溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
RHCS集群介紹請看http://11107124.blog.51cto.com/11097124/1884048
在RHCS集群中每個集群都必須有一個唯一的集群名稱,至少有一個fence設備(實在不行可以使用手動fence_manual),且至少要有三個節點,兩個節點必須有仲裁磁盤
準備環境
node1:192.168.139.2
node2:192.168.139.4
node4:192.168.139.8
VIP:192.168.139.10
在node1裝luci創建集群,并進行集群管理;在node2和node4安裝ricci讓其作為集群節點
1:ssh互信
2:修改主機名為node1,node2,node4
3: ntp時間同步
詳細準備過程可以參考這里 http://11107124.blog.51cto.com/11097124/1872079
分享一個和好的紅帽官方RHCS集群套件資料 https://access.redhat.com/site/documentation/zh-CN/Red_Hat_Enterprise_Linux/6/pdf/Cluster_Administration/Red_Hat_Enterprise_Linux-6-Cluster_Administration-zh-CN.pdf 這里有RHCS集群套件的詳細官方介紹,包括luci/ricci的詳細使用,且是中文版本

下面開始本次實驗安裝luci/ricci,并建一個Web集群
安裝luci在node1,安裝ricci在node2和nde4
[root@node1 yum.repos.d]# yum install luci
[root@node2 yum.repos.d]# yum install ricci -y
[root@node4 yum.repos.d]# yum install ricci -y
如果yum安裝有以下警告
Warning: RPMDB altered outside of yum.
執行如下命令,清楚yum歷史信息便可
[root@node1 yum.repos.d]# rm -rf /var/lib/yum/history/*.sqlite
啟動luci
[root@node1 yum.repos.d]# service luci start ##https://node1.zxl.com:8084(web訪問入口)
