溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
下文給大家帶來關于keepalived+MHA應該如何實現mysql主從高可用集群,感興趣的話就一起來看看這篇文章吧,相信看完keepalived+MHA應該如何實現mysql主從高可用集群對大家多少有點幫助吧。
一 原理分析
1 MHA簡介:
MHA(Master High Availability)目前在MySQL高可用方面是一個相對成熟的解決方案,它由日本DeNA公司youshimaton(現就職于Facebook公司)開發,是一套優秀的作為MySQL高可用性環境下故障切換和主從提升的高可用軟件。在MySQL故障切換過程中,MHA能做到在0~30秒之內自動完成數據庫的故障切換操作,并且在進行故障切換的過程中,MHA能在最大程度上保證數據的一致性,以達到真正意義上的高可用。
2 MHA組成:
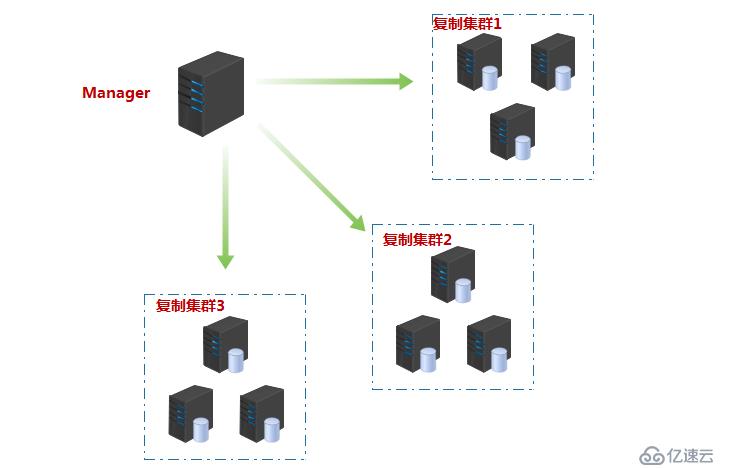
該軟件由兩部分組成:MHA Manager(管理節點)和MHA Node(數據節點)。MHA Manager可以單獨部署在一臺獨立的機器上管理多個master-slave集群,也可以部署在一臺slave節點上。MHA Node運行在每臺MySQL云服務器上,MHA Manager會定時探測集群中的master節點,當master出現故障時,它可以自動將最新數據的slave提升為新的master,然后將所有其他的slave重新指向新的master。整個故障轉移過程對應用程序完全透明。
Manager工具包主要包括以下幾個工具:
masterha_check_ssh 檢查MHA的SSH配置狀況 masterha_check_repl 檢查MySQL復制狀況 masterha_manger 啟動MHA masterha_check_status 檢測當前MHA運行狀態 masterha_master_monitor 檢測master是否宕機 masterha_master_switch 控制故障轉移(自動或者手動) masterha_conf_host 添加或刪除配置的server信息
Node工具包(這些工具通常由MHA Manager的腳本觸發,無需人為操作)主要包括以下幾個工具:
save_binary_logs 保存和復制master的二進制日志 apply_diff_relay_logs 識別差異的中繼日志事件并將其差異的事件應用于其他的slave filter_mysqlbinlog 去除不必要的ROLLBACK事件(MHA已不再使用這個工具) purge_relay_logs 清除中繼日志(不會阻塞SQL線程)
3 MHA工作原理:
在MHA自動故障切換過程中,MHA試圖從宕機的主云服務器上保存二進制日志,最大程度的保證數據的不丟失,但這并不總是可行的。例如,如果主云服務器硬件故障或無法通過ssh訪問,MHA沒法保存二進制日志,只進行故障轉移而丟失了最新的數據。使用MySQL 5.5的半同步復制,可以大大降低數據丟失的風險。MHA可以與半同步復制結合起來。如果只有一個slave已經收到了最新的二進制日志,MHA可以將最新的二進制日志應用于其他所有的slave云服務器上,因此可以保證所有節點的數據一致性。
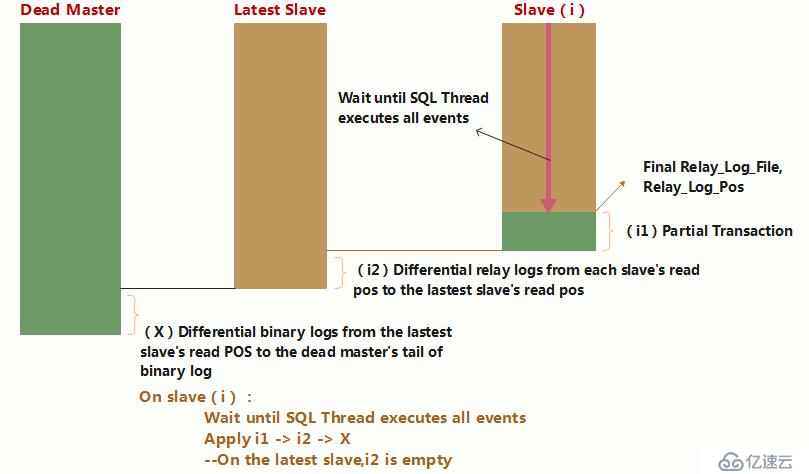
目前MHA主要支持一主多從的架構,要搭建MHA,要求一個復制集群中必須最少有三臺數據庫云服務器,一主二從,即一臺充當master,一臺充當備用master,另外一臺充當從庫,因為至少需要三臺云服務器,出于機器成本的考慮,淘寶也在該基礎上進行了改造,目前淘寶TMHA已經支持一主一從。我們自己使用其實也可以使用1主1從,但是master主機宕機后無法切換,以及無法補全binlog。master的mysqld進程crash后,還是可以切換成功,以及補全binlog的。其結構如下:
官方地址:https://code.google.com/p/mysql-master-ha/
二 實驗環境準備
1 系統版本
統一版本,統一規范,這是將來能夠自動戶運維的前提。
