溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下萬億級數據應該遷移的方法,希望大家閱讀完這篇文章后大所收獲,下面讓我們一起去探討吧!
在星爺的《大話西游》中有一句非常出名的臺詞:“曾經有一份真摯的感情擺在我的面前我沒有珍惜,等我失去的時候才追悔莫及,人間最痛苦的事莫過于此,如果上天能給我一次再來一次的機會,我會對哪個女孩說三個字:我愛你,如果非要在這份愛上加一個期限,我希望是一萬年!”在我們開發人員的眼中,這個感情就和我們數據庫中的數據一樣,我們多希望他一萬年都不改變,但是往往事與愿違,隨著公司的不斷發展,業務的不斷變更,我們對數據的要求也在不斷的變化,大概有下面的幾種情況:
在實際業務開發中,我們會根據不同的情況來做出不同的遷移方案,接下來我們來討論一下到底應該怎么遷移數據。
數據遷移其實不是一蹴而就的,每一次數據遷移都需要一段漫長的時間,有可能是一周,有可能是幾個月,通常來說我們遷移數據的過程基本都和下圖差不多: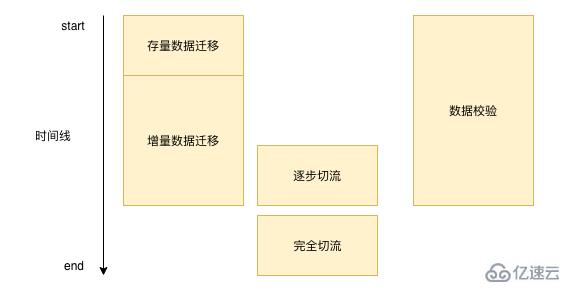 ‘
首先我們需要將我們數據庫已經存在的數據進行批量的遷移,然后需要處理新增的這部分數據,需要實時的把這部分數據在寫完原本的數據庫之后然后寫到我們的新的存儲,在這一過程中我們需要不斷的進行數據校驗。當我們校驗基本問題不大的時候,然后進行切流操作,直到完全切流之后,我們就可以不用再進行數據校驗和增量數據遷移。
‘
首先我們需要將我們數據庫已經存在的數據進行批量的遷移,然后需要處理新增的這部分數據,需要實時的把這部分數據在寫完原本的數據庫之后然后寫到我們的新的存儲,在這一過程中我們需要不斷的進行數據校驗。當我們校驗基本問題不大的時候,然后進行切流操作,直到完全切流之后,我們就可以不用再進行數據校驗和增量數據遷移。
首先我們來說一下存量數據遷移應該怎么做,存量數據遷移在開源社區中搜索了一圈發現沒有太好用的工具,目前來說阿里云的DTS提供了存量數據遷移,DTS支持同構和異構不同數據源之間的遷移,基本支持業界常見的數據庫比如Mysql,Orcale,SQL Server等等。DTS比較適合我們之前說的前兩個場景,一個是分庫的場景,如果使用的是阿里云的DRDS那么就可以直接將數據通過DTS遷移到DRDS,另外一個是數據異構的場景,無論是Redis還是ES,DTS都支持直接進行遷移。
那么DTS的存量遷移怎么做的呢?其實比較簡單大概就是下面幾個步驟:
select * from table_name where id > curId and id < curId + 10000;復制代碼
3.當id大于等于maxId之后,存量數據遷移任務結束
當然我們在實際的遷移過程中可能不會去使用阿里云,或者說在我們的第三個場景下,我們的數據庫字段之間需要做很多轉換,DTS不支持,那么我們就可以模仿DTS的做法,通過分段批量讀取數據的方式來遷移數據,這里需要注意的是我們批量遷移數據的時候需要控制分段的大小,以及頻率,防止影響我們線上的正常運行。
存量數據的遷移方案比較有限,但是增量的數據遷移方法就是百花齊放了,一般來說我們有下面的幾種方法:
這么多種方式我們應該使用哪種呢?我個人來說是比較推薦監聽binlog的做法的,監聽binlog減少開發成本,我們只需要實現consumer邏輯即可,數據能保證一致性,因為是監聽的binlog這里不需要擔心之前雙寫的時候不是一個事務的問題。
前面所說的所有方案,雖然有很多是成熟的云服務(dts)或者中間件(canal),但是他們都有可能出現一些數據丟失,出現數據丟失的情況整體來說還是比較少,但是非常難排查,有可能是dts或者canal不小心抖了一下,又或者是接收數據的時候不小心導致的丟失。既然我們沒有辦法避免我們的數據在遷移的過程中丟失,那么我們應該通過其他手段來進行校正。
通常來說我們遷移數據的時候都會有數據校驗這一個步驟,但是在不同團隊可能會選取不同的數據校驗方案:
當然在實際開發過程中我們也需要注意下面幾點:
當我們數據校驗基本沒有報錯了之后,說明我們的遷移程序是比較穩定的了,那么我們就可以直接使用我們新的數據了嗎?當然是不可以的,如果我們一把切換了,順利的話當然是很好的,如果出現問題了,那么就會影響所有的用戶。
所以我們接下來就需要進行灰度,也就是切流。 對于不同的業務切流的的維度會不一樣,對于用戶維度的切流,我們通常會以userId的取模的方式去進行切流,對于租戶或者商家維度的業務,就需要按照租戶id取模的方式去切流。這個切流需要制定好一個切流計劃,在什么時間段,放出多少的流量,并且切流的時候一定要選擇流量比較少的時候進行切流,每一次切流都需要對日志做詳細的觀察,出現問題盡早修復,流量的一個放出過程是一個由慢到快的過程,比如最開始是以1%的量去不斷疊加的,到后面的時候我們直接以10%,20%的量去快速放量。因為如果出現問題的話往往在小流量的時候就會發現,如果小流量沒有問題那么后續就可以快速放量。
在遷移數據的過程中特別要注意的是主鍵ID,在上面雙寫的方案中也提到過主鍵ID需要雙寫的時候手動的去指定,防止ID生成順序錯誤。
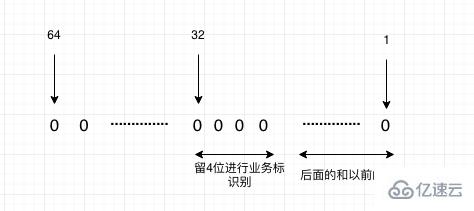
如果我們是因為分庫分表而進行遷移,就需要考慮我們以后的主鍵Id就不能是自增id,需要使用分布式id,這里比較推薦的是美團開源的leaf,他支持兩種模式一種是雪花算法趨勢遞增,但是所有的id都是Long型,適合于一些支持Long為id的應用。還有一種是號段模式,這種會根據你設置的一個基礎id,從這個上面不斷的增加。并且基本都走的是內存生成,性能也是非常的快。
當然我們還有種情況是我們需要遷移系統,之前系統的主鍵id在新系統中已經有了,那么我們的id就需要做一些映射。如果我們在遷移系統的時候已經知道未來大概有哪些系統會遷移進來,我們就可以采用預留的方式,比如A系統現在的數據是1到1億,B系統的數據也是1到1億,我們現在需要將A,B兩個系統合并成新系統,那么我們可以稍微預估一些Buffer,比如給A系統留1到1.5億,這樣A就不需要進行映射,B系統是1.5億到3億,那么我們轉換成老系統Id的時候就需要減去1.5億,最后我們新系統的新的Id就從3億開始遞增。 但是如果系統中沒有做規劃的預留段怎么辦呢?可以通過下面兩種方式:
看完了這篇文章,相信你對萬億級數據應該遷移的方法有了一定的了解,想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