Point your web browser to https://node1.zxl.com:8084 (or equivalent) to access luci
在兩臺節點上給ricci用戶設置密碼,可以與root的密碼不同
[root@node2 yum.repos.d]# echo 123456|passwd --stdin ricci
Changing password for user ricci.
passwd: all authentication tokens updated successfully.
[root@node4 yum.repos.d]# echo 123456|passwd --stdin ricci
Changing password for user ricci.
passwd: all authentication tokens updated successfully.
啟動ricci
[root@node2 cluster]# service ricci start
[root@node4 cluster]# service ricci start
然后用瀏覽器進行web登錄luci端口為8084
彈出的警告窗口
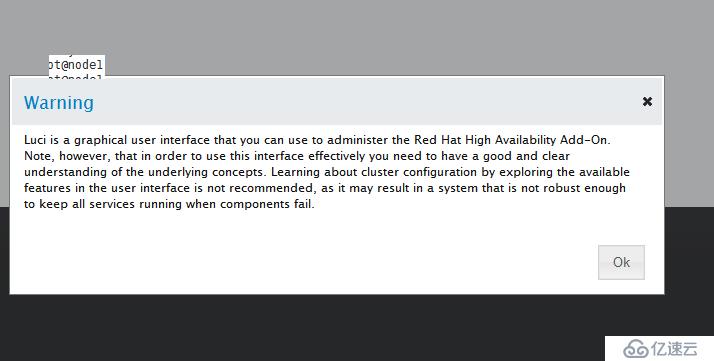
點擊Manager Clusters ->Create創建集群,加入集群節點
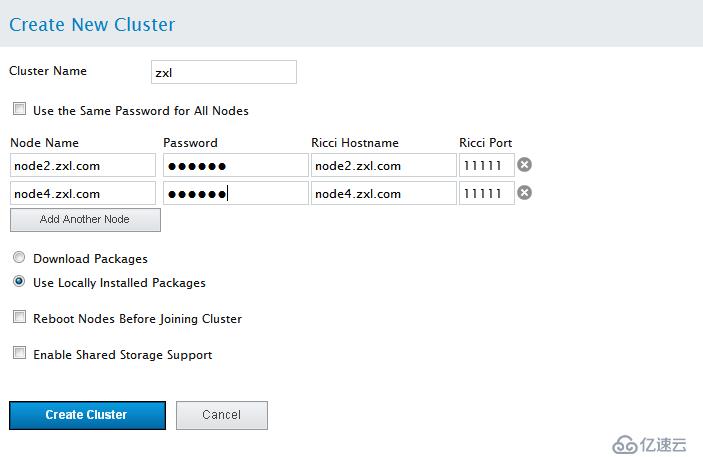
點擊 創建集群。點擊 創建集群 后會有以下動作:
a. 如果您選擇「下載軟件包」,則會在節點中下載集群軟件包。
b. 在節點中安裝集群軟件(或者確認安裝了正確的軟件包)。
c. 在集群的每個節點中更新并傳推廣群配置文件。
d. 加入該集群的添加的節點 顯示的信息表示正在創建該集群。當集群準備好后,該顯示會演示新創建集群的狀態
然后會出現如下界面please wait為node2和node4自動安裝集群的相應包(包括cman,rgmanager)
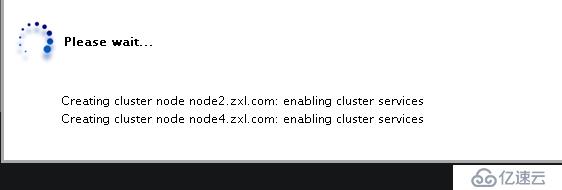
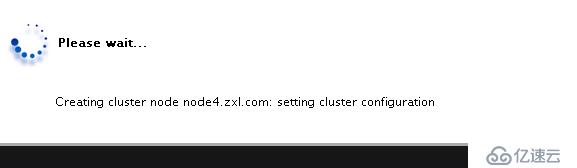
創建完成
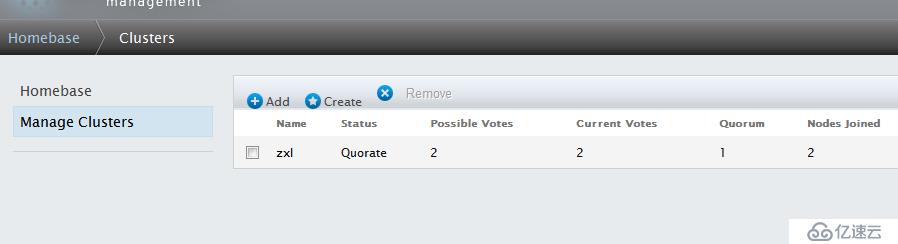
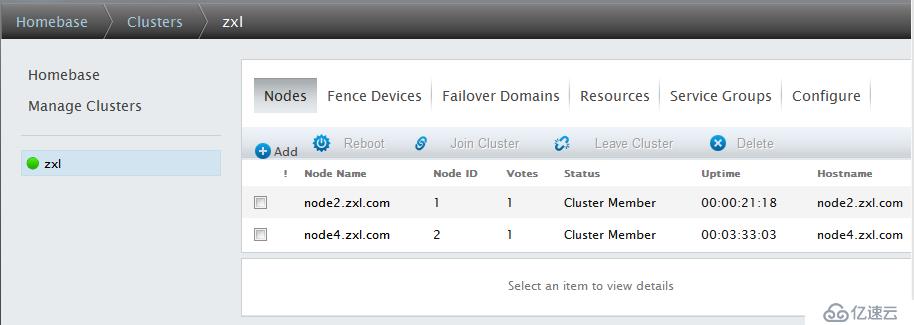