[root@vin ~]# cat /etc/redhat-release CentOS Linux release 7.3.1611 (Core)
2 內核參數
[root@vin ~]# uname -r 3.10.0-514.el7.x86_64
3 主機配置參數:準備4臺干凈的主機node{1,2,3,4}
互相能夠解析主機名,由于節點上配置文件,很多都是大體相同的,只需要修改一份讓后使用for循環復制給其他節點即可,簡單方便,所以這里實現主機名的認證。
角色 ip地址 主機名 server_id 類型 MHA-Manager 172.18.253.73 node1 - 監控復制組 Master 172.18.250.27 node2 1 寫入 Candicate master 172.18.253.160 node3 2 讀 Slave 172.18.254.15 node4 3 讀
4 實現互相能夠解析主機名
[root@vin ~]# cat /etc/hosts 172.18.253.73 node1 172.18.250.27 node2 172.18.253.160 node3 172.18.254.15 node4
5 實現主機間的互相無密鑰通信
由于使用MHA時,Manager需要驗證各個節點之間的ssh連通性,所以我們在這里需要實現給節點之間的無密鑰通信,這里采用了一個簡單的方法,那就是在某個節點上生成ssh密鑰對,實現本主機的認證,然后將認證文件以及公私鑰都復制到其他節點,這樣就不需要,每個節點都去創建密鑰對,在實現認證了。
[root@vin ~]# ssh-keygen -t rsa -P ''
[root@vin ~]# ssh-copy-id -i ./id_rsa.pub node1:
[root@vin ~]# for i in {2..4};do scp id_rsa{,.pub} authorized_keys root@node$i:/root/.ssh/;done三 實現主從復制集群
1 Master配置:
修改配置文件
[root@vin ~]# cat /etc/my.cnf.d/server.cnf [server] server_id = 1 # 提供給主節點一個server號碼,可以是任意的整數 log_bin = master-log # 啟用二進制日志 relay_log = relay-log # 啟用中繼日志,因為主將來也會成為從 innodb_file_per_table = ON # 每個數據表存儲為單個文件 skip_name_resolve = ON # 關閉主機名解析,有助于提升性能 max_connections = 5000 # 最大并發連接數
創建具有復制功能的用戶與用于Manager節點管理的用戶;
[root@vin ~]# mysql MariaDB [(none)]> show master status\G; *************************** 1. row *************************** File: master-log.000003 Position: 245 Binlog_Do_DB: Binlog_Ignore_DB: MariaDB [(none)]> grant replication slave,replication client on *.* to -> 'vinsent'@'172.18.%.%' identified by 'vinsent'; # 這是一個語句 MariaDB [(none)]> grant ALL on *.* to 'MhaAdmin'@'172.18.%.%' identified by 'MhaPass'; MariaDB [(none)]> flush privileges;
說明:我們應該先查看主節點正在使用的日志文件及對應的POSITION,再創建用戶,以便于從節點能夠同步擁有這些用戶;創建Manager節點用于管理的用戶時需要注意的是,用戶名中的主機范圍必須能夠囊括其他節點的地址。
2 Slave{1,2}配置:
兩個從節點的配置相同;修改配置文件,以支持主從復制功能;
