溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關python爬蟲多線程加速爬取的方法的內容。小編覺得挺實用的,因此分享給大家做個參考。一起跟隨小編過來看看吧。
一、準備階段
python3 、多線程庫 、第三方庫 requests的安裝以及調用
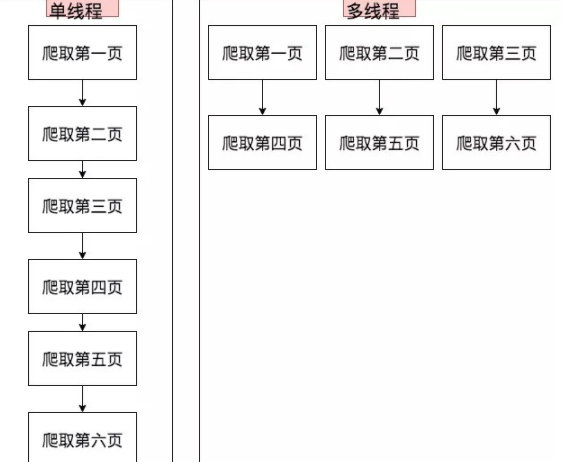
二、線程分析圖示:
三、多線程加速實現代碼演示
import requests
from threading import Thread,current_thread
def parse_page(res):
print('%s 解析 %s' %(current_thread().getName(),len(res)))
def get_page(url,callback=parse_page):
print('%s 下載 %s' %(current_thread().getName(),url))
response=requests.get(url)
if response.status_code == 200:
callback(response.text)
if __name__ == '__main__':
urls=['鏈接']
for url in urls:
t=Thread(target=get_page,args=(url,))
t.start()感謝各位的閱讀!關于python爬蟲多線程加速爬取的方法就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





