溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“講解linux關于正則表達式grep”,在日常操作中,相信很多人在講解linux關于正則表達式grep問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”講解linux關于正則表達式grep”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
正則表達式(Regular Expression)是用于描述一組字符串特征的模式,用來匹配特定的字符串。通過特殊字符+普通字符來進行模式描述,從而達到文本匹配目的工具。類似于生活中常見的尋人啟示,通過描述一個人的特征來進行“搜索匹配”
如今正則已經被我們廣泛應用,目前被集成到了各種文本編輯器/文本處理工具當中
應用場景**驗證: **表單提交時,進行用戶名密碼驗證。**查找: **從大量信息中快速提取指定內容。在一批url中,查找指定url替換: 將指定格式的文本,進行正則匹配查找,找到之后進行特定替換,(vim文本替換等)
在很多技術領域(比如,自然語言處理,數據存儲等),正則表達式可以很方便的提取出我們想要的信息,所以這部分必不可少構成基本要素字符類數量限定符位置限定符特殊符號
1. 字符類:
| 字符 | 說明 | 舉例 |
|---|---|---|
| . | 匹配任意的一個字符 | abc. 可以匹配abcd、abc0等 |
| [] | 匹配 [] 內的任意一個字符 | [012]a可以匹配0a、1a、2a |
| - | 在括號內表示字符范圍 | 如[0-9]可以匹配任何一個數字 |
| ^ | 放在[]內前面表示匹配除括號中字符外的任意一個字符 | [^ab]c可以匹配1c、dc,但是不能匹配ac、bc |
| [[:xxx:]] | grep工具預定義的一些命名字符類 | [[:digit:]]可以匹配一個數字,[[:alpha:]]匹配一個字符,[[:lower:]]匹配任何一個小寫字母等 |
應用:
grep使用--color選項將匹配的字符串以紅色標注出來Linux下可以用echo $?來打印上一條命令執行的退出碼,為0表示執行成功,1表示失敗。
實驗如下:
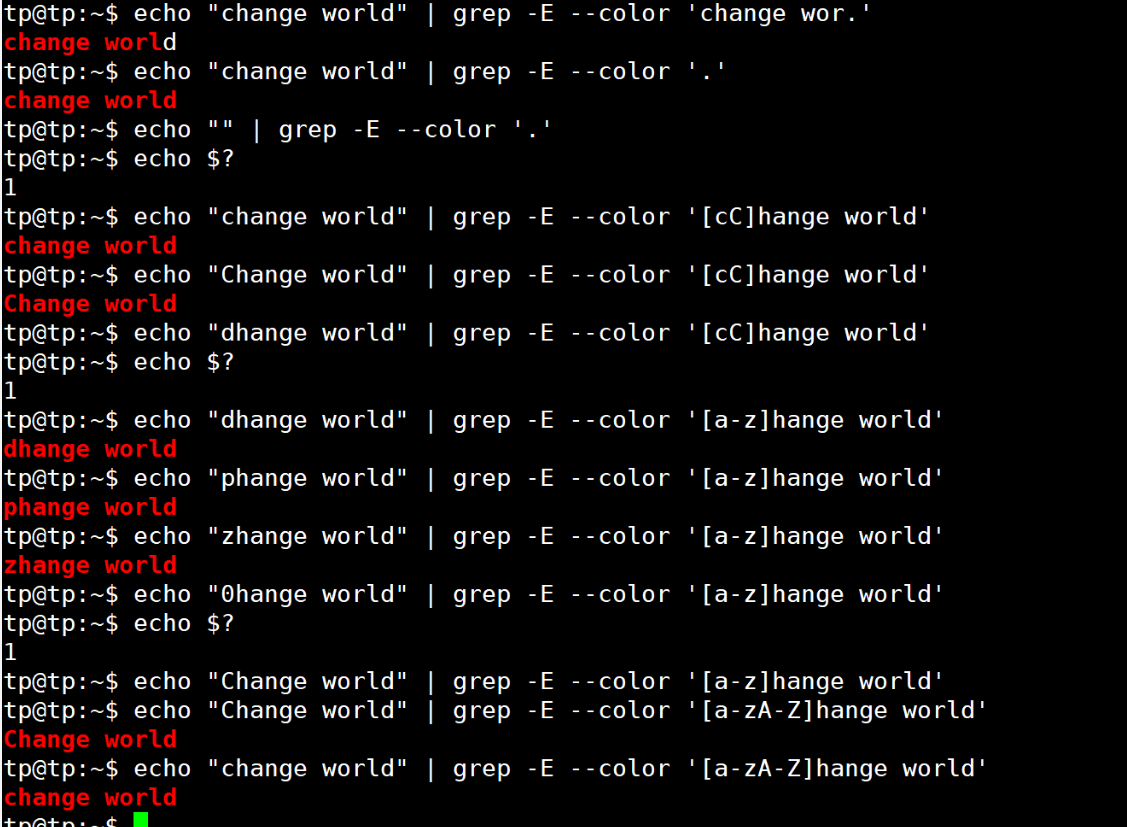
注意:使用 . 默認為貪心匹配,和后面的正則匹配方式相關,后面再述。
