溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹一篇文章教會你如何操作MongoDB,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
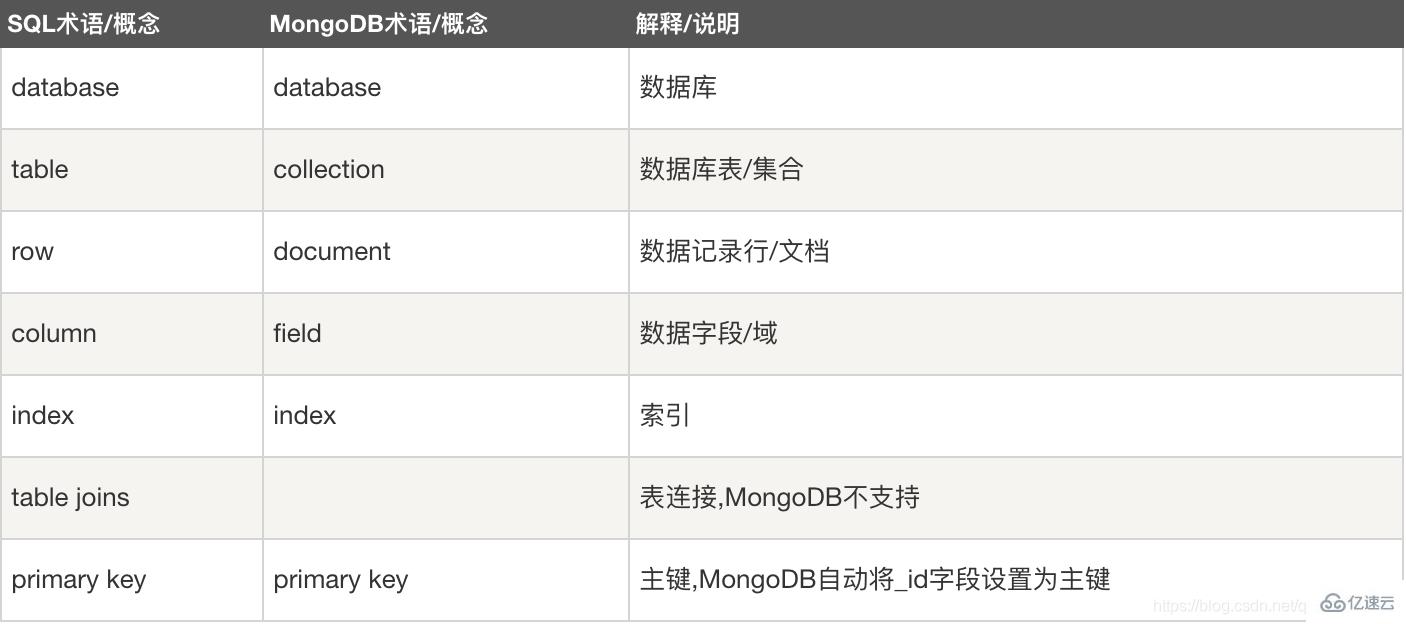
MongoDB是一款強大、靈活、且易于擴展的通用型數據庫。
MongoDB是一個面向文檔(document-oriented)的數據庫,而不是關系型數據庫。 不采用關系型主要是為了獲得更好得擴展性。當然還有一些其他好處,與關系數據庫相比,面向文檔的數據庫不再有“行“(row)的概念取而代之的是更為靈活的“文檔”(document)模型。 通過在文檔中嵌入文檔和數組,面向文檔的方法能夠僅使用一條記錄來表現復雜的層級關系,這與現代的面向對象語言的開發者對數據的看法一致。 另外,不再有預定義模式(predefined schema):文檔的鍵(key)和值(value)不再是固定的類型和大小。由于沒有固定的模式,根據需要添加或刪除字段變得更容易了。通常由于開發者能夠進行快速迭代,所以開發進程得以加快。而且,實驗更容易進行。開發者能嘗試大量的數據模型,從中選一個最好的。
應用程序數據集的大小正在以不可思議的速度增長。隨著可用帶寬的增長和存儲器價格的下降,即使是一個小規模的應用程序,需要存儲的數據量也可能大的驚人,甚至超出 了很多數據庫的處理能力。過去非常罕見的T級數據,現在已經是司空見慣了。 由于需要存儲的數據量不斷增長,開發者面臨一個問題:應該如何擴展數據庫,分為縱向擴展和橫向擴展,縱向擴展是最省力的做法,但缺點是大型機一般都非常貴,而且 當數據量達到機器的物理極限時,花再多的錢也買不到更強的機器了,此時選擇橫向擴展更為合適,但橫向擴展帶來的另外一個問題就是需要管理的機器太多。 MongoDB的設計采用橫向擴展。面向文檔的數據模型使它能很容易地在多臺服務器之間進行數據分割。MongoDB能夠自動處理跨集群的數據和負載,自動重新分配文檔,以及將 用戶的請求路由到正確的機器上。這樣,開發者能夠集中精力編寫應用程序,而不需要考慮如何擴展的問題。如果一個集群需要更大的容量,只需要向集群添加新服務器,MongoDB就會自動將現有的數據向新服務器傳送
MongoDB作為一款通用型數據庫,除了能夠創建、讀取、更新和刪除數據之外,還提供了一系列不斷擴展的獨特功能 #1、索引 支持通用二級索引,允許多種快速查詢,且提供唯一索引、復合索引、地理空間索引、全文索引 #2、聚合 支持聚合管道,用戶能通過簡單的片段創建復雜的集合,并通過數據庫自動優化 #3、特殊的集合類型 支持存在時間有限的集合,適用于那些將在某個時刻過期的數據,如會話session。類似地,MongoDB也支持固定大小的集合,用于保存近期數據,如日志 #4、文件存儲 支持一種非常易用的協議,用于存儲大文件和文件元數據。MongoDB并不具備一些在關系型數據庫中很普遍的功能,如鏈接join和復雜的多行事務。省略 這些的功能是處于架構上的考慮,或者說為了得到更好的擴展性,因為在分布式系統中這兩個功能難以高效地實現
MongoDB的一個主要目標是提供卓越的性能,這很大程度上決定了MongoDB的設計。MongoDB把盡可能多的內存用作緩存cache,視圖為每次查詢自動選擇正確的索引。 總之各方面的設計都旨在保持它的高性能 雖然MongoDB非常強大并試圖保留關系型數據庫的很多特性,但它并不追求具備關系型數據庫的所有功能。只要有可能,數據庫服務器就會將處理邏輯交給客戶端。這種精簡方式的設計是MongoDB能夠實現如此高性能的原因之一
需要注意的是: #1、文檔中的鍵/值對是有序的。 #2、文檔中的值不僅可以是在雙引號里面的字符串,還可以是其他幾種數據類型(甚至可以是整個嵌入的文檔)。 #3、MongoDB區分類型和大小寫。 #4、MongoDB的文檔不能有重復的鍵。 #5、文檔中的值可以是多種不同的數據類型,也可以是一個完整的內嵌文檔。文檔的鍵是字符串。除了少數例外情況,鍵可以使用任意UTF-8字符。 文檔鍵命名規范: #1、鍵不能含有\0 (空字符)。這個字符用來表示鍵的結尾。 #2、.和$有特別的意義,只有在特定環境下才能使用。 #3、以下劃線"_"開頭的鍵是保留的(不是嚴格要求的)。
#1、集合存在于數據庫中,通常情況下為了方便管理,不同格式和類型的數據應該插入到不同的集合,但其實集合沒有固定的結構,這意味著我們完全可以把不同格式和類型的數據統統插入一個集合中。 #2、組織子集合的方式就是使用“.”,分隔不同命名空間的子集合。 比如一個具有博客功能的應用可能包含兩個集合,分別是blog.posts和blog.authors,這是為了使組織結構更清晰,這里的blog集合(這個集合甚至不需要存在)跟它的兩個子集合沒有任何關系。 在MongoDB中,使用子集合來組織數據非常高效,值得推薦 #3、當第一個文檔插入時,集合就會被創建。合法的集合名: 集合名不能是空字符串""。 集合名不能含有\0字符(空字符),這個字符表示集合名的結尾。 集合名不能以"system."開頭,這是為系統集合保留的前綴。 用戶創建的集合名字不能含有保留字符。有些驅動程序的確支持在集合名里面包含,這是因為某些系統生成的集合中包含該字符。除非你要訪問這種系統創建的集合,否則千萬不要在名字里出現$。
數據庫也通過名字來標識。數據庫名可以是滿足以下條件的任意UTF-8字符串: #1、不能是空字符串("")。 #2、不得含有' '(空格)、.、$、/、\和\0 (空字符)。 #3、應全部小寫。 #4、最多64字節。 有一些數據庫名是保留的,可以直接訪問這些有特殊作用的數據庫。 #1、admin: 從身份認證的角度講,這是“root”數據庫,如果將一個用戶添加到admin數據庫,這個用戶將自動獲得所有數據庫的權限。再者,一些特定的服務器端命令也只能從admin數據庫運行,如列出所有數據庫或關閉服務器 #2、local: 這個數據庫永遠都不可以復制,且一臺服務器上的所有本地集合都可以存儲在這個數據庫中 #3、config: MongoDB用于分片設置時,分片信息會存儲在config數據庫中
例如: 如果要使用cms數據庫中的blog.posts集合,這個集合的命名空間就是 cmd.blog.posts。命名空間的長度不得超過121個字節,且在實際使用中應該小于100個字節
#1、安裝路徑為D:\MongoDB,將D:\MongoDB\bin目錄加入環境變量#2、新建目錄與文件D:\MongoDB\data\db
D:\MongoDB\log\mongod.log#3、新建配置文件mongod.cfg,參考:https://docs.mongodb.com/manual/reference/configuration-options/systemLog:
destination: file
path: "D:\MongoDB\log\mongod.log"
logAppend: true
storage:
journal:
enabled: true
dbPath: "D:\MongoDB\data\db"net:
bindIp: 0.0.0.0
port: 27017setParameter:
enableLocalhostAuthBypass: false
#4、制作系統服務mongod --config "D:\MongoDB\mongod.cfg" --bind_ip 0.0.0.0 --install
或者直接在命令行指定配置
mongod --bind_ip 0.0.0.0 --port 27017 --logpath D:\MongoDB\log\mongod.log --logappend --dbpath D:\MongoDB\data\db --serviceName "MongoDB" --serviceDisplayName "MongoDB" --install
先停掉服務:net stop MongoDB
然后移除服務:mongo --remove
再重新制作服務,需要加上--auth,表示加載認證功能
mongod --bind_ip 0.0.0.0 --port 27017 --logpath D:\MongoDB\log\mongod.log --logappend --dbpath D:\MongoDB\data\db --serviceName "MongoDB" --serviceDisplayName "MongoDB" --install --auth
#5、啟動\關閉net start MongoDB
net stop MongoDB#6、登錄mongo
鏈接:http://www.runoob.com/mongodb/mongodb-window-install.html#1、創建賬號use admin
db.createUser(
{
user: "root",
pwd: "123",
roles: [ { role: "root", db: "admin" } ]
})use test
db.createUser(
{
user: "tom",
pwd: "123",
roles: [ { role: "readWrite", db: "test" },
{ role: "read", db: "db1" } ]
})#2、重啟數據庫mongod --remove
mongod --config "C:\mongodb\mongod.cfg" --bind_ip 0.0.0.0 --install --auth#3、登錄:注意使用雙引號而非單引號mongo --port 27017 -u "root" -p "123" --authenticationDatabase "admin"也可以在登錄之后用db.auth("賬號","密碼")登錄
mongo
use admin
db.auth("root","123")#推薦博客:https://www.cnblogs.com/zhoujinyi/p/4610050.html#1、mongo 127.0.0.1:27017/config #連接到任何數據庫config
#2、mongo --nodb #不連接到任何數據庫
#3、啟動之后,在需要時運行new Mongo(hostname)命令就可以連接到想要的mongod了:
> conn=new Mongo('127.0.0.1:27017')
connection to 127.0.0.1:27017
> db=conn.getDB('admin')
admin
#4、help查看幫助
#5、mongo時一個簡化的JavaScript shell,是可以執行JavaScript腳本的MongoDB中存儲的文檔必須有一個"_id"鍵。這個鍵的值可以是任意類型,默認是個ObjectId對象。
