溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
SQL Server 2016 Failover Cluster+ ALwaysOn(三)
我們前面兩篇文章介紹了SQL Server 2016 Failover Cluster的配置,同時又介紹配置新增AlwaysOn節點的先前條件,今天我們主要介紹Always的詳細配置。我們前面已經提到了,如果要實現SQL Server 2016 Failover Cluster+ ALwaysOn,SQL Server Failover Cluster兩個節點或者多個節點安裝一個SQL 實例,然后ALwaysOn也需要安裝一個單獨的實例,雖然AlwaysOn節點必須要加入Faillover Cluster中,但是要創建AlwaysOn必須要它和之前的SQL群集實例之間創建AlwaysOn可用性組關系。另外AlwaysOn功能的開啟是在實例級設置的,這里一共有2個SQL實例,所以就需要對這2個SQL實例分別進行設置。對于SQL群集實例,在其任一所有者節點上使用SQL Server configuration manager設置一次就可以了(重啟SQL服務后生效)。
我們還是繼續回顧上面的架構圖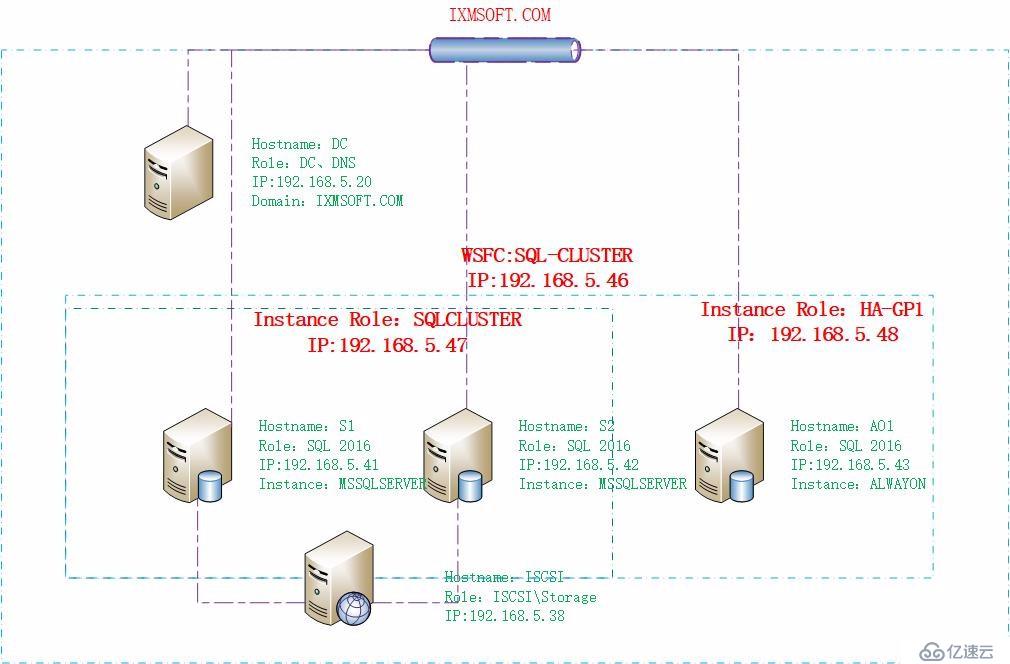
接下來我們配置ALwaysOn High Availability,我們發現提示錯誤,但是有引導我們如何配置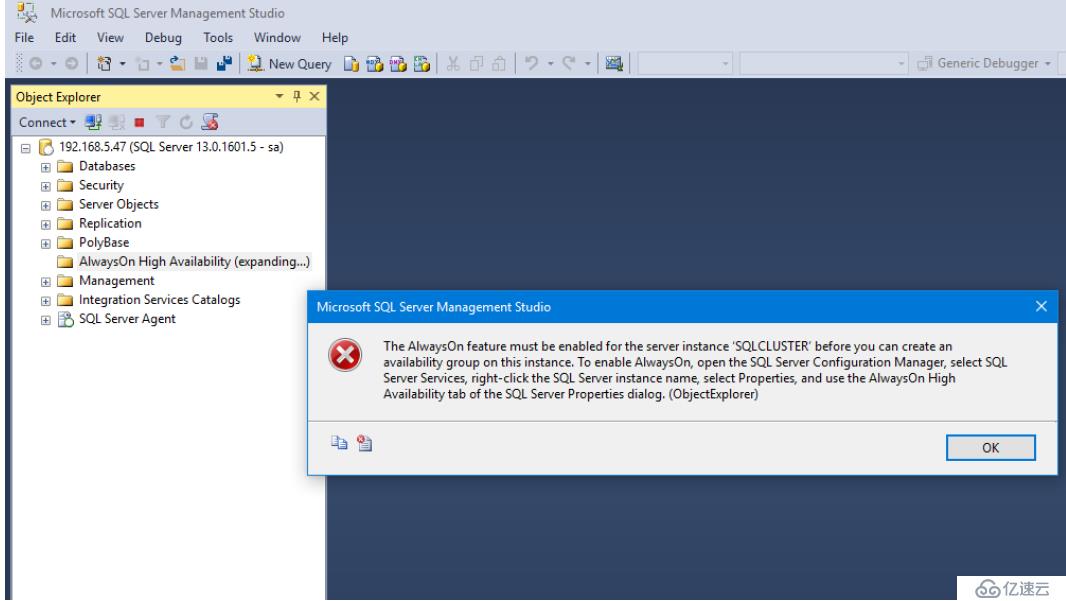
我們通過SSMS右擊--AlwayOn High Avaliablity 會有一個提示,意思是必須為服務器實例啟用AlwaysOn功能,之后才能在此實例上創建可用性組,若要啟用AlowaysOn,請打開SQL Server配置管理器,右鍵單擊SQL Server實例名稱,選擇屬性,然后使用SQL Server屬性對話框的AlwaysOn高可用性選項卡,我們鏈接集群地址,點擊ALways High Availability,提示我們開啟的方法了
