溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Cursor直譯過來就是“游標”,它是Oracle數據庫中SQL解析和執行的載體。Oracle數據庫是用C語言寫的,可以將Cursor理解成是C語言的一種結構(Structure)。
Oracle數據庫里的Cursor分為兩種類型:一種是Shared Cursor;另一種是Session Cursor。本文先介紹Shared Cursor。
1 Oracle里的Shared Cursor。
1.1 Shared Cursor的含義
Shared Cursor就是指緩存在庫緩存里的一種庫緩存對象,說白了就是指緩存在庫緩存里的SQL語句和匿名PL/SQL語句所對應的庫緩存對象。Shared Cursor是Oralce緩存在Library Cache中的幾十種庫緩存對象之一,它所對應的庫緩存對象名柄的Namespace屬性的值 是CRSR(也就是Cursor的縮寫)。Shared Cursor里會存儲目標SQL的SQL文本、解析樹、該SQL所涉及的對象定義、該SQL所使用的綁定變量類型和長度,以及該SQL的執行計劃等信息。
Oracle數據庫中的Shared Cursor又細分為Parent Cursor(父游標)和Child Cursor(子游標)這兩種類型,我們可以通過分別查詢視圖V$SQLAREA和V$SQL來查看當前緩存在庫緩存中的Parent Cursor和Chile Cursor,其中V$SQLAREA用于查看Parent Cursor,V$SQL用于查看Child Cursor。
Parent Cursor和Child Cursor的結構是一樣的(它們都是以庫緩存對象名柄的方式緩存在庫緩存中,Namespace屬性的值均為CRSR),它們的區別在于目標SQL的SQL文本會存儲在其Parent Cursor所對應的庫緩存對象句柄的屬性Name中(Child Cursor對應的庫緩存對象名柄的Name屬性值為空,這意味著只有通過Parent Cursor才能找到相應的Child Cursor),而該SQL的解析樹和執行計劃則會存儲在其Child Cursor所對應的庫緩存對象句柄的Heap 6中,同時Oracle會在該SQL所對應的Parent Cursor的Heap 0的Chhild table中存儲從屬于該Parent Cursor的所有Child Cursor的庫緩存對象名柄地址(這意味著Oracle可以通過訪問Parent Cursor的Heap 0中的Child table而依次順序訪問從屬于該Parent Cursor的所有Child Cursor)。
這種Parent Cursor和Child Cursor的結構就決定了在Oracle數據庫里,任意一個目標SQL一定會同時對應兩個Shared Cursor,其中一個是Parent Cursor,另外一個則是Child Cursor,Parent Cursor會存儲該SQL的SQL文本,而該SQL真正的可以被重用的解析樹和執行計劃則存儲在Child Cursor中。
Oracle設計這種Parent Cursor和Child Cursor并存的結果是因為Oralce是根據目標SQL的SQL文本的哈希值去相應Hash Bucket中的庫緩存對象句柄鏈表里找匹配的庫緩存對象句柄的,但是不同的SQL文本對應的哈希值可能相同,而且同一個SQL(此時的哈希值自然是相同的)也有可能有多份不同的解析權和執行計劃。可以想象一下,如果它們都處于同一個Hash Bucket中的庫緩存對象句柄鏈表里,那么這個庫緩存對象句柄的長度就不是最優的長度(這意味著會增加Oracle從頭到尾搜索這個庫緩存對象句柄鏈表所需要耗費的時間和工作量),為了能盡量減少對應Hash Bucket中庫緩存對象句柄鏈表的長度,Oracle設計了這種嵌套的Parent Cursor和Child Cursor并存的結構。
下面看一個Parent Cursor和Child Cursor的實例:
sys@MYDB>conn zx/zx Connected. zx@MYDB>select empno,ename from emp; EMPNO ENAME ---------- ------------------------------ 7369 SMITH ......省略部分輸出 14 rows selected.
當一條SQL第一次被執行的時候,Oracle會同時產生一個Parent Cursor和一個Child Cursor。上述SQL是首次執行,所以現在Oracle應該會同時產生一個Parent Cursor和一個Child Cursor。使用如下語句驗證:
select sql_text,sql_id,version_count from v$sqlarea where sql_text like 'select empno,ename%';
注意到原目標SQL在V$SQLAREA中只有一條匹配記錄,且這條記錄的列VERSION_COUNT的值為1(VERSION_COUNT表示這個Parent Cursor所擁有的所有Child Cursor的數量),這說明Oracle在執行目標SQL時確實產生了一個Parent Cursor和一個Child Cursor。
上述SQL所對應的SQL_ID為“78bd3uh5a08av”,用這個SQL_ID就可以去V$SQL中查詢該SQL對應的所有Child Cursor的信息:
zx@MYDB>col sql_text for a50 zx@MYDB>select sql_text,sql_id,version_count from v$sqlarea where sql_text like 'select empno,ename%'; SQL_TEXT SQL_ID VERSION_COUNT -------------------------------------------------- --------------------------------------- ------------- select empno,ename from emp 78bd3uh5a08av 1
注意到目標SQL_ID在V$SQL中只有一條匹配記錄,而且這條記錄的CHILD_NUMBER的值為0(CHILD_NUMBER表示某個Child Cursor所對應的子游標號),說明Oracle在執行原目標SQL時確實只產生了一個子游標號為0的Child Cursor。
把原目標SQL中的表名從小寫換成大寫的EMP后再執行:
zx@MYDB>select empno,ename from EMP; EMPNO ENAME ---------- ------------------------------ 7369 SMITH ......省略部分輸出 14 rows selected.