在一個集合里,每個文檔都有唯一的“_id”,確保集合里每個文檔都能被唯一標識。
不同集合"_id"的值可以重復,但同一集合內"_id"的值必須唯一
#1、ObjectId
ObjectId是"_id"的默認類型。因為設計MongoDb的初衷就是用作分布式數據庫,所以能夠在分片環境中生成
唯一的標識符非常重要,而常規的做法:在多個服務器上同步自動增加主鍵既費時又費力,這就是MongoDB采用
ObjectId的原因。
ObjectId采用12字節的存儲空間,是一個由24個十六進制數字組成的字符串
0|1|2|3| 4|5|6| 7|8 9|10|11
時間戳 機器 PID 計數器
如果快速創建多個ObjectId,會發現每次只有最后幾位有變化。另外,中間的幾位數字也會變化(要是在創建過程中停頓幾秒)。
這是ObjectId的創建方式導致的,如上圖
時間戳單位為秒,與隨后5個字節組合起來,提供了秒級的唯一性。這個4個字節隱藏了文檔的創建時間,絕大多數驅動程序都會提供
一個方法,用于從ObjectId中獲取這些信息。
因為使用的是當前時間,很多用戶擔心要對服務器進行時鐘同步。其實沒必要,因為時間戳的實際值并不重要,只要它總是不停增加就好。
接下來3個字節是所在主機的唯一標識符。通常是機器主機名的散列值。這樣就可以保證不同主機生成不同的ObjectId,不產生沖突
接下來連個字節確保了在同一臺機器上并發的多個進程產生的ObjectId是唯一的
前9個字節確保了同一秒鐘不同機器不同進程產生的ObjectId是唯一的。最后3個字節是一個自動增加的 計數器。確保相同進程的同一秒產生的
ObjectId也是不一樣的。
#2、自動生成_id
如果插入文檔時沒有"_id"鍵,系統會自幫你創建 一個。可以由MongoDb服務器來做這件事。
但通常會在客戶端由驅動程序完成。這一做法非常好地體現了MongoDb的哲學:能交給客戶端驅動程序來做的事情就不要交給服務器來做。
這種理念背后的原因是:即便是像MongoDB這樣擴展性非常好的數據庫,擴展應用層也要比擴展數據庫層容易的多。將工作交給客戶端做就
減輕了數據庫擴展的負擔。#1、null:用于表示空或不存在的字段d={'x':null}#2、布爾型:true和falsed={'x':true,'y':false}#3、數值d={'x':3,'y':3.1415926}#4、字符串d={'x':'tom'}#5、日期d={'x':new Date()}d.x.getHours()#6、正則表達式d={'pattern':/^egon.*?nb$/i}正則寫在//內,后面的i代表:i 忽略大小寫
m 多行匹配模式
x 忽略非轉義的空白字符
s 單行匹配模式#7、數組d={'x':[1,'a','v']}#8、內嵌文檔user={'name':'tom','addr':{'country':'China','city':'YT'}}user.addr.country#9、對象id:是一個12字節的ID,是文檔的唯一標識,不可變d={'x':ObjectId()}#1、增use db1 #如果數據庫不存在,則創建數據庫,否則切換到指定數據庫。#2、查show dbs #查看所有可以看到,我們剛創建的數據庫db1并不在數據庫的列表中, 要顯示它,我們需要向db1數據庫插入一些數據。
db.table1.insert({'a':1})#3、刪use db1 #先切換到要刪的庫下db.dropDatabase() #刪除當前庫#1、增當第一個文檔插入時,集合就會被創建> use database1
switched to db database1> db.table1.insert({'a':1})WriteResult({ "nInserted" : 1 })> db.table2.insert({'b':2})WriteResult({ "nInserted" : 1 })db.user
db.user.info 表名是user.info,跟user表沒有任何關系
db.user.auth#2、查> show tables
table1
table2#3、刪> db.table1.drop()true> show tables
table2#1、沒有指定_id則默認ObjectId,_id不能重復,且在插入后不可變#2、插入單條user0={
"name":"tom",
"age":10,
'hobbies':['music','read','dancing'],
'addr':{
'country':'China',
'city':'BJ'
}}db.test.insert(user0)db.test.find()#3、插入多條user1={
"_id":1,
"name":"zhang3",
"age":10,
'hobbies':['music','read','dancing'],
'addr':{
'country':'China',
'city':'weifang'
}}user2={
"_id":2,
"name":"li4",
"age":20,
'hobbies':['music','read','run'],
'addr':{
'country':'China',
'city':'hebei'
}}user3={
"_id":3,
"name":"wang5",
"age":30,
'hobbies':['music','drink'],
'addr':{
'country':'China',
'city':'heibei'
}}user4={
"_id":4,
"name":"zhao6",
"age":40,
'hobbies':['music','read','dancing','tea'],
'addr':{
'country':'China',
'city':'BJ'
}}user5={
"_id":5,
"name":"sun7",
"age":50,
'hobbies':['music','read',],
'addr':{
'country':'China',
'city':'henan'
}}db.user.insertMany([user1,user2,user3,user4,user5])db.t1.insert({"_id":1,"a":"1","b":"2","c":"3"})db.t1.save({"_id":1,"z":"6"}) 有就用新的記錄覆蓋掉原來的記錄,無就新增# SQL:=,!=,>,<,>=,<=# MongoDB:{key:value}代表什么等于什么"$ne"====>不等于"$gt"====>大于"$lt"====>小于"gte"====>大于等于"lte"====>小于等于
其中"$ne"能用于所有數據類型#1、select * from db1.user where name = "alex";db.user.find({'name':'alex'})#2、select * from db1.user where name != "alex";db.user.find({'name':{"$ne":'alex'}})#3、select * from db1.user where id > 2;db.user.find({'_id':{'$gt':2}})#4、select * from db1.user where id < 3;db.user.find({'_id':{'$lt':3}})#5、select * from db1.user where id >= 2;db.user.find({"_id":{"$gte":2,}})#6、select * from db1.user where id <= 2;db.user.find({"_id":{"$lte":2}})# SQL:and,or,not# MongoDB:字典中逗號分隔的多個條件是and關系,"$or"的條件放到[]內,"$not"#1、select * from db1.user where id >= 2 and id < 4;db.user.find({'_id':{"$gte":2,"$lt":4}})#2、select * from db1.user where id >= 2 and age < 40;db.user.find({"_id":{"$gte":2},"age":{"$lt":40}})#3、select * from db1.user where id >= 5 or name = "alex";db.user.find({
"$or":[
{'_id':{"$gte":5}},
{"name":"alex"}
]})#4、select * from db1.user where id % 2=1;db.user.find({'_id':{"$mod":[2,1]}})#5、上題,取反db.user.find({'_id':{"$not":{"$mod":[2,1]}}})# SQL:in,not in# MongoDB:"$in","$nin"#1、select * from db1.user where age in (20,30,31);db.user.find({"age":{"$in":[20,30,31]}})#2、select * from db1.user where name not in ('alex','yuanhao');db.user.find({"name":{"$nin":['alex','yuanhao']}})# SQL: regexp 正則# MongoDB: /正則表達/i#1、select * from db1.user where name regexp '^j.*?(g|n)$';db.user.find({'name':/^j.*?(g|n)$/i})#1、select name,age from db1.user where id=3;db.user.find({'_id':3},{'_id':0,'name':1,'age':1})1:代表要,類似True0:代表不要,類似Flase,默認是0#1、查看有dancing愛好的人db.user.find({'hobbies':'dancing'})#2、查看既有dancing愛好又有tea愛好的人db.user.find({
'hobbies':{
"$all":['dancing','tea']