注意:我們使用SSMS連接到SQL Server后,在服務器屬性對話框中,單擊一般頁面。 的HADR啟用屬性
顯示下列值之一:真正的如果啟用了總是在可用性組織;假,如果總是在可用性組是禁用的。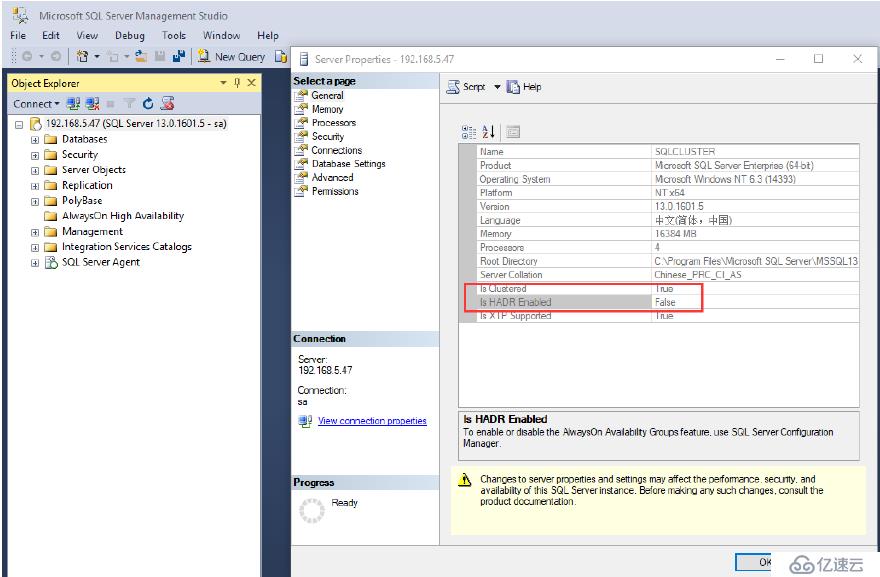
所以我們要開啟功能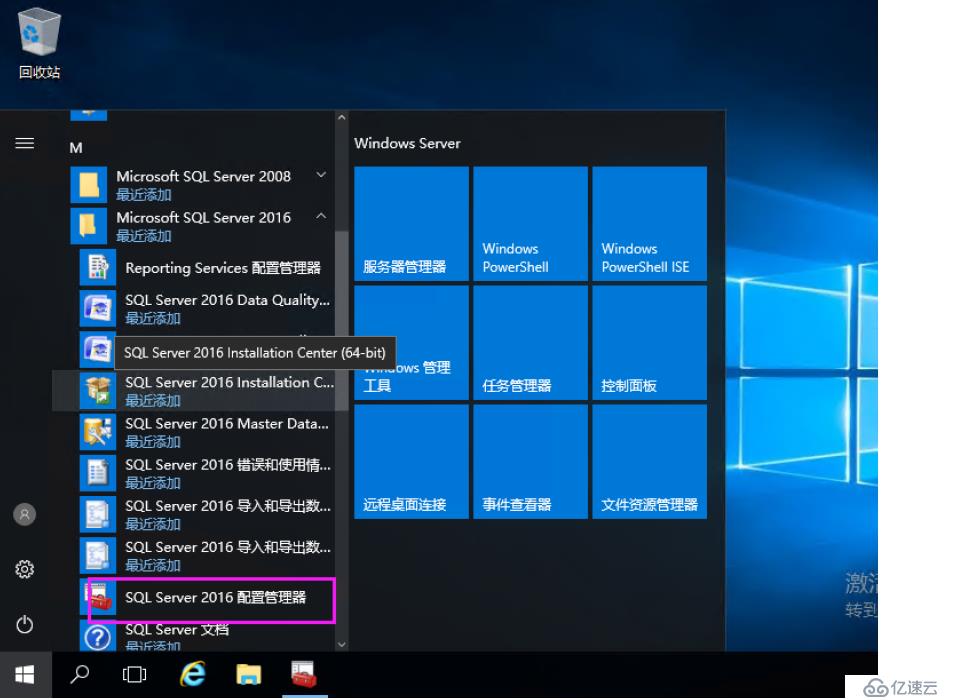
SQL Server服務---屬性--右擊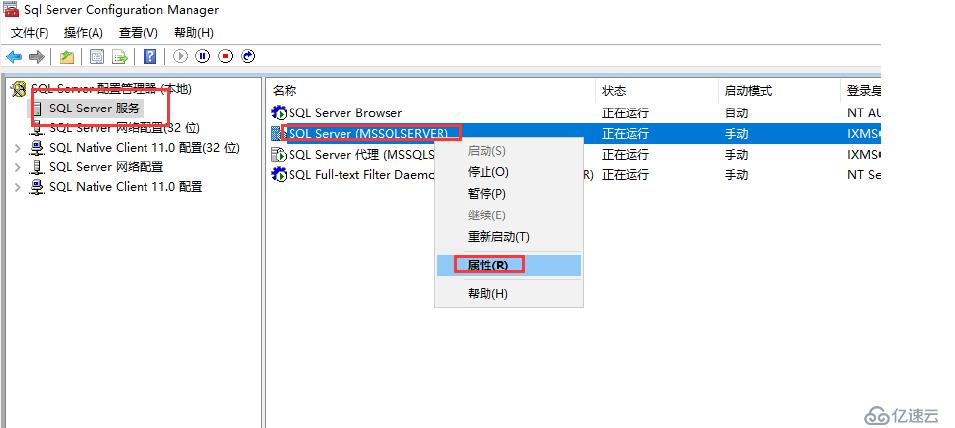
我們將SQL Server服務的登錄賬戶換成域賬戶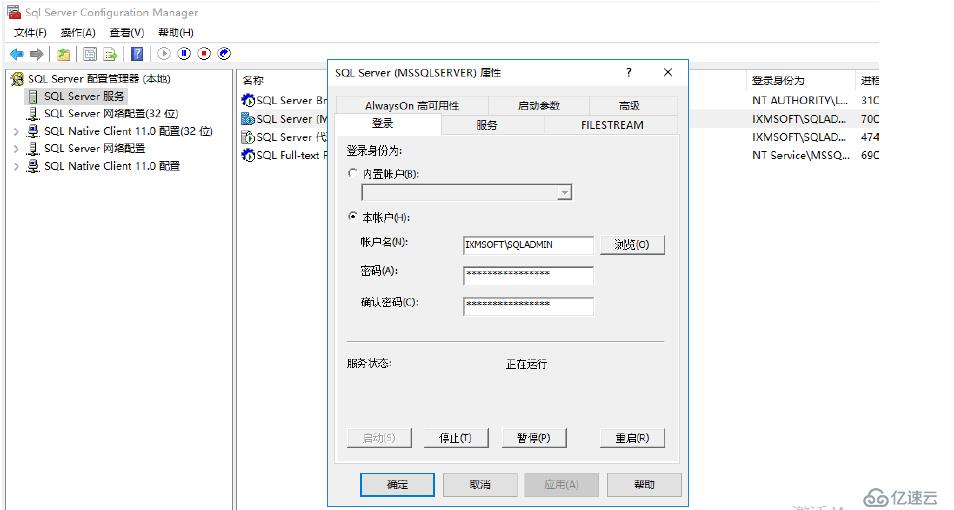
我們勾選啟用AlwayOn可用性組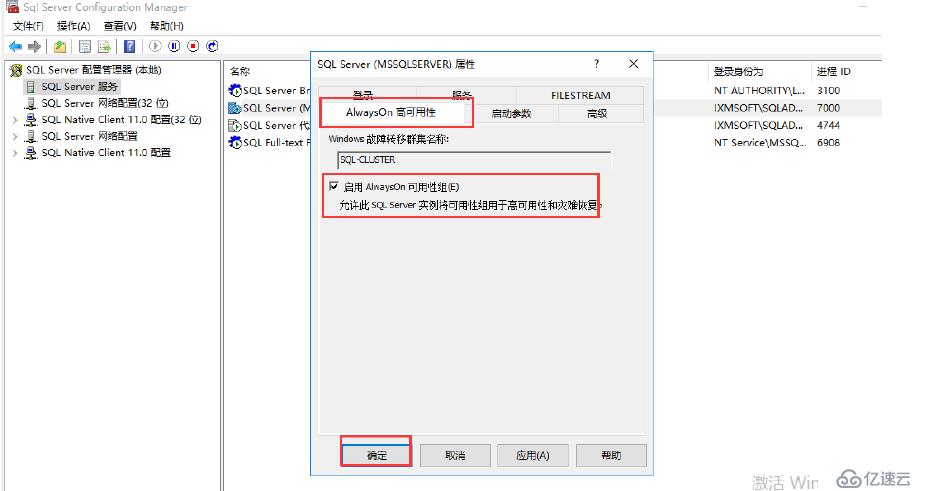
應用--確認后,需要重啟數據庫服務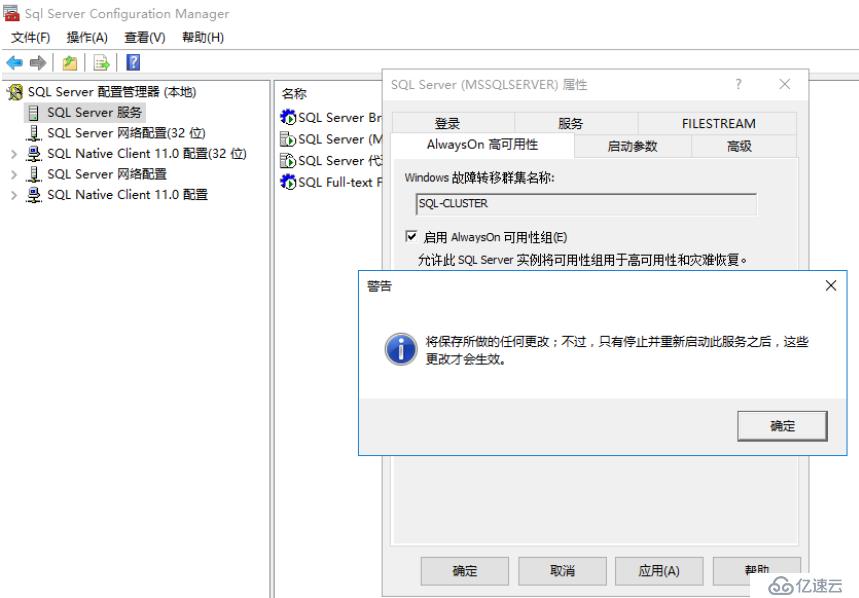
正在重啟服務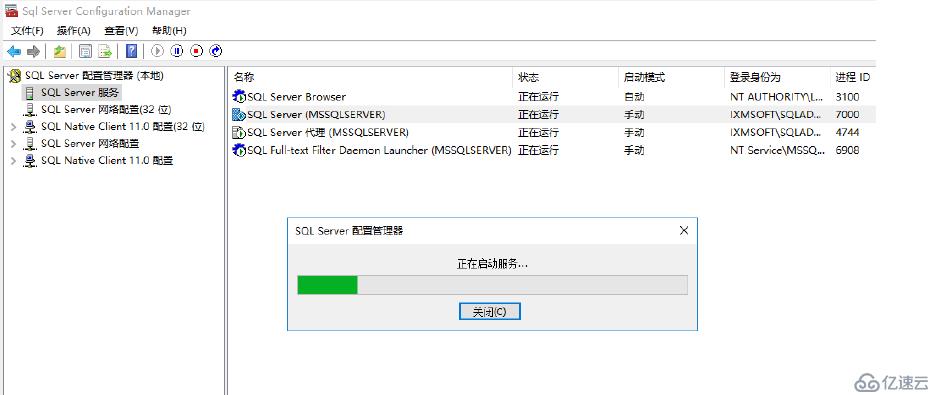
第二臺服務器的AlwaysOn當節點切換到節點2的時候,發先是自動勾選的;所以不用勾選;另外當角色不在操作的節點的時候,我們就會發現LWAYSON高可用無法操作;屬于正常現
象;我們可以通過系統提示的信息就會知道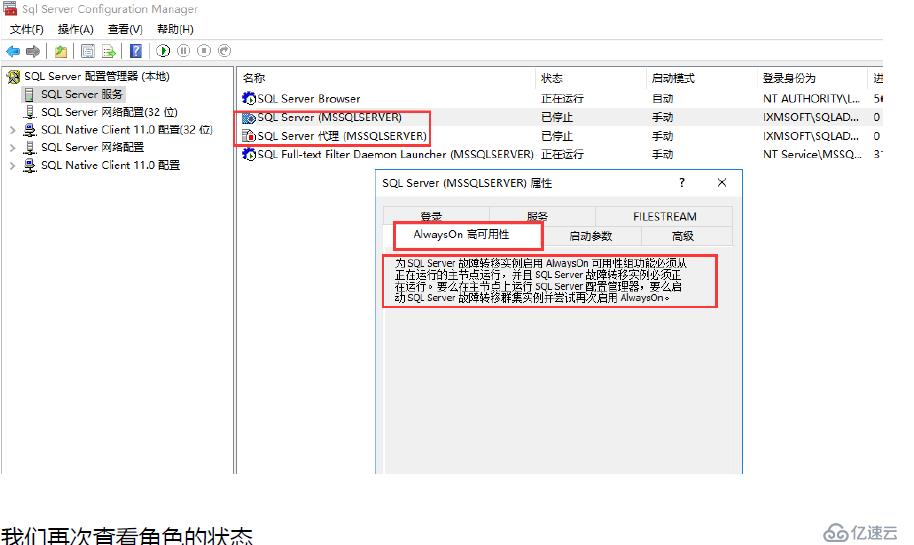
我們再次查看角色的狀態:以下狀態屬于正常現象,原因是由于啟用了ALwaysOn高可用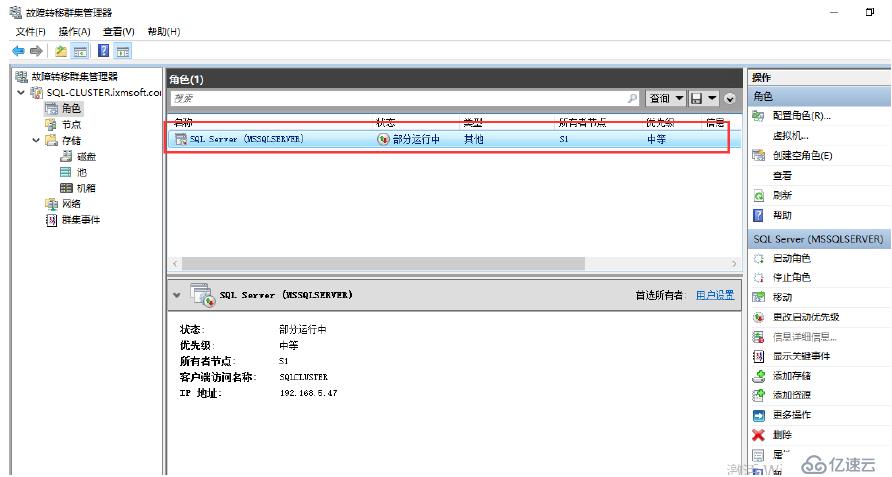
這種情況下可以選擇在節點上3安裝一個SQL命名實例,然后在它和之前的SQL群集實例之間創建AlwaysOn可用性組關系。
