溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
1、介紹
在InnoDB啟動時,如果是新建數據庫則需初始化庫,需要創建字典管理的相關信息。函數innobase_start_or_create_for_mysql調用dict_create完成此功能。即創建數據字典,因為InnoDB系統表的個數結構固定,所以初始化庫的時候只需要創建這幾個表的B+樹即可并將B+樹的根頁號存放到固定位置。對于B+樹,只要找到根頁面,就可以從根頁面開始檢索數據。相關系統表(即上一節講到的4個系統表)在InnoDB內部,不會暴露給用戶。
4個系統表通過固定的硬編碼進行構建。具體原理流程如下。2、數據字典創建及加載原理流程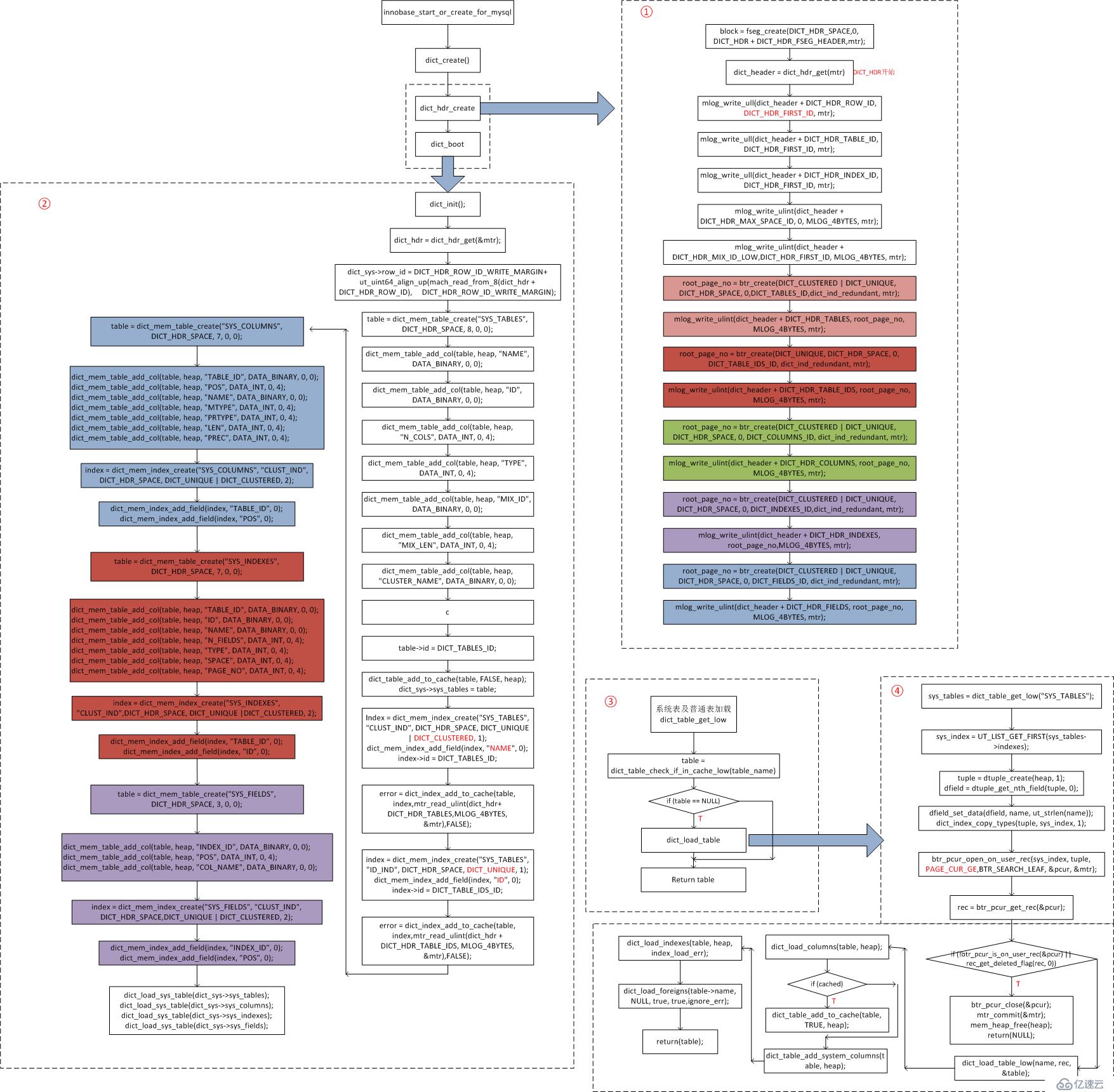
3、說明
1)innobase_start_or_create_for_mysql函數調用dict_create()函數進行數據字典的創建和加載工作。
2)dict_hdr_create完成系統表空間第7號頁面dict header的初始化及創建SYS_TABLES兩個索引、SYS_COLUMNS一個索引、SYS_INDEXES一個索引、SYS_FIELDS一個索引,其創建索引的函數是btr_create。
3)創建B+樹索引后,通過dict_boot函數加載常駐內存的4個系統表。具體流程見流程圖的②部分。
4)加載完成后,將這4個系統表掛在一個全局字典中:
dict0dict.h::
/* Dictionary system struct */
struct dict_sys_t{
ib_mutex_t mutex; /*!< mutex protecting the data
dictionary; protects also the
disk-based dictionary system tables;
this mutex serializes CREATE TABLE
and DROP TABLE, as well as reading
the dictionary data for a table from
system tables */
row_id_t row_id; /*!< the next row id to assign;
NOTE that at a checkpoint this
must be written to the dict system
header and flushed to a file; in
recovery this must be derived from
the log records */
hash_table_t* table_hash; /*!< hash table of the tables, based
on name */
hash_table_t* table_id_hash; /*!< hash table of the tables, based