Oracle會根據目標SQL的SQL文本的哈希值去相應的Hash Bucket中找匹配的Parent Cursor,而哈希運算是對大小寫敏感的,所以當我們執行上述改寫后的目標SQL時,大寫EMP所對應的Hash Bucket和小寫emp所對應的Hash Bucket極有可能不是同一個Hash Bucket(即便是同一個Hash Bucket也沒有關系,因為Oracle還會繼續比對Parent Cursor所在的庫緩存對象句柄的Name屬性值,小寫所對應的Parent Cursor的Name值為“select empno,ename from emp”,大寫EMP對就的Parent Cursor的Name值為“select empno,ename from EMP”,兩者顯然不相等)。也就是說,小寫emp所對應的Parent Cursor并不是大寫EMP所要找的Parent Cursor,兩者不能共享,所以此時Oracle肯定會新生成一對Parent Cursor和Child Cursor。
下面來驗證一下:
zx@MYDB>select sql_text,sql_id,version_count from v$sqlarea where sql_text like 'select empno,ename%'; SQL_TEXT SQL_ID VERSION_COUNT -------------------------------------------------- --------------------------------------- ------------- select empno,ename from emp 78bd3uh5a08av 1 select empno,ename from EMP 53j2db788tnx9 1 zx@MYDB>select plan_hash_value,child_number from v$sql where sql_id='53j2db788tnx9'; PLAN_HASH_VALUE CHILD_NUMBER --------------- ------------ 3956160932 0
從上述結果可以看出,針對大寫EMP所對應的目標SQL(大寫EMP),Oracle確實新生成了一個Parent Cursor和一個Child Cursor。
現在構造一個同一個Parent Cursor下有不同Child Cursor的實例:
使用scott用戶登錄,再次執行小寫emp所對應的目標SQL:
zx@MYDB>conn scott/tiger Connected. scott@MYDB>select empno,ename from emp; EMPNO ENAME ---------- ------------------------------ 7369 SMITH ......省略部分輸出 14 rows selected.
Oracle根據目標SQL的SQL文本的哈希值去相應的Hash Bucket中找匹配的Parent Cursor,找到了匹配的Parent Cursor后還得遍歷從屬于該Parent Cursor的所有Child Cursor(因為可以被重用的解析權和執行計劃都存儲在Child Cursor中)。
對上述SQL(小寫emp)而言,因為同樣的SQL文本之前在ZX用戶下已經執行過,在Library Cache中也已經生成了對應的Parent Cursor和Child Cursor,所以這里Oracle根據上述SQL的SQL文本的哈希值去Library Cache中找匹配的Parent Cursor時肯定時能找到匹配記錄的。但接下來遍歷從屬于該Parent Cursor的所有Child Cursor時,Oracle會發現對應Child Cursor中存儲的解析權和執行計劃此時是不能被重用的,因為此時的Child Cursor里存儲的解析樹和執行計劃針對的是ZX用戶下的表EMP,面上述SQL針對的則是SCOTT用戶下的同名表EMP,待查詢的目標表根本就不是同一個表,解析權和執行計劃當然不能共享了。這意味著Oracle還得針對上述SQL從頭再做一次解析,并把解析后的解析樹和執行計劃存儲在一個新生成的Child Cursor里,再把這個Child Cursor掛在上述Parent Cursor下(即把新生成的Child Cursor在庫緩存對象句柄地址添加到上述Parent Cursor的Heap 0的Child table中)。也就是說一旦上述SQL執行完畢,該SQL所對應的Parent Cursor下就會有兩個Child Cursor,一個Child Cursor中存儲的是針對ZX用戶下表EMP的解析樹和執行計劃,另外一個Child Cursor中存儲的則是針對SCOTT用戶下同名表EMP的解析樹和執行計劃。
使用如下語句驗證:
scott@MYDB>select sql_text,sql_id,version_count from v$sqlarea where sql_text like 'select empno,ename%'; SQL_TEXT SQL_ID VERSION_COUNT -------------------------------------------------- --------------------------------------- ------------- select empno,ename from emp 78bd3uh5a08av 2 select empno,ename from EMP 53j2db788tnx9 1
注意到上述SQL(小寫emp)V$SQLAREA中的匹配記錄的列VERSION_COUNT的值為2 ,說明Oracle在執行該SQL時確實產生了一個Parent Cursor和兩個Child Cursor。
使用如下語句查詢上述SQL所對應的Child Cursor的信息:
scott@MYDB>select plan_hash_value,child_number from v$sql where sql_id='78bd3uh5a08av'; PLAN_HASH_VALUE CHILD_NUMBER --------------- ------------ 3956160932 0 3956160932 1
注意到上述SQL在V$SQL中有兩條匹配記錄,且這兩條記錄的CHILD_NUMBER的值分別為0和1,說明Oracle在執行上述SQL時確實產生了兩個Child Cursor,它們的子游標號分別為0和1.
