溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
在SQL 和 PL/SQL 中使用正則表達式
| 函數名稱 | 描述 |
| REGEXP_LIKE | 與LIKE運算符類似,但執行正則表達式匹配,而不是簡單的模糊匹配(條件) |
| REGEXP_REPLACE | 以正則表達式搜索和替換字符串 |
| REGEXP_INSTR | 以正則表達式搜索字符串,并返回匹配的位置 |
| REGEXP_SUBSTR | 以正則表達式搜索和提取匹配字符串 |
| REGEXP_COUNT | 返回匹配的次數 |
什么是元字符?
元字符是特殊字符有特殊的含義,如一個通配符,重復字符,一個不匹配的字符,一個范圍內的符。
您可以使用多個預定義的元字符符號的模式匹配。
例如, ^(f|ht)tps?:$ 正則表達式搜索字符串從以下開始:
– 字面值 f 或 ht
– 字面值 t
– 字面值 p,字面值s 可選
– 冒號“:” 結尾的字面值
正則表達式的元字符
| 語法 | 描述 |
| . | Matches any character in the supported character set, except NULL |
| + | Matches one or more occurrences |
| ? | Matches zero or one occurrence |
| * | Matches zero or more occurrences of the preceding subexpression |
| {m} | Matches exactly m occurrences of the preceding expression |
| {m, } | Matches at least m occurrences of the preceding subexpression |
| {m,n} | Matches at least m, but not more than n, occurrences of the preceding subexpression |
| […] | Matches any single character in the list within the brackets |
| | | Matches one of the alternatives |
| ( ... ) | Treats the enclosed expression within the parentheses as a unit. The subexpression can be a string of literals or a complex expression containing operators. |
| ^ | Matches the beginning of a string |
| $ | Matches the end of a string |
| \ | Treats the subsequent metacharacter in the expression as a literal |
| \n | Matches the nth (1–9) preceding subexpression of whatever is grouped within parentheses. The parentheses cause an expression to be remembered; a backreference refers to it. |
| \d | A digit character |
| [:class:] | Matches any character belonging to the specified POSIX character class |
| [^:class:] | Matches any single character not in the list within the brackets |
REGEXP_LIKE (source_char, pattern [,match_option]
REGEXP_INSTR (source_char, pattern [, position
[, occurrence [, return_option
[, match_option [, subexpr]]]]])
REGEXP_SUBSTR (source_char, pattern [, position
[, occurrence [, match_option
[, subexpr]]]])
REGEXP_REPLACE(source_char, pattern [,replacestr
[, position [, occurrence
[, match_option]]]])
REGEXP_COUNT (source_char, pattern [, position
[, occurrence [, match_option]]])
使用REGEXP_LIKE 執行基本搜索
REGEXP_LIKE(source_char, pattern [, match_parameter ])
SELECT first_name, last_name FROM employees
WHERE REGEXP_LIKE (first_name, '^Ste(v|ph)en$');
使用REGEXP_REPLACE 替換
REGEXP_REPLACE(source_char, pattern [,replacestr
[, position [, occurrence [, match_option]]]])
