溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
下文給大家帶來關于什么是Mysql數據庫的四類隔離級別,感興趣的話就一起來看看這篇文章吧,相信看完什么是Mysql數據庫的四類隔離級別對大家多少有點幫助吧。
由MySQL AB公司開發,是最流行的開放源碼SQL數據庫管理系統,主要特點:
1、是一種數據庫管理系統
2、是一種關聯數據庫管理系統
3、是一種開放源碼軟件,且有大量可用的共享MySQL軟件
4、MySQL數據庫云服務器具有快速、可靠和易于使用的特點
5、MySQL云服務器工作在客戶端/云服務器模式下,或嵌入式系統中
InnoDB存儲引擎將InnoDB表保存在一個表空間內,該表空間可由數個文件創建。這樣,表的大小就能超過單獨文件的最大容量。表空間可包括原始磁盤分區,從而使得很大的表成為可能。表空間的最大容量為64TB。
2.1. 低級別的隔離級一般支持更高的并發處理,并擁有更低的系統開銷。
Read Uncommitted (讀未提交)
在該隔離級別,所有事務都可以看到其他未提交事務的執行結果。本隔離級別很少用于實際應用,因為它的性能也不比其他級別好多少。讀取未提交的數據,也被稱之為臟讀(Dirty Read)。
Read Committed (讀提交)
這是大多數數據庫系統的默認隔離級別(但不是MySQL默認的)。它滿足了隔離的簡單定義:一個事務只能看見已經提交事務所做的改變。這種隔離級別 也支持所謂的不可重復讀(Nonrepeatable Read),因為同一事務的其他實例在該實例處理其間可能會有新的commit,所以同一select可能返回不同結果。
Repeatable Read (可重讀)
