溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下一個正則表達式導致CPU 利用率居高不下怎么辦,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
線上一個項目監控信息突然報告異常,上到機器上后查看相關資源的使用情況,發現 CPU 利用率將近 100%。通過 Java 自帶的線程 Dump 工具,我們導出了出問題的堆棧信息。
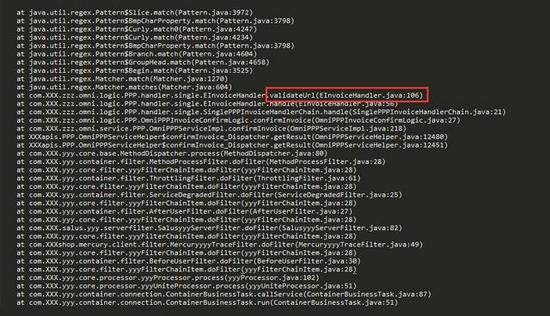
藏在正則表達式里的陷阱,一個正則表達式導致CPU 利用率居高不下
我們可以看到所有的堆棧都指向了一個名為 validateUrl 的方法,這樣的報錯信息在堆棧中一共超過 100 處。通過排查代碼,我們知道這個方法的主要功能是校驗 URL 是否合法。
很奇怪,一個正則表達式怎么會導致 CPU 利用率居高不下。為了弄清楚復現問題,我們將其中的關鍵代碼摘抄出來,做了個簡單的單元測試。
public static void main(String[] args) {
String badRegex = "^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~\\/])+$";
String bugUrl = "http://www.fapiao.com/dddp-web/pdf/download?request=6e7JGxxxxx4ILd-kExxxxxxxqJ4-CHLmqVnenXC692m74H38sdfdsazxcUmfcOH2fAfY1Vw__%5EDadIfJgiEf";
if (bugUrl.matches(badRegex)) {
System.out.println("match!!");
} else {
System.out.println("no match!!");
}
}當我們運行上面這個例子的時候,通過資源監視器可以看到有一個名為 java 的進程 CPU 利用率直接飆升到了 91.4% 。
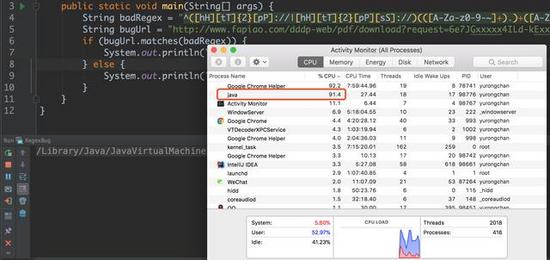
藏在正則表達式里的陷阱,一個正則表達式導致CPU 利用率居高不下
看到這里,我們基本可以推斷,這個正則表達式就是導致 CPU 利用率居高不下的兇手!
于是,我們將排錯的重點放在了那個正則表達式上:
^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~\/])+$這個正則表達式看起來沒什么問題,可以分為三個部分:
第一部分匹配 http 和 https 協議,第二部分匹配 www. 字符,第三部分匹配許多字符。我看著這個表達式發呆了許久,也沒發現沒有什么大的問題。
其實這里導致 CPU 使用率高的關鍵原因就是: Java 正則表達式使用的引擎實現是 NFA 自動機,這種正則表達式引擎在進行字符匹配時會發生回溯(backtracking)。 而一旦發生回溯,那其消耗的時間就會變得很長,有可能是幾分鐘,也有可能是幾個小時,時間長短取決于回溯的次數和復雜度。
看到這里,可能大家還不是很清楚什么是回溯,還有點懵。沒關系,我們一點點從正則表達式的原理開始講起
正則表達式引擎
正則表達式是一個很方便的匹配符號,但要實現這么復雜,功能如此強大的匹配語法,就必須要有一套算法來實現,而實現這套算法的東西就叫做正則表達式引擎。簡單地說,實現正則表達式引擎的有兩種方式: DFA 自動機 (Deterministic Final Automata 確定型有窮自動機)和 NFA 自動機 (Non deterministic Finite Automaton 不確定型有窮自動機)。