另外AlwaysOn功能的開啟是在實例級設置的,這里你一共有2個SQL實例,所以就需要對這2個SQL實例分別進行設置。對于SQL群集實例,在其任一所有者節點上使用SQL Server
configuration manager設置一次就可以了(重啟SQL服務后生效)。
我們同樣先將節點三的ALwaysOn高可用×××打開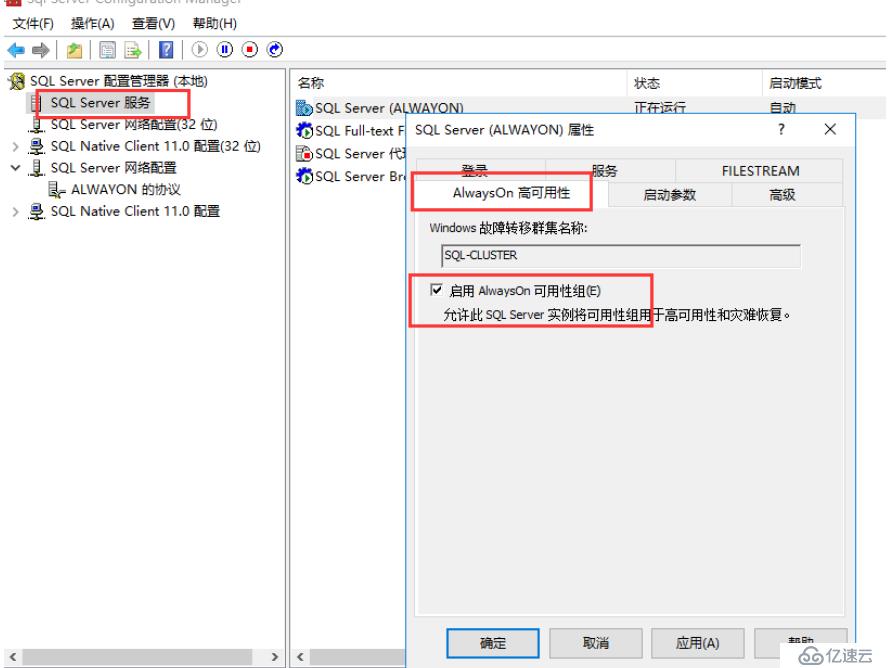
我們用SSMS鏈接實例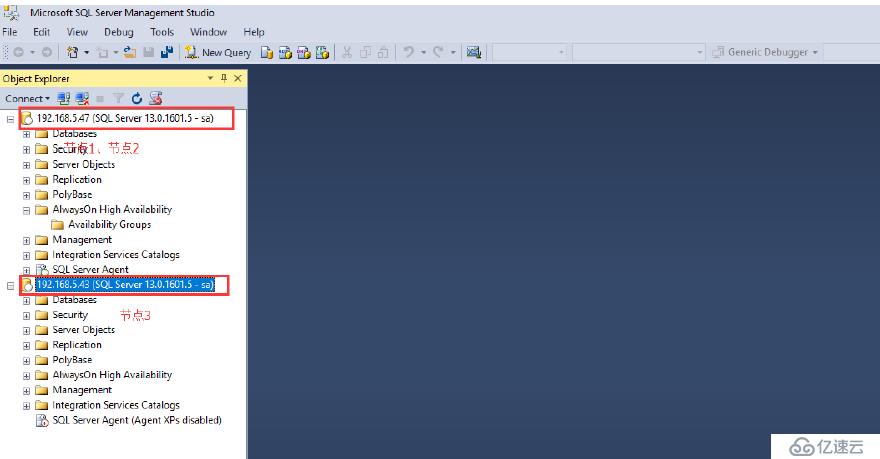
我們都知道高可用性是基于DB的,所以我們需要創建數據庫:HAGourpDB1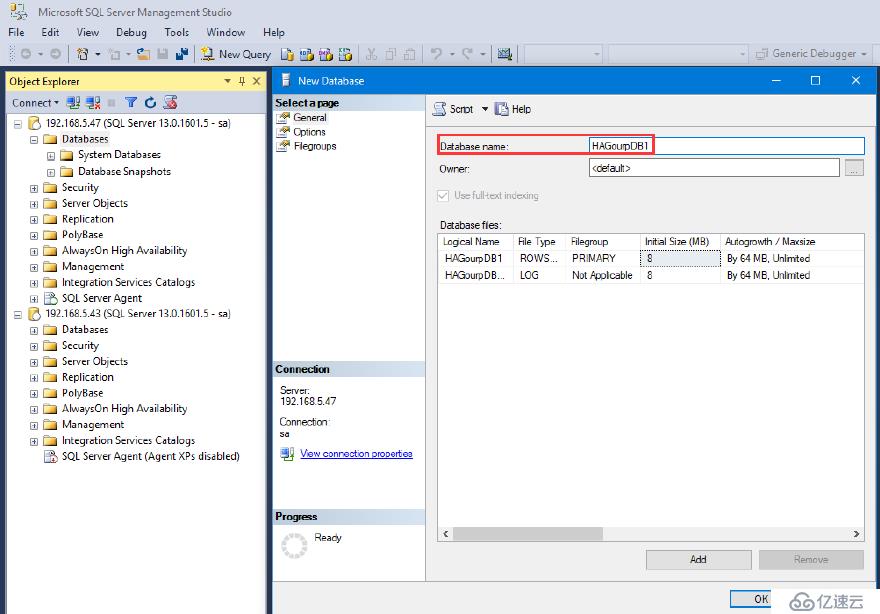
同時創建一張表,perinfo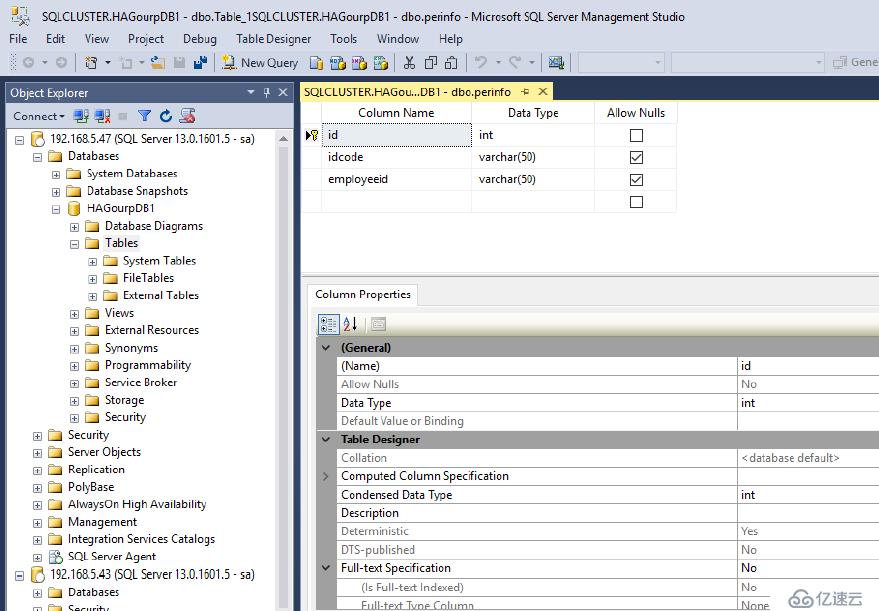
我們插入數據
我們開始在集群實例下創建高可用性組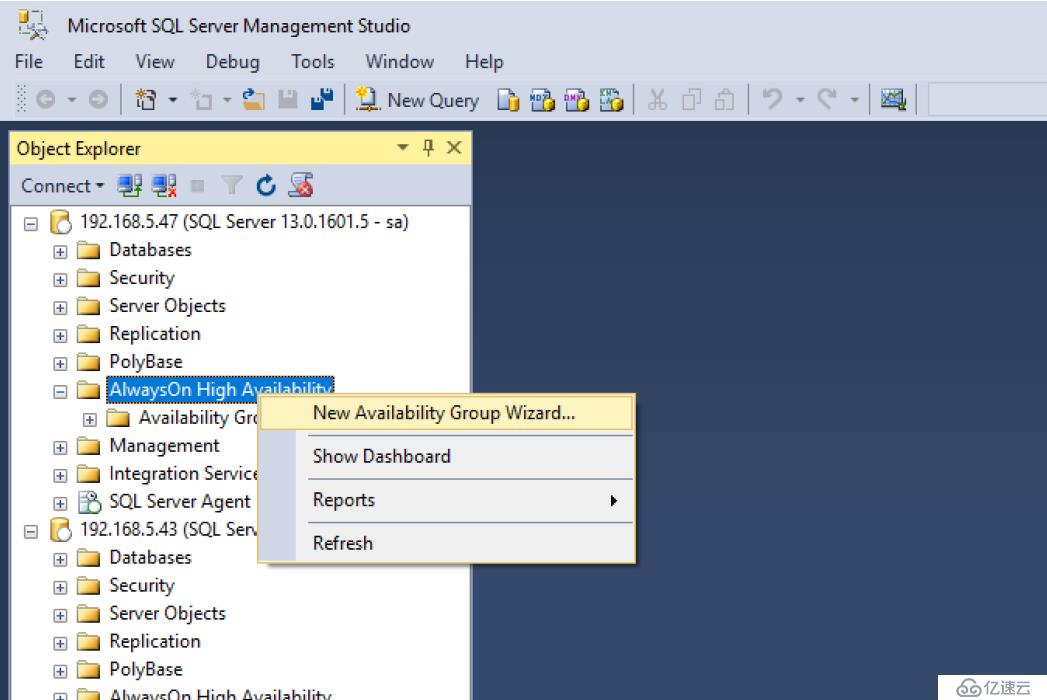
勾選數據庫層運行狀態檢測,定義高可用性組的名稱:HA-GP1
提示需要首先完整備份
所以我們先備份一下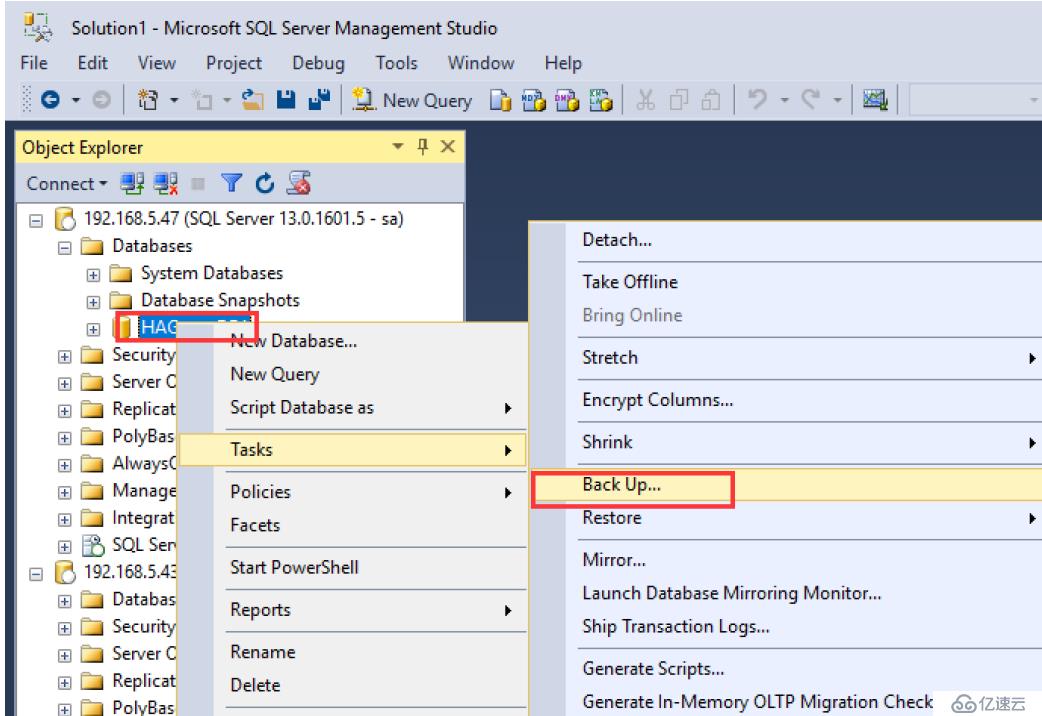
完整備份及備份類型
備份完成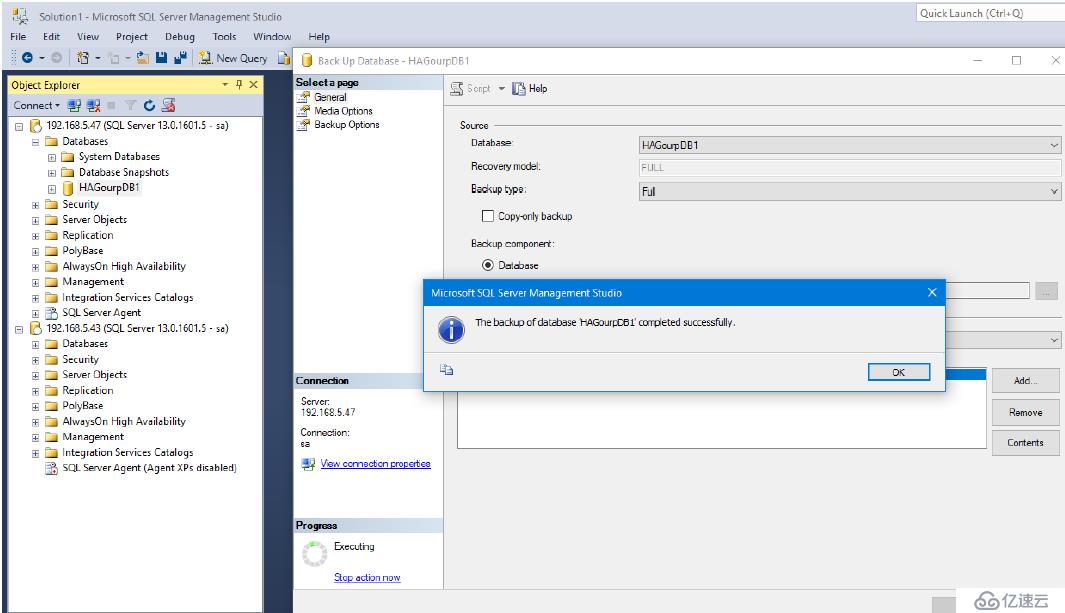
我們同樣備份Log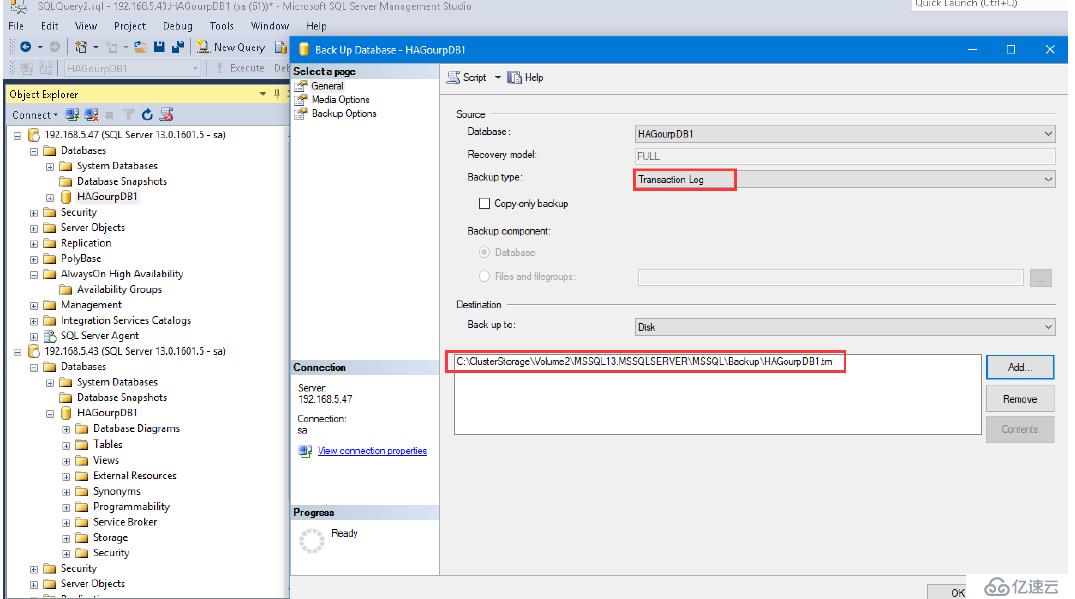
我們需要將備份的數據庫和log在三節點還原一次
恢復狀態:RESTORE WITH NORECOVERY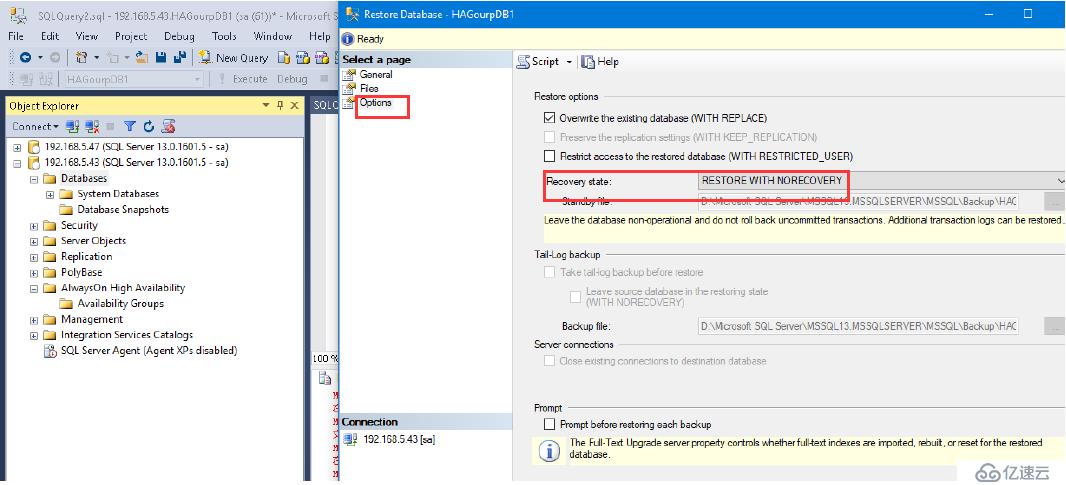
恢復完成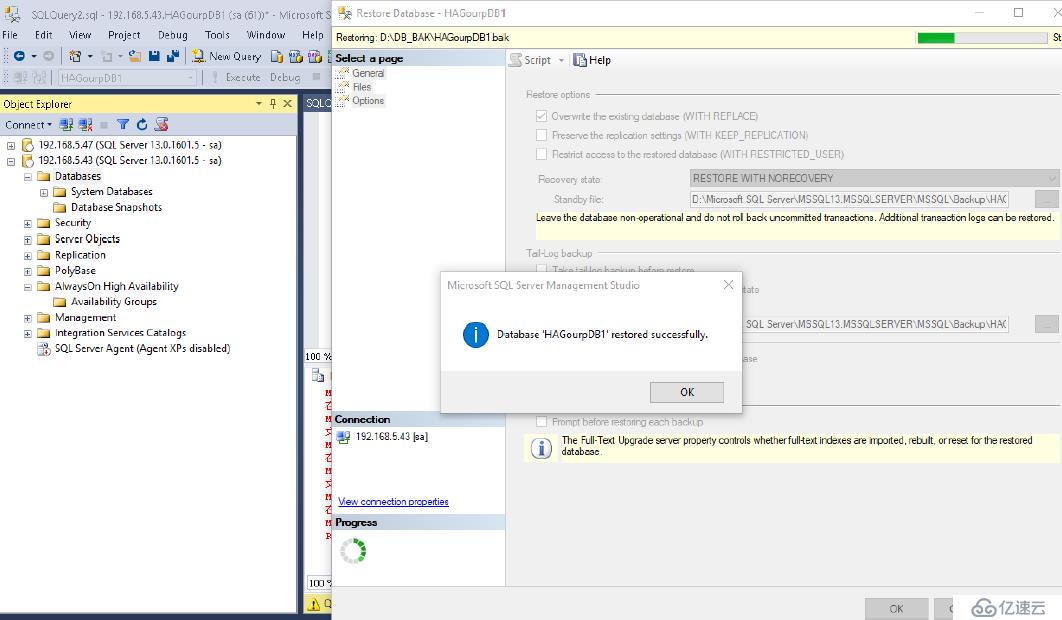
數據庫狀態未還原模式
恢復事務log