這是MySQL的默認事務隔離級別,它確保同一事務的多個實例在并發讀取數據時,會看到同樣的數據行。不過理論上,這會導致另一個棘手的問題:幻讀 (Phantom Read)。簡單的說,幻讀指當用戶讀取某一范圍的數據行時,另一個事務又在該范圍內插入了新行,當用戶再讀取該范圍的數據行時,會發現有新的“幻影” 行。InnoDB和Falcon存儲引擎通過多版本并發控制(MVCC,Multiversion Concurrency Control)機制解決了該問題。
Serializable (可串行)
這是最高的隔離級別,它通過強制事務排序,使之不可能相互沖突,從而解決幻讀問題。簡言之,它是在每個讀的數據行上加上共享鎖。在這個級別,可能導致大量的超時現象和鎖競爭。
2.2. 這四種隔離級別采取不同的鎖類型來實現,若讀取的是同一個數據的話易發生問題。如:
臟讀(Drity Read):某個事務已更新一份數據,另一個事務在此時讀取了同一份數據,由于某些原因,前一個RollBack了操作,則后一個事務所讀取的數據就會是不正確的。
不可重復讀(Non-repeatable read):在一個事務的兩次查詢之中數據不一致,這可能是兩次查詢過程中間插入了一個事務更新的原有的數據。
幻讀(Phantom Read):在一個事務的兩次查詢中數據筆數不一致,例如有一個事務查詢了幾列(Row)數據,而另一個事務卻在此時插入了新的幾列數據,先前的事務在接下來的查詢中,就會發現有幾列數據是它先前所沒有的。
2.3. 在MySQL中,實現了這四種隔離級別,分別有可能產生問題如下所示:
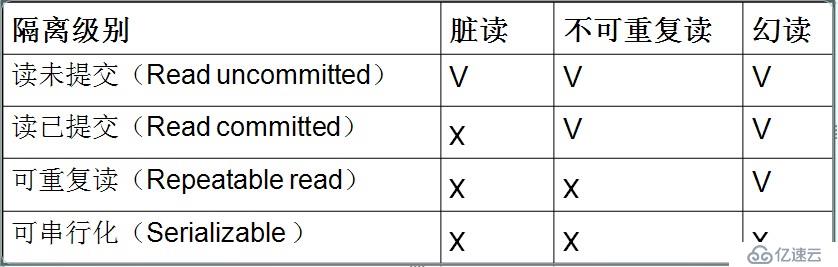
mysql> SHOW GLOBAL VARIABLES LIKE '%iso%'; #查看隔離級別,或select @@tx_isolation
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| tx_isolation | REPEATABLE-READ | #mysql默認為可重讀
+---------------+-----------------+
1 row in set (0.00 sec)