}})#3、查看第4個愛好為tea的人:".方法"db.user.find({"hobbies.3":'tea'})#4、查看所有人最后兩個愛好:"$slice"db.user.find({},{'hobbies':{"$slice":-2},"age":0,"_id":0,"name":0,"addr":0})#5、查看所有人的第2個到第3個愛好db.user.find({},{'hobbies':{"$slice":[1,2]},"age":0,"_id":0,"name":0,"addr":0})> db.blog.find().pretty(){
"_id" : 1,
"name" : "sun7公司破產的真相",
"comments" : [
{
"name" : "zhang3",
"content" : "sun7是誰???",
"thumb" : 200
},
{
"name" : "li4",
"content" : "我去,真的假的",
"thumb" : 300
},
{
"name" : "wang5",
"content" : "吃喝嫖賭抽,欠下兩個億",
"thumb" : 40
},
{
"name" : "zhao6",
"content" : "丐幫歡迎你",
"thumb" : 0
}
]}db.blog.find({},{'comments':{"$slice":-2}}).pretty() #查詢最后兩個db.blog.find({},{'comments':{"$slice":[1,2]}}).pretty() #查詢1到2# 排序:1代表升序,-1代表降序db.user.find().sort({"name":1})db.user.find().sort({"age":-1,'_id':1})# 分頁:limit代表取多少個document,skip代表跳過前多少個document。 db.user.find().sort({'age':1}).limit(1).skip(2)# 獲取數量db.user.count({'age':{"$gt":30}}) --或者
db.user.find({'age':{"$gt":30}}).count()#1、{'key':null} 匹配key的值為null或者沒有這個keydb.t2.insert({'a':10,'b':111})db.t2.insert({'a':20})db.t2.insert({'b':null})> db.t2.find({"b":null}){ "_id" : ObjectId("5a5cc2a7c1b4645aad959e5a"), "a" : 20 }{ "_id" : ObjectId("5a5cc2a8c1b4645aad959e5b"), "b" : null }#2、查找所有db.user.find() #等同于db.user.find({})db.user.find().pretty()#3、查找一個,與find用法一致,只是只取匹配成功的第一個db.user.findOne({"_id":{"$gt":3}})#4、去重db.user.find().distinct()update() 方法用于更新已存在的文檔。語法格式如下:
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
})參數說明:對比update db1.t1 set name='zhangsan',sex='Male' where name='zhang3' and age=18;query : 相當于where條件。
update : update的對象和一些更新的操作符(如$,$inc...等,相當于set后面的
upsert : 可選,默認為false,代表如果不存在update的記錄不更新也不插入,設置為true代表插入。
multi : 可選,默認為false,代表只更新找到的第一條記錄,設為true,代表更新找到的全部記錄。
writeConcern :可選,拋出異常的級別。
更新操作是不可分割的:若兩個更新同時發送,先到達服務器的先執行,然后執行另外一個,不會破壞文檔。#注意:除非是刪除,否則_id是始終不會變的#1、覆蓋式:db.user.update({'age':20},{"name":"wang5","hobbies_count":3})是用{"_id":2,"name":"wang5","hobbies_count":3}覆蓋原來的記錄#2、一種最簡單的更新就是用一個新的文檔完全替換匹配的文檔。這適用于大規模式遷移的情況。例如var obj=db.user.findOne({"_id":2})obj.username=obj.name+'SB'obj.hobbies_count++delete obj.age
db.user.update({"_id":2},obj)#設置:$set通常文檔只會有一部分需要更新。可以使用原子性的更新修改器,指定對文檔中的某些字段進行更新。
更新修改器是種特殊的鍵,用來指定復雜的更新操作,比如修改、增加后者刪除#1、update db1.user set name="wang5" where id = 2db.user.update({'_id':2},{"$set":{"name":"wang5",}})#2、沒有匹配成功則新增一條{"upsert":true}db.user.update({'_id':6},{"$set":{"name":"wang5","age":18}},{"upsert":true})#3、默認只改匹配成功的第一條,{"multi":改多條}db.user.update({'_id':{"$gt":4}},{"$set":{"age":28}})db.user.update({'_id':{"$gt":4}},{"$set":{"age":38}},{"multi":true})#4、修改內嵌文檔,把名字為wang5的人所在的地址國家改成Japandb.user.update({'name':"wang5"},{"$set":{"addr.country":"Japan"}})#5、把名字為wang5的人的地2個愛好改成piaodb.user.update({'name':"wang5"},{"$set":{"hobbies.1":"piao"}})#6、刪除wang5的愛好,$unsetdb.user.update({'name':"wang5"},{"$unset":{"hobbies":""}})#增加和減少:$inc#1、所有人年齡增加一歲db.user.update({},
{
"$inc":{"age":1}
},
{
"multi":true }
)#2、所有人年齡減少5歲db.user.update({},
{
"$inc":{"age":-5}
},
{
"multi":true }
)#添加刪除數組內元素
往數組內添加元素:$push#1、為名字為wang5的人添加一個愛好readdb.user.update({"name":"wang5"},{"$push":{"hobbies":"read"}})#2、為名字為wang5的人一次添加多個愛好tea,dancingdb.user.update({"name":"wang5"},{"$push":{
"hobbies":{"$each":["tea","dancing"]}}})按照位置且只能從開頭或結尾刪除元素:$pop#3、{"$pop":{"key":1}} 從數組末尾刪除一個元素db.user.update({"name":"wang5"},{"$pop":{
"hobbies":1}})#4、{"$pop":{"key":-1}} 從頭部刪除db.user.update({"name":"wang5"},{"$pop":{
"hobbies":-1}})#5、按照條件刪除元素,:"$pull" 把符合條件的統統刪掉,而$pop只能從兩端刪db.user.update({'addr.country':"China"},{"$pull":{
"hobbies":"read"}},{
"multi":true})#避免添加重復:"$addToSet"db.urls.insert({"_id":1,"urls":[]})db.urls.update({"_id":1},{"$addToSet":{"urls":'http://www.baidu.com'}})db.urls.update({"_id":1},{"$addToSet":{"urls":'http://www.baidu.com'}})db.urls.update({"_id":1},{"$addToSet":{"urls":'http://www.baidu.com'}})db.urls.update({"_id":1},{
"$addToSet":{
"urls":{
"$each":[
'http://www.baidu.com',
'http://www.baidu.com',
'http://www.xxxx.com'
]
}
}
})#1、了解:限制大小"$slice",只留最后n個db.user.update({"_id":5},{
"$push":{"hobbies":{
"$each":["read",'music','dancing'],
"$slice":-2
}
}})#2、了解:排序The $sort element value must be either 1 or -1"db.user.update({"_id":5},{
"$push":{"hobbies":{
"$each":["read",'music','dancing'],
"$slice":-1,
"$sort":-1
}
}})#注意:不能只將"$slice"或者"$sort"與"$push"配合使用,且必須使用"$eah"#1、刪除多個中的第一個db.user.deleteOne({ 'age': 8 })#2、刪除國家為China的全部db.user.deleteMany( {'addr.country': 'China'} ) #3、刪除全部db.user.deleteMany({})如果你有數據存儲在MongoDB中,你想做的可能就不僅僅是將數據提取出來那么簡單了;你可能希望對數據進行分析并加以利用。MongoDB提供了以下聚合工具:#1、聚合框架#2、MapReduce(詳見MongoDB權威指南)#3、幾個簡單聚合命令:count、distinct和group。(詳見MongoDB權威指南)#聚合框架:可以使用多個構件創建一個管道,上一個構件的結果傳給下一個構件。 這些構件包括(括號內為構件對應的操作符):篩選($match)、投射($project)、分組($group)、排序($sort)、限制($limit)、跳過($skip)不同的管道操作符可以任意組合,重復使用
from pymongo import MongoClientimport datetime