同樣選擇恢復狀態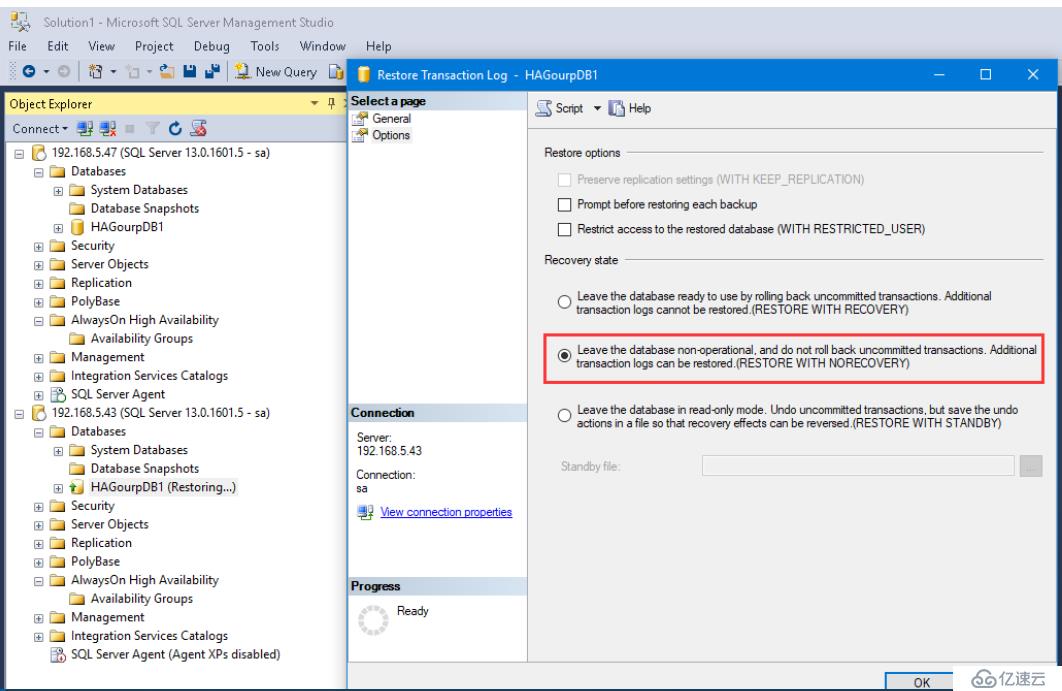
恢復完成
我們繼續創建高可用性組,滿足條件繼續下一步
我們增加副本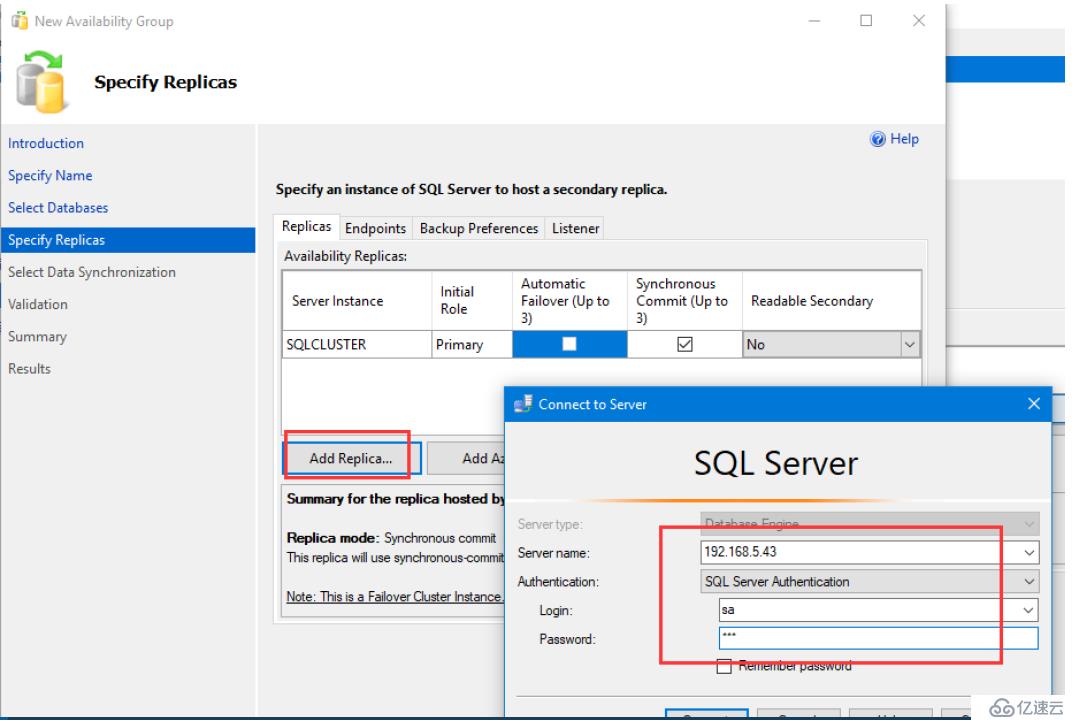
無論是主副本或者輔助副本都選擇同步提交模式,輔助副本的Readable Secondary選擇為Yes。只是為了后面的只讀輔助數據庫準備。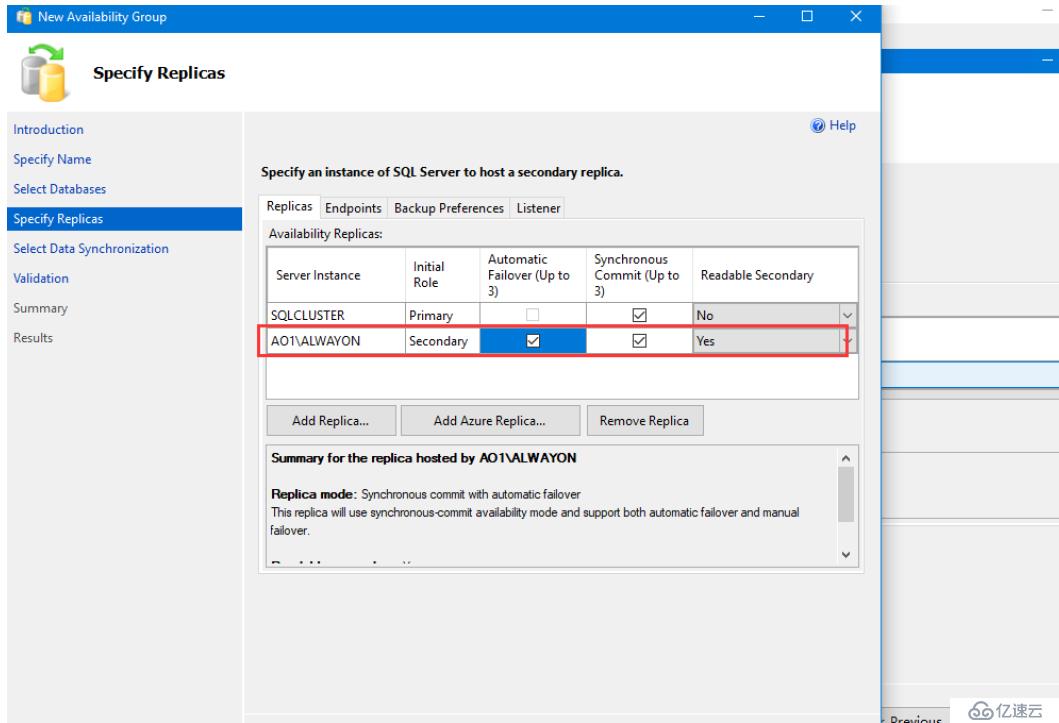
AlwaysOn和鏡像一樣都采用Endpoint(端點)來進行數據傳輸。AlwaysOn使用端點是為了和輔助副本進行日志傳輸和心跳線的通信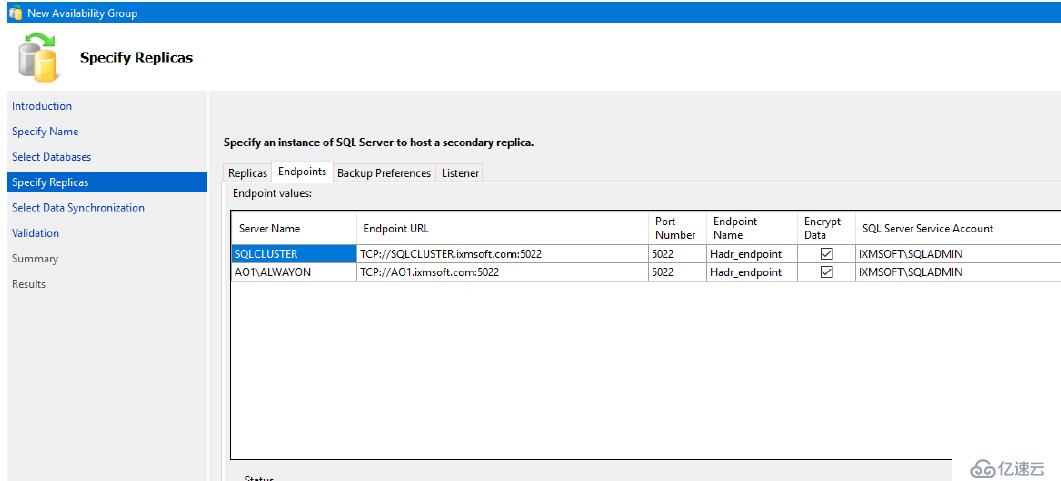
備份優先級勾選Prefer Secondary。意思是有限考慮輔助副本上做數據備份。只有在沒有輔助副本的情況下才使用主副本。把輔助副本的優先級別調為100,而主副本50。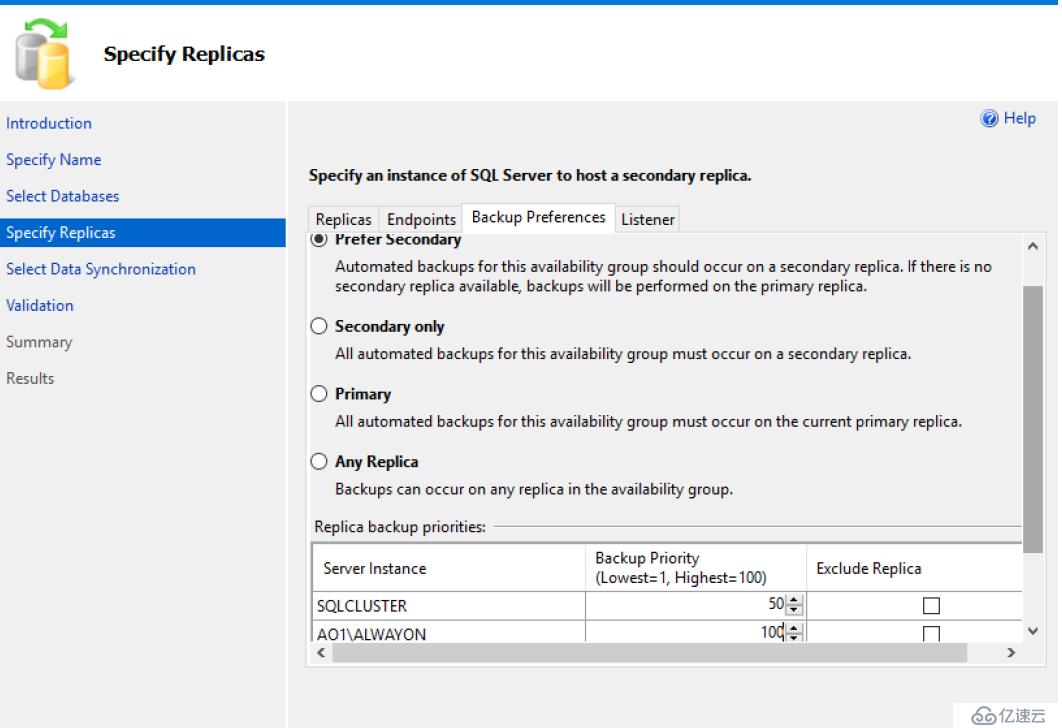
我們監聽端口稍后創建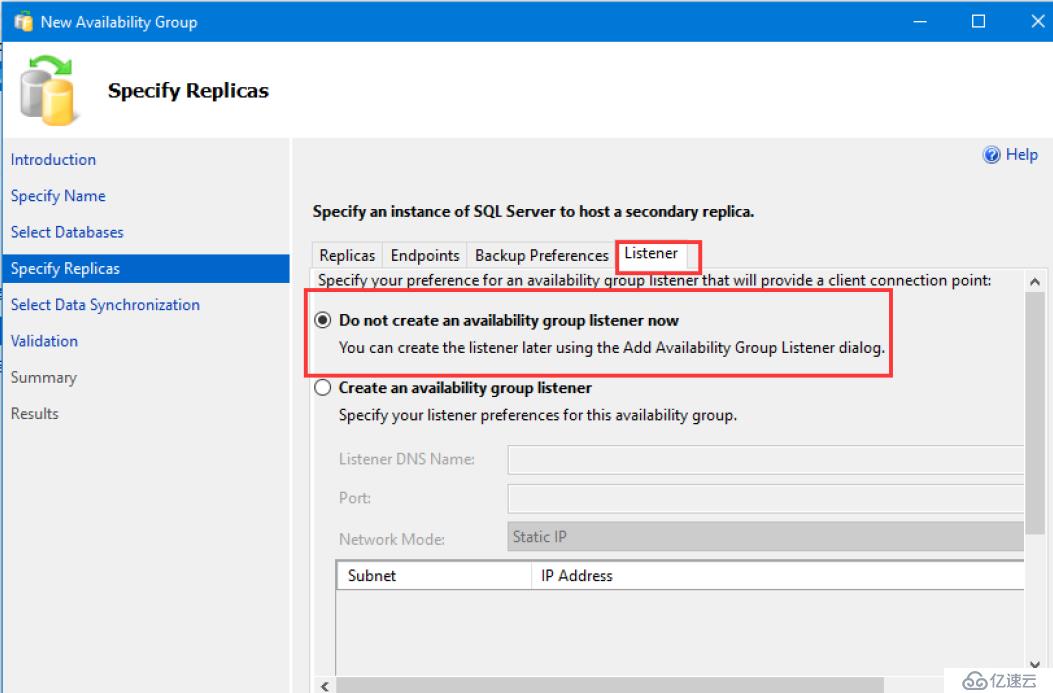
確認即可---yes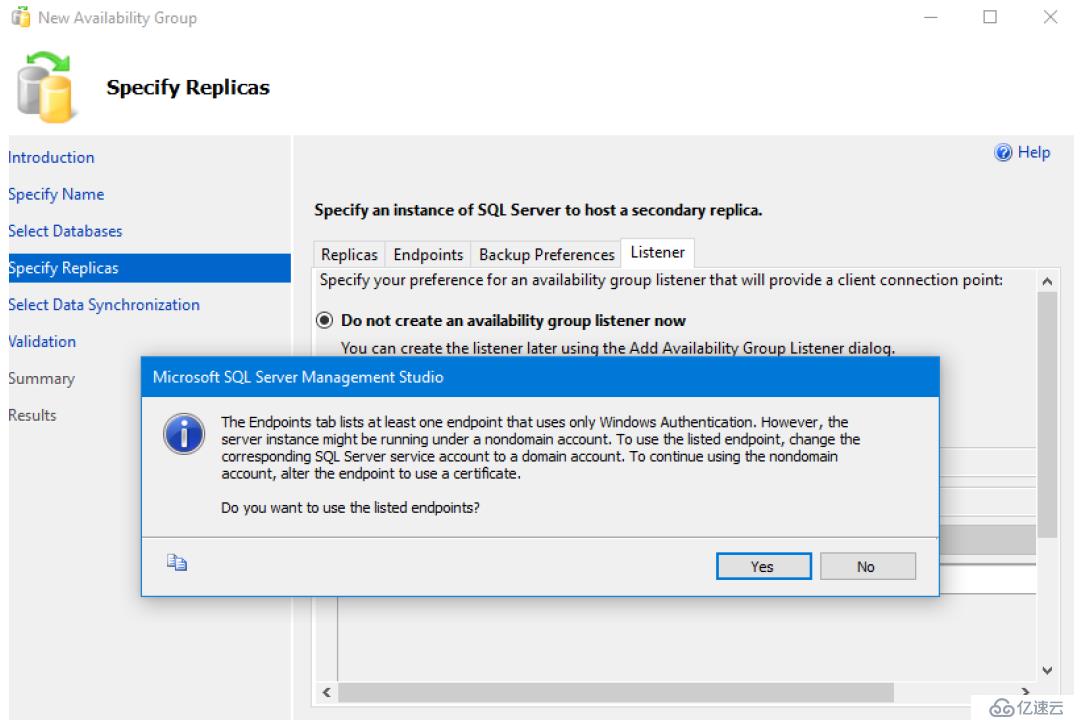
這個地方是選擇初始化數據庫的方式。如果你選擇Full,你需要提供一個共享地址,AlwaysOn自己自動備份數據庫然后還原到目標的輔助副本上。這里我們選擇Join only,所以
我們需要事先把數據庫備份并還原到目標的輔助數據庫上----Join only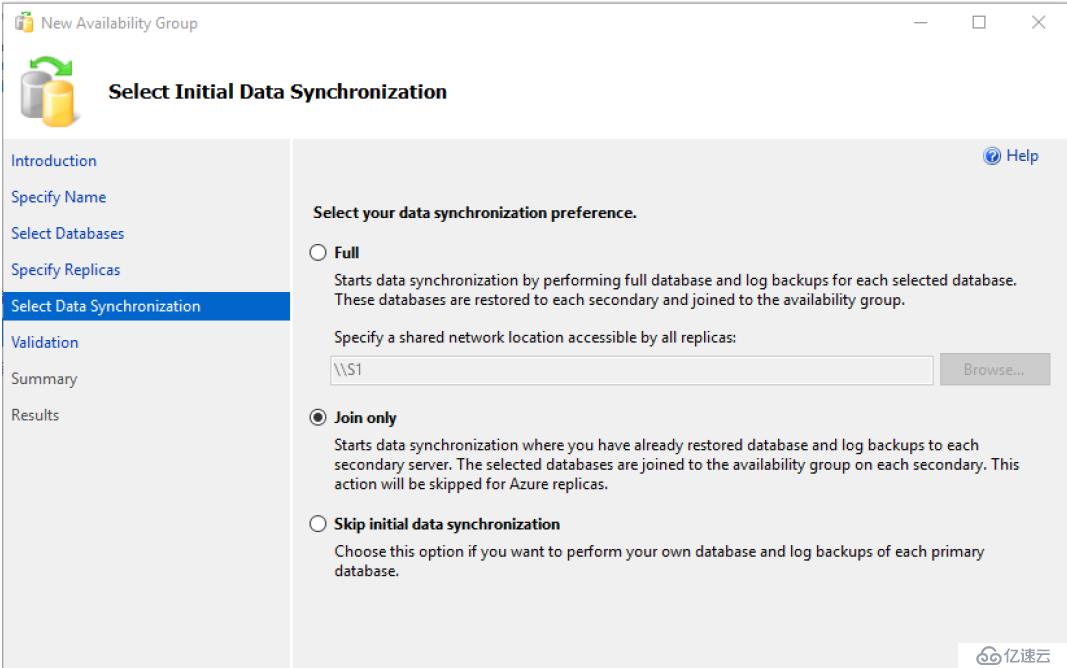
開始下一步后,我們查看狀態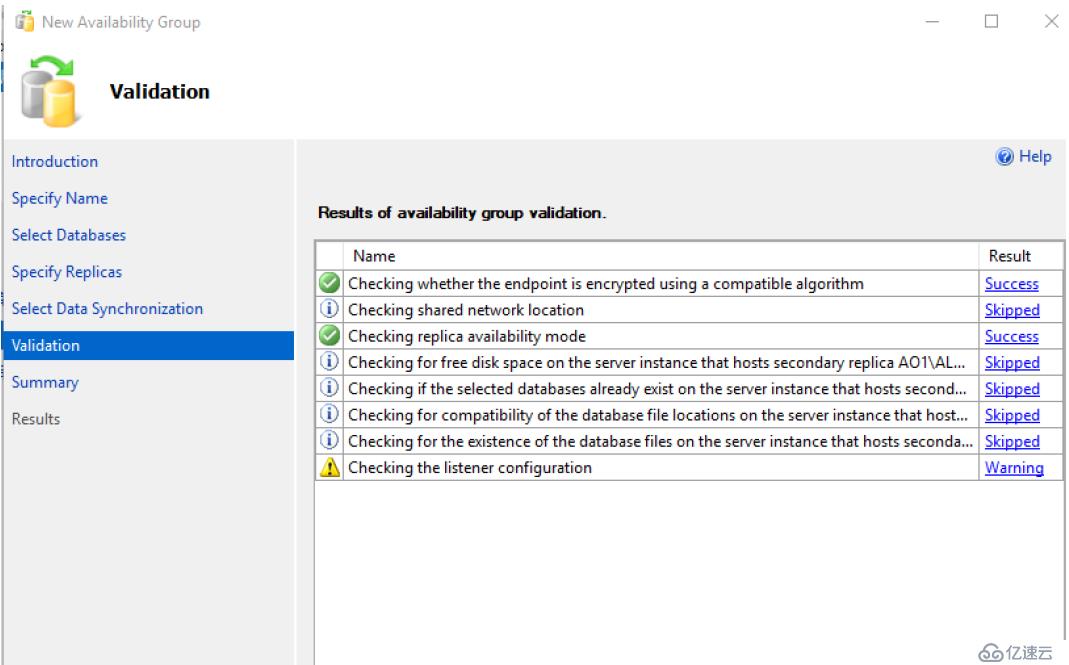
創建完成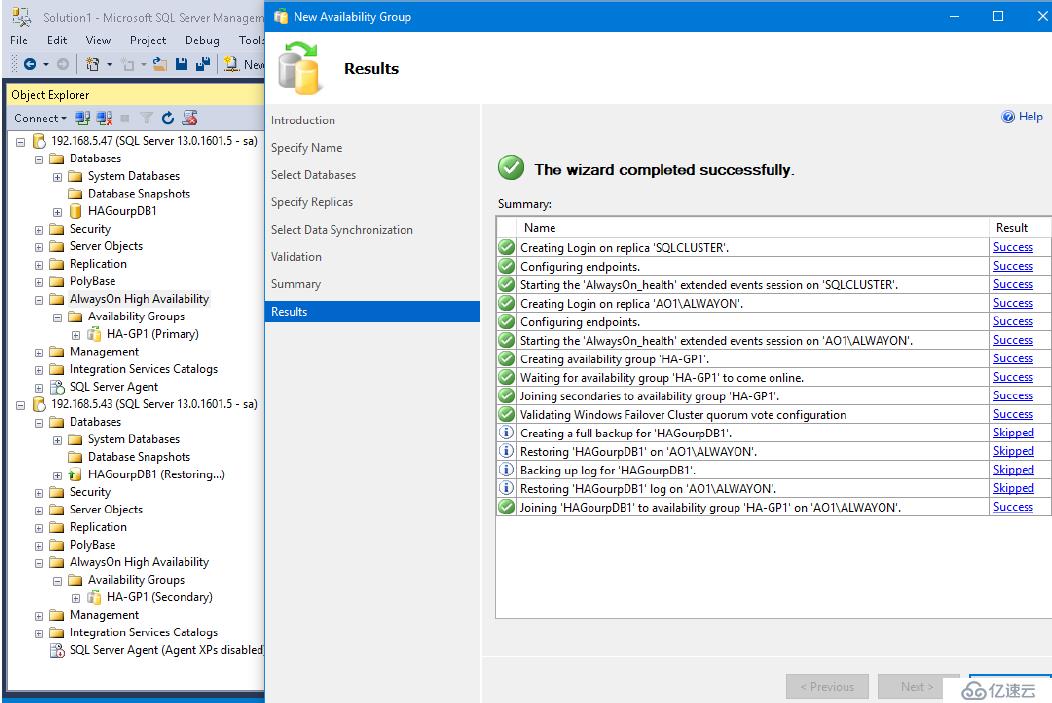