[root@vin ~]# cat /etc/my.cnf.d/server.cnf [server] server_id = 2 log_bin = master-log relay_log = relay-log relay_log_purge = OFF # 關閉中繼日志裁剪功能 read_only = ON # 由于是從節點,故設置為只讀模式 innodb_file_per_table = ON skip_name_resolve = ON max_connections = 5000
連接至主節點,實現同步;
[root@vin ~]# mysql MariaDB [(none)]> change master to master_host='172.18.250.27',master_user='vinsent',master_password='vinsent',master_log_file='master-log.000003',master_log_pos=245; MariaDB [(none)]> start slave; MariaDB [(none)]> show slave status\G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 172.18.250.27 Master_User: vinsent Master_Port: 3306 Connect_Retry: 60 Master_Log_File: master-log.000003 Read_Master_Log_Pos: 637 Relay_Log_File: relay-log.000002 Relay_Log_Pos: 922 Relay_Master_Log_File: master-log.000003 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 637 Relay_Log_Space: 1210 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 1
說明:查看從節點狀態,確保"Slave_IO_Running","Slave_SQL_Running"的值為"YES",即從節點正常工作,并且"Last_IO_Errno","Last_SQL_Errno"中沒有錯誤信息提示,出現錯誤,一般就是連接性錯誤,這說明要么用戶創建的有問題,要么主從節點的數據不同步,請確保兩者數據一致。
測試一下從節點是否將主節點的數據同步至本地:
MariaDB [(none)]> select user from mysql.user; +----------+ | user | +----------+ | root | | MhaAdmin | | vinsent | | root | | | | root | | | | root | +----------+
四 安裝MHA包
除了源碼包,MHA官方也提供了rpm格式的程序包,其下載地址為http://code.google.com/p/mysql-master/wiki/Downloads?tm=2。CentOS 7 系統可直接使用適用于el6的程序包,另外,MHA Manager和MHA NODe程序包的版本并不強制要求一致。
1 Manager節點
[root@vin ~]# ls mha4mysql-manager-0.56-0.el6.noarch.rpm mha4mysql-node-0.56-0.el6.noarch.rpm
主節點需要安裝mha4mysql-manager管理包,以及node幾點包,
2 Master && SLave{1,2}節點
從節點只需要安裝mode包即可
[root@vin ~]# ls mha4mysql-node-0.56-0.el6.noarch.rpm [root@vin ~]# yum install /root/*.rpm
3 檢測各節點之間ssh可用性
出現下面的結果則說明ssh聯通性無誤
[root@vin ~]# masterha_check_ssh --conf=/etc/masterha/app1.cnf ... - [info] All SSH connection tests passed successfully.