注:正常狀態下,節點Nodes名稱和Cluster Name均顯示為綠色,如果出現異常,將顯示為紅色。
添加Fence設備,RHCS集群必須至少有一個Fence設備,點擊Fence Devices -->add

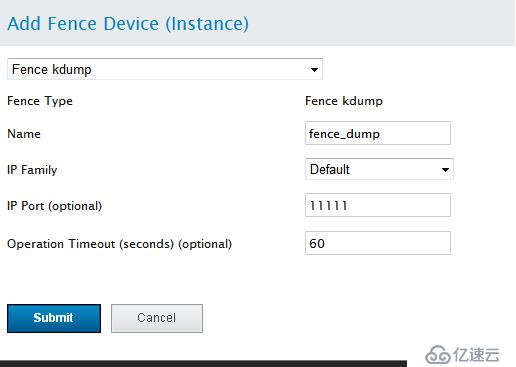
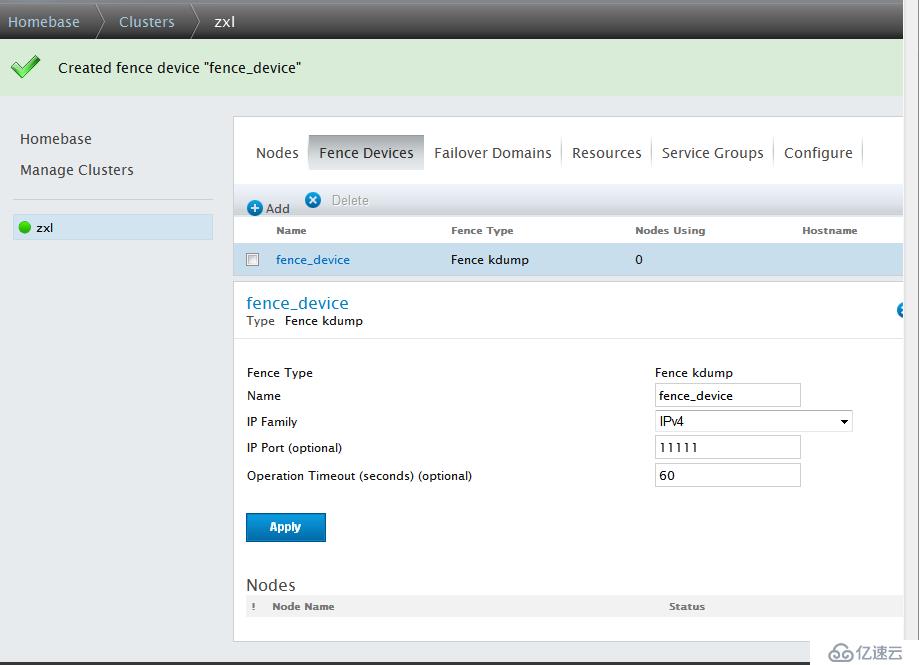
創建Failover Domain
Failover Domain是配置集群的失敗轉移域,通過失敗轉移域可以將服務和資源的切換限制在指定的節點間,下面的操作將創建1個失敗轉移域,
點擊Failover Domains-->Add
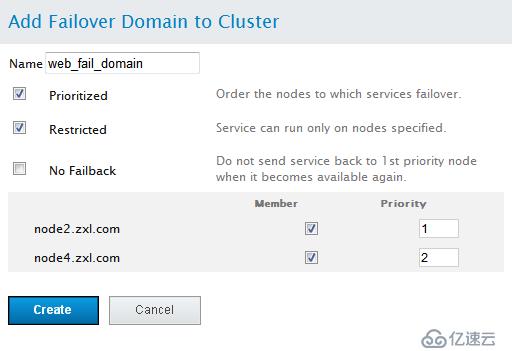
Prioritized:是否在Failover domain 中啟用域成員優先級設置,這里選擇啟用。
Restrict:表示是否在失敗轉移域成員中啟用服務故障切換限制。這里選擇啟用。
Not failback :表示在這個域中使用故障切回功能,也就是說,主節點故障時,備用節點會自動接管主節點服務和資源,當主節點恢復正常時,集群的服務和資源會從備用節點自動切換到主節點。
然后,在Member復選框中,選擇加入此域的節點,這里選擇的是node2和node4節點在“priority”處將node1的優先級設置為1,node2的優先級設置為2。
需要說明的是“priority”設置為1的節點,優先級是最高的,隨著數值的降低,節點優先級也依次降低。
所有設置完成,點擊Submit按鈕,開始創建Failover domain。
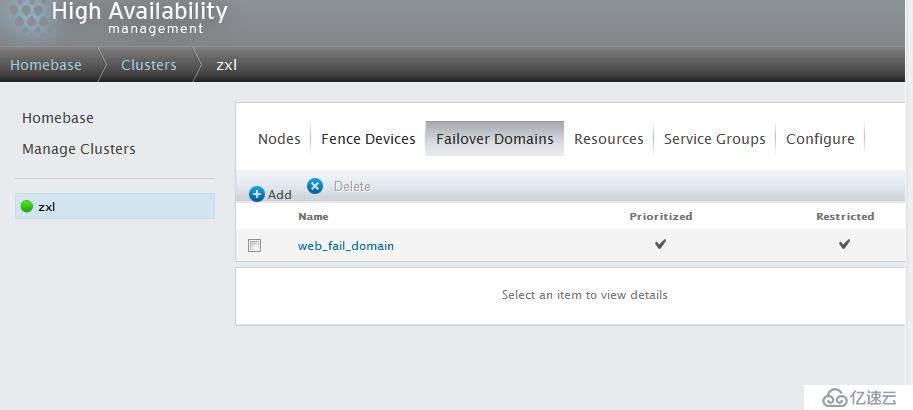
這樣集群節點和fence設備和故障轉移域就創建完成了,下面開始加入Resources,以web服務為列
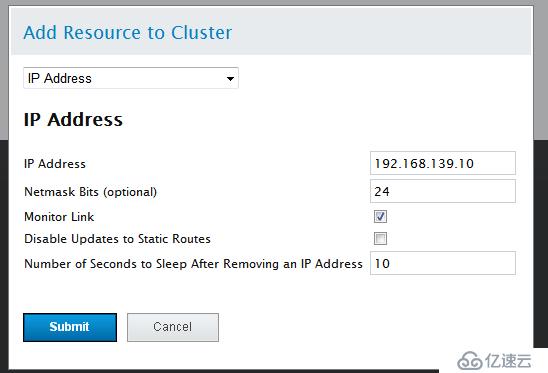
點擊Resources-->Add 添加VIP(192.168.139.10)
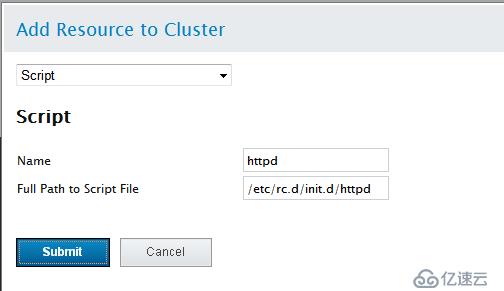
添加httpd(在RHCS中都是script類型的腳本在/etc/rc.d/init.c/目錄下)
注:Monitor Link追蹤連接
Disable Updates to Static Routes 是否停止跟新靜態路由
Number ofSeconds to Sleep After Removing an IP Address 超時時間