client=MongoClient('mongodb://root:123@localhost:27017')table=client['db1']['emp']# table.drop()l=[('tom','male',18,'20170301','校長',73000.33,401,1), #以下是教學部('bob','male',78,'20150302','teacher',10000.31,401,1),('sam','male',81,'20130305','teacher',8300,401,1),('zhang3','male',73,'20140701','teacher',3500,401,1),('li4','male',28,'20121101','teacher',2100,401,1),('may','female',18,'20110211','teacher',9000,401,1),('wang5','male',18,'19000301','teacher',30000,401,1),('成龍','male',48,'20101111','teacher',10000,401,1),('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是銷售部門('丫丫','female',38,'20101101','sale',2000.35,402,2),('丁丁','female',18,'20110312','sale',1000.37,402,2),('星星','female',18,'20160513','sale',3000.29,402,2),('格格','female',28,'20170127','sale',4000.33,402,2),('張野','male',28,'20160311','operation',10000.13,403,3), #以下是運營部門('程咬金','male',18,'19970312','operation',20000,403,3),('程咬銀','female',18,'20130311','operation',19000,403,3),('程咬銅','male',18,'20150411','operation',18000,403,3),('程咬鐵','female',18,'20140512','operation',17000,403,3)]for n,item in enumerate(l):
d={
"_id":n,
'name':item[0],
'sex':item[1],
'age':item[2],
'hire_date':datetime.datetime.strptime(item[3],'%Y%m%d'),
'post':item[4],
'salary':item[5]
}
table.save(d){"$match":{"字段":"條件"}},可以使用任何常用查詢操作符$gt,$lt,$in等#例1、select * from db1.emp where post='teacher';db.emp.aggregate({"$match":{"post":"teacher"}})#例2、select * from db1.emp where id > 3 group by post; db.emp.aggregate(
{"$match":{"_id":{"$gt":3}}},
{"$group":{"_id":"$post",'avg_salary':{"$avg":"$salary"}}})#例3、select * from db1.emp where id > 3 group by post having avg(salary) > 10000; db.emp.aggregate(
{"$match":{"_id":{"$gt":3}}},
{"$group":{"_id":"$post",'avg_salary':{"$avg":"$salary"}}},
{"$match":{"avg_salary":{"$gt":10000}}}){"$project":{"要保留的字段名":1,"要去掉的字段名":0,"新增的字段名":"表達式"}}#1、select name,post,(age+1) as new_age from db1.emp;db.emp.aggregate(
{"$project":{
"name":1,
"post":1,
"new_age":{"$add":["$age",1]}
}})#2、表達式之數學表達式{"$add":[expr1,expr2,...,exprN]} #相加{"$subtract":[expr1,expr2]} #第一個減第二個{"$multiply":[expr1,expr2,...,exprN]} #相乘{"$pide":[expr1,expr2]} #第一個表達式除以第二個表達式的商作為結果{"$mod":[expr1,expr2]} #第一個表達式除以第二個表達式得到的余數作為結果#3、表達式之日期表達式:$year,$month,$week,$dayOfMonth,$dayOfWeek,$dayOfYear,$hour,$minute,$second#例如:select name,date_format("%Y") as hire_year from db1.empdb.emp.aggregate(
{"$project":{"name":1,"hire_year":{"$year":"$hire_date"}}})#例如查看每個員工的工作多長時間db.emp.aggregate(
{"$project":{"name":1,"hire_period":{
"$subtract":[
{"$year":new Date()},
{"$year":"$hire_date"}
]
}}})#4、字符串表達式{"$substr":[字符串/$值為字符串的字段名,起始位置,截取幾個字節]}{"$concat":[expr1,expr2,...,exprN]} #指定的表達式或字符串連接在一起返回,只支持字符串拼接{"$toLower":expr}{"$toUpper":expr}db.emp.aggregate( {"$project":{"NAME":{"$toUpper":"$name"}}})#5、邏輯表達式$and$or$not其他見Mongodb權威指南{"$group":{"_id":分組字段,"新的字段名":聚合操作符}}#1、將分組字段傳給$group函數的_id字段即可{"$group":{"_id":"$sex"}} #按照性別分組{"$group":{"_id":"$post"}} #按照職位分組{"$group":{"_id":{"state":"$state","city":"$city"}}} #按照多個字段分組,比如按照州市分組#2、分組后聚合得結果,類似于sql中聚合函數的聚合操作符:$sum、$avg、$max、$min、$first、$last#例1:select post,max(salary) from db1.emp group by post; db.emp.aggregate({"$group":{"_id":"$post","max_salary":{"$max":"$salary"}}})#例2:去每個部門最大薪資與最低薪資db.emp.aggregate({"$group":{"_id":"$post","max_salary":{"$max":"$salary"},"min_salary":{"$min":"$salary"}}})#例3:如果字段是排序后的,那么$first,$last會很有用,比用$max和$min效率高db.emp.aggregate({"$group":{"_id":"$post","first_id":{"$first":"$_id"}}})#例4:求每個部門的總工資db.emp.aggregate({"$group":{"_id":"$post","count":{"$sum":"$salary"}}})#例5:求每個部門的人數db.emp.aggregate({"$group":{"_id":"$post","count":{"$sum":1}}})#3、數組操作符{"$addToSet":expr}:不重復{"$push":expr}:重復#例:查詢崗位名以及各崗位內的員工姓名:select post,group_concat(name) from db1.emp group by post;db.emp.aggregate({"$group":{"_id":"$post","names":{"$push":"$name"}}})db.emp.aggregate({"$group":{"_id":"$post","names":{"$addToSet":"$name"}}}){"$sort":{"字段名":1,"字段名":-1}} #1升序,-1降序{"$limit":n} {"$skip":n} #跳過多少個文檔#例1、取平均工資最高的前兩個部門db.emp.aggregate({
"$group":{"_id":"$post","平均工資":{"$avg":"$salary"}}},{
"$sort":{"平均工資":-1}},{
"$limit":2})#例2、db.emp.aggregate({
"$group":{"_id":"$post","平均工資":{"$avg":"$salary"}}},{
"$sort":{"平均工資":-1}},{
"$limit":2},{
"$skip":1})#集合users包含的文檔如下{ "_id" : 1, "name" : "dave123", "q1" : true, "q2" : true }{ "_id" : 2, "name" : "dave2", "q1" : false, "q2" : false }{ "_id" : 3, "name" : "ahn", "q1" : true, "q2" : true }{ "_id" : 4, "name" : "li", "q1" : true, "q2" : false }{ "_id" : 5, "name" : "annT", "q1" : false, "q2" : true }{ "_id" : 6, "name" : "li", "q1" : true, "q2" : true }{ "_id" : 7, "name" : "ty", "q1" : false, "q2" : true }#下述操作時從users集合中隨機選取3個文檔db.users.aggregate(