對于這兩種自動機,他們有各自的區別,這里并不打算深入將它們的原理。簡單地說,DFA 自動機的時間復雜度是線性的,更加穩定,但是功能有限。而 NFA 的時間復雜度比較不穩定,有時候很好,有時候不怎么好,好不好取決于你寫的正則表達式。但是勝在 NFA 的功能更加強大,所以包括 Java 、.NET、Perl、Python、Ruby、PHP 等語言都使用了 NFA 去實現其正則表達式。
那 NFA 自動機到底是怎么進行匹配的呢?我們以下面的字符和表達式來舉例說明。
text="Today is a nice day."regex="day"
要記住一個很重要的點,即:NFA 是以正則表達式為基準去匹配的。也就是說,NFA 自動機會讀取正則表達式的一個一個字符,然后拿去和目標字符串匹配,匹配成功就換正則表達式的下一個字符,否則繼續和目標字符串的下一個字符比較。或許你們聽不太懂,沒事,接下來我們以上面的例子一步步解析。
首先,拿到正則表達式的第一個匹配符:d。于是那去和字符串的字符進行比較,字符串的第一個字符是 T,不匹配,換下一個。第二個是 o,也不匹配,再換下一個。
第三個是 d,匹配了,那么就讀取正則表達式的第二個字符:a。 讀取到正則表達式的第二個匹配符:a。那著繼續和字符串的第四個字符 a 比較,又匹配了。那么接著讀取正則表達式的第三個字符:y。
讀取到正則表達式的第三個匹配符:y。那著繼續和字符串的第五個字符 y 比較,又匹配了。嘗試讀取正則表達式的下一個字符,發現沒有了,那么匹配結束。
上面這個匹配過程就是 NFA 自動機的匹配過程,但實際上的匹配過程會比這個復雜非常多,但其原理是不變的。
NFA自動機的回溯
了解了 NFA 是如何進行字符串匹配的,接下來我們就可以講講這篇文章的重點了:回溯。為了更好地解釋回溯,我們同樣以下面的例子來講解。
text="abbc"regex="ab{1,3}c"上面的這個例子的目的比較簡單,匹配以 a 開頭,以 c 結尾,中間有 1-3 個 b 字符的字符串。NFA 對其解析的過程是這樣子的:
首先,讀取正則表達式第一個匹配符 a 和 字符串第一個字符 a 比較,匹配了。于是讀取正則表達式第二個字符。 讀取正則表達式第二個匹配符 b{1,3} 和字符串的第二個字符 b 比較,匹配了。但因為 b{1,3} 表示 1-3 個 b 字符串,以及 NFA 自動機的貪婪特性(也就是說要盡可能多地匹配),所以此時并不會再去讀取下一個正則表達式的匹配符,而是依舊使用 b{1,3} 和字符串的第三個字符 b 比較,發現還是匹配。于是繼續使用 b{1,3} 和字符串的第四個字符 c 比較,發現不匹配了。此時就會發生回溯。 發生回溯是怎么操作呢?發生回溯后,我們已經讀取的字符串第四個字符 c 將被吐出去,指針回到第三個字符串的位置。之后,程序讀取正則表達式的下一個操作符 c,讀取當前指針的下一個字符 c 進行對比,發現匹配。于是讀取下一個操作符,但這里已經結束了。 下面我們回過頭來看看前面的那個校驗 URL 的正則表達式:
^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~\/])+$出現問題的 URL 是:
http://www.fapiao.com/dzfp-web/pdf/download?request=6e7JGm38jfjghVrv4ILd-kEn64HcUX4qL4a4qJ4-CHLmqVnenXC692m74H5oxkjgdsYazxcUmfcOH2fAfY1Vw__%5EDadIfJgiEf
我們把這個正則表達式分為三個部分:
第一部分:校驗協議。^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)。
第二部分:校驗域名。(([A-Za-z0-9-~]+).)+。
第三部分:校驗參數。([A-Za-z0-9-~/])+$。
我們可以發現正則表達式校驗協議 http:// 這部分是沒有問題的,但是在校驗 www.fapiao.com 的時候,其使用了 xxxx. 這種方式去校驗。那么其實匹配過程是這樣的:
匹配到 www.
匹配到 fapiao.