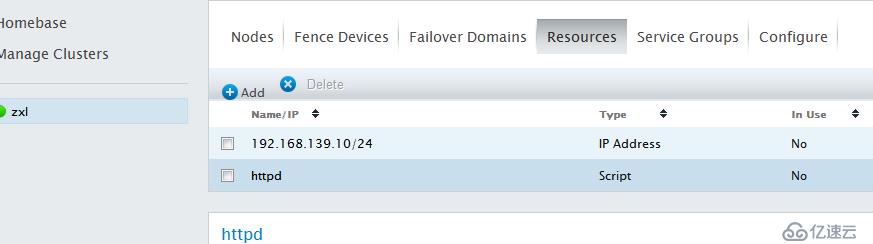
OK,資源添加完畢,下面定義服務組(資源必須在組內才能運行)資源組內定義的資源為內部資源
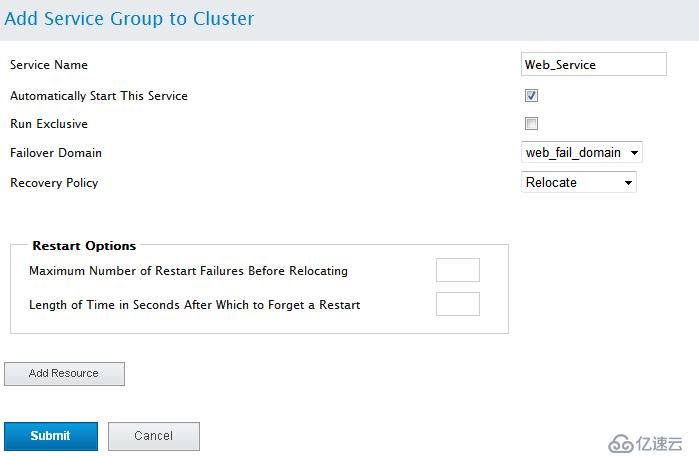
Automatically Start This Service 自動運行這個服務
Run Exclusive 排查運行
Failover Domain 故障轉移域(這里要選擇你提前設置的那個故障轉移域)
Recovery Policy 資源轉移策略
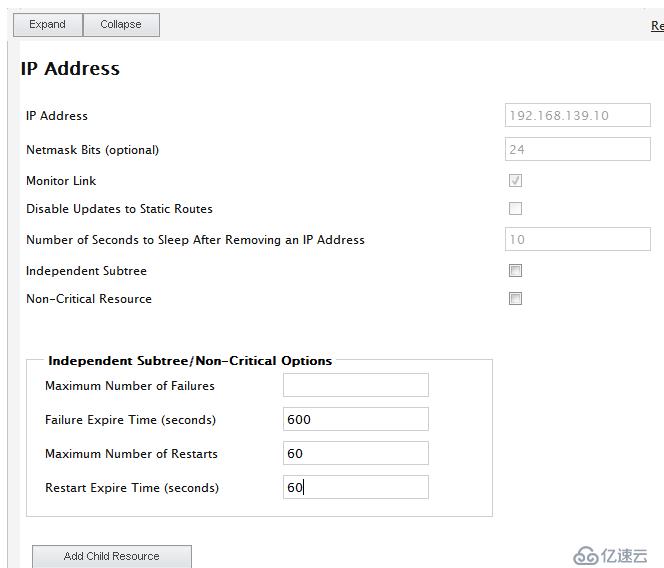
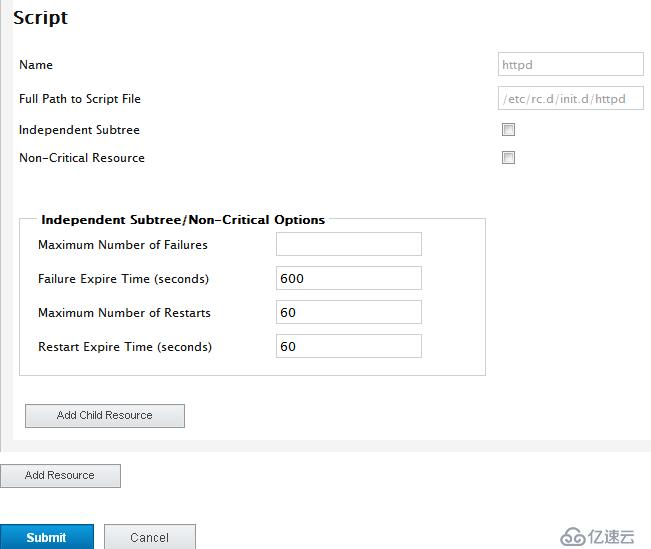
Maximum Number of Failures 最大錯誤次數
Failues Expire Time 錯誤超時時間
Maximum Number of Restars 最大重啟時間
Restart Expire Time(seconds) 重啟時間間隔
點擊Submit提交,創建集群服務
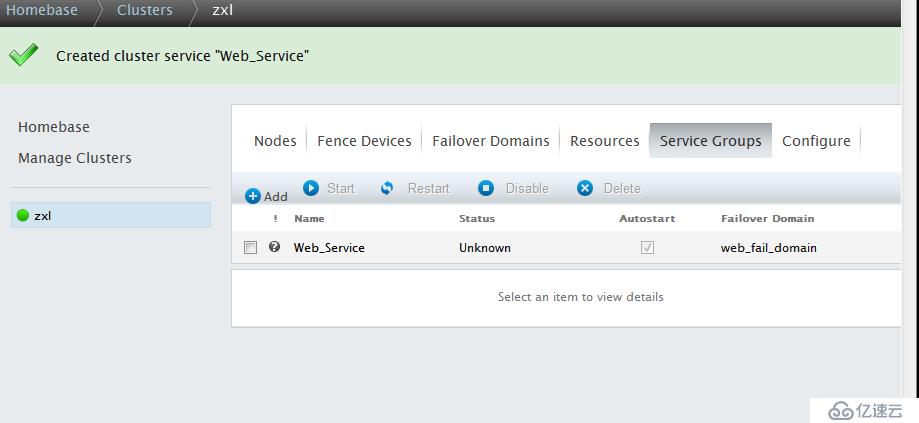
點擊Web-Service-->Start開啟集群服務
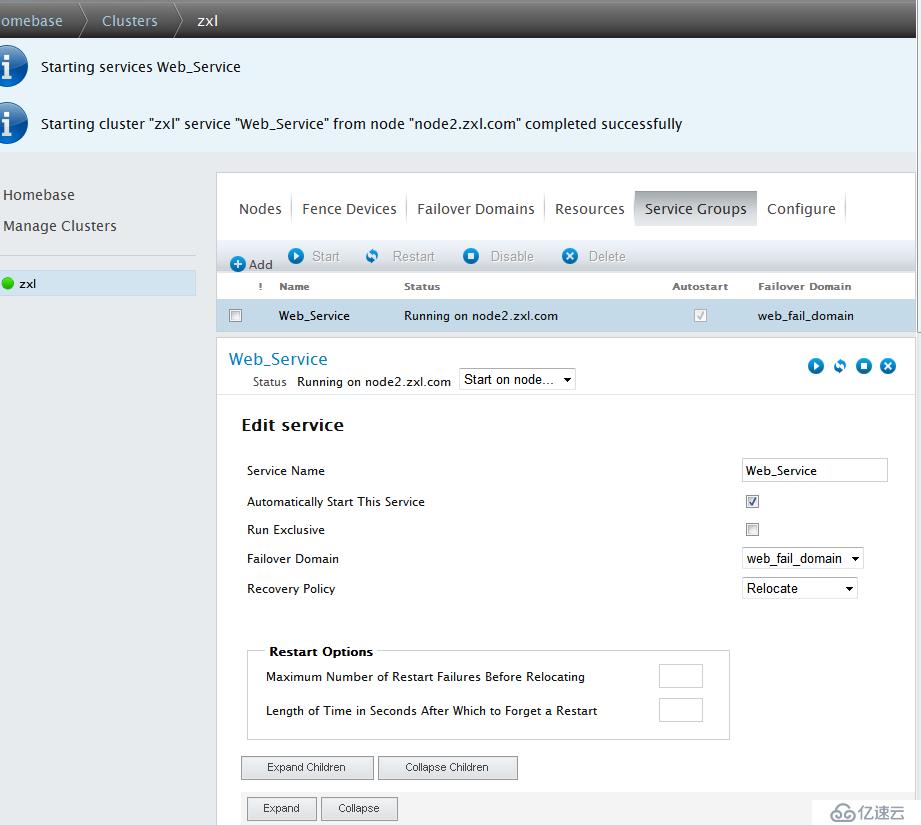

Web服務和Vip啟動成功
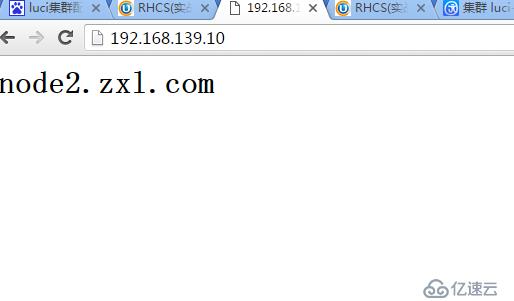
用瀏覽器測試訪問VIP
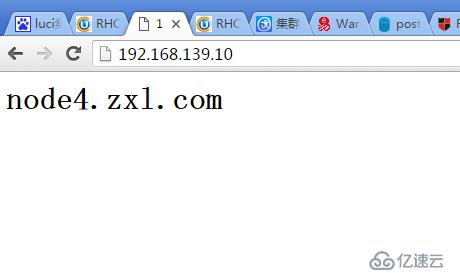
[root@www init.d]# ip addr show ##可以看到VIP192.168.139.10已近自動配置
inet 192.168.139.8/24 brd 192.168.139.255 scope global eth0
inet 192.168.139.10/24 scope global secondary eth0
[root@www init.d]# clustat ##用這個命令可以查看集群狀態
Cluster Status for zxl @ Tue Dec 20 15:43:04 2016
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
node2.zxl.com 1 Online, rgmanager
node4.zxl.com 2 Online, Local, rgmanager