[ { $sample: { size: 3 } } ])MongoDB是一款強大、靈活、且易于擴展的通用型數據庫。
MongoDB是一個面向文檔(document-oriented)的數據庫,而不是關系型數據庫。 不采用關系型主要是為了獲得更好得擴展性。當然還有一些其他好處,與關系數據庫相比,面向文檔的數據庫不再有“行“(row)的概念取而代之的是更為靈活的“文檔”(document)模型。 通過在文檔中嵌入文檔和數組,面向文檔的方法能夠僅使用一條記錄來表現復雜的層級關系,這與現代的面向對象語言的開發者對數據的看法一致。 另外,不再有預定義模式(predefined schema):文檔的鍵(key)和值(value)不再是固定的類型和大小。由于沒有固定的模式,根據需要添加或刪除字段變得更容易了。通常由于開發者能夠進行快速迭代,所以開發進程得以加快。而且,實驗更容易進行。開發者能嘗試大量的數據模型,從中選一個最好的。
應用程序數據集的大小正在以不可思議的速度增長。隨著可用帶寬的增長和存儲器價格的下降,即使是一個小規模的應用程序,需要存儲的數據量也可能大的驚人,甚至超出 了很多數據庫的處理能力。過去非常罕見的T級數據,現在已經是司空見慣了。 由于需要存儲的數據量不斷增長,開發者面臨一個問題:應該如何擴展數據庫,分為縱向擴展和橫向擴展,縱向擴展是最省力的做法,但缺點是大型機一般都非常貴,而且 當數據量達到機器的物理極限時,花再多的錢也買不到更強的機器了,此時選擇橫向擴展更為合適,但橫向擴展帶來的另外一個問題就是需要管理的機器太多。 MongoDB的設計采用橫向擴展。面向文檔的數據模型使它能很容易地在多臺服務器之間進行數據分割。MongoDB能夠自動處理跨集群的數據和負載,自動重新分配文檔,以及將 用戶的請求路由到正確的機器上。這樣,開發者能夠集中精力編寫應用程序,而不需要考慮如何擴展的問題。如果一個集群需要更大的容量,只需要向集群添加新服務器,MongoDB就會自動將現有的數據向新服務器傳送
MongoDB作為一款通用型數據庫,除了能夠創建、讀取、更新和刪除數據之外,還提供了一系列不斷擴展的獨特功能 #1、索引 支持通用二級索引,允許多種快速查詢,且提供唯一索引、復合索引、地理空間索引、全文索引 #2、聚合 支持聚合管道,用戶能通過簡單的片段創建復雜的集合,并通過數據庫自動優化 #3、特殊的集合類型 支持存在時間有限的集合,適用于那些將在某個時刻過期的數據,如會話session。類似地,MongoDB也支持固定大小的集合,用于保存近期數據,如日志 #4、文件存儲 支持一種非常易用的協議,用于存儲大文件和文件元數據。MongoDB并不具備一些在關系型數據庫中很普遍的功能,如鏈接join和復雜的多行事務。省略 這些的功能是處于架構上的考慮,或者說為了得到更好的擴展性,因為在分布式系統中這兩個功能難以高效地實現
MongoDB的一個主要目標是提供卓越的性能,這很大程度上決定了MongoDB的設計。MongoDB把盡可能多的內存用作緩存cache,視圖為每次查詢自動選擇正確的索引。 總之各方面的設計都旨在保持它的高性能 雖然MongoDB非常強大并試圖保留關系型數據庫的很多特性,但它并不追求具備關系型數據庫的所有功能。只要有可能,數據庫服務器就會將處理邏輯交給客戶端。這種精簡方式的設計是MongoDB能夠實現如此高性能的原因之一
需要注意的是: #1、文檔中的鍵/值對是有序的。 #2、文檔中的值不僅可以是在雙引號里面的字符串,還可以是其他幾種數據類型(甚至可以是整個嵌入的文檔)。 #3、MongoDB區分類型和大小寫。 #4、MongoDB的文檔不能有重復的鍵。 #5、文檔中的值可以是多種不同的數據類型,也可以是一個完整的內嵌文檔。文檔的鍵是字符串。除了少數例外情況,鍵可以使用任意UTF-8字符。 文檔鍵命名規范: #1、鍵不能含有\0 (空字符)。這個字符用來表示鍵的結尾。 #2、.和$有特別的意義,只有在特定環境下才能使用。 #3、以下劃線"_"開頭的鍵是保留的(不是嚴格要求的)。
#1、集合存在于數據庫中,通常情況下為了方便管理,不同格式和類型的數據應該插入到不同的集合,但其實集合沒有固定的結構,這意味著我們完全可以把不同格式和類型的數據統統插入一個集合中。 #2、組織子集合的方式就是使用“.”,分隔不同命名空間的子集合。 比如一個具有博客功能的應用可能包含兩個集合,分別是blog.posts和blog.authors,這是為了使組織結構更清晰,這里的blog集合(這個集合甚至不需要存在)跟它的兩個子集合沒有任何關系。 在MongoDB中,使用子集合來組織數據非常高效,值得推薦 #3、當第一個文檔插入時,集合就會被創建。合法的集合名: 集合名不能是空字符串""。 集合名不能含有\0字符(空字符),這個字符表示集合名的結尾。 集合名不能以"system."開頭,這是為系統集合保留的前綴。 用戶創建的集合名字不能含有保留字符。有些驅動程序的確支持在集合名里面包含,這是因為某些系統生成的集合中包含該字符。除非你要訪問這種系統創建的集合,否則千萬不要在名字里出現$。
數據庫也通過名字來標識。數據庫名可以是滿足以下條件的任意UTF-8字符串: #1、不能是空字符串("")。 #2、不得含有' '(空格)、.、$、/、\和\0 (空字符)。 #3、應全部小寫。 #4、最多64字節。 有一些數據庫名是保留的,可以直接訪問這些有特殊作用的數據庫。 #1、admin: 從身份認證的角度講,這是“root”數據庫,如果將一個用戶添加到admin數據庫,這個用戶將自動獲得所有數據庫的權限。再者,一些特定的服務器端命令也只能從admin數據庫運行,如列出所有數據庫或關閉服務器 #2、local: 這個數據庫永遠都不可以復制,且一臺服務器上的所有本地集合都可以存儲在這個數據庫中 #3、config: MongoDB用于分片設置時,分片信息會存儲在config數據庫中
例如: 如果要使用cms數據庫中的blog.posts集合,這個集合的命名空間就是 cmd.blog.posts。命名空間的長度不得超過121個字節,且在實際使用中應該小于100個字節
#1、安裝路徑為D:\MongoDB,將D:\MongoDB\bin目錄加入環境變量#2、新建目錄與文件D:\MongoDB\data\db
D:\MongoDB\log\mongod.log#3、新建配置文件mongod.cfg,參考:https://docs.mongodb.com/manual/reference/configuration-options/systemLog:
destination: file
path: "D:\MongoDB\log\mongod.log"
logAppend: true
storage:
journal:
enabled: true
dbPath: "D:\MongoDB\data\db"net:
bindIp: 0.0.0.0
port: 27017setParameter:
enableLocalhostAuthBypass: false
#4、制作系統服務mongod --config "D:\MongoDB\mongod.cfg" --bind_ip 0.0.0.0 --install
或者直接在命令行指定配置
mongod --bind_ip 0.0.0.0 --port 27017 --logpath D:\MongoDB\log\mongod.log --logappend --dbpath D:\MongoDB\data\db --serviceName "MongoDB" --serviceDisplayName "MongoDB" --install
先停掉服務:net stop MongoDB
然后移除服務:mongo --remove
再重新制作服務,需要加上--auth,表示加載認證功能
mongod --bind_ip 0.0.0.0 --port 27017 --logpath D:\MongoDB\log\mongod.log --logappend --dbpath D:\MongoDB\data\db --serviceName "MongoDB" --serviceDisplayName "MongoDB" --install --auth
#5、啟動\關閉net start MongoDB
net stop MongoDB#6、登錄mongo
鏈接:http://www.runoob.com/mongodb/mongodb-window-install.html#1、創建賬號use admin
db.createUser(
{
user: "root",
pwd: "123",
roles: [ { role: "root", db: "admin" } ]
})use test
db.createUser(
{
user: "tom",
pwd: "123",
roles: [ { role: "readWrite", db: "test" },
{ role: "read", db: "db1" } ]
})#2、重啟數據庫mongod --remove
mongod --config "C:\mongodb\mongod.cfg" --bind_ip 0.0.0.0 --install --auth#3、登錄:注意使用雙引號而非單引號mongo --port 27017 -u "root" -p "123" --authenticationDatabase "admin"也可以在登錄之后用db.auth("賬號","密碼")登錄
mongo
use admin
db.auth("root","123")#推薦博客:https://www.cnblogs.com/zhoujinyi/p/4610050.html#1、mongo 127.0.0.1:27017/config #連接到任何數據庫config
#2、mongo --nodb #不連接到任何數據庫
#3、啟動之后,在需要時運行new Mongo(hostname)命令就可以連接到想要的mongod了:
> conn=new Mongo('127.0.0.1:27017')
connection to 127.0.0.1:27017
> db=conn.getDB('admin')
admin
#4、help查看幫助
#5、mongo時一個簡化的JavaScript shell,是可以執行JavaScript腳本的MongoDB中存儲的文檔必須有一個"_id"鍵。這個鍵的值可以是任意類型,默認是個ObjectId對象。
在一個集合里,每個文檔都有唯一的“_id”,確保集合里每個文檔都能被唯一標識。
不同集合"_id"的值可以重復,但同一集合內"_id"的值必須唯一
#1、ObjectId