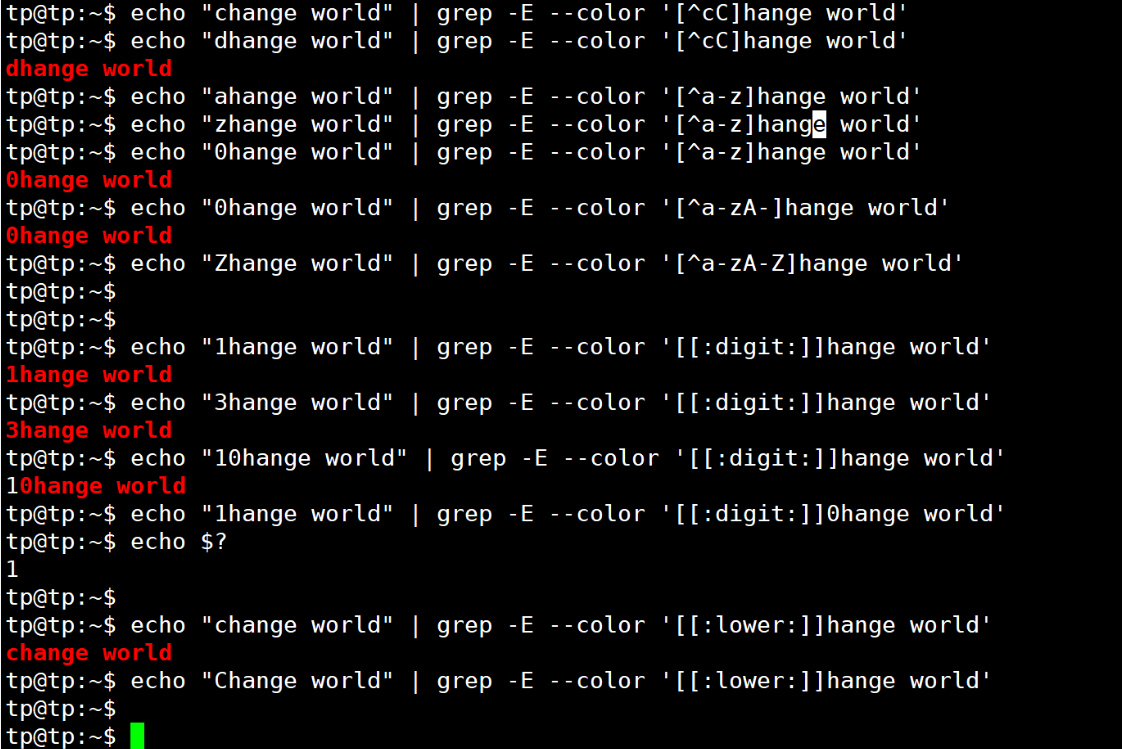
2. 數量限定符:
| 字符 | 說明 | 舉例 |
|---|---|---|
| ? | 匹配緊跟它前面的單元(前面的一個數字或字符) 0或1次 | 如匹配小數,用0\.?[0-9]匹配0.1 、0.2、0.3等;由于.在正則里面是特殊符號所以需要用\進行轉義操作(后面再說) |
| + | 匹配緊跟它前面的單元 1或多次 | [a-zA-Z0-9_.-]+@[a-zA-Z0-9_.-]+\.com匹配一個郵箱地址 |
| * | 匹配緊跟它前面的單元0或多次 | [0-9][0-9]*匹配至少一位數字,等價于[0-9]+ |
| {N} | 精確匹配緊跟它前面的單元N次 | [0-9]{3}匹配000到999之間的數字 |
| {N,} | 匹配緊跟它前面的單元至少N次 | [0-9]{3,}匹配三位及其以上的數字 |
| {,M} | 匹配緊跟它前面的單元最多M次 | [0-9]{,1}等價于[0-9]? |
| {N,M} | 匹配緊跟它前面的單元N~M次 | 近似匹配IP地址:[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3} |
