溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
通過案例學調優之--分區表基本概念
Partitioning addresses key issues in supporting very large tables and indexes by letting you decompose them into smaller and more manageable pieces called partitions. SQL queries and DML statements do not need to be modified in order to access partitioned tables. However, after partitions are defined, DDL statements can access and manipulate individuals partitions rather than entire tables or indexes. This is how partitioning can simplify the manageability of large database objects. Also, partitioning is entirely transparent to applications.
Each partition of a table or index must have the same logical attributes, such as column names, datatypes, and constraints, but each partition can have separate physical attributes such as pctfree, pctused, and tablespaces.
Partitioning is useful for many different types of applications, particularly applications that manage large volumes of data. OLTP systems often benefit from improvements in manageability and availability, while data warehousing systems benefit from performance and manageability.
分區表設計原則
表的大小:當表的大小超過1.5GB-2GB,或對于OLTP系統,表的記錄超過1000萬,都應考慮對表進行分區。
數據訪問特性:基于表的大部分查詢應用,只訪問表中少量的數據。對于這樣表進行分區,可充分利用分區排除無關數據查詢的特性。
數據維護:按時間段刪除成批的數據,例如按月刪除歷史數據。對于這樣的表需要考慮進行分區,以滿足維護的需要。
數據備份和恢復: 按時間周期進行表空間的備份時,將分區與表空間建立對應關系。
只讀數據:如果一個表中大部分數據都是只讀數據,通過對表進行分區,可將只讀數據存儲在只讀表空間中,對于數據庫的備份是非常有益的。
并行數據操作:對于經常執行并行操作(如Parallel Insert,Parallel Update等)的表應考慮進行分區。
表的可用性:當對表的部分數據可用性要求很高時,應考慮進行表分區。
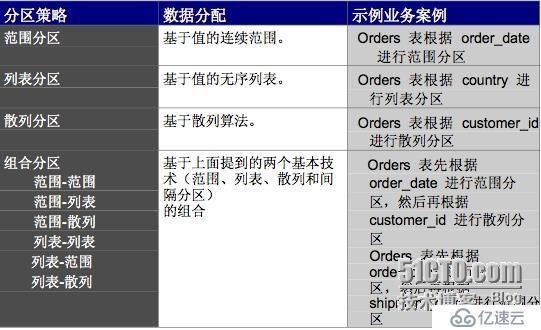
分區表的類型
Oracle 10g:
Range Partitioning
List Partitioning
Hash Partitioning
Composite Partitioning
RANG-HASH
RANG-LIST
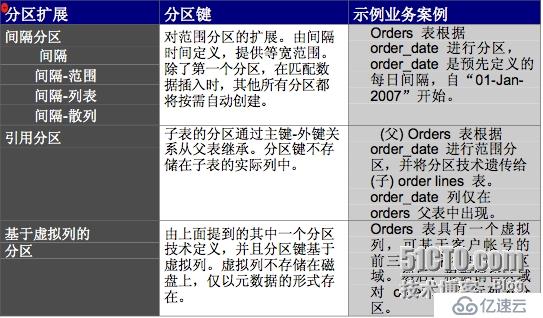
Oracle 11g:
分區表常用視圖
1、查詢當前用戶下有哪些是分區表:
SELECT * FROM USER_PART_TABLES;
2、查詢當前用戶下有哪些分區索引:
SELECT * FROM USER_PART_INDEXES;
3、查詢當前用戶下分區索引的分區信息:
SELECT * FROM USER_IND_PARTITIONS T
WHERE T.INDEX_NAME=xxx;
4、查詢當前用戶下分區表的分區信息:
SELECT * FROM USER_TAB_PARTITIONS T
WHERE T.TABLE_NAME=xxx;
5、查詢某分區下的數據量:
SELECT COUNT(*) FROM TABLE_PARTITION PARTITION(TAB_PARTOTION_01);
6、查詢索引、表上在那些列上創建了分區:
SELECT * FROM USER_PART_KEY_COLUMNS;
7、查詢某用戶下二級分區的信息(只有創建了二級分區才有數據):
SELECT * FROM USER_TAB_SUBPARTITIONS;
分區表索引
Just like partitioned tables, partitioned indexes improve manageability, availability, performance, and scalability. They can either be partitioned independently (global indexes) or automatically linked to a table's partitioning method (local indexes). In general, you should use global indexes for OLTP applications and local indexes for data warehousing or DSS applications. Also, whenever possible, you should try to use local indexes because they are easier to manage. When deciding what kind of partitioned index to use, you should consider the following guidelines in order:
If the table partitioning column is a subset of the index keys, use a local index. If this is the case, you are finished. If this is not the case, continue to guideline 2.