ObjectId是"_id"的默認類型。因為設計MongoDb的初衷就是用作分布式數據庫,所以能夠在分片環境中生成
唯一的標識符非常重要,而常規的做法:在多個服務器上同步自動增加主鍵既費時又費力,這就是MongoDB采用
ObjectId的原因。
ObjectId采用12字節的存儲空間,是一個由24個十六進制數字組成的字符串
0|1|2|3| 4|5|6| 7|8 9|10|11
時間戳 機器 PID 計數器
如果快速創建多個ObjectId,會發現每次只有最后幾位有變化。另外,中間的幾位數字也會變化(要是在創建過程中停頓幾秒)。
這是ObjectId的創建方式導致的,如上圖
時間戳單位為秒,與隨后5個字節組合起來,提供了秒級的唯一性。這個4個字節隱藏了文檔的創建時間,絕大多數驅動程序都會提供
一個方法,用于從ObjectId中獲取這些信息。
因為使用的是當前時間,很多用戶擔心要對服務器進行時鐘同步。其實沒必要,因為時間戳的實際值并不重要,只要它總是不停增加就好。
接下來3個字節是所在主機的唯一標識符。通常是機器主機名的散列值。這樣就可以保證不同主機生成不同的ObjectId,不產生沖突
接下來連個字節確保了在同一臺機器上并發的多個進程產生的ObjectId是唯一的
前9個字節確保了同一秒鐘不同機器不同進程產生的ObjectId是唯一的。最后3個字節是一個自動增加的 計數器。確保相同進程的同一秒產生的
ObjectId也是不一樣的。
#2、自動生成_id
如果插入文檔時沒有"_id"鍵,系統會自幫你創建 一個。可以由MongoDb服務器來做這件事。
但通常會在客戶端由驅動程序完成。這一做法非常好地體現了MongoDb的哲學:能交給客戶端驅動程序來做的事情就不要交給服務器來做。
這種理念背后的原因是:即便是像MongoDB這樣擴展性非常好的數據庫,擴展應用層也要比擴展數據庫層容易的多。將工作交給客戶端做就
減輕了數據庫擴展的負擔。#1、null:用于表示空或不存在的字段d={'x':null}#2、布爾型:true和falsed={'x':true,'y':false}#3、數值d={'x':3,'y':3.1415926}#4、字符串d={'x':'tom'}#5、日期d={'x':new Date()}d.x.getHours()#6、正則表達式d={'pattern':/^egon.*?nb$/i}正則寫在//內,后面的i代表:i 忽略大小寫
m 多行匹配模式
x 忽略非轉義的空白字符
s 單行匹配模式#7、數組d={'x':[1,'a','v']}#8、內嵌文檔user={'name':'tom','addr':{'country':'China','city':'YT'}}user.addr.country#9、對象id:是一個12字節的ID,是文檔的唯一標識,不可變d={'x':ObjectId()}#1、增use db1 #如果數據庫不存在,則創建數據庫,否則切換到指定數據庫。#2、查show dbs #查看所有可以看到,我們剛創建的數據庫db1并不在數據庫的列表中, 要顯示它,我們需要向db1數據庫插入一些數據。
db.table1.insert({'a':1})#3、刪use db1 #先切換到要刪的庫下db.dropDatabase() #刪除當前庫#1、增當第一個文檔插入時,集合就會被創建> use database1
switched to db database1> db.table1.insert({'a':1})WriteResult({ "nInserted" : 1 })> db.table2.insert({'b':2})WriteResult({ "nInserted" : 1 })db.user
db.user.info 表名是user.info,跟user表沒有任何關系
db.user.auth#2、查> show tables
table1
table2#3、刪> db.table1.drop()true> show tables
table2#1、沒有指定_id則默認ObjectId,_id不能重復,且在插入后不可變#2、插入單條user0={
"name":"tom",
"age":10,
'hobbies':['music','read','dancing'],
'addr':{
'country':'China',
'city':'BJ'
}}db.test.insert(user0)db.test.find()#3、插入多條user1={
"_id":1,
"name":"zhang3",
"age":10,
'hobbies':['music','read','dancing'],
'addr':{
'country':'China',
'city':'weifang'
}}user2={
"_id":2,
"name":"li4",
"age":20,
'hobbies':['music','read','run'],
'addr':{
'country':'China',
'city':'hebei'
}}user3={
"_id":3,
"name":"wang5",
"age":30,
'hobbies':['music','drink'],
'addr':{
'country':'China',
'city':'heibei'
}}user4={
"_id":4,
"name":"zhao6",
"age":40,
'hobbies':['music','read','dancing','tea'],
'addr':{
'country':'China',
'city':'BJ'
}}user5={
"_id":5,
"name":"sun7",
"age":50,
'hobbies':['music','read',],
'addr':{
'country':'China',
'city':'henan'
}}db.user.insertMany([user1,user2,user3,user4,user5])db.t1.insert({"_id":1,"a":"1","b":"2","c":"3"})db.t1.save({"_id":1,"z":"6"}) 有就用新的記錄覆蓋掉原來的記錄,無就新增# SQL:=,!=,>,<,>=,<=# MongoDB:{key:value}代表什么等于什么"$ne"====>不等于"$gt"====>大于"$lt"====>小于"gte"====>大于等于"lte"====>小于等于
其中"$ne"能用于所有數據類型#1、select * from db1.user where name = "alex";db.user.find({'name':'alex'})#2、select * from db1.user where name != "alex";db.user.find({'name':{"$ne":'alex'}})#3、select * from db1.user where id > 2;db.user.find({'_id':{'$gt':2}})#4、select * from db1.user where id < 3;db.user.find({'_id':{'$lt':3}})#5、select * from db1.user where id >= 2;db.user.find({"_id":{"$gte":2,}})#6、select * from db1.user where id <= 2;db.user.find({"_id":{"$lte":2}})# SQL:and,or,not# MongoDB:字典中逗號分隔的多個條件是and關系,"$or"的條件放到[]內,"$not"#1、select * from db1.user where id >= 2 and id < 4;db.user.find({'_id':{"$gte":2,"$lt":4}})#2、select * from db1.user where id >= 2 and age < 40;db.user.find({"_id":{"$gte":2},"age":{"$lt":40}})#3、select * from db1.user where id >= 5 or name = "alex";db.user.find({
"$or":[
{'_id':{"$gte":5}},
{"name":"alex"}
]})#4、select * from db1.user where id % 2=1;db.user.find({'_id':{"$mod":[2,1]}})#5、上題,取反db.user.find({'_id':{"$not":{"$mod":[2,1]}}})# SQL:in,not in# MongoDB:"$in","$nin"#1、select * from db1.user where age in (20,30,31);db.user.find({"age":{"$in":[20,30,31]}})#2、select * from db1.user where name not in ('alex','yuanhao');db.user.find({"name":{"$nin":['alex','yuanhao']}})# SQL: regexp 正則# MongoDB: /正則表達/i#1、select * from db1.user where name regexp '^j.*?(g|n)$';db.user.find({'name':/^j.*?(g|n)$/i})#1、select name,age from db1.user where id=3;db.user.find({'_id':3},{'_id':0,'name':1,'age':1})1:代表要,類似True0:代表不要,類似Flase,默認是0#1、查看有dancing愛好的人db.user.find({'hobbies':'dancing'})#2、查看既有dancing愛好又有tea愛好的人db.user.find({
'hobbies':{
"$all":['dancing','tea']
}})#3、查看第4個愛好為tea的人:".方法"db.user.find({"hobbies.3":'tea'})#4、查看所有人最后兩個愛好:"$slice"db.user.find({},{'hobbies':{"$slice":-2},"age":0,"_id":0,"name":0,"addr":0})#5、查看所有人的第2個到第3個愛好db.user.find({},{'hobbies':{"$slice":[1,2]},"age":0,"_id":0,"name":0,"addr":0})> db.blog.find().pretty(){
