等。翻譯愛好者,譯有《精通正則表達式》(第三版)和《技術領導之路》,目前正在寫作《正則表達式傻瓜書》(暫定名),希望為國內開發同行貢獻一本實用的正則表達式教程。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