Service Name Owner (Last) State ------- ---- ----- ------ ----- service:Web_Service node4.zxl.com started
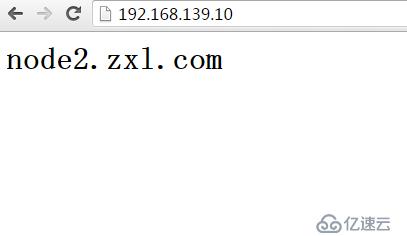
進行服務轉移到node2
[root@www init.d]# clusvcadm -r Web_Service -m node2
'node2' not in membership list
Closest match: 'node2.zxl.com'
Trying to relocate service:Web_Service to node2.zxl.com...Success
service:Web_Service is now running on node2.zxl.com
[root@www init.d]# clustat ##轉移成功
Cluster Status for zxl @ Tue Dec 20 16:21:53 2016
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
node2.zxl.com 1 Online, rgmanager
node4.zxl.com 2 Online, Local, rgmanager
Service Name Owner (Last) State
------- ---- ---- ------ -----
service:Web_Service node2.zxl.com started
模擬node2故障,看服務是否自動轉移
[root@node2 init.d]# halt
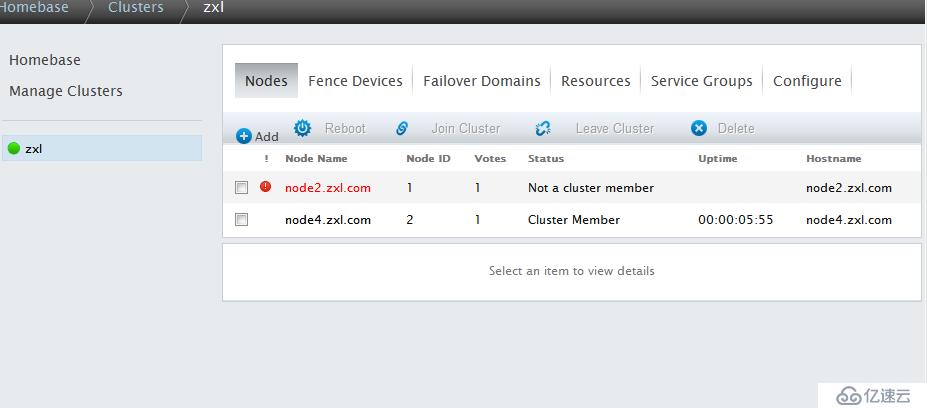
服務成功轉移到node4
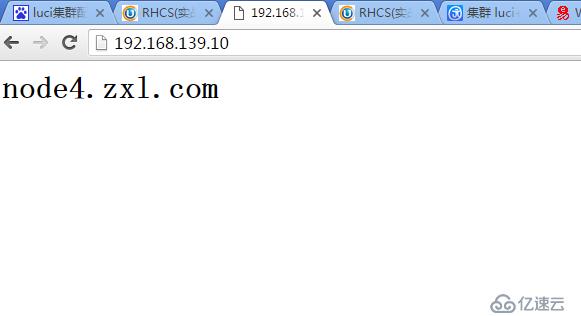
重新啟動node2,并啟動ricci,可以看到node2已近恢復
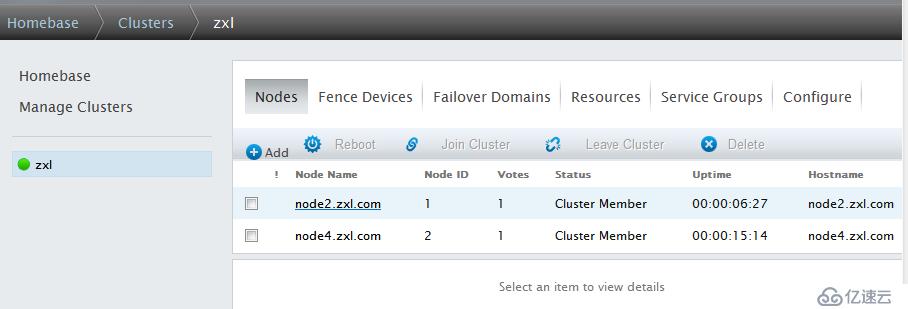
并且由于在定義故障轉移域時沒有選擇Not failback(即主節點一恢復正常,服務會自動轉移回來),所以Web服務有轉移到了node2上(因為node2的priority優先級為1最高,是主節點)
下面加入我找的一些關于luci配置的詳細介紹