"_id" : 1,
"name" : "sun7公司破產的真相",
"comments" : [
{
"name" : "zhang3",
"content" : "sun7是誰???",
"thumb" : 200
},
{
"name" : "li4",
"content" : "我去,真的假的",
"thumb" : 300
},
{
"name" : "wang5",
"content" : "吃喝嫖賭抽,欠下兩個億",
"thumb" : 40
},
{
"name" : "zhao6",
"content" : "丐幫歡迎你",
"thumb" : 0
}
]}db.blog.find({},{'comments':{"$slice":-2}}).pretty() #查詢最后兩個db.blog.find({},{'comments':{"$slice":[1,2]}}).pretty() #查詢1到2# 排序:1代表升序,-1代表降序db.user.find().sort({"name":1})db.user.find().sort({"age":-1,'_id':1})# 分頁:limit代表取多少個document,skip代表跳過前多少個document。 db.user.find().sort({'age':1}).limit(1).skip(2)# 獲取數量db.user.count({'age':{"$gt":30}}) --或者
db.user.find({'age':{"$gt":30}}).count()#1、{'key':null} 匹配key的值為null或者沒有這個keydb.t2.insert({'a':10,'b':111})db.t2.insert({'a':20})db.t2.insert({'b':null})> db.t2.find({"b":null}){ "_id" : ObjectId("5a5cc2a7c1b4645aad959e5a"), "a" : 20 }{ "_id" : ObjectId("5a5cc2a8c1b4645aad959e5b"), "b" : null }#2、查找所有db.user.find() #等同于db.user.find({})db.user.find().pretty()#3、查找一個,與find用法一致,只是只取匹配成功的第一個db.user.findOne({"_id":{"$gt":3}})#4、去重db.user.find().distinct()update() 方法用于更新已存在的文檔。語法格式如下:
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
})參數說明:對比update db1.t1 set name='zhangsan',sex='Male' where name='zhang3' and age=18;query : 相當于where條件。
update : update的對象和一些更新的操作符(如$,$inc...等,相當于set后面的
upsert : 可選,默認為false,代表如果不存在update的記錄不更新也不插入,設置為true代表插入。
multi : 可選,默認為false,代表只更新找到的第一條記錄,設為true,代表更新找到的全部記錄。
writeConcern :可選,拋出異常的級別。
更新操作是不可分割的:若兩個更新同時發送,先到達服務器的先執行,然后執行另外一個,不會破壞文檔。#注意:除非是刪除,否則_id是始終不會變的#1、覆蓋式:db.user.update({'age':20},{"name":"wang5","hobbies_count":3})是用{"_id":2,"name":"wang5","hobbies_count":3}覆蓋原來的記錄#2、一種最簡單的更新就是用一個新的文檔完全替換匹配的文檔。這適用于大規模式遷移的情況。例如var obj=db.user.findOne({"_id":2})obj.username=obj.name+'SB'obj.hobbies_count++delete obj.age
db.user.update({"_id":2},obj)#設置:$set通常文檔只會有一部分需要更新。可以使用原子性的更新修改器,指定對文檔中的某些字段進行更新。
更新修改器是種特殊的鍵,用來指定復雜的更新操作,比如修改、增加后者刪除#1、update db1.user set name="wang5" where id = 2db.user.update({'_id':2},{"$set":{"name":"wang5",}})#2、沒有匹配成功則新增一條{"upsert":true}db.user.update({'_id':6},{"$set":{"name":"wang5","age":18}},{"upsert":true})#3、默認只改匹配成功的第一條,{"multi":改多條}db.user.update({'_id':{"$gt":4}},{"$set":{"age":28}})db.user.update({'_id':{"$gt":4}},{"$set":{"age":38}},{"multi":true})#4、修改內嵌文檔,把名字為wang5的人所在的地址國家改成Japandb.user.update({'name':"wang5"},{"$set":{"addr.country":"Japan"}})#5、把名字為wang5的人的地2個愛好改成piaodb.user.update({'name':"wang5"},{"$set":{"hobbies.1":"piao"}})#6、刪除wang5的愛好,$unsetdb.user.update({'name':"wang5"},{"$unset":{"hobbies":""}})#增加和減少:$inc#1、所有人年齡增加一歲db.user.update({},
{
"$inc":{"age":1}
},
{
"multi":true }
)#2、所有人年齡減少5歲db.user.update({},
{
"$inc":{"age":-5}
},
{
"multi":true }
)#添加刪除數組內元素
往數組內添加元素:$push#1、為名字為wang5的人添加一個愛好readdb.user.update({"name":"wang5"},{"$push":{"hobbies":"read"}})#2、為名字為wang5的人一次添加多個愛好tea,dancingdb.user.update({"name":"wang5"},{"$push":{
"hobbies":{"$each":["tea","dancing"]}}})按照位置且只能從開頭或結尾刪除元素:$pop#3、{"$pop":{"key":1}} 從數組末尾刪除一個元素db.user.update({"name":"wang5"},{"$pop":{
"hobbies":1}})#4、{"$pop":{"key":-1}} 從頭部刪除db.user.update({"name":"wang5"},{"$pop":{
"hobbies":-1}})#5、按照條件刪除元素,:"$pull" 把符合條件的統統刪掉,而$pop只能從兩端刪db.user.update({'addr.country':"China"},{"$pull":{
"hobbies":"read"}},{
"multi":true})#避免添加重復:"$addToSet"db.urls.insert({"_id":1,"urls":[]})db.urls.update({"_id":1},{"$addToSet":{"urls":'http://www.baidu.com'}})db.urls.update({"_id":1},{"$addToSet":{"urls":'http://www.baidu.com'}})db.urls.update({"_id":1},{"$addToSet":{"urls":'http://www.baidu.com'}})db.urls.update({"_id":1},{
"$addToSet":{
"urls":{
"$each":[
'http://www.baidu.com',
'http://www.baidu.com',
'http://www.xxxx.com'
]
}
}
})#1、了解:限制大小"$slice",只留最后n個db.user.update({"_id":5},{
"$push":{"hobbies":{
"$each":["read",'music','dancing'],
"$slice":-2
}
}})#2、了解:排序The $sort element value must be either 1 or -1"db.user.update({"_id":5},{
"$push":{"hobbies":{
"$each":["read",'music','dancing'],
"$slice":-1,
"$sort":-1
}
}})#注意:不能只將"$slice"或者"$sort"與"$push"配合使用,且必須使用"$eah"#1、刪除多個中的第一個db.user.deleteOne({ 'age': 8 })#2、刪除國家為China的全部db.user.deleteMany( {'addr.country': 'China'} ) #3、刪除全部db.user.deleteMany({})如果你有數據存儲在MongoDB中,你想做的可能就不僅僅是將數據提取出來那么簡單了;你可能希望對數據進行分析并加以利用。MongoDB提供了以下聚合工具:#1、聚合框架#2、MapReduce(詳見MongoDB權威指南)#3、幾個簡單聚合命令:count、distinct和group。(詳見MongoDB權威指南)#聚合框架:可以使用多個構件創建一個管道,上一個構件的結果傳給下一個構件。 這些構件包括(括號內為構件對應的操作符):篩選($match)、投射($project)、分組($group)、排序($sort)、限制($limit)、跳過($skip)不同的管道操作符可以任意組合,重復使用
from pymongo import MongoClientimport datetime