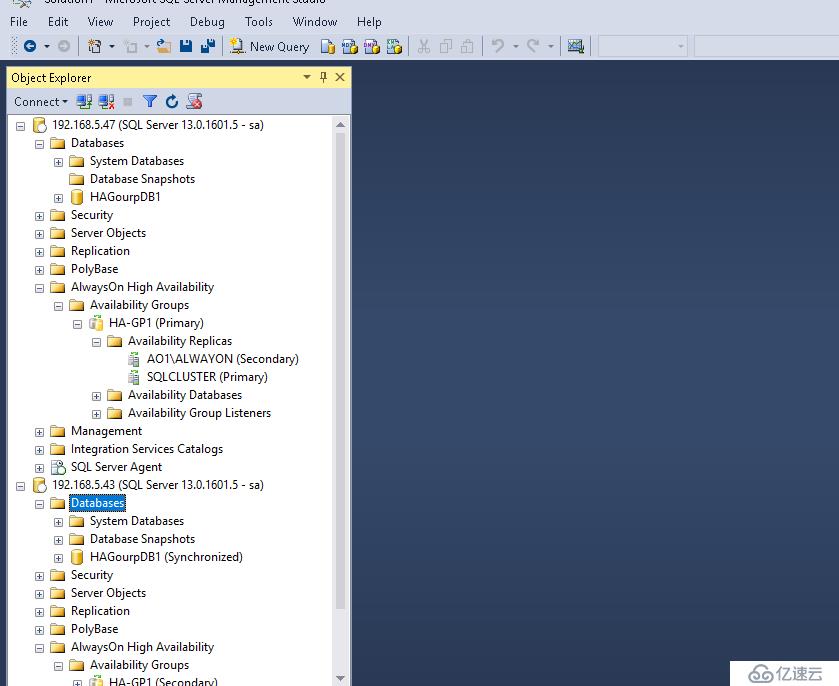
我們展開數據庫高可用性組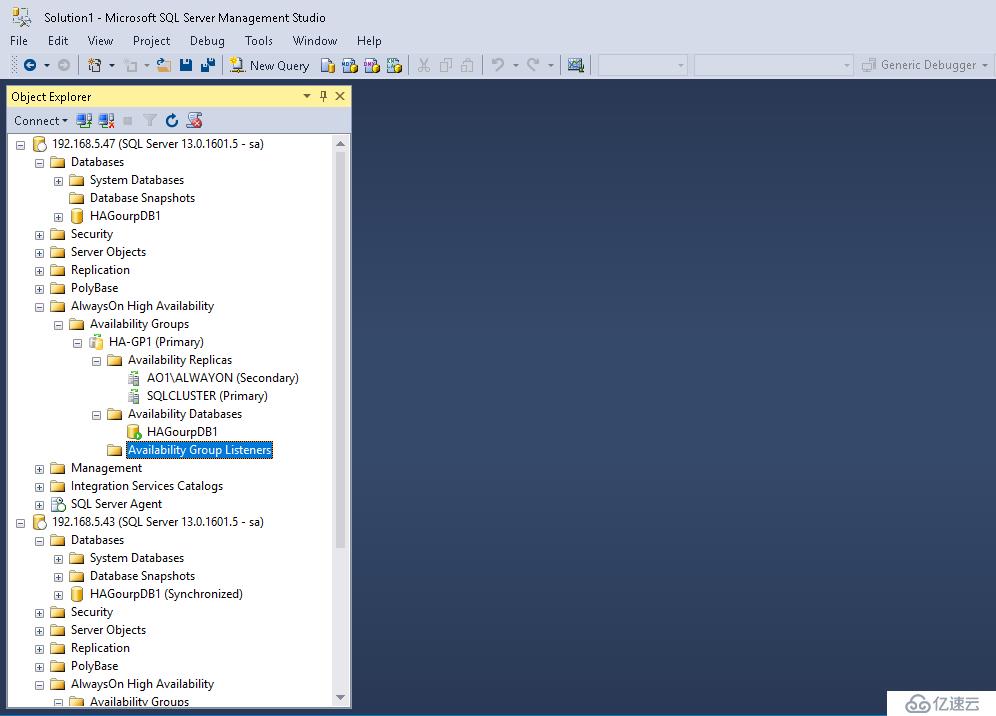
我們查看角色會多出一個高可用性組角色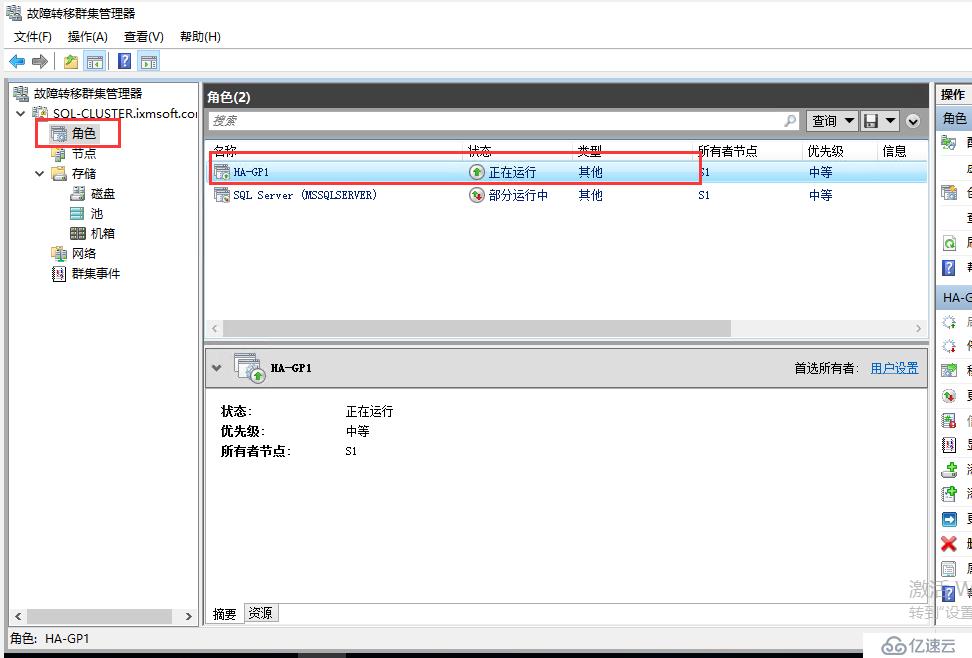
我們接著創建一個監聽
AlwaysOn創建后,客戶端就需要進行連接,為了讓應用程序能夠透明地連接到主副本而不受故障故障轉移的影響,我們需要創建一個偵聽器,偵聽器就是一個虛擬的網絡名稱,可以通過這個虛擬網絡名稱訪問可用性組,而不用關心連接的是哪一個節點,它會自動將請求轉發到主節點,當主節點發生故障后,輔助節點會變為主節點,偵聽器也會自動去偵聽主節點。
一個偵聽器包括虛擬IP地址、虛擬網絡名稱、端口號三個元素,一旦創建成功,虛擬網絡名稱會注冊到DNS中,同時為可用性組資源添加IP地址資源和網絡名稱資源。用戶就可以使用此名稱來連接到可用性組中。與故障轉移群集不同,除了使用虛擬網絡名稱之外,主副本的真實實例名還可以被用來連接。
SQL Server2012早期版本的SQL Server只有在實例啟動的時候地會嘗試綁定IP和端口,但是SQL Server2012卻允許在副本實例處于運行狀況的時候隨時綁定新的IP地址、網絡名稱和端口號。因此可以為隨時為為可用性組添加偵聽器,而且這個操作會立即生效。當添加了偵聽器之后,在SQL Server的錯誤日志中可以看到類似:在虛擬網絡名稱上停止和啟動偵聽器的消息。
要注意的是,SQLBrowser服務是不支持Listener的。這是因為應用程序在使用Listener的虛擬網絡名連接SQLServer時,是以一個默認實例的形式進行訪問的(只有主機名,沒有實例名),因此客戶端根本就不會去嘗試使用SQLBrowser服務。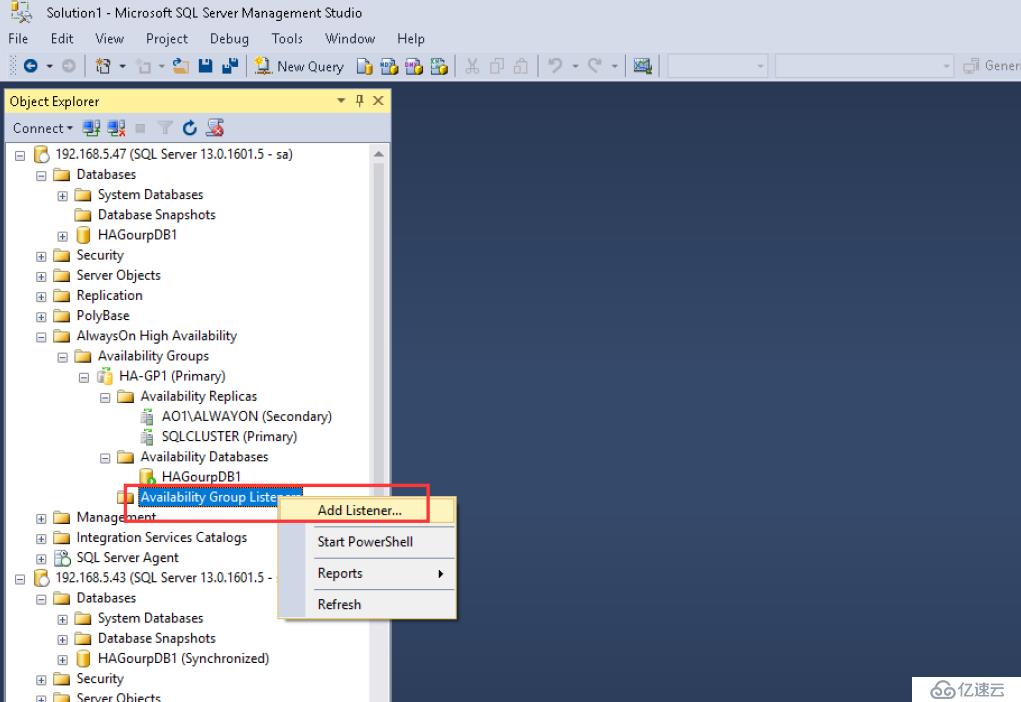
定義監聽名稱及IP
名稱:HA-LST;