on id */
ulint size; /*!< varying space in bytes occupied
by the data dictionary table and
index objects */
dict_table_t* sys_tables; /*!< SYS_TABLES table */
dict_table_t* sys_columns; /*!< SYS_COLUMNS table */
dict_table_t* sys_indexes; /*!< SYS_INDEXES table */
dict_table_t* sys_fields; /*!< SYS_FIELDS table */
/*=============================*/
UT_LIST_BASE_NODE_T(dict_table_t)
table_LRU; /*!< List of tables that can be evicted
from the cache */
UT_LIST_BASE_NODE_T(dict_table_t)
table_non_LRU; /*!< List of tables that can't be
evicted from the cache */
}; 結構體中sys_tables、sys_columns、sys_indexes、sys_fields四個結構存儲上述對應的4個系統表。
結構體中HASH表及鏈表用來存儲InnoDB中的所有表的緩存,包括系統表及用戶表。table_hash哈希表按名字緩存,table_id_hash按表ID進行hash,LRU鏈表用來管理表對象緩存。
5)普通用戶表加載流程見流程圖的③、④部分。
當用戶訪問一個用戶表時,首先需要從表對象緩存中查找這個表的SHARE對象,如果找到則直接從其實例化表對象鏈表中拿一個使用;如果沒有找到,則需要重新打開這個表,需要找到這個表的字典信息。即③的流程。
具體加載一個表的字典是④流程,dict_load_table的工作。
a)首先需要找到SYS_TABLES表,也是先找緩存,緩存找不到再從系統表加載: dict_table_get_low
b)找到之后構建一個查詢鍵值,從SYS_TABLES的name主鍵索引進行查詢,如果誒呦找到或者該記錄已經被刪除則返回,否則解析找到的這條記錄。然后根據這些信息創建表的內存對象table。
c)加載列操作與加載表的原理基本一樣,對應系統表的SYS_COLUMNS,聚集索引為(TABLE_ID,POS),查找時,如果TABLE_ID相同,在POS從小到大排序,所以構造所有列的鍵值時,只需要通過TABLE_ID查詢即可,按順序取出所有列信息一一構造內存對象。
d)加載索引信息類似的流程
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