啟動、停止、刷新和刪除集群 您可以通過在集群的每個節點中執行以下動作啟動、停止、重啟某個集群。在具體集群頁面中點擊集群顯示 頂部的「節點」,此時會顯示組成該集群的節點。
如果要將集群服務移動到另一個集群成員中,則在集群節點或整個集群中執行啟動和重啟操作時會造成短暫 的集群服務中斷,因為它是在要停止或重啟的節點中運行。
要停止集群,請執行以下步驟。這樣會關閉節點中的集群軟件,但不會從節點中刪除集群配置信息,且該節 點仍會出現在該集群節點顯示中,只是狀態為不是集群成員。
1. 點擊每個節點旁的復選框選擇集群中的所有節點。
2. 在該頁面頂部的菜單中選擇「離開集群」,此時會在頁面頂部出現一條信息表示正在停止每個節點。
3. 刷新該頁面查看節點更新的狀態。
要啟動集群,請執行以下步驟:
1. 點擊每個節點旁的復選框選擇集群中的所有節點。
2. 在該頁面頂部的菜單中選擇「加入集群」功能。
3. 刷新該頁面查看節點更新的狀態。 要重啟運行中的集群,首先請停止集群中的所有節點,然后啟動集群中的所有節點,如上所述。
要刪除整個集群,請按照以下步驟執行。這導致所有集群服務停止,并從節點中刪除該集群配置信息,同時 在集群顯示中刪除它們。如果您之后嘗試使用已刪除的節點添加現有集群,luci 將顯示該節點已不是任何集
1. 點擊每個節點旁的復選框選擇集群中的所有節點。
2. 在該頁面頂部的菜單中選擇「刪除」功能。
如果您要從 luci 界面中刪除某個集群而不停止任何集群服務或者更改集群成員屬性,您可以使用「管理集 群」頁面中的「刪除」選項,
您還可以使用 Conga 的 luci 服務器 組件為高可用性服務執行以下管理功能:
啟動服務
重啟服務
禁用服務
刪除服務
重新定位服務
在具體集群頁面中,您可以點擊集群顯示頂部的「服務組」為集群管理服務。此時會顯示為該集群配置的服 務。
「啟動服務」 — 要啟動任何當前沒有運行的服務,請點擊該服務旁的復選框選擇您要啟動的所有服 務,并點擊「啟動」。
「重啟服務」 — 要重啟任何當前運行的服務,請點擊該服務旁的復選框選擇您要啟動的所有服務,并 點擊「重啟」。
「禁用服務」 — 要禁用任何當前運行的服務,請點擊該服務旁的復選框選擇您要啟動的所有服務并, 點擊「禁用」。
「刪除服務」 — 要刪除任何當前運行的服務,請點擊該服務旁的復選框選擇您要啟動的所有服務并點 擊「刪除」。
「重新定位服務」 — 要重新定位運行的服務,請在服務顯示中點擊該服務的名稱。此時會顯示該服務 配置頁面,并顯示該服務目前在哪個節點中運行。