IP地址:192.168.5.48;
Port為1433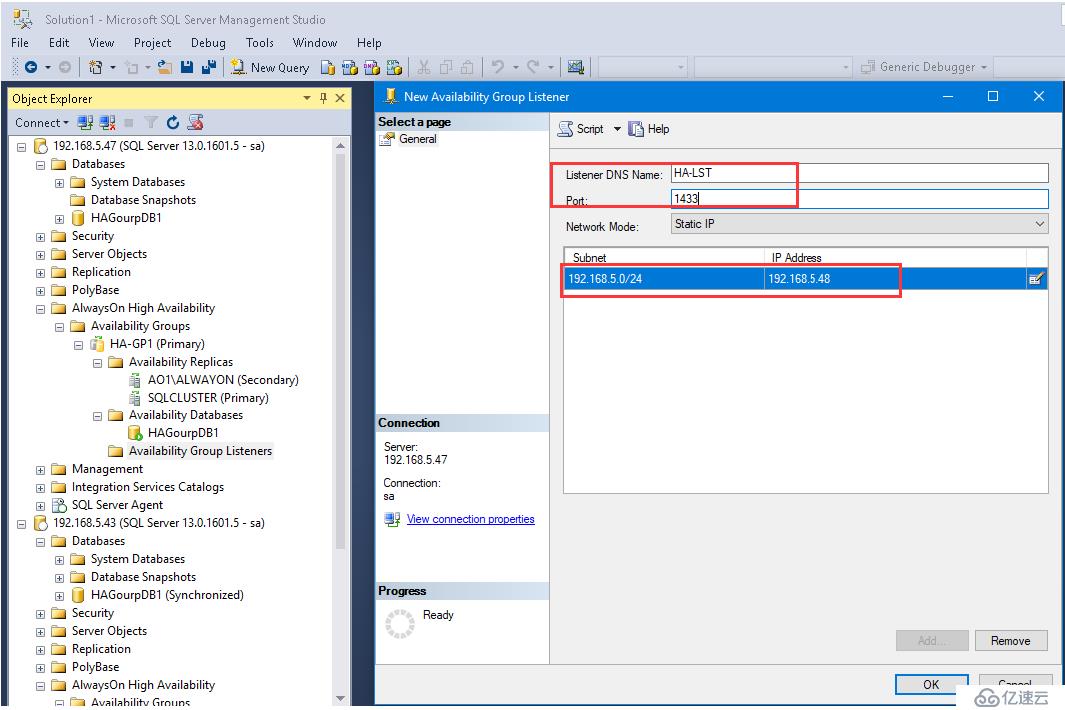
定義完成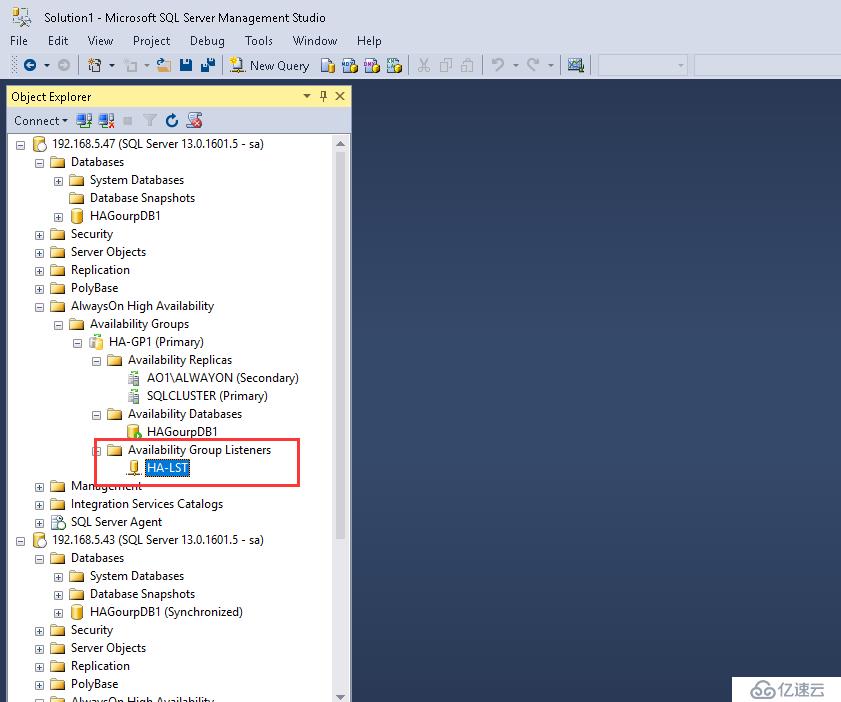
我們在查看角色,就會發現有對應的管理地址了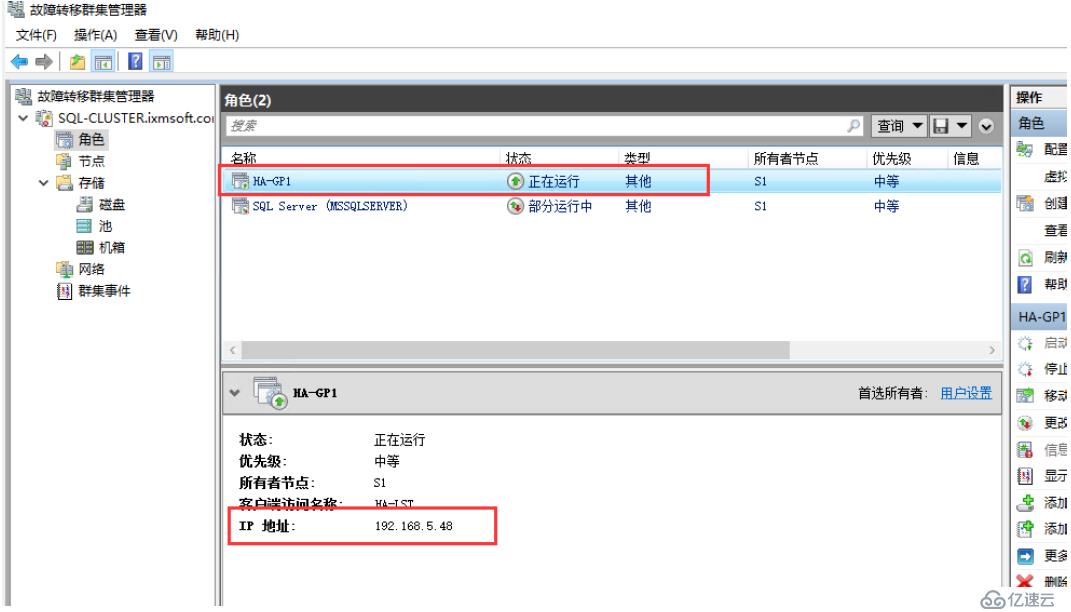
定義完成后,我們可以查看高可用行組的顯示面板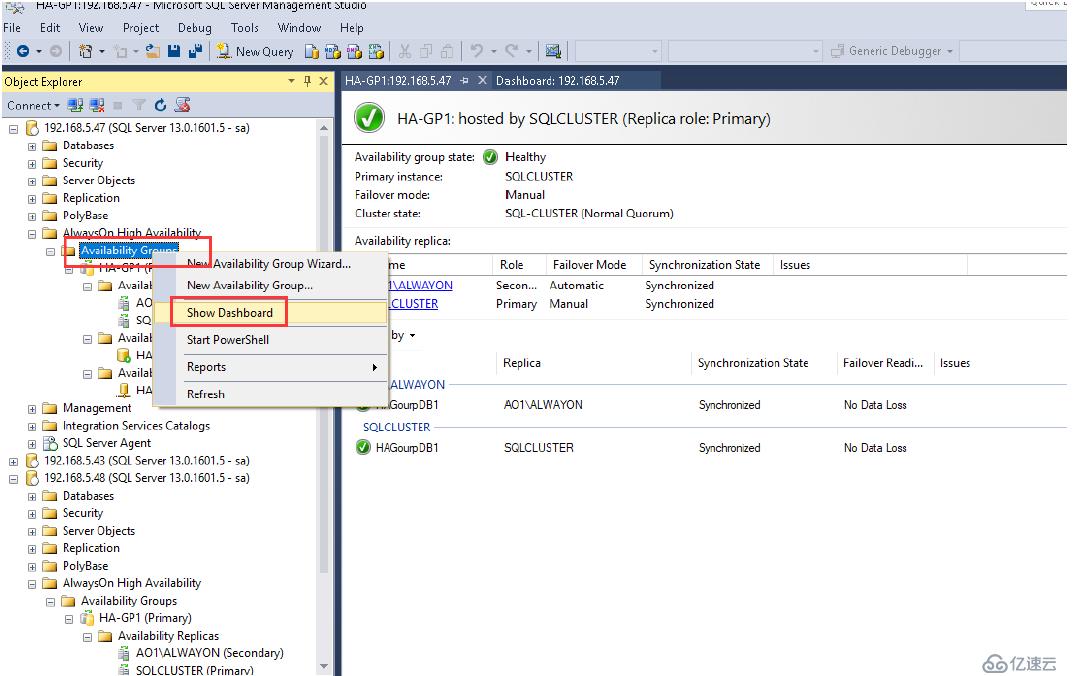
我們可以通過顯示面板查看高可用性組的狀態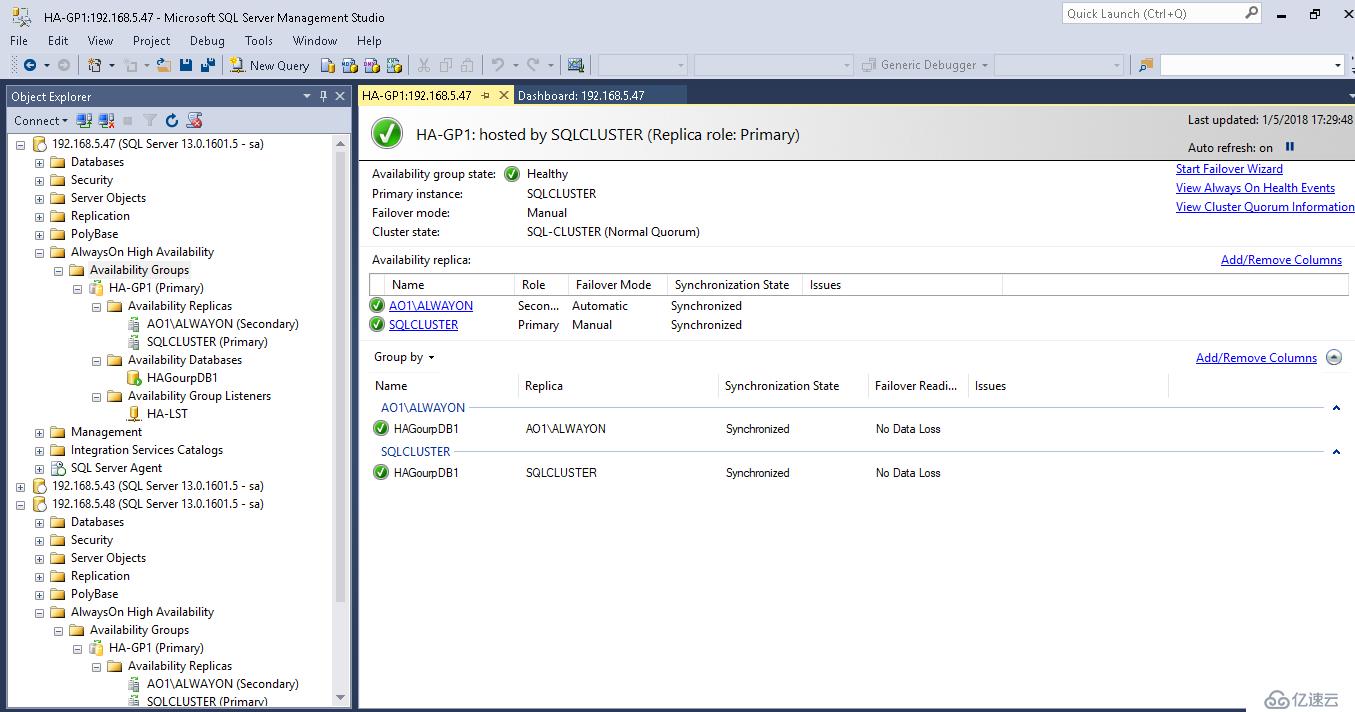
接下來我們切換一下;切換前我們需要注意一個問題:切換的時候不能在集群管理器里面切換,需要在高可用性組下切換,不然會有問題,就算切換成功了,有些數據也會出現問題
我們首先在集群管理器里面查看節點所有者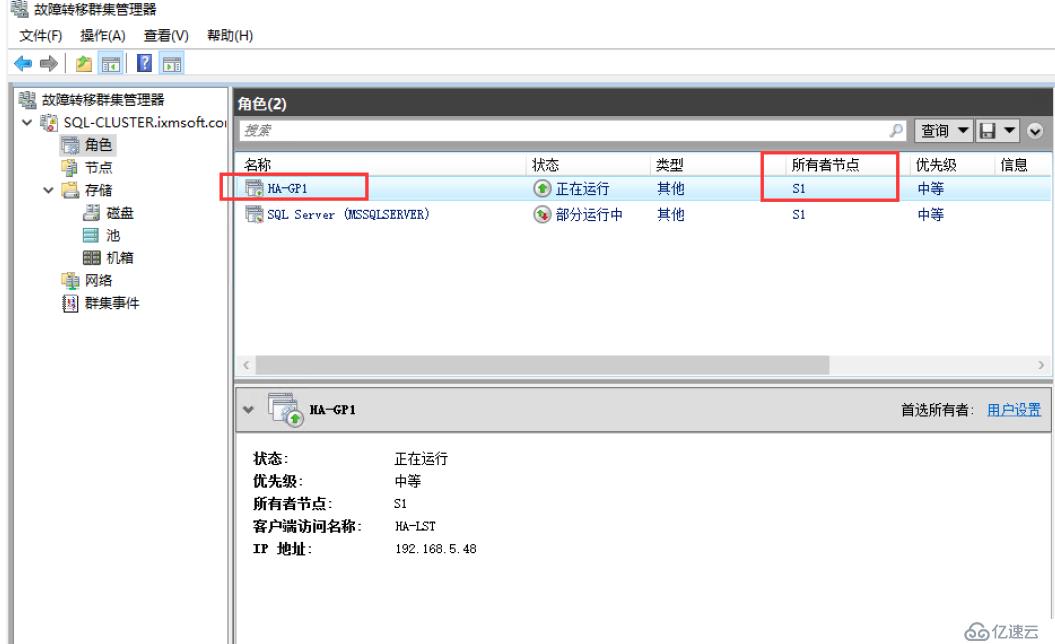
另外我們連接到群集節點后,發現高可用性組下的可用性副本的節點屬于輔助節點;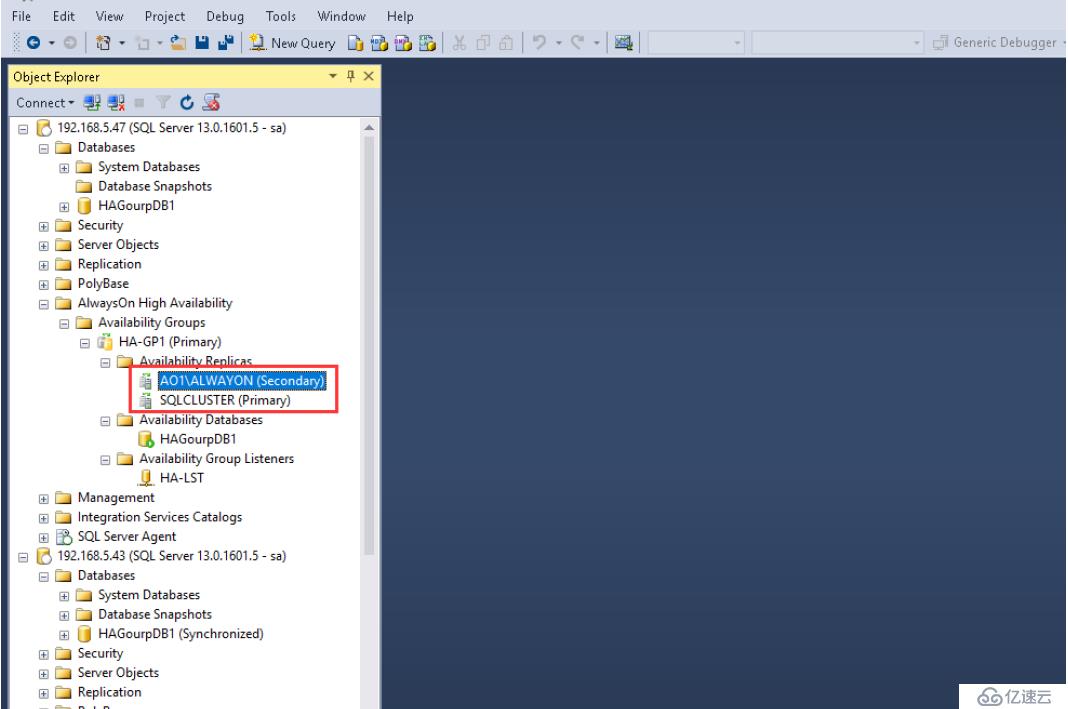
接下來我們準備開始切換,我們使用SSMS連接到第三個節點實例
查看當前可用性組下在第三個節點處于輔助副本狀態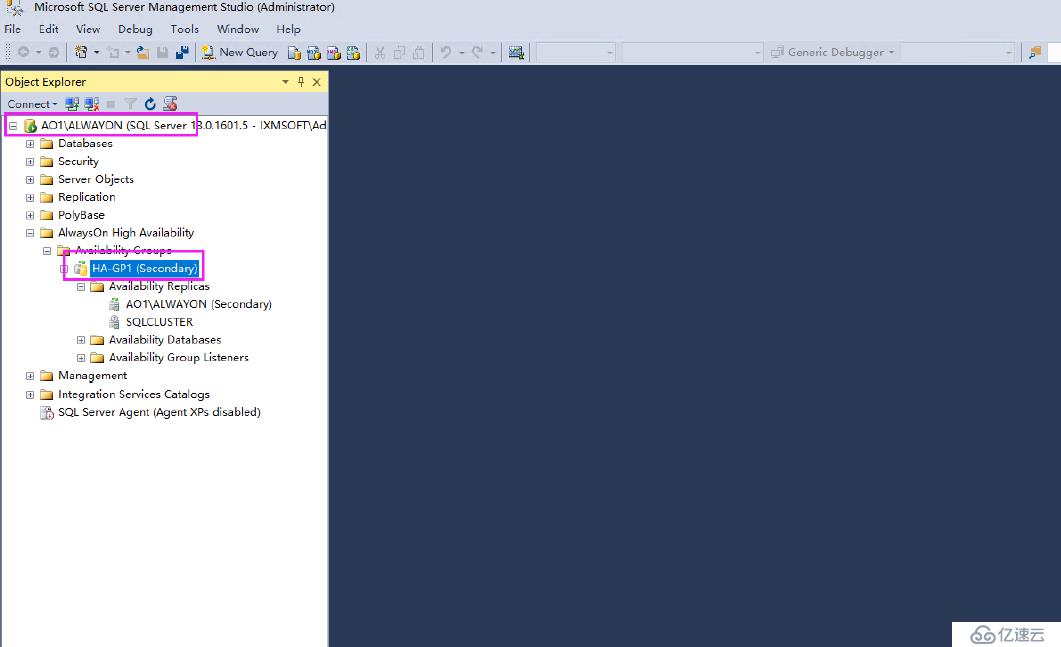
我們開始切換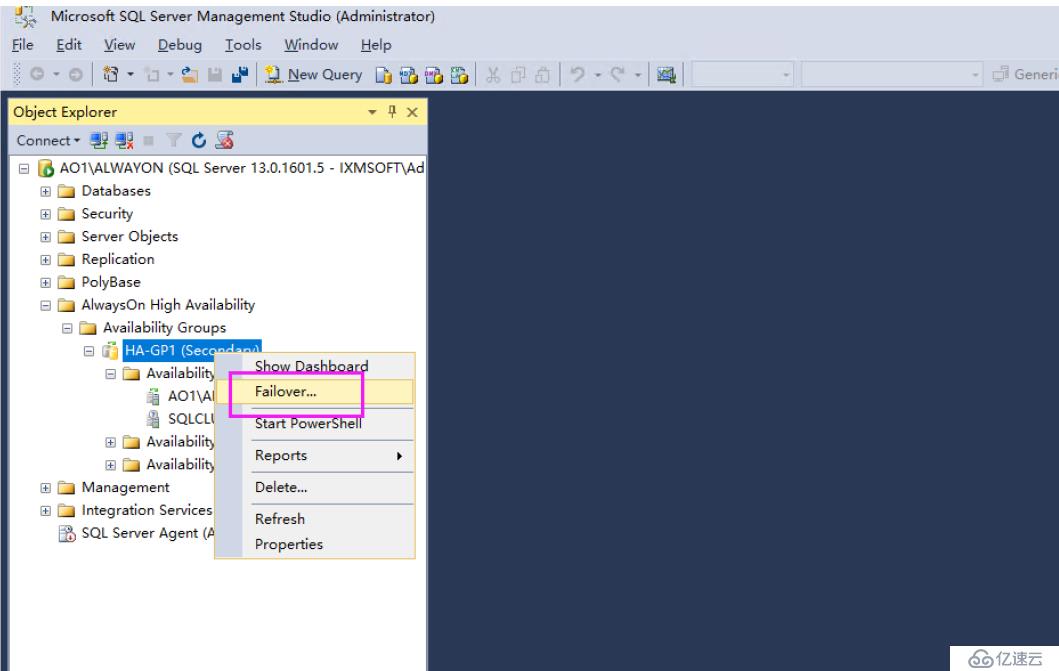
選擇主副本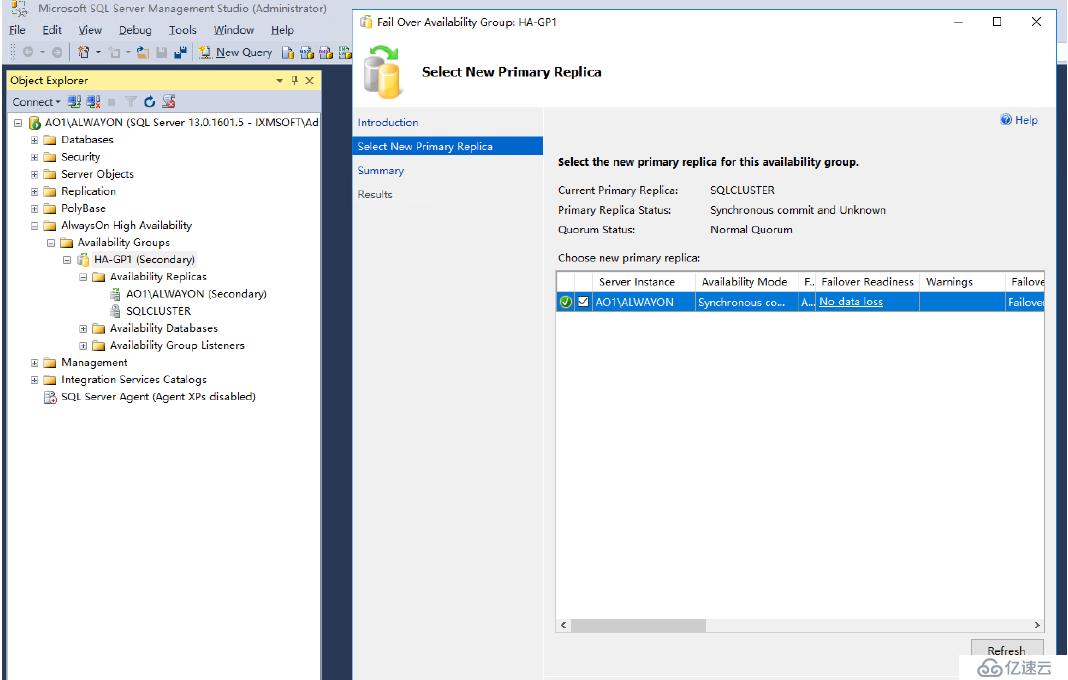
確認信息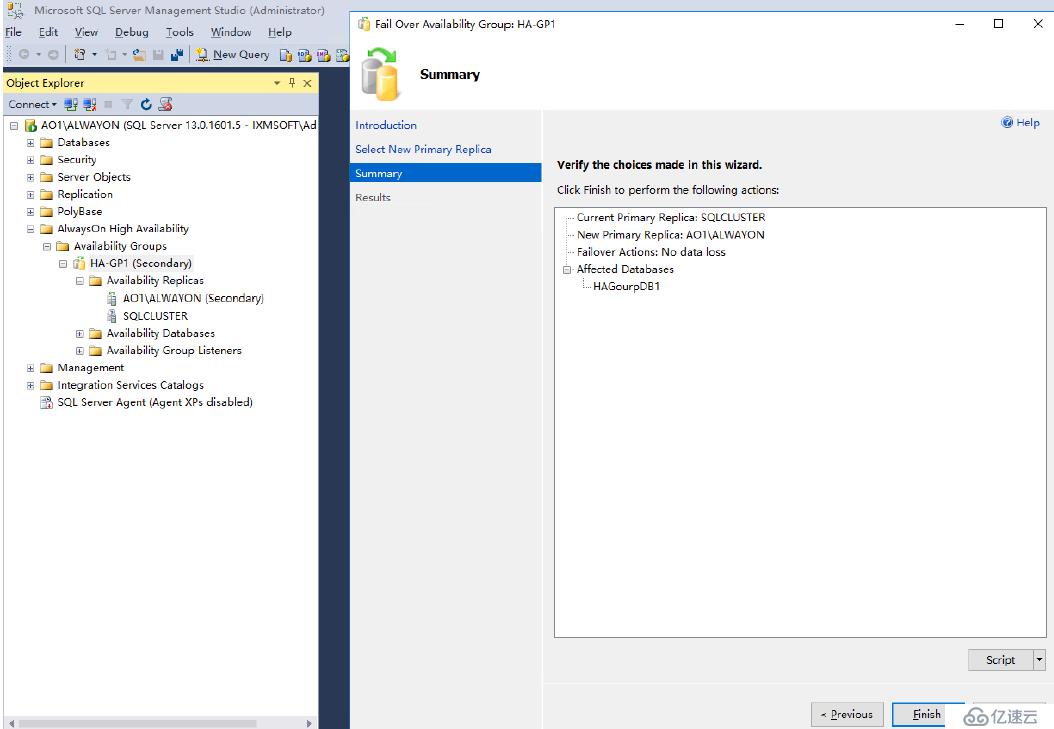
轉移完成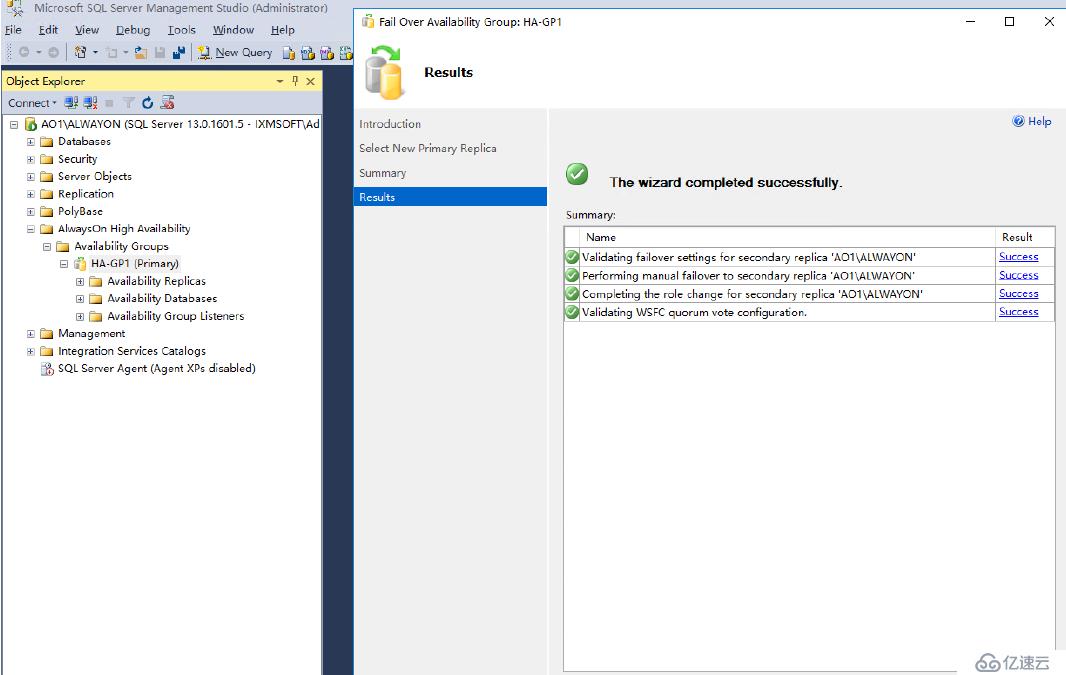
我們再查看AO1第三節點的AG狀態就成了主副本了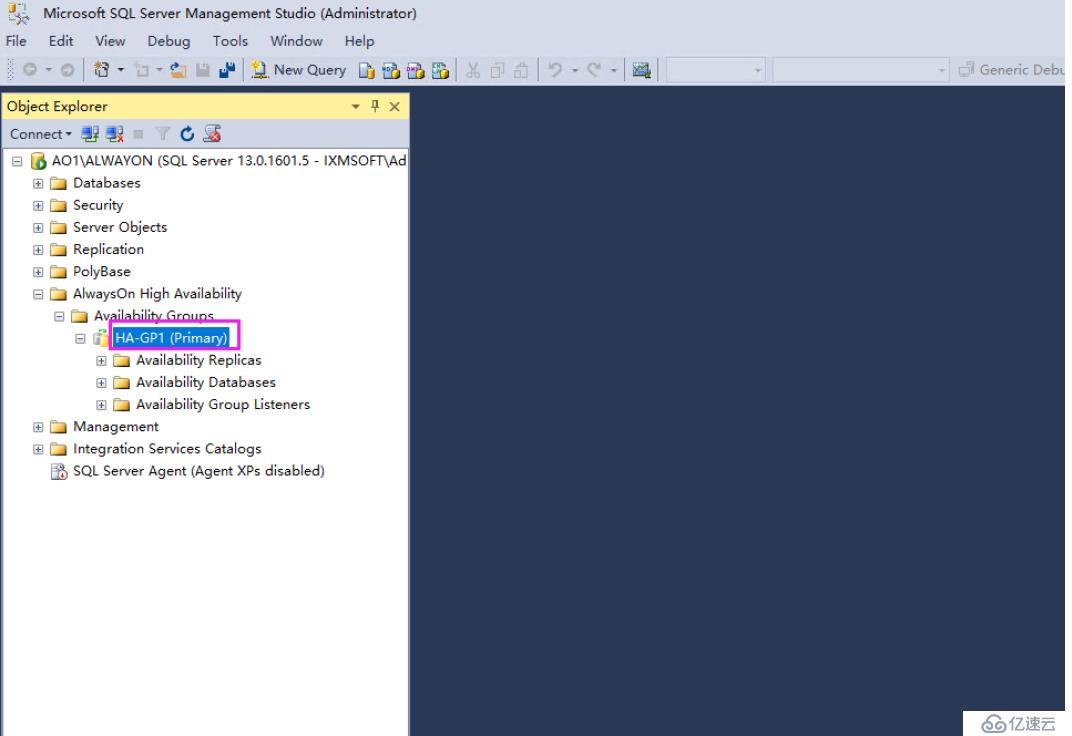