4 檢測管理的mysql主從復制集群的連接配置參數是否滿足
[root@vin ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf ... Mon Nov 13 22:11:30 2017 - [info] Slaves settings check done. Mon Nov 13 22:11:30 2017 - [info] 172.18.250.27(172.18.250.27:3306) (current master) +--172.18.253.160(172.18.253.160:3306) +--172.18.254.15(172.18.254.15:3306) ... MySQL Replication Health is OK.
如果配置參數滿足要求,那么你將看到這個集群的主從節點,如上實例。
5 啟動MHA
Manager節點:
[root@vin ~]# masterha_manager --conf=/etc/masterha/app1.cnf Mon Nov 13 22:16:17 2017 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. # 沒有默認配置文件 Mon Nov 13 22:16:17 2017 - [info] Reading application default configuration from /etc/masterha/app1.cnf.. Mon Nov 13 22:16:17 2017 - [info] Reading server configuration from /etc/masterha/app1.cnf..
說明:MHA默認是工作在前臺的,要想將它防止至后臺運行,可使用下面的命令:
[root@vin ~]# nohup masterha_manager --conf=/etc/masterha/app1.cnf > \ /data/masterha/app1/managerha/manager.log 2&>1 &
成功啟動之后,查看一下Master節點的狀態;
[root@vin ~]# masterha_check_status --conf=/etc/masterha/app1.cnf app1 (pid:4090) is running(0:PING_OK), master:172.18.250.27
說明:如果未成功啟動,這里的命令將不能夠正確執行;提示:"app1 is stopped(2:NOT_RUNNING)."
六 配置keepalived
設置為用戶提供服務的地址為"172.18.14.55/16",通過keepalived實現VIP在Mysql復制集群中浮動。
1 安裝keepalived
使用默認yum安裝即可;在Mysql復制集群的所有主機上都安裝配置keepalived;
[root@vin ~]# yum install keepalived -y
2修改keepalived配置文件實現keepalived集群
Master:
[root@vin ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from kadmin@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_DEVEL
route_mcast_group4 224.14.0.14 # 廣播地址
}
vrrp_script chk_mysql {
script "killall -0 mysql" # 監控mysql健康性腳本
insterval 1
weight -10
}
vrrp_instance VI_1 { # keepalived實例
state BACKUP
interface ens33
virtual_router_id 66
priority 98 # keepalived節點優先級
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.18.14.55/16 # 面向客戶端的地址
}
track_script {
chk_mysql
}
}Slave{1,2}:復主節點的配置文件至Slave節點:
[root@vin ~]# for i in {3,4};do scp /etc/keepalived/keepalived.conf \
root@node$i:/etc/keepalived/ ;done說明:復制過去并不能直接使用,由于keepalived通過優先級機制來決定VIP工作在哪臺主機,所以將兩個從節點的優先級調節至比主節點上keepalived的優先級低,且互相不同。
有心人可能發現問題了,怎么沒有修改VRRP實例的狀態"state BACKUP";上面云服務器的keepalived都設置為了BACKUP模式,在keepalived中2種模式,分別是master->backup模式和backup->backup模式。這兩種模式有很大區別。在master->backup模式下,一旦主節點宕機,虛擬ip會自動漂移到從節點,當主節點修復后,keepalived啟動后,還會把虛擬ip搶占過來,即使設置了非搶占模式(nopreempt)搶占ip的動作也會發生。在backup->backup模式下,當主節點故障后虛擬ip會自動漂移到從節點上,當原主節點恢復后,并不會搶占新主的虛擬ip,即使是優先級高于從庫的優先級別,也不會發生搶占。為了減少ip漂移次數,通常是把修復好的主庫當做新的備庫。
七 故障出現
模擬故障發生,我們手動"down"掉了主節點,生產中可能有各種原因導致故障的出現,這里為了最好的模擬辦法,當然是關停服務了。
1 Master
[root@vin ~]# systemctl stop mariadb
2 在MHA節點上查看MHA的狀態
[root@vin ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf .... Mon Nov 13 22:36:37 2017 - [info] MHA::MasterMonitor version 0.56. Mon Nov 13 22:36:37 2017 - [info] GTID failover mode = 0 Mon Nov 13 22:36:37 2017 - [info] Dead Servers: # 指明故障的節點 Mon Nov 13 22:36:37 2017 - [info] 172.18.250.27(172.18.250.27:3306) Mon Nov 13 22:36:37 2017 - [info] Alive Servers: Mon Nov 13 22:36:37 2017 - [info] 172.18.253.160(172.18.253.160:3306) Mon Nov 13 22:36:37 2017 - [info] 172.18.254.15(172.18.254.15:3306) Mon Nov 13 22:36:37 2017 - [info] Alive Slaves: Mon Nov 13 22:36:37 2017 - [info] 172.18.254.15(172.18.254.15:3306) # 從節點由兩個轉為了一個,另為一個升級為主節點 ....