匹配到 com/dzfp-web/pdf/download?request=6e7JGm38jf.....,你會發現因為貪婪匹配的原因,所以程序會一直讀后面的字符串進行匹配,最后發現沒有點號,于是就一個個字符回溯回去了。
這是這個正則表達式存在的第一個問題。
另外一個問題是在正則表達式的第三部分,我們發現出現問題的 URL 是有下劃線(_)和百分號(%)的,但是對應第三部分的正則表達式里面卻沒有。這樣就會導致前面匹配了一長串的字符之后,發現不匹配,最后回溯回去。
這是這個正則表達式存在的第二個問題。
解決方案
明白了回溯是導致問題的原因之后,其實就是減少這種回溯,你會發現如果我在第三部分加上下劃線和百分號之后,程序就正常了。
public static void main(String[] args) {
String badRegex = "^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~_%\\/])+$";
String bugUrl = "http://www.fapiao.com/dddp-web/pdf/download?request=6e7JGxxxxx4ILd-kExxxxxxxqJ4-CHLmqVnenXC692m74H38sdfdsazxcUmfcOH2fAfY1Vw__%5EDadIfJgiEf";
if (bugUrl.matches(badRegex)) {
System.out.println("match!!");
} else {
System.out.println("no match!!");
}
}運行上面的程序,立刻就會打印出match!!。
但這是不夠的,如果以后還有其他 URL 包含了亂七八糟的字符呢,我們難不成還再修改一遍。肯定不現實嘛!
其實在正則表達式中有這么三種模式: 貪婪模式、懶惰模式、獨占模式。
在關于數量的匹配中,有 + ? * {min,max} 四種兩次,如果只是單獨使用,那么它們就是貪婪模式。
如果在他們之后加多一個 ? 符號,那么原先的貪婪模式就會變成懶惰模式,即盡可能少地匹配。但是懶惰模式還是會發生回溯現象的。例如下面這個例子:
text="abbc"regex="ab{1,3}?c"正則表達式的第一個操作符 a 與 字符串第一個字符 a 匹配,匹配成功。于是正則表達式的第二個操作符 b{1,3}? 和 字符串第二個字符 b 匹配,匹配成功。因為最小匹配原則,所以拿正則表達式第三個操作符 c 與字符串第三個字符 b 匹配,發現不匹配。于是回溯回去,拿正則表達式第二個操作符 b{1,3}? 和字符串第三個字符 b 匹配,匹配成功。于是再拿正則表達式第三個操作符 c 與字符串第四個字符 c 匹配,匹配成功。于是結束。
如果在他們之后加多一個 + 符號,那么原先的貪婪模式就會變成獨占模式,即盡可能多地匹配,但是不回溯。
于是乎,如果要徹底解決問題,就要在保證功能的同時確保不發生回溯。我將上面校驗 URL 的正則表達式的第二部分后面加多了個 + 號,即變成這樣:
^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)
(([A-Za-z0-9-~]+).)++ --->>> (這里加了個+號)
([A-Za-z0-9-~_%\/])+$這樣之后,運行原有的程序就沒有問題了。
最后推薦一個網站,這個網站可以檢查你寫的正則表達式和對應的字符串匹配時會不會有問題。
Online regex tester and debugger: PHP, PCRE, Python, Golang and JavaScript
例如我本文中存在問題的那個 URL 使用該網站檢查后會提示:catastrophic backgracking(災難性回溯)。

藏在正則表達式里的陷阱,一個正則表達式導致CPU 利用率居高不下
當你點擊左下角的「regex debugger」時,它會告訴你一共經過多少步檢查完畢,并且會將所有步驟都列出來,并標明發生回溯的位置。
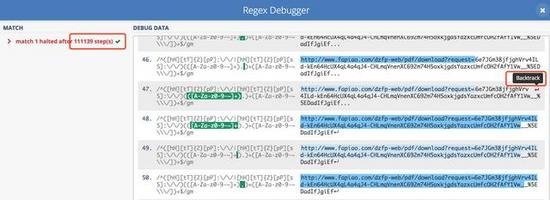
藏在正則表達式里的陷阱,一個正則表達式導致CPU 利用率居高不下
本文中的這個正則表達式在進行了 11 萬步嘗試之后,自動停止了。這說明這個正則表達式確實存在問題,需要改進。
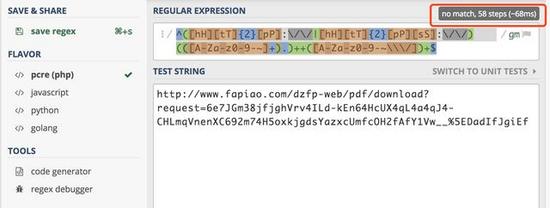
但是當我用我們修改過的正則表達式進行測試,即下面這個正則表達式。
^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+).)++([A-Za-z0-9-~\/])+$工具提示只用了 58 步就完成了檢查。
以上是“一個正則表達式導致CPU 利用率居高不下怎么辦”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