我們再從主切換到備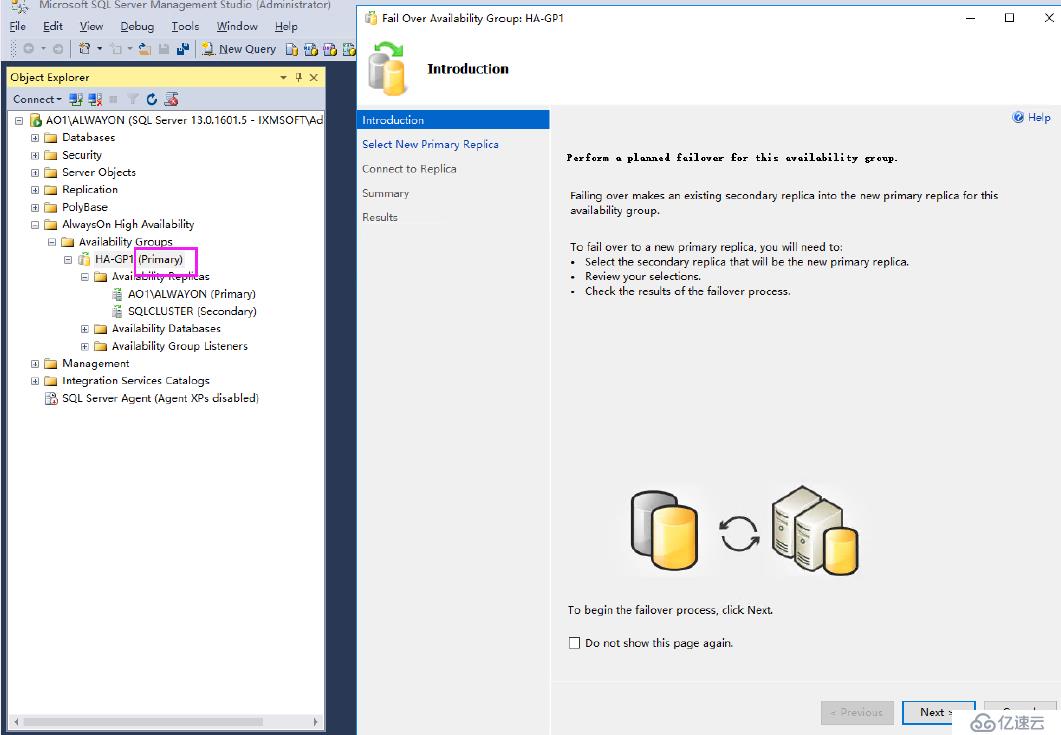
選擇新的主副本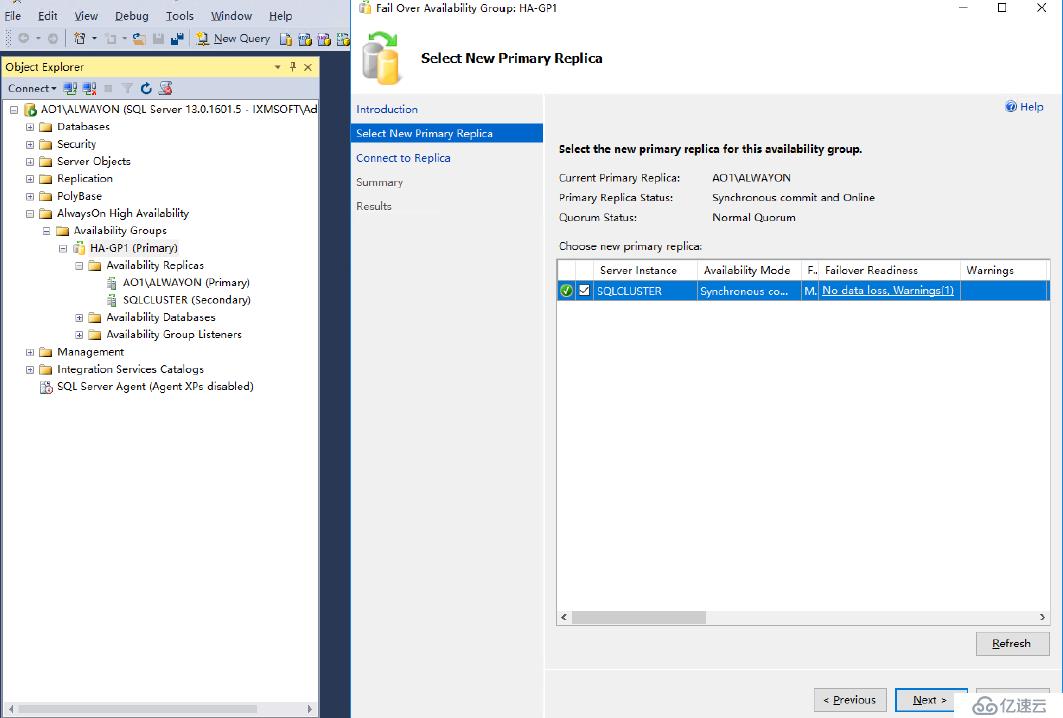
鏈接副本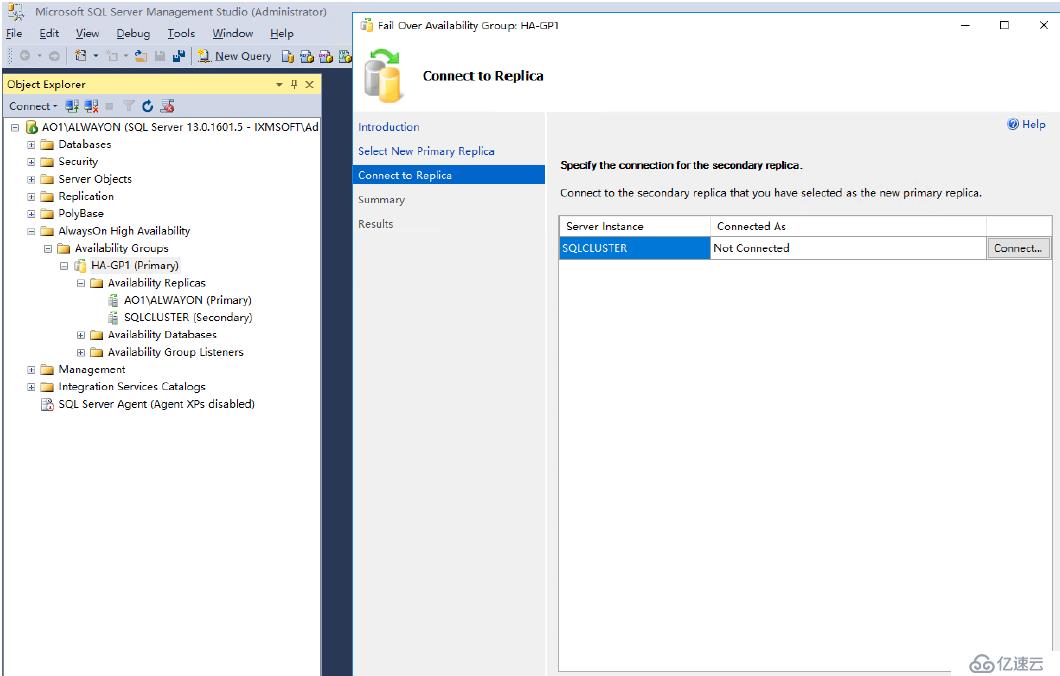
開始連接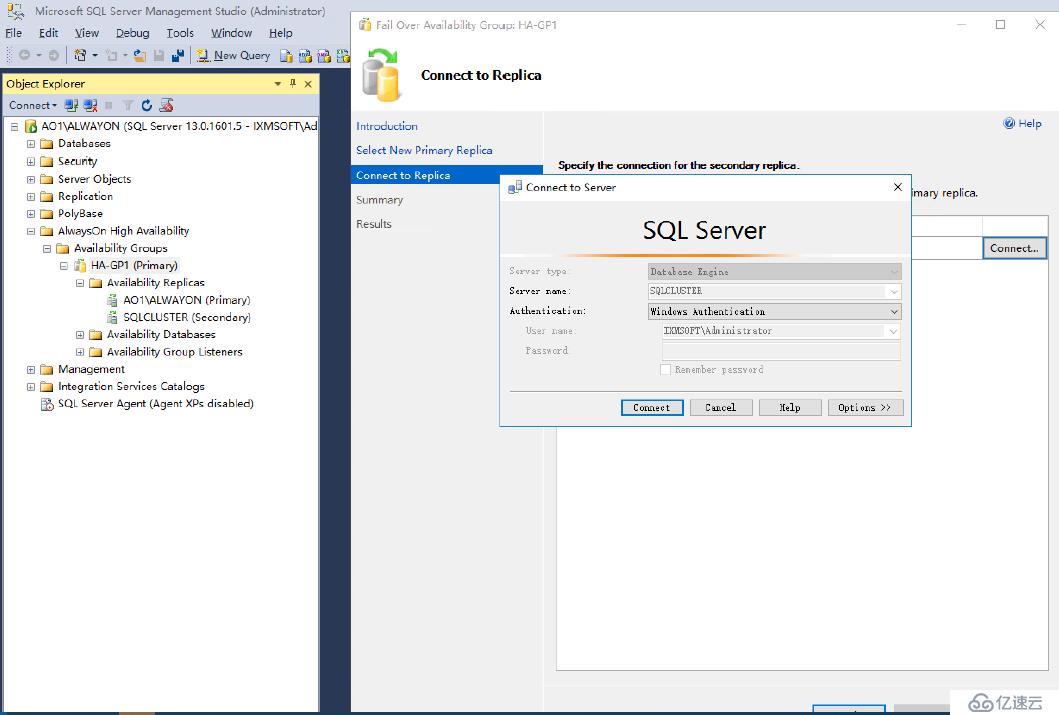
鏈接成功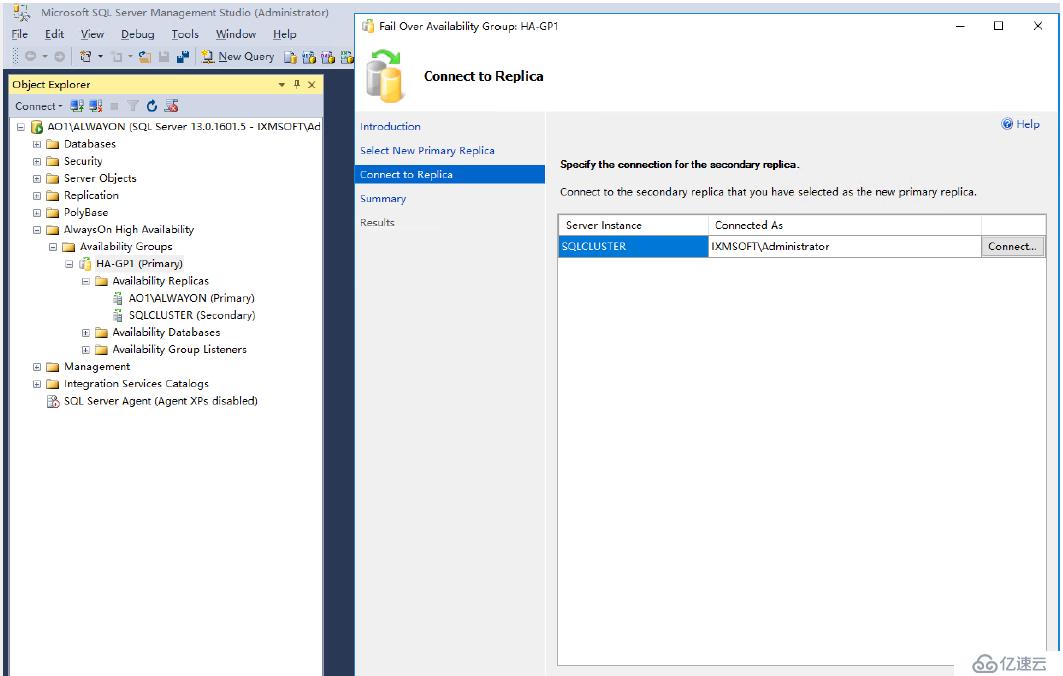
確認轉移信息
轉移完成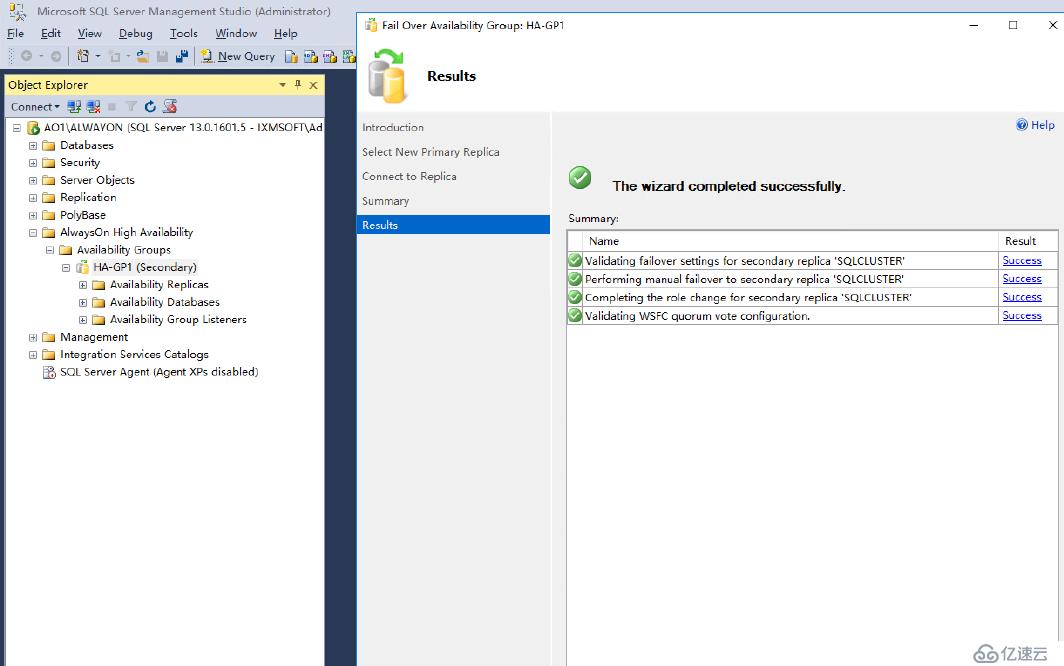
我們從SQLCLUSTER上插入一條數據
然后從AO1上查看數據
我們從AO1上插入數據提示,數據庫為只讀,所以無法插入數據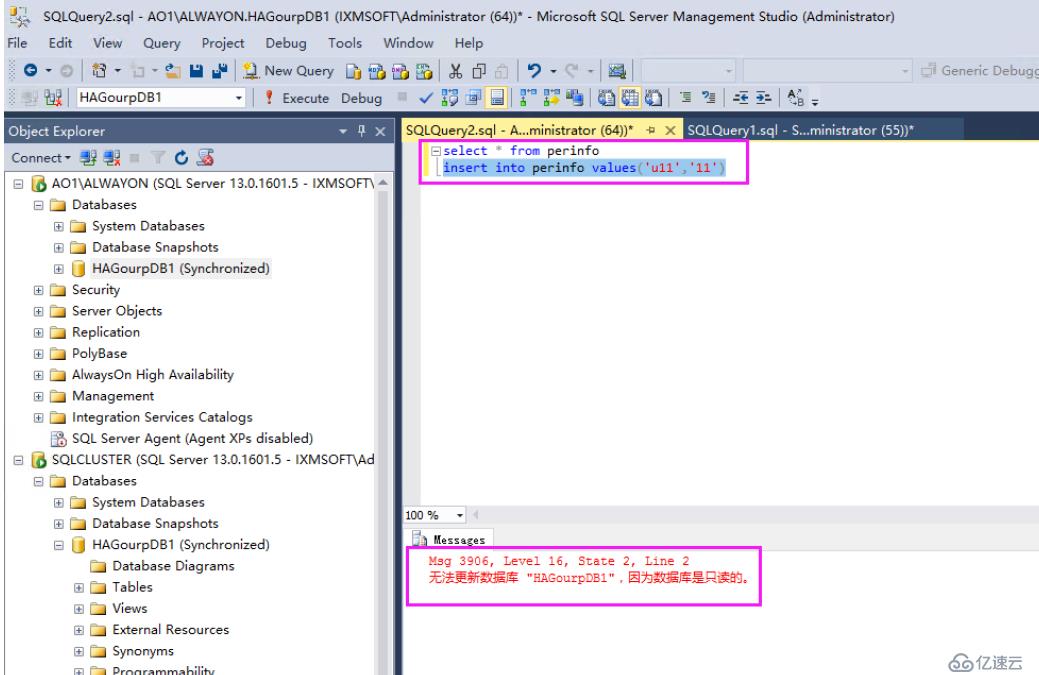
原因是由于當前節點屬于第二節點,如果可讀可寫的話,需要將該節點轉移到主副本節點才可以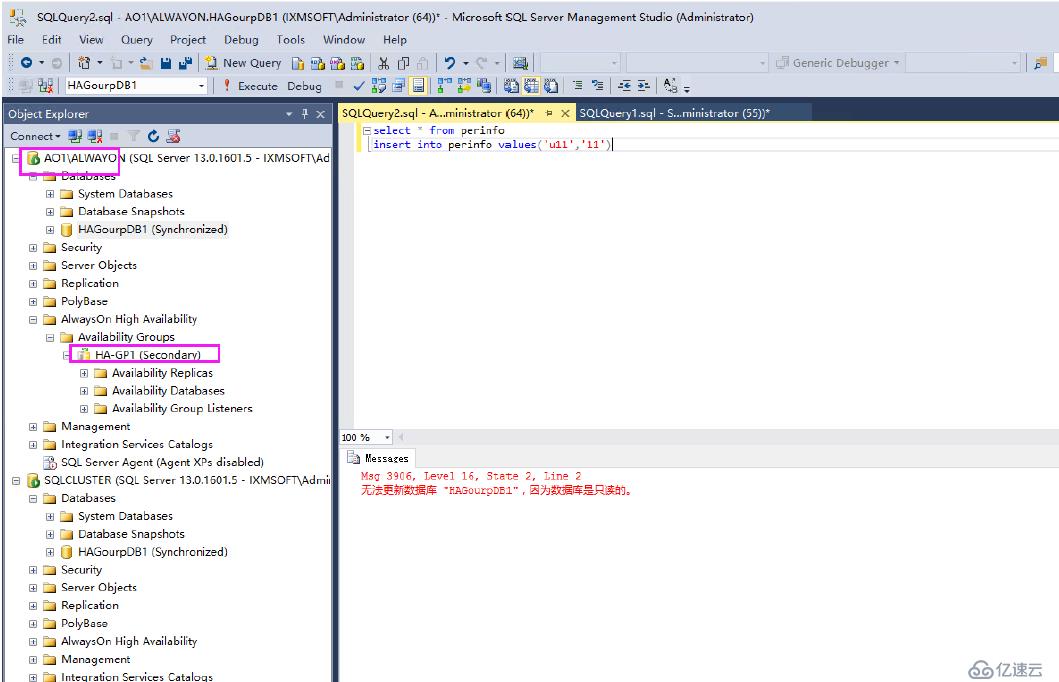
我們將AO1\ALWAYON下的AG下的HA-GP1從從副本轉移到主副本我們再次插入數據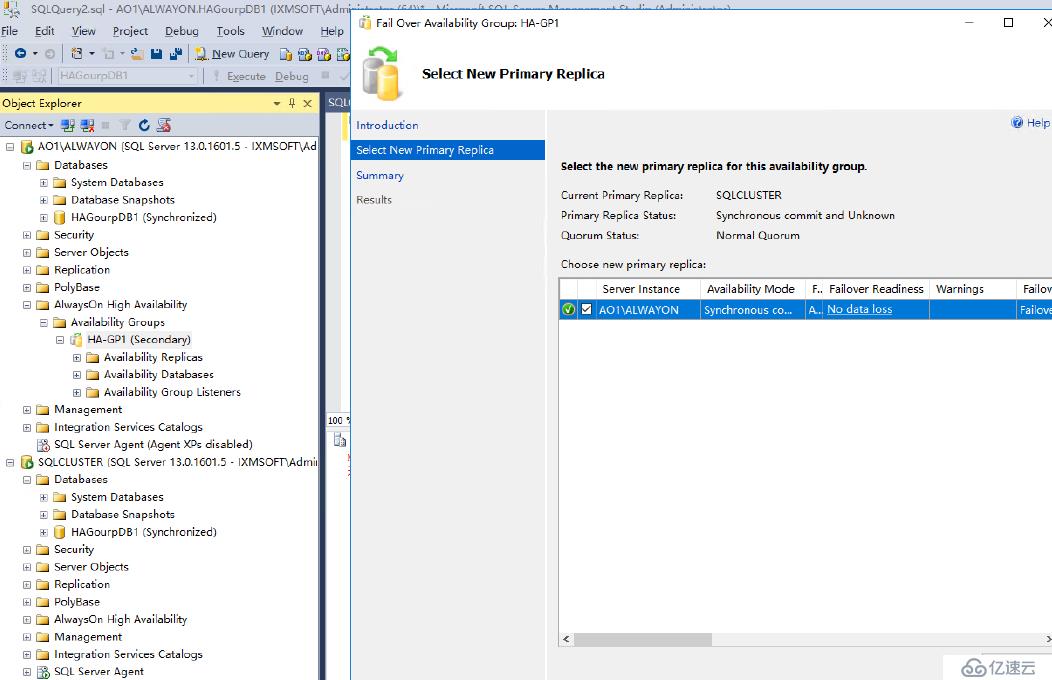
轉移完成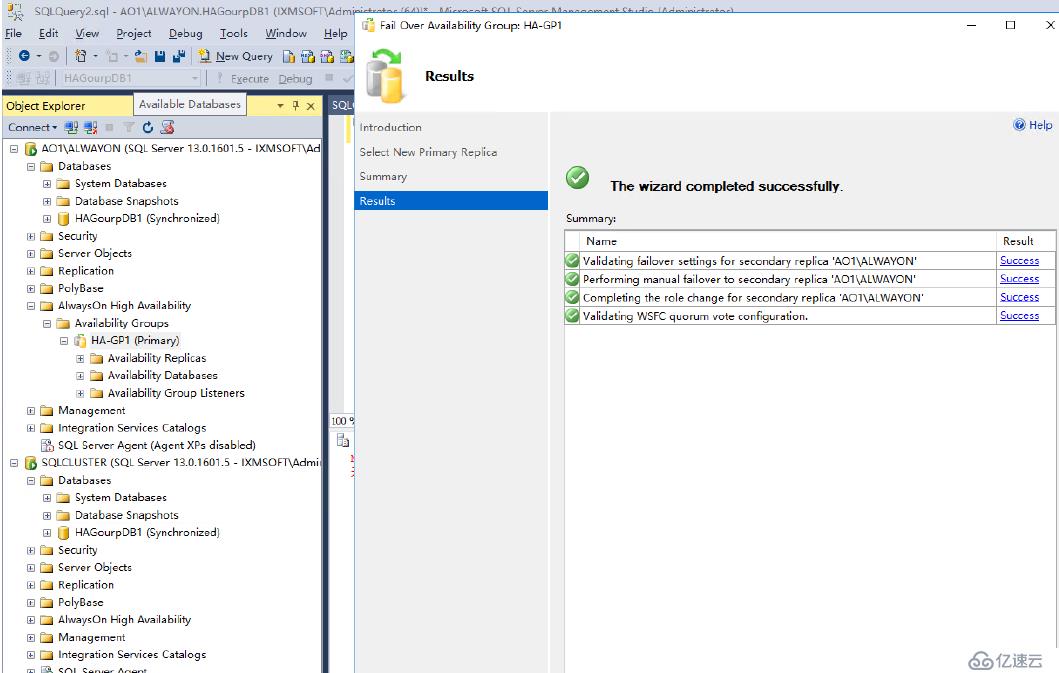

我們再次嘗試插入數據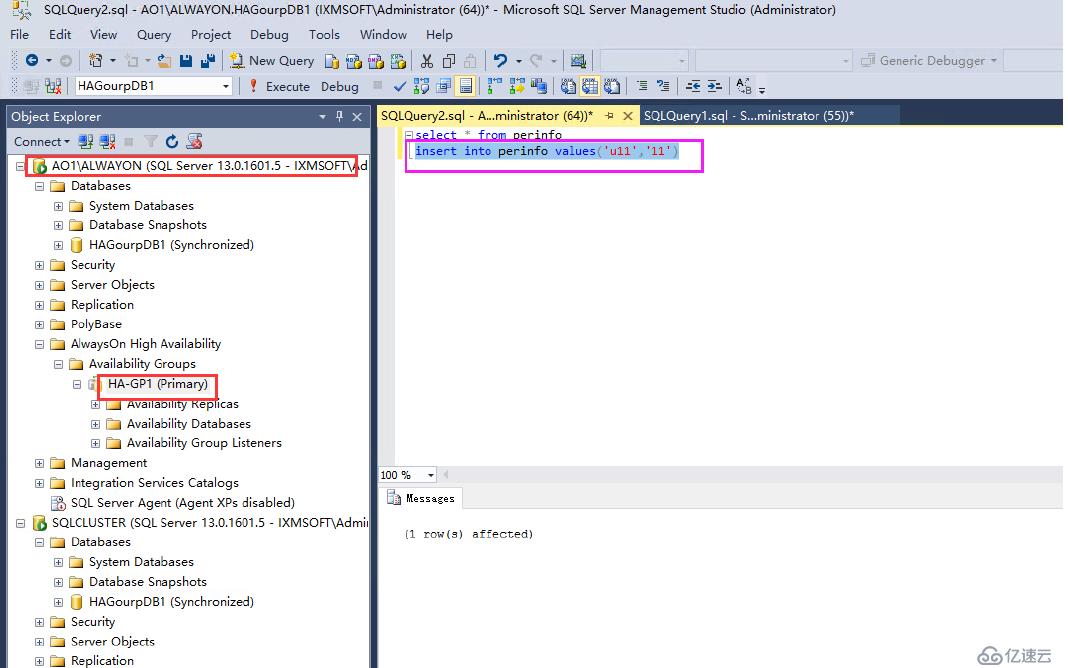
我們從SQLCLUSTER集群節點查看數據是否同步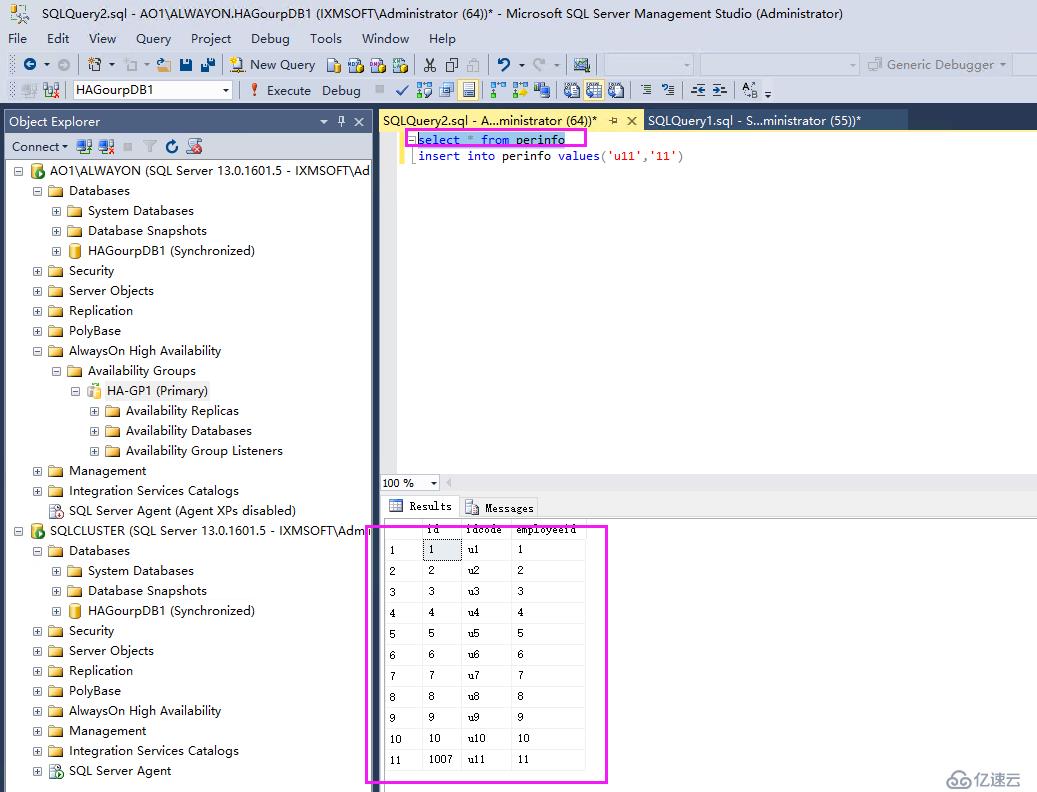
我們再次到SQLCLUSTER節點插入數據,提示錯誤
原因是節點屬于AO1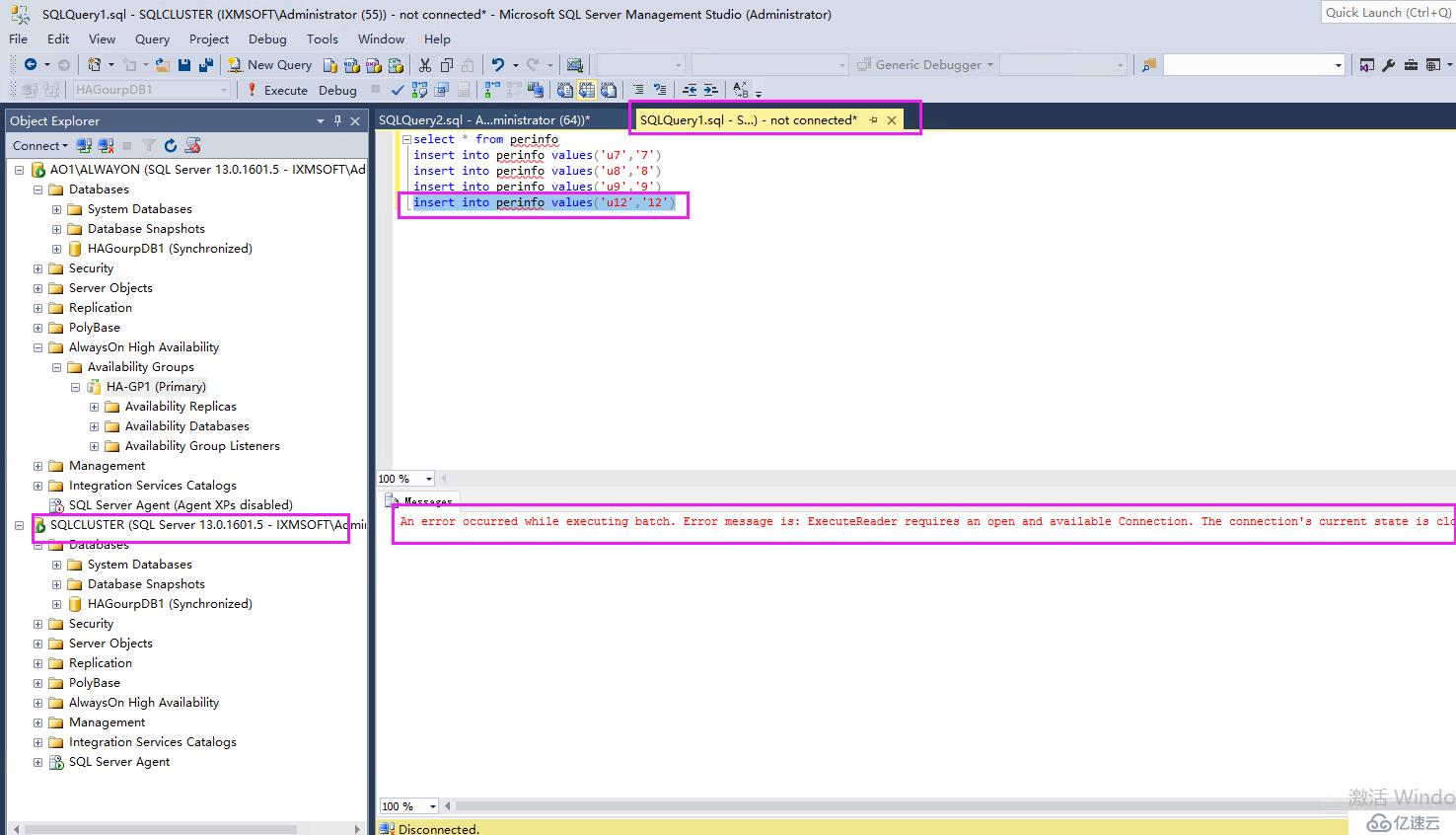