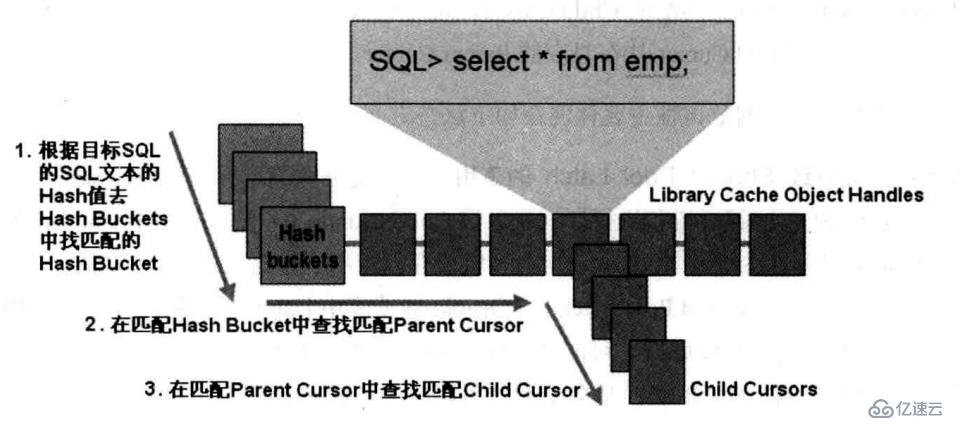
Oracle在解析目標SQL時去庫緩存中查找匹配Shared Cursor的過程實際上是在依次順序執行如下步驟:
(1)根據目標SQL的SQL文本的哈希值去庫緩存中找匹配的Hash Bucket。注意,更準確的說,這里的哈希運算是基于對應庫緩存對象句柄的屬性Name和Namespace的值的,只不過對于SQL語句而言,其對應的庫緩存對象句柄的屬性Name的值就是該SQL的SQL文本,屬性Namespace的值就是常量“CRSR”,所以這里可以近似看作是只根據目標SQL的SQL文本來做哈希運算。
(2)然后在匹配的Hash Bucket的庫緩存對象鏈表中查找匹配的Parent Cursor,當然,在查找匹配Parent Cursor的過程中肯定會比對目標SQL的SQL文本(因為不同的SQL文本計算出來的哈希值可能是相同的)。
(3)步驟2如果找到了匹配的Parent Cursor,則Oracle接下來就會遍歷從屬于該Parent Cursor的所有Child Cursor以查找匹配的Child Cursor。
(4)步驟2如果找不到了匹配的Parent Cursor,則也意味著此時沒有可以共享的解析樹和執行計劃,Oracle就會從頭開始解析上述目標SQL,新生成一個Parent Cursor和一個Child Cursor,并把它們掛在對應的Hash Bucket中。
(5)步驟3如果找到了匹配的Child Cursor,則Oracle就會把存儲于該Child Cursor中的解析樹和執行計劃直接拿過來重用,而不用再從頭開始解析。
(6)步驟3如果找不到匹配的Child Cursor,則意味著沒有可以共享的解析樹和執行計劃,接下來Oracle也會從頭開始解析上述目標SQL,新生成一個Child Cursor,并把這個Child Cursor掛在對應的Parent Cursor下。
1.2 硬解析
硬解析(Hard Parse)是指Oracle在執行目標SQL時,在庫緩存中找不到可以重用的解析樹和執行計劃,而不得不從頭開始解析目標SQL并生成相應的Parent Cursor和Child Cursor的過程。
硬解析實際上有兩種類型,一種是在庫緩存中找不到匹配的Parent Cursor,此時Oracle會從頭開始解析目標SQL,新生成一個Parent Cursor和Child Cursor,并把它們掛在對應的Hash Bucket中;另一種是找到了匹配的Parent Cursor但未找到匹配的Child Cursor,此時Oracle也會從頭開始解析該目標SQL,新生成一個Child Cursor,并把這個Child Cursor掛在對應的Parent Cursor下。
硬解析是非常不好的,它的危害性主要體現在如下這些方面:
硬解析可能會導致Shared Pool Latch的爭用。無論是哪種類型的硬解析,都至少需要新生成一個Child Cursor,并把目標SQL的解析樹和執行計劃載入該Child Cursor里,然后把這個Child Cursor存儲在庫緩存中。這意味著Oracle必須在Shared Pool中分配出一塊內存區域用于存儲上述Child Cursor,而在Shared Pool中分配內存這個動作是要持有Shared Pool Latch的(Oracle數據庫中的Latch的作用之一就是保護共享內存的分配),所以如果有一定數量的并發硬解析,可能會導致Shared Pool Latch爭用,而且一旦發生大量的Shared Pool Latch爭用,系統的性能和可擴展性會受到嚴重影響(常常表現為CPU的占用率居高不下,接近100%)。