3 在從節點進行測試看主節點是否正確切換
Slave1:
MariaDB [(none)]> show slave status; # 查看從節點狀態為空,說明已非從節點 Empty set (0.00 sec) MariaDB [(none)]> show master status; # 再查看master狀態,已正確切換 +-------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +-------------------+----------+--------------+------------------+ | master-log.000003 | 245 | | | +-------------------+----------+--------------+------------------+
Slave2:
MariaDB [(none)]> show slave status\G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 172.18.253.160 # 從節點"Slave2"已經將主節點指向了新的主節點 Master_User: vinsent Master_Port: 3306 Connect_Retry: 60 Master_Log_File: master-log.000003 ...
4 查看keepalived地址綁定情況:
Master:
[root@vin ~]# ip a | grep ens33 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 inet 172.18.250.27/16 brd 172.18.255.255 scope global dynamic ens33
Slave1:
[root@vin ~]# ip a | grep ens33 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 inet 172.18.250.160/16 brd 172.18.255.255 scope global dynamic ens33 inet 172.18.14.55/16 scope global secondary ens33 # 地址正確漂移至從節點Slave1
Slave2:
[root@vin ~]# ip a | grep ens33 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 inet 172.18.254.15/16 brd 172.18.255.255 scope global dynamic ens33
八 故障恢復
為了滿足集群要求,應當立即將故障的主節點修復上線。由于Mysql復制集群的主節點已然切換,那么故障的原主節點上線之后只能為從節點,所以應當修改其配置文件滿足從節點的要求。
1 Master節點
[root@vin ~]# vim /etc/my.cnf.d/server.cnf # 添加如下兩項 [server] relay_log_purge = OFF read_only = ON
啟動服務,并連接Mysql;并連接至新的主節點做主從同步;這里值得注意的是:如果你的主節點是在運行過程中故障宕機來了,那么你要做的就不僅僅是修改配置,啟動服務了。修改配置文件之后,應當對新主做一個完全備份,將新主節點的數據恢復至本機,然后在連接至新的主節點做復制同步(本實驗沒有太多的數據,故直接上線)。
[root@vin ~]# systemctl start mariadb [root@vin ~]# mysql MariaDB [(none)]> change master to master_host='172.18.253.160',master_user='vinsent',master_password='vinsent',master_log_file='master-log.000003',master_log_pos=245; MariaDB [(none)]> start slave; MariaDB [(none)]> show slave status\G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 172.18.253.160 Master_User: vinsent Master_Port: 3306 ...