If the index is unique, use a global index. If this is the case, you are finished. If this is not the case, continue to guideline 3.
If your priority is manageability, use a local index. If this is the case, you are finished. If this is not the case, continue to guideline 4.
If the application is an OLTP one and users need quick response times, use a global index. If the application is a DSS one and users are more interested in throughput, use a local index.
局部索引local index
1. 局部索引一定是分區索引,分區鍵等同于表的分區鍵,分區數等同于表的分區說,一句話,局部索引的分區機制和表的分區機制一樣。
2. 如果局部索引的索引列以分區鍵開頭,則稱為前綴局部索引。
3. 如果局部索引的列不是以分區鍵開頭,或者不包含分區鍵列,則稱為非前綴索引。
4. 前綴和非前綴索引都可以支持索引分區消除,前提是查詢的條件中包含索引分區鍵。
5. 局部索引只支持分區內的唯一性,無法支持表上的唯一性,因此如果要用局部索引去給表做唯一性約束,則約束中必須要包括分區鍵列。
6. 局部分區索引是對單個分區的,每個分區索引只指向一個表分區,全局索引則不然,一個分區索引能指向n個表分區,同時,一個表分區,也可能指向n個索引分區, 對分區表中的某個分區做truncate或者move,shrink等,可能會影響到n個全局索引分區,正因為這點,局部分區索引具有更高的可用性。
7. 位圖索引只能為局部分區索引。
8. 局部索引多應用于數據倉庫環境中。
全局索引global index
1. 全局索引的分區鍵和分區數和表的分區鍵和分區數可能都不相同,表和全局索引的分區機制不一樣。
2. 全局索引可以分區,也可以是不分區索引,全局索引必須是前綴索引,即全局索引的索引列必須是以索引分區鍵作為其前幾列。
3. 全局分區索引的索引條目可能指向若干個分區,因此,對于全局分區索引,即使只動,截斷一個分區中的數據,都需要rebulid若干個分區甚至是整個索引。
4. 全局索引多應用于oltp系統中。
5. 全局分區索引只按范圍或者散列hash分區,hash分區是10g以后才支持。
6. oracle9i以后對分區表做move或者truncate的時可以用update global indexes語句來同步更新全局分區索引,用消耗一定資源來換取高度的可用性。
7. 表用a列作分區,索引用b做局部分區索引,若where條件中用b來查詢,那么oracle會掃描所有的表和索引的分區,成本會比分區更高,此時可以考慮用b做全局分區索引
分區索引字典
DBA_PART_INDEXES 分區索引的概要統計信息,可以得知每個表上有哪些分區索引,分區索引的類新(local/global,)
Dba_ind_partitions 每個分區索引的分區級統計信息
Dba_indexesminusdba_part_indexes 可以得到每個表上有哪些非分區索引
索引重建
Alter index idx_name rebuild partition index_partition_name [online nologging]
需要對每個分區索引做rebuild,重建的時候可以選擇online(不會鎖定表),或者nologging建立索引的時候不生成日志,加快速度。
Alter index rebuild idx_name [online nologging]
對非分區索引,只能整個index重建
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