client=MongoClient('mongodb://root:123@localhost:27017')table=client['db1']['emp']# table.drop()l=[('tom','male',18,'20170301','校長',73000.33,401,1), #以下是教學部('bob','male',78,'20150302','teacher',10000.31,401,1),('sam','male',81,'20130305','teacher',8300,401,1),('zhang3','male',73,'20140701','teacher',3500,401,1),('li4','male',28,'20121101','teacher',2100,401,1),('may','female',18,'20110211','teacher',9000,401,1),('wang5','male',18,'19000301','teacher',30000,401,1),('成龍','male',48,'20101111','teacher',10000,401,1),('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是銷售部門('丫丫','female',38,'20101101','sale',2000.35,402,2),('丁丁','female',18,'20110312','sale',1000.37,402,2),('星星','female',18,'20160513','sale',3000.29,402,2),('格格','female',28,'20170127','sale',4000.33,402,2),('張野','male',28,'20160311','operation',10000.13,403,3), #以下是運營部門('程咬金','male',18,'19970312','operation',20000,403,3),('程咬銀','female',18,'20130311','operation',19000,403,3),('程咬銅','male',18,'20150411','operation',18000,403,3),('程咬鐵','female',18,'20140512','operation',17000,403,3)]for n,item in enumerate(l):
d={
"_id":n,
'name':item[0],
'sex':item[1],
'age':item[2],
'hire_date':datetime.datetime.strptime(item[3],'%Y%m%d'),
'post':item[4],
'salary':item[5]
}
table.save(d){"$match":{"字段":"條件"}},可以使用任何常用查詢操作符$gt,$lt,$in等#例1、select * from db1.emp where post='teacher';db.emp.aggregate({"$match":{"post":"teacher"}})#例2、select * from db1.emp where id > 3 group by post; db.emp.aggregate(
{"$match":{"_id":{"$gt":3}}},
{"$group":{"_id":"$post",'avg_salary':{"$avg":"$salary"}}})#例3、select * from db1.emp where id > 3 group by post having avg(salary) > 10000; db.emp.aggregate(
{"$match":{"_id":{"$gt":3}}},
{"$group":{"_id":"$post",'avg_salary':{"$avg":"$salary"}}},
{"$match":{"avg_salary":{"$gt":10000}}}){"$project":{"要保留的字段名":1,"要去掉的字段名":0,"新增的字段名":"表達式"}}#1、select name,post,(age+1) as new_age from db1.emp;db.emp.aggregate(
{"$project":{
"name":1,
"post":1,
"new_age":{"$add":["$age",1]}
}})#2、表達式之數學表達式{"$add":[expr1,expr2,...,exprN]} #相加{"$subtract":[expr1,expr2]} #第一個減第二個{"$multiply":[expr1,expr2,...,exprN]} #相乘{"$pide":[expr1,expr2]} #第一個表達式除以第二個表達式的商作為結果{"$mod":[expr1,expr2]} #第一個表達式除以第二個表達式得到的余數作為結果#3、表達式之日期表達式:$year,$month,$week,$dayOfMonth,$dayOfWeek,$dayOfYear,$hour,$minute,$second#例如:select name,date_format("%Y") as hire_year from db1.empdb.emp.aggregate(
{"$project":{"name":1,"hire_year":{"$year":"$hire_date"}}})#例如查看每個員工的工作多長時間db.emp.aggregate(
{"$project":{"name":1,"hire_period":{
"$subtract":[
{"$year":new Date()},
{"$year":"$hire_date"}
]
}}})#4、字符串表達式{"$substr":[字符串/$值為字符串的字段名,起始位置,截取幾個字節]}{"$concat":[expr1,expr2,...,exprN]} #指定的表達式或字符串連接在一起返回,只支持字符串拼接{"$toLower":expr}{"$toUpper":expr}db.emp.aggregate( {"$project":{"NAME":{"$toUpper":"$name"}}})#5、邏輯表達式$and$or$not其他見Mongodb權威指南{"$group":{"_id":分組字段,"新的字段名":聚合操作符}}#1、將分組字段傳給$group函數的_id字段即可{"$group":{"_id":"$sex"}} #按照性別分組{"$group":{"_id":"$post"}} #按照職位分組{"$group":{"_id":{"state":"$state","city":"$city"}}} #按照多個字段分組,比如按照州市分組#2、分組后聚合得結果,類似于sql中聚合函數的聚合操作符:$sum、$avg、$max、$min、$first、$last#例1:select post,max(salary) from db1.emp group by post; db.emp.aggregate({"$group":{"_id":"$post","max_salary":{"$max":"$salary"}}})#例2:去每個部門最大薪資與最低薪資db.emp.aggregate({"$group":{"_id":"$post","max_salary":{"$max":"$salary"},"min_salary":{"$min":"$salary"}}})#例3:如果字段是排序后的,那么$first,$last會很有用,比用$max和$min效率高db.emp.aggregate({"$group":{"_id":"$post","first_id":{"$first":"$_id"}}})#例4:求每個部門的總工資db.emp.aggregate({"$group":{"_id":"$post","count":{"$sum":"$salary"}}})#例5:求每個部門的人數db.emp.aggregate({"$group":{"_id":"$post","count":{"$sum":1}}})#3、數組操作符{"$addToSet":expr}:不重復{"$push":expr}:重復#例:查詢崗位名以及各崗位內的員工姓名:select post,group_concat(name) from db1.emp group by post;db.emp.aggregate({"$group":{"_id":"$post","names":{"$push":"$name"}}})db.emp.aggregate({"$group":{"_id":"$post","names":{"$addToSet":"$name"}}}){"$sort":{"字段名":1,"字段名":-1}} #1升序,-1降序{"$limit":n} {"$skip":n} #跳過多少個文檔#例1、取平均工資最高的前兩個部門db.emp.aggregate({
"$group":{"_id":"$post","平均工資":{"$avg":"$salary"}}},{
"$sort":{"平均工資":-1}},{
"$limit":2})#例2、db.emp.aggregate({
"$group":{"_id":"$post","平均工資":{"$avg":"$salary"}}},{
"$sort":{"平均工資":-1}},{
"$limit":2},{
"$skip":1})#集合users包含的文檔如下{ "_id" : 1, "name" : "dave123", "q1" : true, "q2" : true }{ "_id" : 2, "name" : "dave2", "q1" : false, "q2" : false }{ "_id" : 3, "name" : "ahn", "q1" : true, "q2" : true }{ "_id" : 4, "name" : "li", "q1" : true, "q2" : false }{ "_id" : 5, "name" : "annT", "q1" : false, "q2" : true }{ "_id" : 6, "name" : "li", "q1" : true, "q2" : true }{ "_id" : 7, "name" : "ty", "q1" : false, "q2" : true }#下述操作時從users集合中隨機選取3個文檔db.users.aggregate(
[ { $sample: { size: 3 } } ])以上是“一篇文章教會你如何操作MongoDB”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