2 Manager:
切換至MHA上并查看集群狀態;
[root@vin ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf ... Mon Nov 13 22:54:53 2017 - [info] GTID failover mode = 0 Mon Nov 13 22:54:53 2017 - [info] Dead Servers: Mon Nov 13 22:54:53 2017 - [info] Alive Servers: Mon Nov 13 22:54:53 2017 - [info] 172.18.250.27(172.18.250.27:3306) # 由于沒有在配置文件中指明誰是主,故這里只能看到所有工作的主機 Mon Nov 13 22:54:53 2017 - [info] 172.18.253.160(172.18.253.160:3306) Mon Nov 13 22:54:53 2017 - [info] 172.18.254.15(172.18.254.15:3306) Mon Nov 13 22:54:53 2017 - [info] Alive Slaves: Mon Nov 13 22:54:53 2017 - [info] 172.18.250.27(172.18.250.27:3306) ... MySQL Replication Health is OK.
啟動MHA Manger監控,查看集群里面現在誰是master;
[root@vin ~]# masterha_check_status --conf=/etc/masterha/app1.cnf app1 is stopped(2:NOT_RUNNING).
??怎么回事,明明已經正確啟動,為何此處顯示為“stopped”;趕緊去官網一查發現:"Currently MHA Manager process does not run as a daemon. If failover completed successfully or the master process was killed by accident, the manager stops working. To run as a daemon, daemontool. or any external daemon program can be used. Here is an example to run from daemontools.",原來如此。
九 總結
通過查日志觀察切換過程分析MHA切換過程:
[root@vin masterha]# cat manager.log Mon Nov 13 22:36:03 2017 - [info] MHA::MasterMonitor version 0.56. Mon Nov 13 22:36:04 2017 - [info] GTID failover mode = 0 Mon Nov 13 22:36:04 2017 - [info] Dead Servers: Mon Nov 13 22:36:04 2017 - [info] 172.18.250.27(172.18.250.27:3306) Mon Nov 13 22:36:04 2017 - [info] Alive Servers: Mon Nov 13 22:36:04 2017 - [info] 172.18.253.160(172.18.253.160:3306) Mon Nov 13 22:36:04 2017 - [info] 172.18.254.15(172.18.254.15:3306) Mon Nov 13 22:36:04 2017 - [info] Alive Slaves: Mon Nov 13 22:36:04 2017 - [info] 172.18.254.15(172.18.254.15:3306) Version=5.5.52-MariaDB (oldest major version between slaves) log-bin:enabled Mon Nov 13 22:36:04 2017 - [info] Replicating from 172.18.253.160(172.18.253.160:3306) Mon Nov 13 22:36:04 2017 - [info] Primary candidate for the new Master (candidate_master is set) Mon Nov 13 22:36:04 2017 - [info] Current Alive Master: 172.18.253.160(172.18.253.160:3306) Mon Nov 13 22:36:04 2017 - [info] Checking slave configurations.. Mon Nov 13 22:36:04 2017 - [warning] relay_log_purge=0 is not set on slave 172.18.254.15(172.18.254.15:3306). Mon Nov 13 22:36:04 2017 - [info] Checking replication filtering settings.. Mon Nov 13 22:36:04 2017 - [info] binlog_do_db= , binlog_ignore_db= Mon Nov 13 22:36:04 2017 - [info] Replication filtering check ok. Mon Nov 13 22:36:04 2017 - [info] GTID (with auto-pos) is not supported Mon Nov 13 22:36:04 2017 - [info] Starting SSH connection tests.. Mon Nov 13 22:36:05 2017 - [info] All SSH connection tests passed successfully. Mon Nov 13 22:36:05 2017 - [info] Checking MHA Node version.. Mon Nov 13 22:36:06 2017 - [info] Version check ok. Mon Nov 13 22:36:06 2017 - [error][/usr/share/perl5/vendor_perl/MHA/ServerManager.pm, ln492] Server 172.18.250.27(172.18.250.27:3306) is dead, but must be alive! Check server settings. Mon Nov 13 22:36:06 2017 - [error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln424] Error happened on checking configurations. at /usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm line 399. Mon Nov 13 22:36:06 2017 - [error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln523] Error happened on monitoring servers. Mon Nov 13 22:36:06 2017 - [info] Got exit code 1 (Not master dead). Mon Nov 13 22:36:13 2017 - [info] MHA::MasterMonitor version 0.56. Mon Nov 13 22:36:13 2017 - [info] GTID failover mode = 0 Mon Nov 13 22:36:13 2017 - [info] Dead Servers: Mon Nov 13 22:36:13 2017 - [info] 172.18.250.27(172.18.250.27:3306) Mon Nov 13 22:36:13 2017 - [info] Alive Servers: Mon Nov 13 22:36:13 2017 - [info] 172.18.253.160(172.18.253.160:3306) Mon Nov 13 22:36:13 2017 - [info] 172.18.254.15(172.18.254.15:3306) Mon Nov 13 22:36:13 2017 - [info] Alive Slaves: Mon Nov 13 22:36:13 2017 - [info] 172.18.254.15(172.18.254.15:3306) Version=5.5.52-MariaDB (oldest major version between slaves) log-bin:enabled Mon Nov 13 22:36:13 2017 - [info] Replicating from 172.18.253.160(172.18.253.160:3306) Mon Nov 13 22:36:13 2017 - [info] Primary candidate for the new Master (candidate_master is set) Mon Nov 13 22:36:13 2017 - [info] Current Alive Master: 172.18.253.160(172.18.253.160:3306) Mon Nov 13 22:36:13 2017 - [info] Checking slave configurations.. Mon Nov 13 22:36:13 2017 - [warning] relay_log_purge=0 is not set on slave 172.18.254.15(172.18.254.15:3306). Mon Nov 13 22:36:13 2017 - [info] Checking replication filtering settings.. Mon Nov 13 22:36:13 2017 - [info] binlog_do_db= , binlog_ignore_db= Mon Nov 13 22:36:13 2017 - [info] Replication filtering check ok. Mon Nov 13 22:36:13 2017 - [info] GTID (with auto-pos) is not supported Mon Nov 13 22:36:13 2017 - [info] Starting SSH connection tests.. Mon Nov 13 22:36:15 2017 - [info] All SSH connection tests passed successfully. Mon Nov 13 22:36:15 2017 - [info] Checking MHA Node version.. Mon Nov 13 22:36:15 2017 - [info] Version check ok. Mon Nov 13 22:36:15 2017 - [error][/usr/share/perl5/vendor_perl/MHA/ServerManager.pm, ln492] Server 172.18.250.27(172.18.250.27:3306) is dead, but must be alive! Check server settings. Mon Nov 13 22:36:15 2017 - [error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln424] Error happened on checking configurations. at /usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm line 399. Mon Nov 13 22:36:15 2017 - [error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln523] Error happened on monitoring servers. Mon Nov 13 22:36:15 2017 - [info] Got exit code 1 (Not master dead).
從上面的輸出可以看出整個MHA的切換過程,共包括以下的步驟:
配置文件檢查階段,這個階段會檢查整個集群配置文件配置
宕機的master處理,這個階段包括虛擬ip摘除操作,主機關機操作,這是MHA管理keepalived的時候,我們這里是通過keepalived的腳本實現mysql狀態監控的。MHA也有管理keepalived的腳本,有需要的可以自行研究。
復制dead maste和最新slave相差的relay log,并保存到MHA Manger具體的目錄下
識別含有最新更新的slave
應用從master保存的二進制日志事件(binlog events)
提升一個slave為新的master進行復制
使其他的slave連接新的master進行復制
目前高可用方案可以一定程度上實現數據庫的高可用,比如MMM,heartbeat+drbd,Cluster等。還有percona的Galera Cluster等。這些高可用軟件各有優劣。在進行高可用方案選擇時,主要是看業務還有對數據一致性方面的要求。最后出于對數據庫的高可用和數據一致性的要求,推薦使用MHA架構。
看了以上關于keepalived+MHA應該如何實現mysql主從高可用集群詳細內容,是否有所收獲。如果想要了解更多相關,可以繼續關注我們的行業資訊板塊。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