SELECT REGEXP_REPLACE(phone_number, '\.','-') AS phone
FROM employees;
使用 REGEXP_INSTR 插入
REGEXP_INSTR (source_char, pattern [, position [,
occurrence [, return_option [, match_option]]]])
SELECT street_address,REGEXP_INSTR(street_address,'[[:alpha:]]') AS
First_Alpha_Position
FROM locations;
使用 REGEXP_SUBSTR 函數提取字符串
REGEXP_SUBSTR (source_char, pattern [, position [, occurrence [, match_option]]])
SELECT REGEXP_SUBSTR(street_address , ' [^ ]+ ') AS Road FROM locations;
子表達式
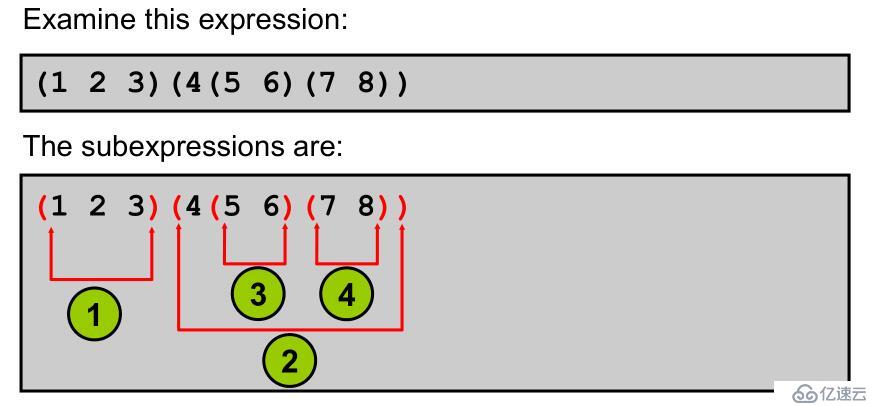
使用子表達式與正則表達式支持
SELECT
REGEXP_INSTR
('0123456789', -- source char or search value
'(123)(4(56)(78))', -- regular expression patterns
1, -- position to start searching
1, -- occurrence
0, -- return option
'i', -- match option (case insensitive)
1) -- sub-expression on which to search
"Position"
FROM dual;
為什么要訪問第n個子表達式
一個更實際的用途:DNA測序
您可能需要找到一個特定的子模式,確定了在小鼠DNA免疫
所需的蛋白質。
SELECT REGEXP_INSTR(' ccacctttccctccactcctcacgttctcacctgtaaagcgtccctc
cctcatccccatgcccccttaccctgcagggtagagtaggctagaaaccagagagctccaagc
tccatctgtggagaggtgccatccttgggctgcagagagaggagaatttgccccaaagctgcc
tgcagagcttcaccacccttagtctcacaaagccttgagttcatagcatttcttgagttttca
ccctgcccagcaggacactgcagcacccaaagggcttcccaggagtagggttgccctcaagag
gctcttgggtctgatggccacatcctggaattgttttcaagttgatggtcacagccctgaggc
atgtaggggcgtggggatgcgctctgctctgctctcctctcctgaacccctgaaccctctggc
taccccagagcacttagagccag ',
'(gtc(tcac)(aaag))',
1, 1, 0, 'i',
1) "Position"
FROM dual;
REGEXP_SUBSTR 示例
SELECT
REGEXP_SUBSTR
('acgctgcactgca', -- source char or search value
'acg(.*)gca', -- regular expression pattern
1, -- position to start searching
1, -- occurrence
'i', -- match option (case insensitive)
1) -- sub-expression
"Value"
FROM dual;
使用 REGEXP_COUNT函數
REGEXP_COUNT (source_char, pattern [, position
[, occurrence [, match_option]]])
SELECT REGEXP_COUNT(
'ccacctttccctccactcctcacgttctcacctgtaaagcgtccctccctcatccccatgcccccttaccctgcag
ggtagagtaggctagaaaccagagagctccaagctccatctgtggagaggtgccatccttgggctgcagagagaggag
aatttgccccaaagctgcctgcagagcttcaccacccttagtctcacaaagccttgagttcatagcatttcttgagtt
ttcaccctgcccagcaggacactgcagcacccaaagggcttcccaggagtagggttgccctcaagaggctcttgggtc
tgatggccacatcctggaattgttttcaagttgatggtcacagccctgaggcatgtaggggcgtggggatgcgctctg
ctctgctctcctctcctgaacccctgaaccctctggctaccccagagcacttagagccag' ,
'gtc') AS Count
FROM dual;
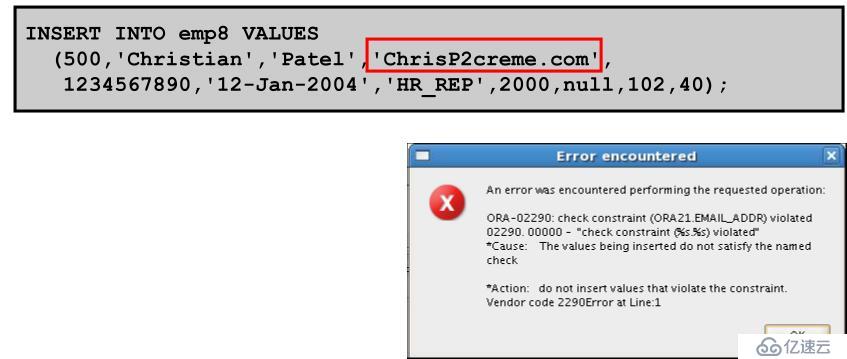
Check約束和正則表達式:示例
ALTER TABLE emp8
ADD CONSTRAINT email_addr
CHECK(REGEXP_LIKE(email,'@')) NOVALIDATE;
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