應用:
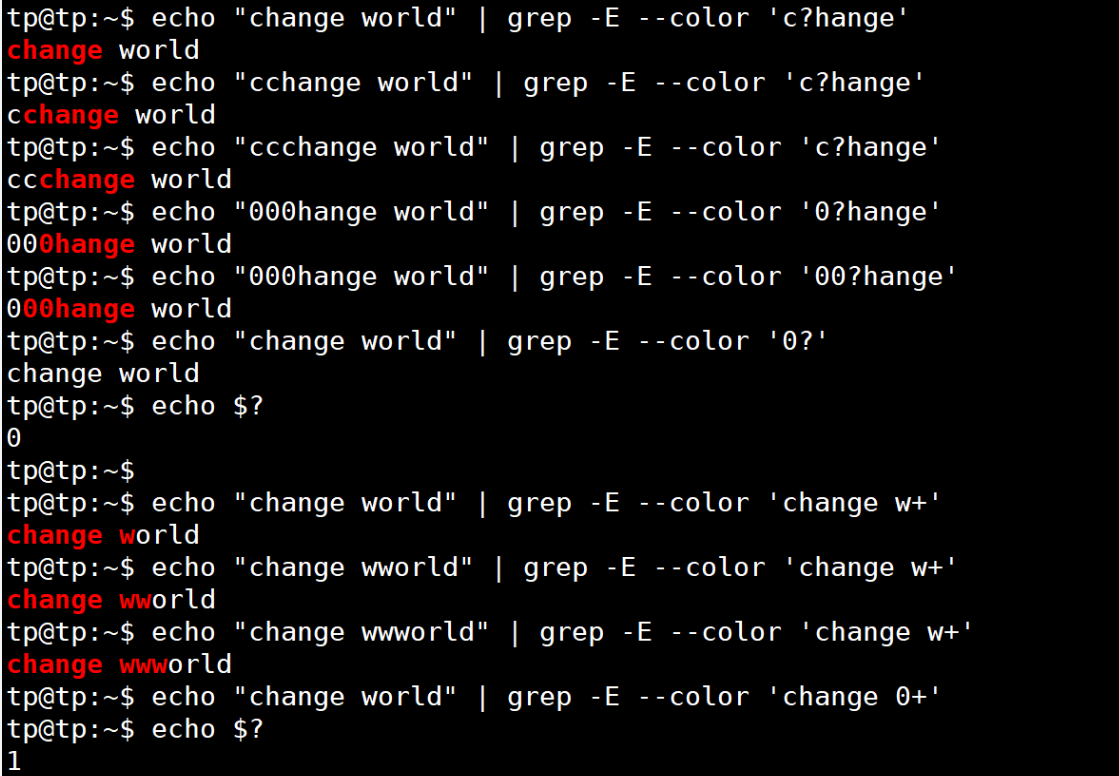
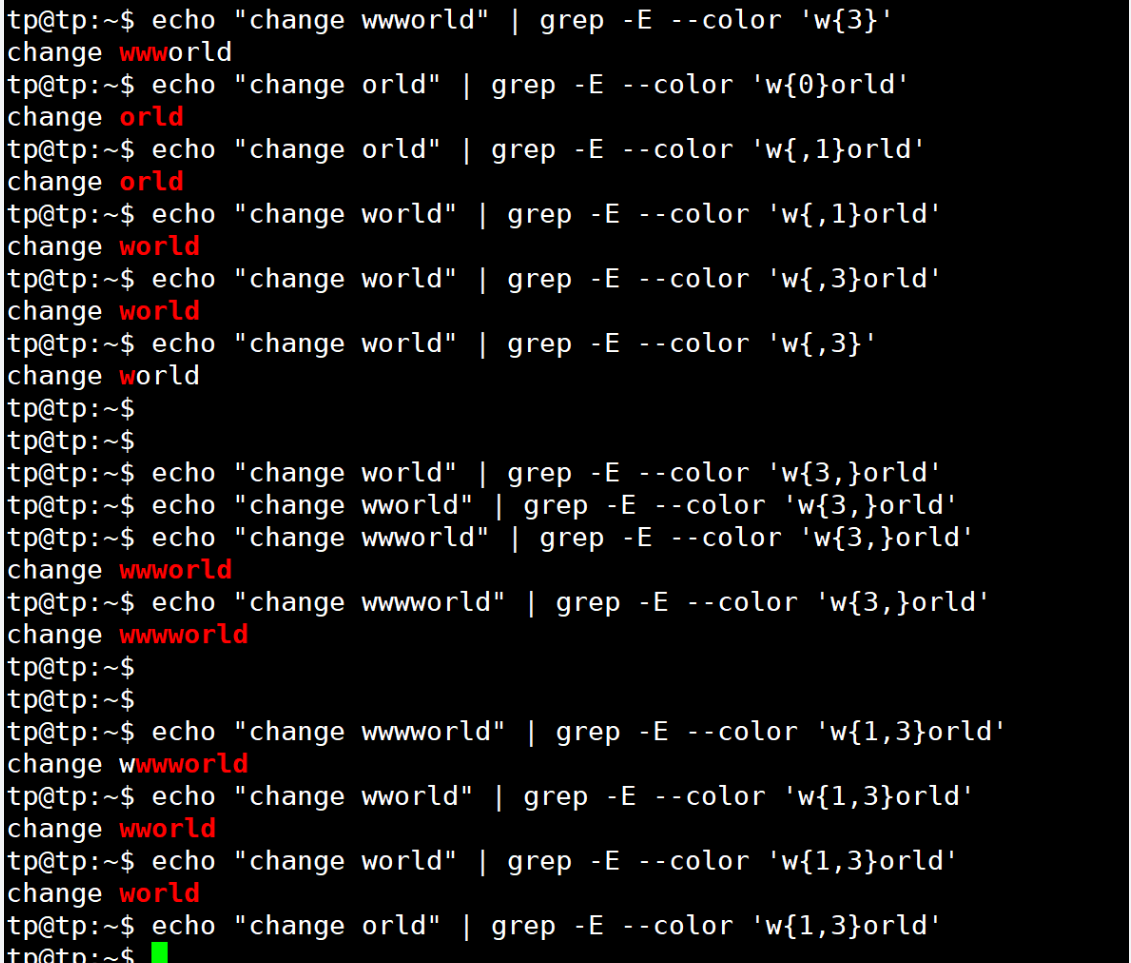
3. 位置限定符:
| 字符 | 說明 | 舉例 |
|---|---|---|
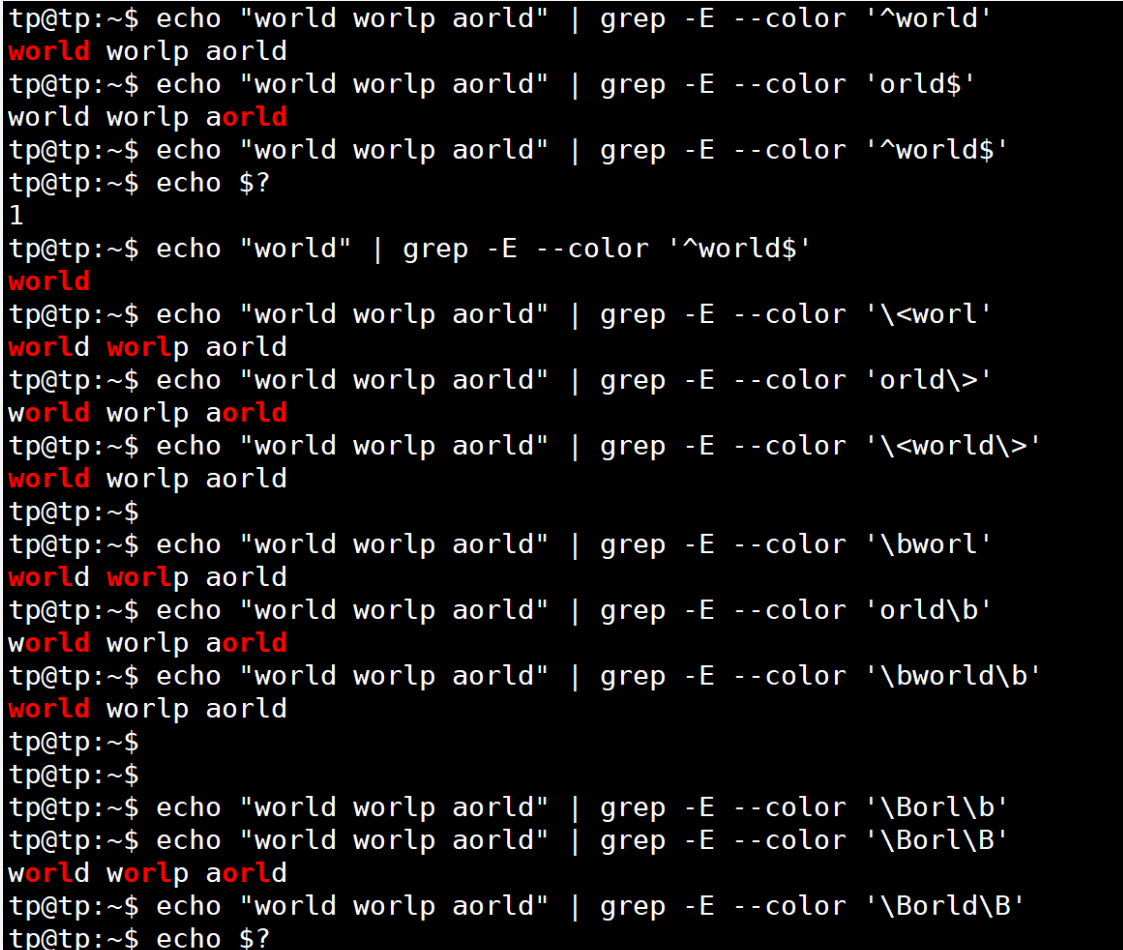
| ^ | 匹配行首位置,從行首開始匹配 | ^world只匹配一行開頭的world |
| $ | 匹配行末位置,從行末尾開始匹配 | ;$匹配一行末尾的;號,^$匹配空行 |
| < | 匹配單詞開始位置 | < th匹配this,不匹配teach、ethernet |
| \> | 匹配單詞末尾位置 | p\>匹配sleep、leap等,不匹配parent、sleepy |
| \b | 匹配單詞的開始位置、末尾位置 | 如 \borld匹配world、aorld,\borld\b只匹配orld |
| \B | 匹配非單詞的開頭、末尾位置 | 如 \Bat\B匹配battery,不匹配attend、hat等以字符串"at"開頭、結尾的單詞 |
注意:其中 \b 用來限定是目標串中是否有以指定字符串開頭的單詞,我們稱之為詞界。 \B 稱之為非詞界