但是我們查看數據,從當前節點從AO1插入的數據依然可以同步到SQLCLUSTER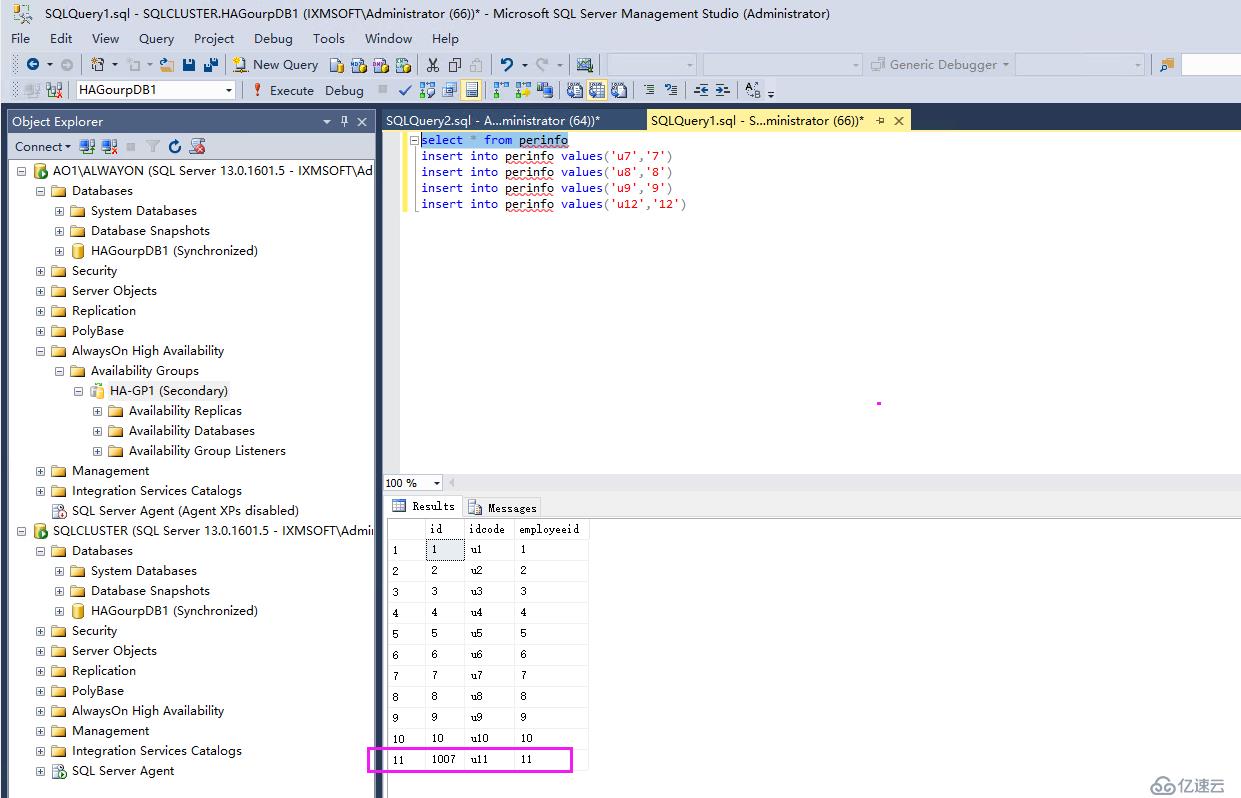
各副本間的數據同步
AlwaysOn必須要維護各副本間的數據一致性,當主副本上的數據發生變化,會同步到輔助副本上。這里AlwaysOn通過三個步驟來完成:
步驟1:主副本記錄發生變化的數據;
步驟2:將記錄傳輸到各個輔助副本;
步驟3:把數據變化操作在輔助副本上執行一遍。
具體實現如下:
在主副本和輔助副本上,SQL Server都會啟動相應的線程來完成相應的任務。對于一般的SQL Server服務器,即沒有配置高可用性,會運行Log Writer的線程,當發生數據修改事務時,此線程負責將本次操對應的日志信息記錄到日志緩沖區中,然后再寫入到物理日志文件。但如果配置了AlwaysOny主副本的數據庫,SQL Server會為它建立一個叫Log Scanner的線程,不間斷的工作,負責將日志從日志緩沖區或日志文件里讀出,打包成日志塊,發送到輔助副本。因此可以保證發生的數據變化,不斷送給各輔助副本。
輔助副本上存在固化和重做兩個線程完成數據更新操作,固化線程會將主副本Log Scanner所發過來的日志塊寫入輔助副本磁盤上的日志文件里,因此稱為固化,然后重做線程負責從磁盤上讀取日志塊,將日志記錄對應的操作重演一遍,此時主副本和輔助副本上的數據就一致了。重做線程每隔固定的時間點,會跟主副本通信,告知自己的工作進度。主副本由此知道兩邊數據的差距。Log Scanner負責傳送日志塊,不需要等待Log Writer完成日志固化;輔助副本完成日志固化以后就會發送消息到主副本,告知數據傳輸完成,而不需要等待重做完成,這樣各自獨立的設計,是盡可能減少 AlwaysOn所帶來的操作對數據庫性能的影響。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





