溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
環境:VSPHERE5.5+獨立oracle 11G數據庫
現象:打開vcenter服務器控制臺,輸入密碼后卡在歡迎界面無響應,客戶端也無法正常登陸。
正常重啟也不行。由于VC所在虛機為獨立磁盤無法做快照,不能備當時狀態。
查看所在WINDOWS系統日志發現硬件可能有問題。
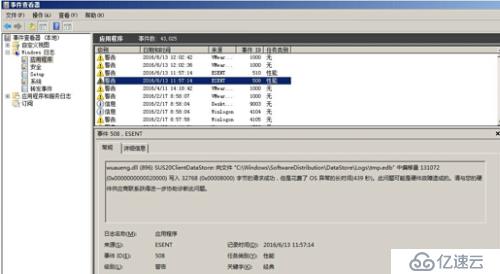
這是偏移量,并不能代表硬件有問題,懷疑VC連接的數據庫有問題,逐登陸排查。
1、登陸11.15.146.2
首先查看數據庫進程,正常。
2、查看數據庫的告警日志,發現一個問題。

這個實際上是個比較常見的錯誤。通常來說是因為在日志被寫滿時會切換日志組,這個時候會觸發一次checkpoint,DBWR會把內存中的臟塊往數據文件中寫,只要沒寫結束就不會釋放這個日志組。如果歸檔模式被開啟的話,還會伴隨著ARCH寫歸檔的過程。如果redo log產生的過快,當CPK或歸檔還沒完成,LGWR已經把其余的日志組寫滿,又要往當前的日志組里面寫redolog的時候,這個時候就會發生沖突,數據庫就會被掛起。并且一直會往alert.log中寫類似上面的錯誤信息。
分析原因:
服務器有三個日志組g1、g2、g3.當g1寫完時,要往g2上寫,這時候g1要進行歸檔,還要進行checkpoint。然后另外兩個日志組繼續寫。當g2和g3都寫完之后,又要往g1上寫,但是問題來了,g1還沒有完成歸檔和checkpoint操作。所以這時就會報警。
解決方法:
多加幾個日志組,并且每個日志組空間大一點,這樣就可以延緩時間,會留給g1充分的時間來完成歸檔和checkpoint任務。就不會有報錯。
操作步驟:
首先查看下數據庫的日志組狀態
查看在線日志組:SQL> select * from v$log;
查看日志組中的成員:SQL> select * from v$logfile;
查看日志組的具體狀態:SQL> select group#,sequence#,bytes,members,status from v$log;
GROUP# SEQUENCE# BYTES MEMBERS STATUS
------------------------------------------------
1 28825 52428800 1 INACTIVE
2 28826 52428800 1 ACTIVE
3 28827 52428800 1 CURRENT
CURRENT: 表示是當前的日志。
INACTIVE:臟數據已經寫入數據塊。該狀態可以drop。
ACTIVE: 臟數據還沒有寫入數據塊。
日志只有50M太小
擴充下日志組大小
SQL> alter database add logfile group 4 ('/u01/app/oracle/oradata/pvdb/redo04.log')size 500M;
Database altered.
SQL> alter database add logfile group 5('/u01/app/oracle/oradata/pvdb/redo05.log') size 500M;
Database altered.
SQL> alter database add logfile group 6 ('/u01/app/oracle/oradata/pvdb/redo06.log')size 500M;
Database altered.
切換日志組
SQL> alter system switch logfile;
System altered.
SQL> alter system switch logfile;
System altered.
注意:alter system switch logfile 和alter system archive log current這兩個切換的區別。
alter system switch logfile 是不等待歸檔完成就switch logfile。如果database尚未開啟archive log mode。那用這個切換是毋庸置疑了。另外,也是對單實例database和RAC模式下當前實例執行日志切換。
而alter system archive log current則需要等待歸檔完成才switch logfile。會對其中所有實例執行日志切換。
整體上說來,在自動歸檔的庫里,兩個命令的所產生的結果幾乎一樣。有區別的是alter system archive log current所用的時間會比alter system switch logfile 的長。
刪除日志組
SQL> alter database drop logfile group 1;
Database altered.
SQL> alter database drop logfile group 2;
Database altered.
SQL> alter database drop logfile group 3;
Database altered.
注意刪除日志組及日志組成員:
原則:刪除前必須遵守如下原則,每個實例必須至少有兩個日志組;當一個組處于ACTIVE或者CURRENT的狀態時不可刪除;刪除日志組的操作只對數據庫進行更改,操作系統的文件尚未刪除;當刪除時適用DROP LOGFILE GROUP N語句時,此時GROUP N內的所有成員都將被刪除。
ALTER DATABASE DROP LOGFILE GROUP N;
日志組狀態的改變:
SQL> select group#,sequence#,bytes,members,status from v$log;
GROUP# SEQUENCE# BYTES MEMBERS STATUS
---------- ---------- ---------- ---------- ----------------
1 201268 2147483648 1 CURRENT
2 201263 2147483648 1 ACTIVE
3 201264 2147483648 1 ACTIVE
4 201267 524288000 1 ACTIVE
5 201265 524288000 1 ACTIVE
6 201266 524288000 1 ACTIVE
SQL> ALTER SYSTEM CHECKPOINT;
SQL> select group#,sequence#,bytes,members,status from v$log;
GROUP# SEQUENCE# BYTES MEMBERS STATUS
---------- ---------- ---------- ---------- ----------------
1 201268 2147483648 1 CURRENT
2 201263 2147483648 1 INACTIVE
3 201264 2147483648 1 INACTIVE
4 201267 524288000 1 INACTIVE
5 201265 524288000 1 INACTIVE
6 201266 524288000 1 INACTIVE
刪除日志成員的原則:當你刪除一個是該組中最后一個成員的時候,你不能刪除此成員;當組的轉臺處于current的狀態時,不能刪除組成員;在歸檔模式下,必須得歸檔之后才能刪除;刪除日志組成員的操作只對數據庫進行更改,操作系統的文件尚未刪除。
刪除日志組后再刪除相應日志文件,例如redo01.log
SQL> !rm /u01/app/oracle/oradata/pvdb/redo01.log
SQL> alter system switch logfile;
System altered.
SQL> select group#,sequence#,bytes,members,status from v$log;
GROUP# SEQUENCE# BYTES MEMBERS STATUS
------------------------------------------------
4 28828 524288000 1 INACTIVE
5 28829 524288000 1 ACTIVE
6 28830 524288000 1 CURRENT
最后切完日志組后,觀察新建的REDO日志組已被應用,數據庫正常,數據庫日志再無報警,問題解決。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