測試數據庫為test,表為tx;表結構:
| id | int |
num | int |
兩個命令行客戶端分別為A,B;不斷改變A的隔離級別,在B端修改數據。
3.1. 將A的隔離級別設置為read uncommitted(讀未提交)
mysql> SET tx_isolation='READ-UNCOMMITTED'
在B未更新數據之前:
客戶端A:
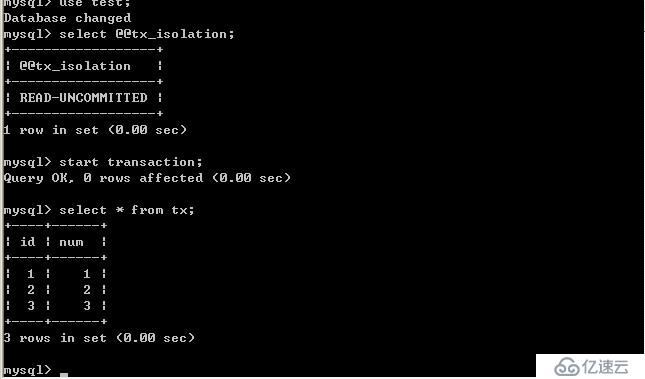
B更新數據:
客戶端B:
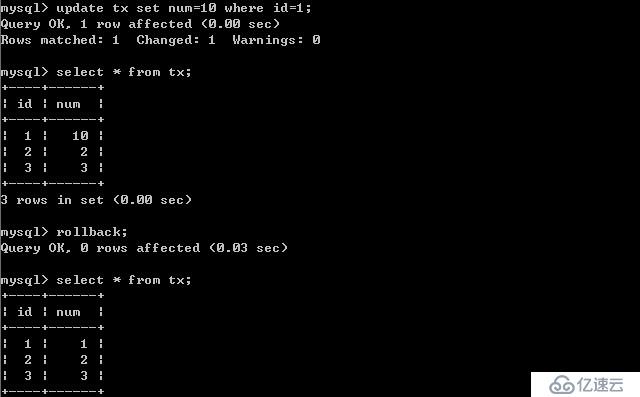
客戶端A:
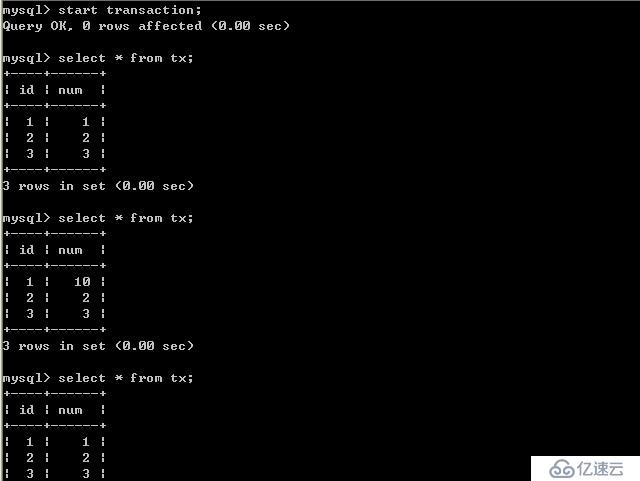
經過上面的實驗可以得出結論,事務B更新了一條記錄,但是沒有提交,此時事務A可以查詢出未提交記錄。造成臟讀現象。未提交讀是最低的隔離級別。
3.2. 將客戶端A的事務隔離級別設置為read committed (讀提交)
mysql> SET tx_isolation='READ-COMMITTED'
在B未更新數據之前:
客戶端A:
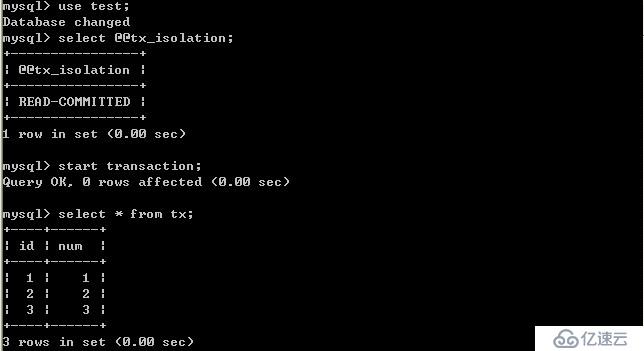
B更新數據:
客戶端B:
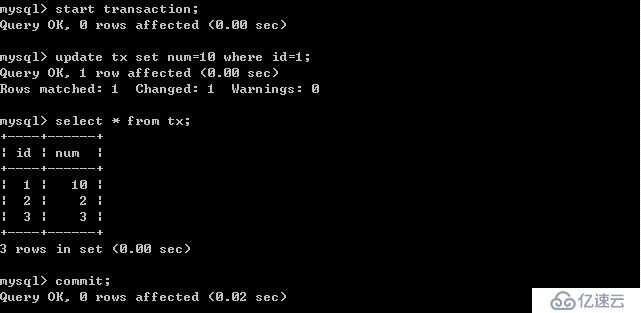
客戶端A:
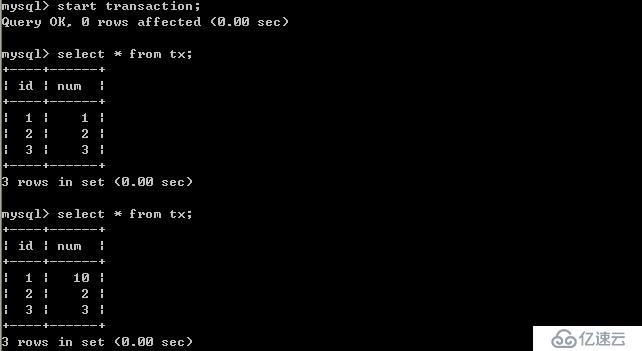
經過上面的實驗可以得出結論,已提交讀隔離級別解決了臟讀的問題,但是出現了不可重復讀的問題,即事務A在兩次查詢的數據不一致,因為在兩次查詢之間事務B更新了一條數據。已提交讀只允許讀取已提交的記錄,但不要求可重復讀。
3.3. 將客戶端A的事務隔離級別設置為repeatable read (可重讀)
mysql> SET tx_isolation='REPEATABLE-READ'
在B未更新數據之前:
客戶端A:
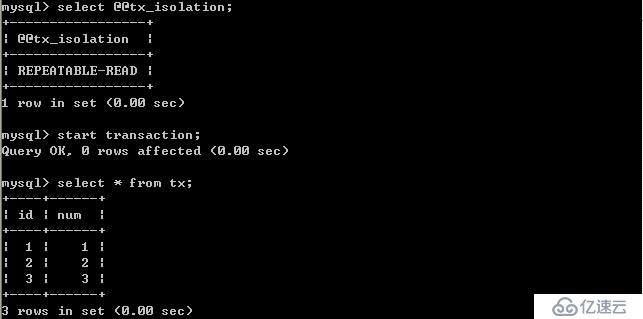