在「在節點中啟動......」下拉框中選擇您想要將服務重新定位的節點,并點擊「啟動」圖標。此時 會在頁面頂部顯示一條信息說明正在重啟該服務。您可以刷新該頁面查看新顯示,在該顯示中說明該服 務正在您選擇的節點中運行。
注意 如果您所選運行的服務是一個 vm 服務,下拉框中將會顯示 migrate 選項而不是 relocate 選
您還可以點擊「服務」頁面中的服務名稱啟動、重啟、禁用或者刪除獨立服務。此時會顯示服務配置 頁面。在服務配置頁面右上角有一些圖標:「啟動」、「重啟」、「禁用」和「刪除」。
備份和恢復 luci 配置 從紅帽企業版 Linux 6.2 開始,您可以使用以下步驟備份 luci 數據庫,即保存在 /var/lib/luci/data/luci.db 文件中。這不是給集群自身的配置,自身配置保存在 cluster.conf 文件中。相反,它包含用戶和集群以及 luci 維護的相關屬性列表。
默認情況下,備份生成的步驟將會寫入同 一目錄的 luci.db 文件中。
1. 執行 service luci stop。
2. 執行 service luci backup-db。
您可以選擇是否指定一個文件名作為 backup-db 命令的參數,該命令可將 luci 數據庫寫入那個文 件。例如:要將 luci 數據庫寫入文件 /root/luci.db.backup,您可以執行命令 service luci backup-db /root/luci.db.backup。注:但如果將備份文件寫入 /var/lib/luci/data/ 以外的位置(您使用 service luci backup-db 指定的備份文件名將不會在 list-backups 命令的輸出結果中顯示。
3. 執行 service luci start。
使用以下步驟恢復 luci 數據庫。
1. 執行 service luci stop。
2. 執行 service luci list-backups,并注釋要恢復的文件名。
3. 執行 service luci restore-db /var/lib/luci/data/lucibackupfile,其中 lucibackupfile 是要恢復的備份文件。
例如:以下命令恢復保存在備份文件 luci-backup20110923062526.db 中的 luci 配置信息: [root@luci1 ~]#service luci restore-db /var/lib/luci/data/luci-backup20110923062526.db