應用:
4. 特殊符號:
| 字符 | 說明 | 舉例 |
|---|---|---|
| \ | 轉義字符,普通字符轉義為特殊字符,特殊字符轉義為普通字符 | <寫成<匹配單詞開頭,.前面加上\寫成\.取 . 的字面值 |
| () | 將正則表達式的一部分括起來組成一個單元,可以對整個單元使用數量限定符 | ([0-9]{1,3}\.){3}[0-9]{3}匹配IP地址 |
| | | 連接兩個子表達式,表示或的關系 | n(o|either)匹配no或neither |
應用:
( )將包含內容括起來作為一個整體,進而通過數量限定符限定。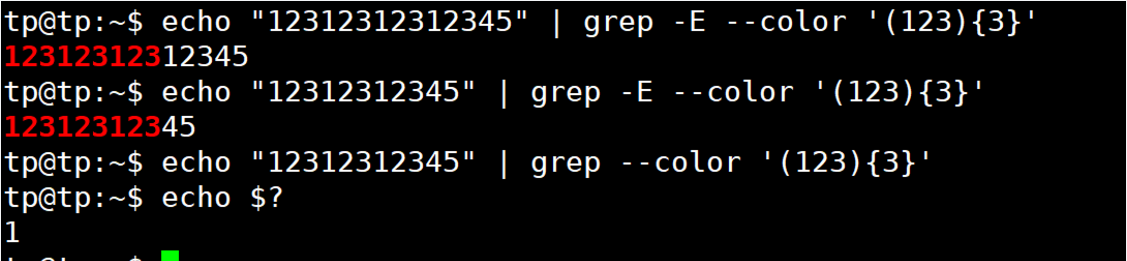
| 用來級聯多個條件,只要有任意一個匹配,即可匹配,表示或者關系,我們稱之為析取符,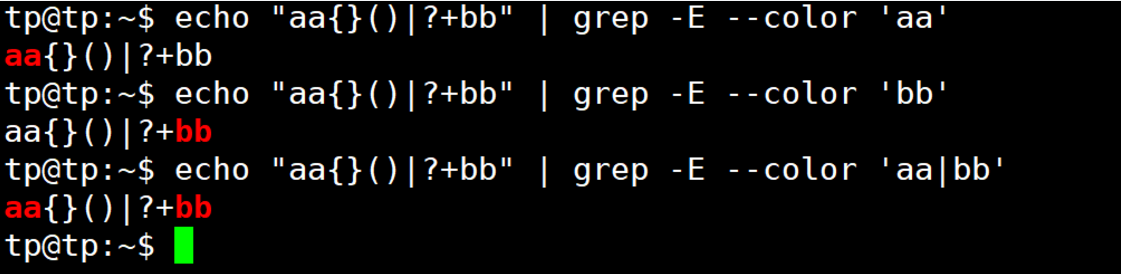
正則表達式版本其他常用通用字符集及其替換
| 符號 | 等價于 | 匹配 |
|---|---|---|
| \d | [0-9] | 數字字符 |
| \D | [^0-9] | 非數字字符 |
| \w | [a-zA-Z0-9_] | 數字字母下劃線 |
