溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章運用簡單易懂的例子給大家介紹如何在Java中使用reduce方法,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
reduce 操作可以實現從Stream中生成一個值,其生成的值不是隨意的,而是根據指定的計算模型。比如,之前提到count、min和max方法,因為常用而被納入標準庫中。事實上,這些方法都是reduce操作。
reduce方法有三個override的方法:
Optional<T> reduce(BinaryOperator<T> accumulator); T reduce(T identity, BinaryOperator<T> accumulator); <U> U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner);
我們先看第一個變形,其接受一個函數接口BinaryOperator<T>,而這個接口又繼承于BiFunction<T, T, T>.在BinaryOperator接口中,又定義了兩個靜態方法minBy和maxBy。這里我們先不管這兩個靜態方法,先了解reduce的操作。
@FunctionalInterface
public interface BinaryOperator<T> extends BiFunction<T,T,T> {
public static <T> BinaryOperator<T> minBy(Comparator<? super T> comparator) {
Objects.requireNonNull(comparator);
return (a, b) -> comparator.compare(a, b) <= 0 ? a : b;
}
public static <T> BinaryOperator<T> maxBy(Comparator<? super T> comparator) {
Objects.requireNonNull(comparator);
return (a, b) -> comparator.compare(a, b) >= 0 ? a : b;
}
}在使用時,我們可以使用Lambada表達式來表示
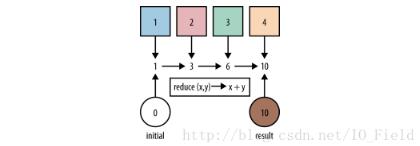
BinaryOperator接口,可以看到reduce方法接受一個函數,這個函數有兩個參數,第一個參數是上次函數執行的返回值(也稱為中間結果),第二個參數是stream中的元素,這個函數把這兩個值相加,得到的和會被賦值給下次執行這個函數的第一個參數。要注意的是:第一次執行的時候第一個參數的值是Stream的第一個元素,第二個參數是Stream的第二個元素。這個方法返回值類型是Optional,
Optional accResult = Stream.of(1, 2, 3, 4)
.reduce((acc, item) -> {
System.out.println("acc : " + acc);
acc += item;
System.out.println("item: " + item);
System.out.println("acc+ : " + acc);
System.out.println("--------");
return acc;
});
System.out.println("accResult: " + accResult.get());
System.out.println("--------");
// 結果打印
--------
acc : 1
item: 2
acc+ : 3
--------
acc : 3
item: 3
acc+ : 6
--------
acc : 6
item: 4
acc+ : 10
--------
accResult: 10
--------
下面來看第二個變形,與第一種變形相同的是都會接受一個BinaryOperator函數接口,不同的是其會接受一個identity參數,用來指定Stream循環的初始值。如果Stream為空,就直接返回該值。另一方面,該方法不會返回Optional,因為該方法不會出現null。
int accResult = Stream.of(1, 2, 3, 4)
.reduce(0, (acc, item) -> {
System.out.println("acc : " + acc);
acc += item;
System.out.println("item: " + item);
System.out.println("acc+ : " + acc);
System.out.println("--------");
return acc;
});
System.out.println("accResult: " + accResult);
System.out.println("--------");
// 結果打印
acc : 0
item: 1
acc+ : 1
--------
acc : 1
item: 2
acc+ : 3
--------
acc : 3
item: 3
acc+ : 6
--------
acc : 6
item: 4
acc+ : 10
--------
accResult: 10
--------從打印結果可以看出,reduce前兩種變形,因為接受參數不同,其執行的操作也有相應變化:
變形1,未定義初始值,從而第一次執行的時候第一個參數的值是Stream的第一個元素,第二個參數是Stream的第二個元素
變形2,定義了初始值,從而第一次執行的時候第一個參數的值是初始值,第二個參數是Stream的第一個元素
對于第三種變形,我們先看各個參數的含義,第一個參數返回實例u,傳遞你要返回的U類型對象的初始化實例u,第二個參數累加器accumulator,可以使用二元?表達式(即二元lambda表達式),聲明你在u上累加你的數據來源t的邏輯,例如(u,t)->u.sum(t),此時lambda表達式的行參列表是返回實例u和遍歷的集合元素t,函數體是在u上累加t,第三個參數組合器combiner,同樣是二元?表達式,(u,t)->u。
在官方文檔上有這么一段介紹,
U result = identity;
for (T element : this stream)
result = accumulator.apply(result, element)
return result;
but is not constrained to execute sequentially.
The identity value must be an identity for the combiner function. This means that for all u, combiner(identity, u) is equal to u. Additionally, the combiner function must be compatible with the accumulator function; for all u and t, the following must hold:
combiner.apply(u, accumulator.apply(identity, t)) == accumulator.apply(u, t)
因為reduce的變形的第一個參數類型是實際返回實例的數據類型,同時其為一個泛型也就是意味著該變形的可以返回任意類型的數據。從上面文檔介紹的字面意思解讀是第三個參數函數用來組合兩個值,而這兩個值必須與第二個函數參數相兼容,也就是說它們所得的結果是一樣的。看到這里肯定有迷惑的地方,第三個參數到底是用來干嘛的?我們先看一段代碼,為了便于了解其中的緣由,并沒有使用Lambda表達式,
ArrayList<Integer> accResult_ = Stream.of(1, 2, 3, 4)
.reduce(new ArrayList<Integer>(),
new BiFunction<ArrayList<Integer>, Integer, ArrayList<Integer>>() {
@Override
public ArrayList<Integer> apply(ArrayList<Integer> acc, Integer item) {
acc.add(item);
System.out.println("item: " + item);
System.out.println("acc+ : " + acc);
System.out.println("BiFunction");
return acc;
}
}, new BinaryOperator<ArrayList<Integer>>() {
@Override
public ArrayList<Integer> apply(ArrayList<Integer> acc, ArrayList<Integer> item) {
System.out.println("BinaryOperator");
acc.addAll(item);
System.out.println("item: " + item);
System.out.println("acc+ : " + acc);
System.out.println("--------");
return acc;
}
});
System.out.println("accResult_: " + accResult_);
// 結果打印
item: 1
acc+ : [1]
BiFunction
item: 2
acc+ : [1, 2]
BiFunction
item: 3
acc+ : [1, 2, 3]
BiFunction
item: 4
acc+ : [1, 2, 3, 4]
BiFunction
accResult_: [1, 2, 3, 4]
accResult_: 10首先示例代碼中,傳遞給第一個參數是ArrayList,在第二個函數參數中打印了“BiFunction”,而在第三個參數接口中打印了函數接口中打印了”BinaryOperator“.可是,看打印結果,只是打印了“BiFunction”,而沒有打印”BinaryOperator“,說明第三個函數參數病沒有執行。這里我們知道了該變形可以返回任意類型的數據。
對于第三個函數參數,為什么沒有執行,剛開始的時候也是沒有看懂到底是啥意思呢,而且其參數必須為返回的數據類型?看了好幾遍文檔也是一頭霧水。
在 java8 reduce方法中的第三個參數combiner有什么作用?

這里找到了答案,Stream是支持并發操作的,為了避免競爭,對于reduce線程都會有獨立的result,combiner的作用在于合并每個線程的result得到最終結果。
這也說明了了第三個函數參數的數據類型必須為返回數據類型了。
需要注意的是,因為第三個參數用來處理并發操作,如何處理數據的重復性,應多做考慮,否則會出現重復數據!
關于如何在Java中使用reduce方法就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