硬解析可能會導致庫緩存相關Latch(如Library Cache Latch)和Mutex的爭用。無論是哪種類型的硬解析,都需要掃描相關的Hash Bucket中的庫緩存對象句柄鏈表,而掃描庫緩存對象句柄鏈表這個動作是要持有Library Cache Latch的(Oracle數據庫中Latch的另外一個作用就是用于共享SGA內存結構的并發訪問控制),所以如果有一定數量的并發硬解析,則可能會導致Library Cache Latch的爭用。和Shared Pool Latch爭用一樣,一旦發生大量的Library Cache Latch的爭用,系統的性能和可擴展性也會受到嚴重影響。從11gR1開始,Oracle用Mutex替換了庫緩存相關Latch,所以在Oracle 11gR1及其后續的版本中,將不再存在庫緩存相關Latch的急用,取而代之的是Mutex的爭用(可以簡單的將Mutex理解成一種輕量級的Latch,Mutex主要也是用于共享SGA內存結果的并發訪問控制),Oracle也因此引入了一系列新的等待事件來描述這種Mutex的爭用,比如:Cursor: pin S、Cursor: pin X、Cursor: pin S wait on X、Cursor:mutex S、Cursor:mutex X、Library cache:mutex X等。
另外需要注意的是,Oracle在做硬解析時對Shared Pool Latch和Library Cache Latch的持有過程,大致如下:Oracle首先持有Library Cache Latch,在庫緩存中掃描相關Hash Bucket中的庫緩存對象句柄鏈表,以查看是否有匹配的Parent Cursor,然后釋放Library Cache Latch(這里釋放的原因是因為沒有找到匹配的parent Cursor)。接下來是硬解析的后半部分,首先持有Library Cache Latch,然后在不釋放Library Cache Latch的情況下持有Shared Pool Latch,以便從Shared Pool中申請分配內存,成功申請后就會釋放Shared Pool Latch,最后再釋放Library Cache Latch,詳細過程可以參考http://www.laoxiong.net/shared-pool-latch-and-library-cache-latch.html。
對于OLTP類型的系統而言,硬解析是萬惡之源。
1.3 軟解析
軟解析(Soft Parse)是指Oracle在執行目標SQL時,在Library Cache中找到了匹配的Parent Cursor和Child Cursor,并將存儲在Child Cursor中的解析樹和執行計劃直接拿過來重用,無須從頭開始解析的過程。
和硬解析相比,軟解析的優勢主要表現在如下幾個方面:
軟解析不會導致Shared Pool Latch的爭用。因為軟解析能夠在庫緩存中找到匹配的Parent Cursor和Child Cursor,所以它不需要生成新的Parent Cursor和Child Cursor。這意味著軟解析根本就不需要持有Shared Pool Latch以便在Shared Pool中申請分配一塊共享內存區域,既然不需要持有Shared Pool Latch,自然不會有Shared Pool Latch爭用,即Shared Pool Latch的爭用所帶來的系統性能和可擴展性的問題對軟解析來說并不存在。
軟解析雖然也可能會導致庫緩存相關Latch(如Library Cache Latch)和Mutex的爭用,但軟解析持有庫緩存相關Latch的次數要少,而且軟解析對某些Latch(如Library Cache Latch)持有的時間會比硬解析短,這意味著即使產生了庫緩存相關Latch的爭用,軟解析的爭用程度也沒有硬解析那么嚴重,即庫緩存相關Latch和Mutex的爭用所帶來的系統性能和可擴展性的問題對軟解析來說要比硬解析少很多。
正是基于上述兩個方面的原因,如果OLTP類型的系統在執行目標SQL時能夠廣泛使用軟解析,則系統的性能和可擴展性就會比全部使用硬解析時有顯著的提升,執行目標SQL時需要消耗的系統資源(主要體現在CPU上)也會顯著降低。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