| \W | [^\w] | 非數字字母下劃線 |
| \s | [_\r\t\n\f] | 表格,換行等空白區域 |
| \S | [^\s] | 非空白區域 |
于是, 我們現在可以用這些符號來簡化我們正則表達式的編寫了?試試

可是結果好像并不如我們所愿?其實這里還與正則表達式版本有關。正則分為以下幾個版本:
基本的正則表達式(Basic Regular Expression 又叫 Basic RegEx 簡稱 BREs)擴展的正則表達式(Extended Regular Expression 又叫 Extended RegEx 簡稱 EREs)Perl 的正則表達式(Perl Regular Expression 又叫 Perl RegEx 簡稱 PREs)
在grep中指定相應的參數即可,而這幾個版本中默認的就是基本正則,帶上-E選項就是擴展正則,而帶上-P參數就是用perl版正則。解決前面的問題,我們這里讓grep帶上-P選項便可解決了
版本間區別正則表達式的Extended規范和Basic規范基本相同。只是在Basic規范下,有些字符 ?+{}|() 應解釋為普通字符,要表示上述特殊含義則需要加 \ 轉義。反之,在Extended規范下, ?+{}|() 應該被理解成特殊含義,要取其字面值,也要對其進行\ \ 轉義。所以, grep 工具帶上 -E 選項,表示使用擴展正則來進行匹配(亦可直接使用egrep 命令操作),若沒有,則表示使用基準正則進行匹配。帶-P選項使用的perl正則匹配。它是perl語言集成的最重要的一種特性,它十分強大,很多語言設計正則式支持的時候基本上都參考Perl的正則表達式。正則匹配模式
貪婪模式
正則表達式去匹配時,會盡量多的去匹配符合條件的內容,grep命令 默認使用的就是貪婪匹配,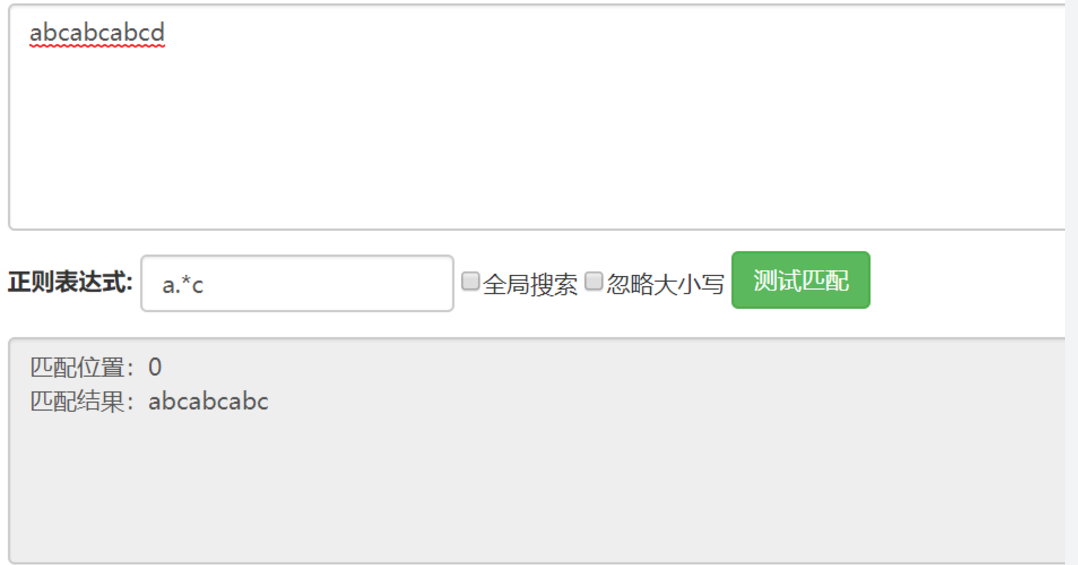 非貪婪模式
非貪婪模式
正則表達式去匹配時,會盡量少的匹配符合條件的內容 也就是說,一旦發現匹配符合要求,立馬就匹配成功,而不會繼續匹配下去(除非有g選項,開啟下一組匹配)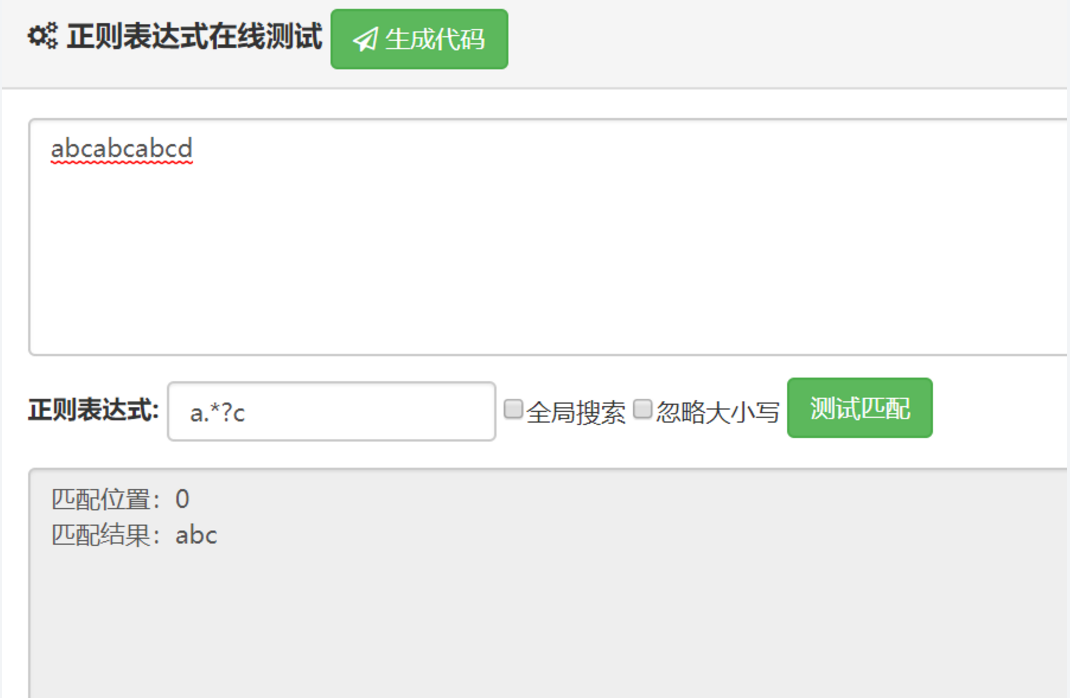
總結:可以看到,非貪婪模式的標識符,就是貪婪模式的標識符后面加上一個 ?
到此,關于“講解linux關于正則表達式grep”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