4. 執行 service luci start。
如果您需要恢復 luci 數據庫,但在您因完全重新安裝生成備份的機器中已丟失 host.pem 文件,例如:您 需要將集群重新手動添加回 luci 方可重新認證集群節點。 請使用以下步驟在生成備份之外的機器中恢復 luci 數據庫。注:除恢復數據庫本身外,您還需要復制 SSL 證書文件,以保證在 ricci 節點中認證 luci。在這個示例中是在 luci1 機器中生成備份,在 luci2 機器中 恢復備份。
1. 執行以下一組命令在 luci1 中生成 luci 備份,并將 SSL 證書和 luci 備份復制到 luci2 中。
[root@luci1 ~]# service luci stop
[root@luci1 ~]# service luci backup-db
[root@luci1 ~]# service luci list-backups /var/lib/luci/data/luci- backup20120504134051.db
[root@luci1 ~]# scp /var/lib/luci/certs/host.pem /var/lib/luci/data/lucibackup20120504134051.db root@luci2:
2. 在 luci2 機器中,保證已安裝 luci,且沒有運行。如果還沒有安裝,則請安裝該軟件包。
3. 執行以下一組命令保證認證到位,并在 luci2 中使用 luci1 恢復 luci 數據庫。
[root@luci2 ~]# cp host.pem /var/lib/luci/certs/
[root@luci2 ~]# chown luci: /var/lib/luci/certs/host.pem
[root@luci2 ~]# /etc/init.d/luci restore-db ~/lucibackup20120504134051.db
[root@luci2 ~]# shred -u ~/host.pem ~/luci-backup20120504134051.db
[root@luci2 ~]# service luci start
再分享一個網友寫的關于RHCS集群的實驗連接,寫的很好 http://blog.chinaunix.net/uid-26931379-id-3558613.html
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