B更新數據:
客戶端B:
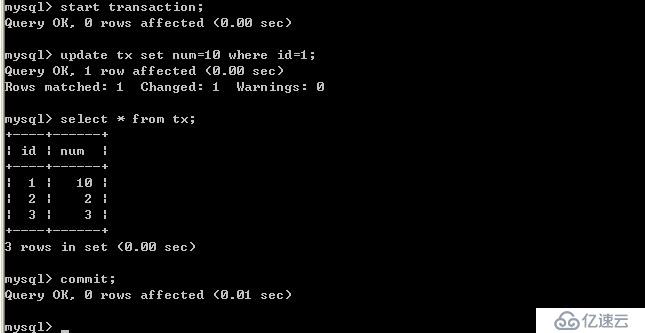
客戶端A:
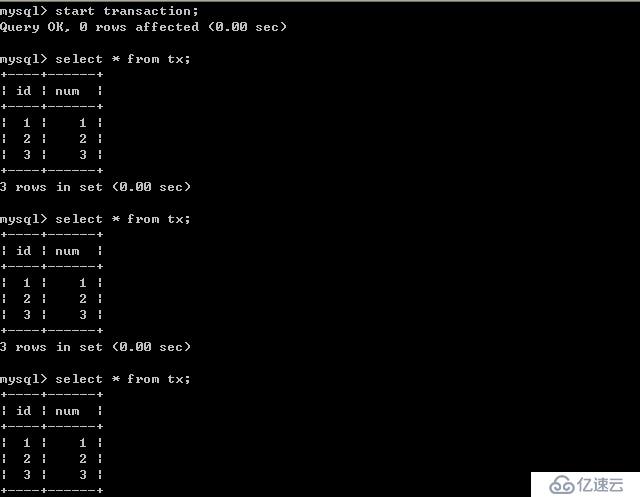
B插入數據:
客戶端B:
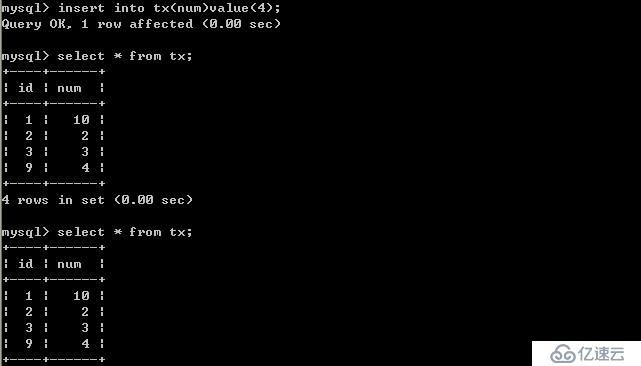
客戶端A:
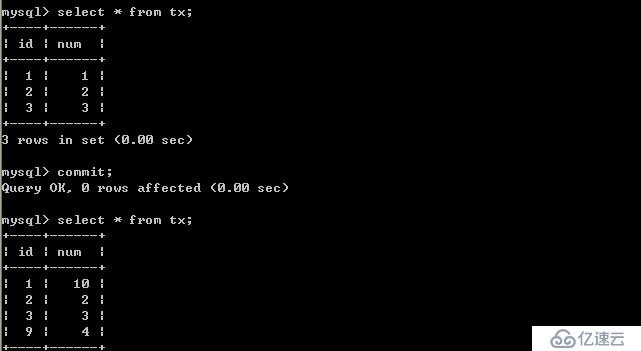
由以上的實驗可以得出結論,可重復讀隔離級別只允許客戶端讀取已提交記錄,并且必須是自己該客戶端的事務提交后才能看到,其他客戶端更新的并提交了的數據。這樣也是會造成幻讀,因為客戶端事務提交前后所讀取的數據可能不一樣,如果其他客戶端更新了數據,并提交了事務,那當前這個客戶端沒做任何操作,只是事務提交前后所讀取的內容不一致造成幻讀。
3.4. 將客戶端A的事務隔離級別設置為Serializable (可串行)
mysql> SET tx_isolation='SERIALIZABLEA'
A端打開事務,B端插入一條記錄
事務A端:

事務B端:

因為此時事務A的隔離級別設置為serializable,開始事務后,并沒有提交,所以事務B只能等待。
事務A提交事務:
事務A端

事務B端
 serializable完全鎖定字段,若一個事務來查詢同一份數據就必須等待,直到前一個事務完成并解除鎖定為止 。是完整的隔離級別,會鎖定對應的數據表格,因而會有效率的問題。
serializable完全鎖定字段,若一個事務來查詢同一份數據就必須等待,直到前一個事務完成并解除鎖定為止 。是完整的隔離級別,會鎖定對應的數據表格,因而會有效率的問題。
看了以上關于什么是Mysql數據庫的四類隔離級別詳細內容,是否有所收獲。如果想要了解更多相關,可以繼續關注我們的行業資訊板塊。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





